- The paper’s primary contribution is formalizing LLM pipeline decisions as causal problems to mitigate bias and enhance reliability.
- The paper presents semiparametric estimation and orthogonalization techniques to robustly quantify intervention effects across pretraining, alignment, and deployment stages.
- The paper highlights that applying causal inference improves evaluation methods and safety audits by accurately identifying intervention impacts and mediators.
Causal Methods in LLM Development and Evaluation
Motivation for Causal Inference in LLM Pipelines
The paper "Causal methods for LLM development and evaluation" (2605.25998) asserts that typical engineering decisions in LLM pipelines are intrinsically causal. Development processes such as pretraining data composition, alignment via preference learning, routing strategies, and evaluation frameworks all involve interventions that affect downstream outcomes. However, these interventions are rarely randomized; logged data is typically confounded by historical system configurations, feedback loops, and evolving deployment environments.
The authors highlight that predictive modeling is inadequate under selection bias, distribution shift, and noisy labels commonly encountered in LLM pipelines. Instead, they advocate for a principled identification and estimation paradigm from causal inference, specifically emphasizing: (1) the formalization of LLM decisions as causal problems; (2) mapping opportunities for causal methods throughout all stages of LLM development and evaluation; and (3) delineating research directions on leveraging causal techniques for agentic workflows and world modeling.
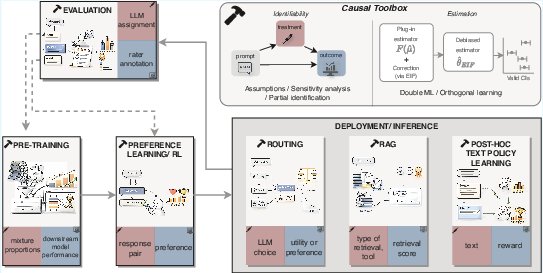
Figure 1: Overview of using causal methods for LLM development and evaluation.
Principles of Causal Reasoning Relevant to LLMs
Identifiability
The primary question is whether causal effects of interventions (e.g., changing the domain weights in pretraining, routing a query to a different model) are recoverable from observational data. The identifiability challenge is compounded by non-randomized logging, selective observation of outcomes, and metric bias introduced by learned judges. Causal modeling, e.g., via structured counterfactual reasoning, is critical to make explicit the assumptions required for identifiability. The paper stresses that identifiability is not a limitation but an explicit boundary condition that prevents unwarranted causal claims and enables sensitivity analysis and partial identification [Dorn.2024, Oprescu.2023].
Estimation
High-dimensional and complex context in LLM pipelines complicates estimation. Errors in learning nuisance parameters—such as historical policies, reward models, and missing-label predictors—propagate into final effect estimates. The paper advocates for semiparametric efficient estimation using double/debiased machine learning (DML) [Chernozhukov.2018], which removes confounding by orthogonalizing residuals, and enables valid inference even with flexible models for auxiliary quantities.
Causal Applications Across the LLM Pipeline
Pre-training Data Mixtures
Curation choices (domain weights, filtering, deduplication) act as continuous interventions affecting generalization, toxicity, and memorization. Fully retraining for each candidate mixture is cost-prohibitive. The authors propose learning a model predicting downstream performance as a function of corpus weights, utilizing continuous treatment effect estimation [Kennedy.2017], and orthogonalization-based hyperparameter optimization [Schroeder.2026]. This enables efficient search for optimal compositions under causal constraints.
Alignment and Preference Learning
Alignment (especially RLHF and DPO) relies on pairwise comparisons where the prompt, response pair, and annotator feedback constitute (X,A,Y) triples. Standard approaches like the Bradley-Terry (BT) model are vulnerable to misspecification—nontransitive preferences and cyclic patterns [Xu.2025]. Doubly-robust DML-based alignment yields increased data efficiency and validity [Xu.2025b, Frauen.2026]. Instrumental variable frameworks remove confounding in annotator feedback [Xia.2024], and semiparametric extensions address BT limitations [Kallus.2025, Li.2025, Spokoiny.2025].
Deployment: Routing, Multi-Agent Workflows, and Offline Policy Learning
Routing: Assigning queries to candidate models using historical logs is confounded by prior assignment policies. Causal adjustment is necessary to estimate regret-minimizing routing policies [Tsiourvas.2025].
Multi-Agent Workflows: Sequential decision-making (retrieval, tool-use, routing) imposes dynamic confounding and complex mediation structures. Off-policy evaluation techniques accommodating structured mediators and long-term rewards are crucial [Wu.2026, Dudik.2011, Kausik.2024]. RAG systems especially illustrate causal mediation effects across retriever and generator components [Leung.2026].
Offline Policy Learning: Choosing/generating text artifacts (prompts, rewrites) from logged interactions imposes a causal bandit structure with high-dimensional treatments, requiring treatment-effect estimation and policy learning under weak overlap and latent confounding [saito2022off, saito2023off, kiyohara2025off, Kramer.2026].
Evaluation of LLMs
LLM evaluation tasks—ranking models on target prompts—are fundamentally counterfactual: outcomes differ across assignments, conditioned on context. DML provides robust adjustment under contextual shifts, enabling valid confidence intervals even with learned nuisance models [Frauen.2026]. Automated evaluators introduce systematic biases (e.g., verbosity), necessitating debiasing frameworks combining large-scale judge scores with small human gold-standard samples (prediction-powered inference, PPI) [Angelopoulos.2023, van2026calibeating, Fisch.2024, Guerdan.2026]. Active data collection methods minimize annotation cost and maximize informative feedback [Cook.2024, Zrnic.2024, Angelopoulos.2025]. Causal log analysis is essential for evaluating agentic systems beyond terminal outcomes, allowing mediation and failure attribution [Kirgis.2026].
Safety Audits and Reward Identification
Tracing harmful behaviors to interventions in the pipeline (data bias, reward misspecification) is an identification problem. Reward discovery via inverse RL and partial identification yields distributions over plausible reward functions, enabling robust bounding of harmful action probabilities under deployment shifts [bou2026the, joselowitz2025insights]. Sensitivity analysis formally quantifies uncertainties in causal reward attribution.
Strong Claims and Contradictions
- The paper explicitly cautions against the belief that simply adding causal objectives to LLM training will produce genuine causal reasoning, asserting that such abilities require explicit identification assumptions (contradicting uncritical claims in prior works).
- The authors argue that causal methods are "potentially underutilized" in current LLM research, despite their ability to ensure reliability and scientific grounding in design.
- The paper asserts that evaluations solely with LLM judges are not identifiable for true user utility unless unbiased human references are available, regardless of the number of judged examples.
Implications and Future Directions
Practically, widespread adoption of causal methods can increase robustness, validity, and data-efficiency across LLM development, especially in the presence of non-stationary deployment, heterogeneous contexts, and sparse feedback. Theoretically, explicit causal modeling clarifies boundary conditions for inference, avoids spurious learning from artifacts, and enables principled evaluation of agentic workflows. Future directions include developing advanced off-policy evaluation and causal mediation techniques for sequential and agentic systems, sensitivity analysis for latent reward identification, and optimal evaluation schemes for complex pipelines.
Conclusion
This work formally situates causal inference as a principled foundation for LLM development and evaluation. By mapping causal modeling onto each pipeline stage and highlighting identifiability and estimation challenges, the authors motivate a research agenda for robust, scientifically grounded AI systems. The integration of causal methods promises to mitigate confounding, bias, and fragility, and will be increasingly important as LLMs are deployed in evolving, agentic, and high-stakes environments.