- The paper introduces DeconfoundLM, a method that isolates confounder effects to achieve more reliable causal alignment in large language models.
- It demonstrates that naive observational fine-tuning amplifies non-causal artifacts, leading to significant risks and misalignment.
- Empirical results show that higher regularization and explicit deconfounding improve model generalization and fairness in complex scenarios.
Causal Alignment of LLMs with Observational Data: Opportunities, Risks, and the DeconfoundLM Method
Introduction
Fine-tuning LLMs using human-annotated or experimentally generated preference data has been the dominant paradigm for aligning generative models with task-specific objectives. However, operational limitations such as engineering effort, opportunity costs, and scale render large-scale experimentation expensive and impractical in many real-world applications. At the same time, organizations accumulate vast troves of historical logs—observational data—recording model outputs and resultant key performance indicators (e.g., click-through rates, engagement, conversion). This paper (“Aligning LLMs with Observational Data: Opportunities and Risks from a Causal Perspective” (2506.00152)) interrogates the empirical and theoretical limits of utilizing such observational data for reward modeling and LLM alignment, emphasizing the substantial risks stemming from confounding.
The authors systematically analyze the pitfalls of naive observational fine-tuning through real-world and synthetic experiments. They introduce DeconfoundLM, a fine-tuning method that isolates and removes the estimated effects of known confounders in reward signals. Empirical results demonstrate that DeconfoundLM improves causal recovery and generalization relative to baseline reward learning methods, particularly when confounding is severe and entangled. The findings inform critical practice in leveraging historical data for LLM alignment, and have broader implications for fairness and causal reasoning in LLMs.
Confounding in Observational LLM Alignment
Reward signals derived from observational data are generally confounded: unobserved or uncontrolled variables influence both the model’s output and the recorded business metric. This spurious correlation distorts the reward signal, causing the aligned model to internalize and amplify non-causal artifacts—a phenomenon here termed "Causal Goodhart." The authors illustrate this concretely with the StackExchange "Monday Effect" experiment, where using answer scores (driven by platform engagement cycles, not content quality) as a reward leads models to disproportionately favor temporally correlated lexical artifacts in generation.
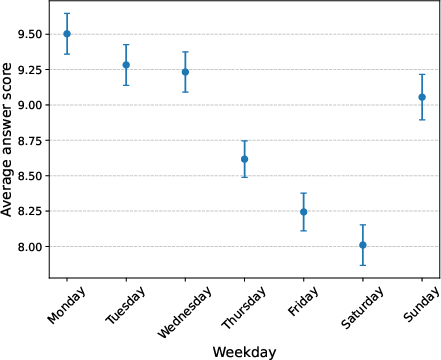
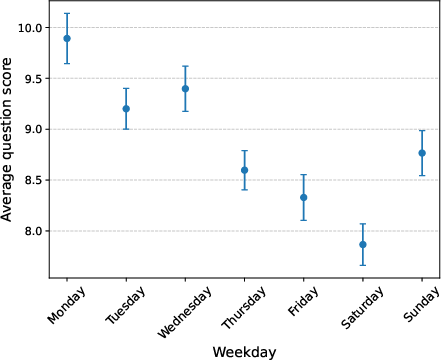
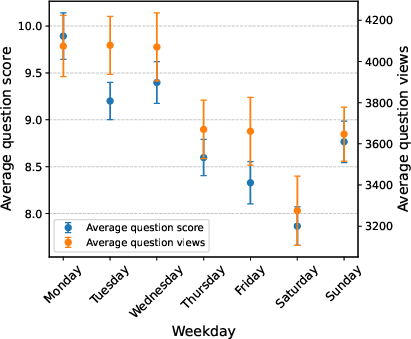
Figure 1: Average answer score by weekday, demonstrating significant cyclic confounding in StackExchange data.
The model, after DPO fine-tuning on these reward signals, amplifies artifacts like "Happy Monday!" in generated text—an explicit demonstration of confounder-induced reward misspecification. This highlights that, without explicit control for confounding, observational signals can induce systematic model misalignment.
Empirical Value and Limits of Observational Data
Despite confounding risk, utilizing observational data may still yield improvements when experimental data are unavailable or limited. The authors conduct large-scale evaluation using the Upworthy A/B test archive—a rare dataset where experimental ground-truth causal effects are available, allowing off-policy evaluation.
Training on observational packages (without access to randomized comparisons) enables the reward model to achieve ROC AUCs only moderately below those of experimental data-trained counterparts (0.74 vs. 0.82; see Figure 2), demonstrating that historical data contain informative—albeit noisy—preference signals.
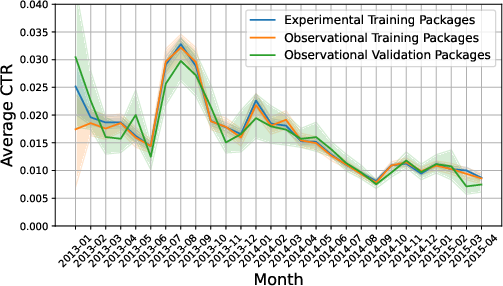
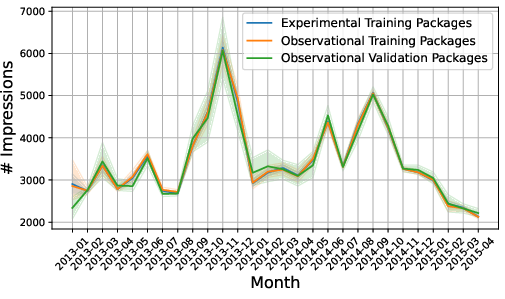
Figure 3: Monthly average CTRs across different data splits reveal strong non-causal temporal patterns, a source of confounding.
However, the generalization gap persists, and temporal overfitting is observed: reward models optimized for minimal MSE often maximize correlation with time-dependent artifacts rather than generalize causal structure.
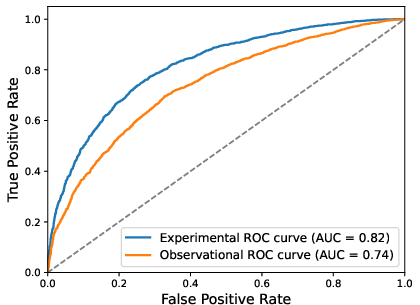
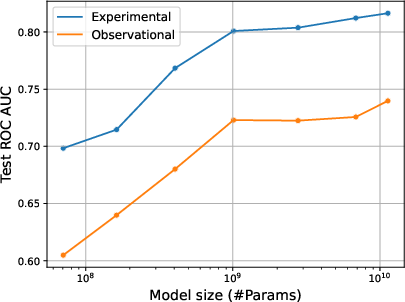
Figure 2: Pythia-12B comparison—models trained on experimental vs. observational data. Causal generalization is notably stronger with the former.
Role of Regularization and Hyperparameter Tuning
When confounding is present, optimal generalization frequently occurs at substantially higher regularization levels than those identified by standard validation splits. The gap between validation-optimal and test-optimal regularization increases with model size. This necessitates scale-aware hyperparameter selection; fixed regularization settings can lead to detrimental overfitting, especially as model capacity grows.
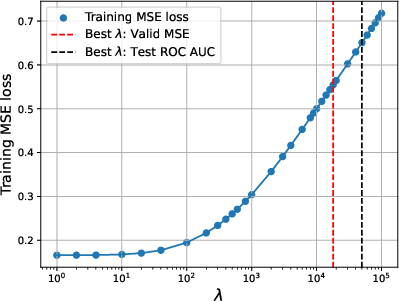
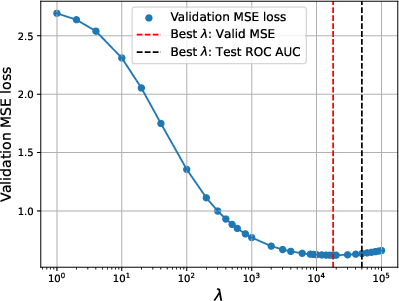
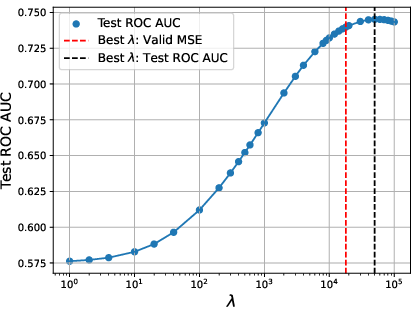
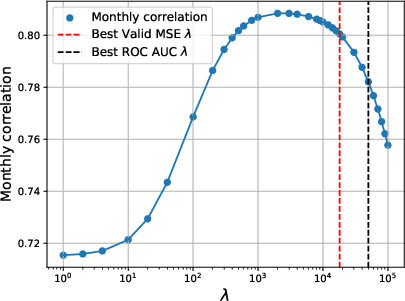
Figure 4: Training MSE vs. regularization parameter λ. Strong regularization is essential for mitigating confounder overfitting.
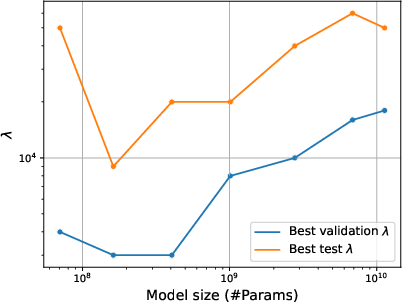
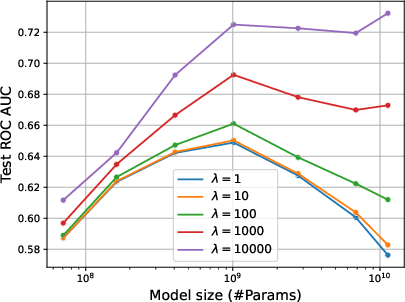
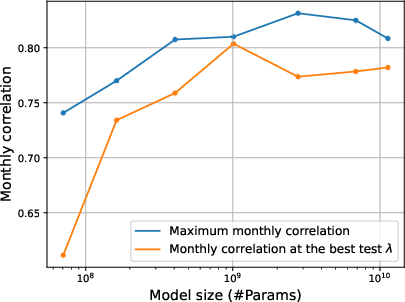
Figure 5: Optimal regularization by model size—test performance requires increased regularization as scale grows, an effect not reflected on the validation split.
DeconfoundLM: Explicit Causal Correction
The central contribution is DeconfoundLM, an econometrically motivated fine-tuning pipeline comprising:
- Estimation of the effect of known confounders on the reward signal (via methods such as instrumental variable regression or double machine learning).
- Subtraction of the confounder contribution from observed outcomes, yielding a deconfounded reward.
- Fine-tuning of the LLM using this deconfounded signal, thus directing gradient optimization toward causal structure.
Formal simulation experiments (built atop the MIND dataset) test DeconfoundLM against baselines under both orthogonal and entangled confounding scenarios. In these simulations, only DeconfoundLM and true-reward baselines demonstrate high-quality recovery of the desideratum (e.g., sentiment in generated headlines) without introducing spurious confounder-driven artifacts. Directly including confounders (e.g., as input features) is insufficient when confounder-outcome dependence is entangled with the textual signal.
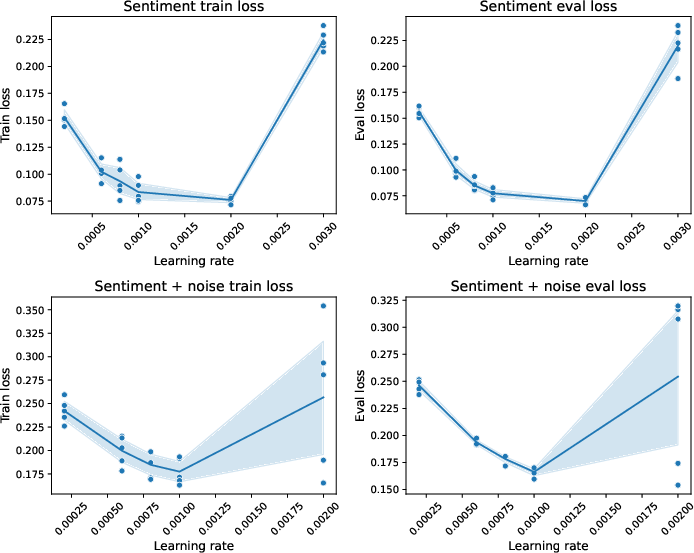
Figure 6: Loss curves for reward model training and evaluation—sentiment-based signal reveals learning dynamics under various methods and hyperparameters.
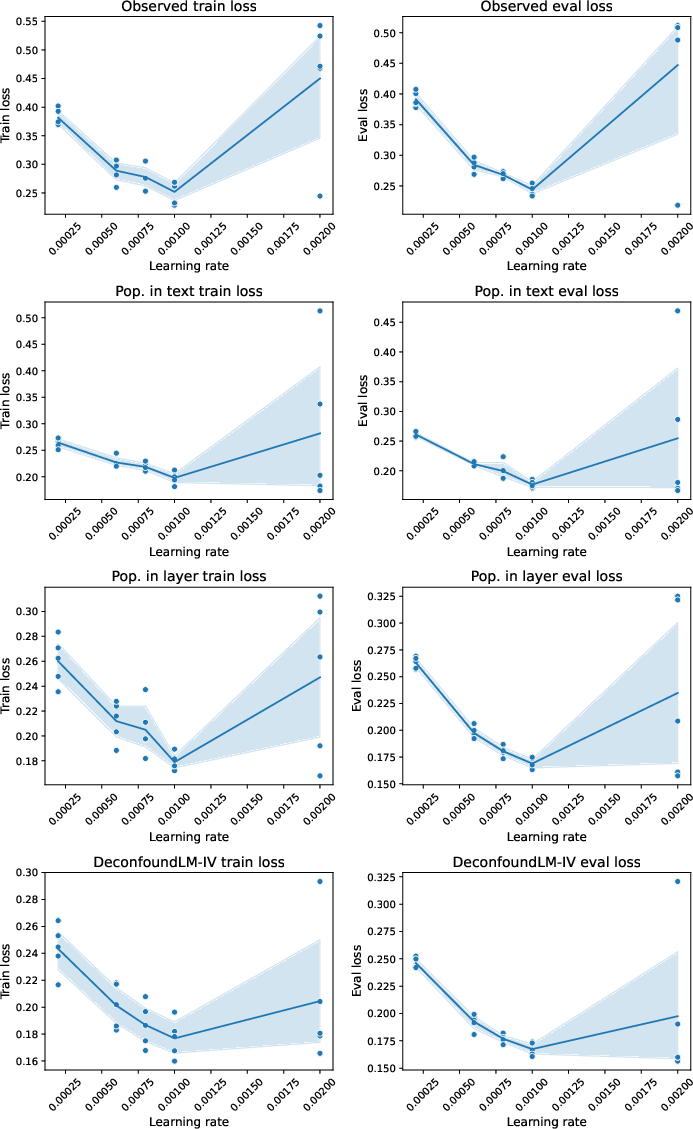
Figure 7: Loss curves for the orthogonal confounding scenario—DeconfoundLM achieves lower evaluation loss than reward models that fail to account for confounding.
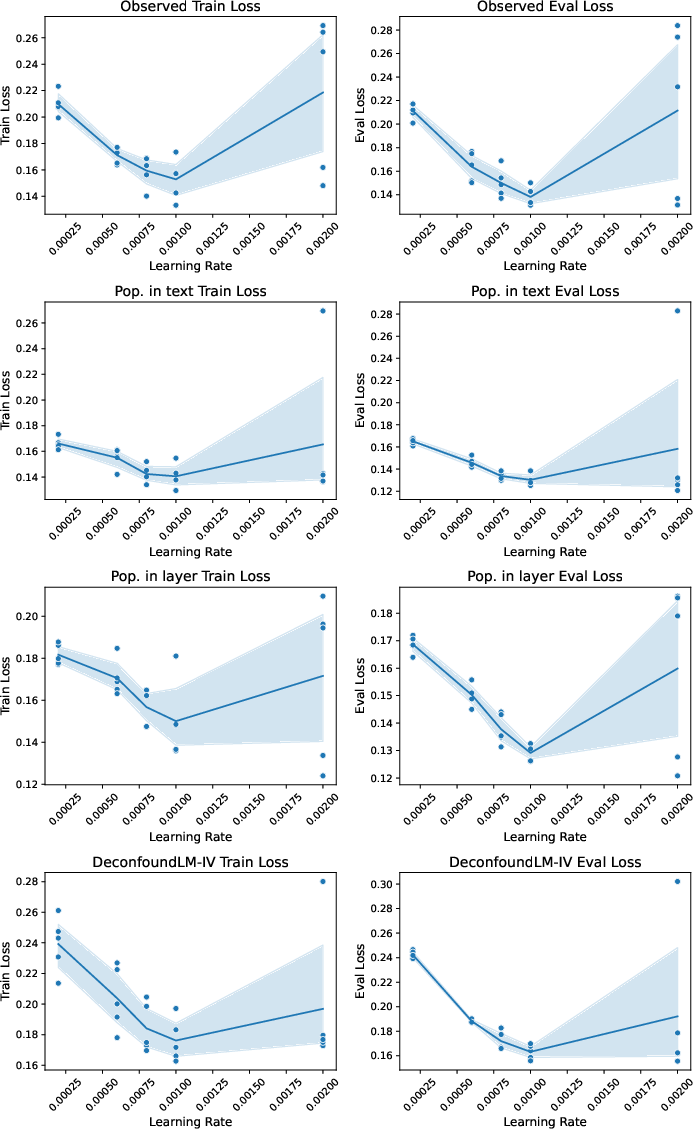
Figure 8: Loss curves for the entangled confounding scenario—naive methods fail to generalize, whereas DeconfoundLM remains robust.
Implications, Limitations, and Future Directions
By explicitly modeling and subtracting estimated confounder effects, DeconfoundLM enables more causally reliable utilization of abundant observational data for LLM alignment. This framework has significant operational value for application domains where running controlled content experiments is impracticable (e.g., marketing, health messaging).
Nonetheless, the approach assumes the confounders are all observed, and decomposing the reward function is tractable and accurate. When high-dimensional unmeasured confounding persists, causal misalignment remains a possibility, warranting further research into double/debiased learning and robust identification schemes for LLM-driven counterfactual policy estimation.
Critically, the findings extend beyond alignment performance: ignoring confounders can amplify fairness and accountability risks, internalizing structural biases inherent in historical logs. Deconfounding thus provides both a tool for better business outcomes and a pathway toward more equitable generative systems.
Conclusion
Empirical and simulation results from this study substantiate that fine-tuning LLMs with naive observational rewards poses substantial risks of confounder-induced misalignment, particularly as model capacity increases. In contrast, principled deconfounding using estimated confounder effects (DeconfoundLM) enables improved causal recovery, robustness to artifact amplification, and fairer model behavior. Continued progress in causal and alignment-aware objective construction will be essential as LLMs are deployed on massive, passively logged datasets in safety-critical domains.

