What is the objective of reasoning with reinforcement learning?
Abstract: We show that several popular algorithms for reinforcement learning in LLMs with binary rewards can be viewed as stochastic gradient ascent on a monotone transform of the probability of a correct answer given a prompt. In particular, the transformation associated with rejection sampling algorithms is the logarithm and that associated with the GRPO algorithm is the arcsine of the square root.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of “What is the objective of reasoning with reinforcement learning?”
1) What is this paper about?
The paper looks at how people fine‑tune LLMs using reinforcement learning (RL) when answers are simply marked “right” or “wrong.” The authors show that many popular RL methods are actually doing the same basic thing: they are trying to increase the chance that the model gives a correct answer to a prompt. The differences between methods mostly come from using different “scales” or “lenses” for measuring that chance.
In short: lots of RL tricks for LLMs boil down to “make correct answers more likely,” just measured through different math curves.
2) What questions are the authors asking?
The paper asks:
- Are common RL‑for‑LLM methods secretly optimizing the same goal?
- If so, what exact goal is each method pushing toward?
- Can we view each method as increasing some transformed version of “probability of a correct answer”?
- What does this view tell us about when RL can or cannot help?
Their main claim: these methods do stochastic gradient ascent (tiny nudges to the model parameters) on a function that is just a monotone transformation of “probability of being correct.” Different methods use different transformations, but the underlying goal is the same.
3) How do they study it? (Methods in simple terms)
Think of a simple training loop:
- You pick a question (a prompt).
- The model generates several candidate answers.
- An outside checker marks each answer as correct or incorrect.
- You update the model to make the good answers more likely next time.
In math terms, the model tries to increase , the probability it answers correctly for a given prompt . But each algorithm doesn’t always push on directly. Instead, it pushes on a transformed version (where is an increasing function). Examples of :
- Identity: (just the probability itself)
- Logarithm:
- Arcsine‑sqrt: (up to a constant scale)
To do this, each method assigns a weight to each sampled answer before updating the model. Those weights (often called “advantages”) tell the update how strongly to encourage or discourage the patterns that produced that answer. The authors prove that, on average, choosing certain weights is exactly the same as climbing the hill of a specific .
Two key examples:
- Rejection sampling fine‑tuning: only update using the correct answers. The authors show this corresponds to very close to .
- GRPO: normalizes updates using the variability of rewards, which the authors show corresponds to close to .
You don’t need to follow the heavy math; the idea is that by choosing how we weight samples, we choose which “curve” we climb.
4) What did they find and why does it matter?
Main findings:
- Many RL fine‑tuning methods for LLMs are just different ways to increase the probability of a correct answer. They differ mainly by which monotone curve they choose to climb.
- Vanilla REINFORCE (a classic RL method):
- Rejection sampling fine‑tuning:
- GRPO: (after a scaling)
- If your base model never produces correct answers, none of these methods can improve it. You need at least some chance of correctness to learn from.
- They give a general recipe: by choosing weights cleverly, you can target almost any smooth increasing curve you like. (They use a known math trick related to Bernstein polynomials to do this.)
- In the end, if your model is powerful enough and you can train it perfectly, the choice of doesn’t change the best possible solution: you’d still put (nearly) all probability on correct answers. But the choice of can change the learning dynamics—how fast and how smoothly you get there.
Why it matters:
- This gives a simple, unifying way to compare RL methods: not as different goals, but as different “rescalings” of the same goal (raise the chance of being correct).
- It clarifies debates like “Is GRPO better than REINFORCE?” by reframing them: they’re optimizing the same core thing with different emphasis, similar to how logistic loss and hinge loss both aim for good classification but with different scoring curves.
5) What are the implications?
- Unifying lens: Researchers can analyze and design RL fine‑tuning methods by asking: “What curve does this method climb?” That helps predict how the method will behave, especially at low, medium, or high accuracy levels.
- Practical guidance:
- No magic bullets: Picking GRPO vs. rejection sampling vs. REINFORCE won’t change the ultimate target—more correct answers—but can change training stability, speed, and sensitivity to rare successes.
- Start with a capable base model: If the model never gets anything right, RL fine‑tuning with right/wrong rewards won’t help.
- Tailor the “curve”: If you care more about improving from very low accuracy (say, going from 1% to 2%), a curve like can give stronger encouragement there. If you care about other regions (like mid‑range probabilities), choose a curve that emphasizes that region.
- Research impact: This framework makes it easier to invent new RL fine‑tuning methods on purpose, rather than by trial and error—pick the you want, then design the sample weights to match it.
In one sentence: The paper shows that many RL post‑training methods for LLMs are just different ways to boost the probability of being correct, viewed through different, but equivalent, lenses—so choose the lens that best suits your training needs and your model’s current skill level.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what the paper leaves unresolved and where further research could be most impactful:
- Lack of empirical validation: No experiments compare the practical performance of different rescalings h (e.g., identity, log, arcsin√t) across tasks, models, or datasets.
- No guidance on when a particular h is preferable: The paper does not provide theoretical or empirical criteria for choosing h to optimize training speed, stability, or sample efficiency.
- Convergence and stability analysis absent: There are no guarantees for stochastic gradient ascent under these estimators (e.g., conditions on step sizes, Lipschitz properties, convergence rates).
- Variance of gradient estimators with finite M not analyzed: The paper does not quantify the variance/bias trade-offs of different Z_i choices as a function of M and pθ(C|x), nor provide optimal M selection.
- Approximation error for GRPO not bounded: The gap between h_{M,ε} and its ideal limit h(t)=2/π·arcsin(√t) lacks uniform finite-M, finite-ε error bounds.
- Approximation error for rejection sampling’s h_M vs log(t) not fully quantified: While an expression is provided, tight, uniform bounds over t∈[0,1] and guidance for practical M are missing.
- Base model proficiency threshold is unquantified: The statement that the base model must “already perform nontrivially” lacks thresholds (e.g., minimal pθ(C|x)) or rates of progress as a function of initial accuracy.
- Ignoring KL regularization common in RLHF: The framework does not model or analyze KL penalties (e.g., PPO-style constraints); how J_h interacts with KL terms remains undetermined.
- Binary reward restriction: The analysis assumes R_i∈{0,1}; extensions to graded or continuous rewards (e.g., learned reward models) and their induced h are not developed.
- Token-level credit assignment not addressed: Real LLM fine-tuning typically applies per-token gradients; how the proposed objectives map to token-level reward shaping is left unexplored.
- Dependence on verifier reliability: Effects of label noise (false positives/negatives in C(x)) on bias, variance, and convergence are not analyzed; robust variants are not proposed.
- Handling massive or continuous answer spaces: Summation over y∈C(x) assumes a discrete tractable set; extensions to continuous or structured outputs and measurable C(x) are not covered.
- Practicality of rejection sampling for small pθ(C|x): Expected sample complexity/time to observe B successes and alternatives (e.g., importance sampling, adaptive B, stratified sampling) are not studied.
- Interaction with decoding strategies: The effect of temperature, nucleus/top-k sampling, beam search, or mixture-of-temps (off-policy sampling) on the unbiasedness and efficiency of the estimators is not analyzed.
- Impact of corpus composition and prompt weighting: The framework assumes a fixed distribution Q but does not explore importance weighting, curriculum learning, or adaptive per-prompt rescalings h_x.
- Generalization and overfitting to the verifier: Maximizing pθ(C|x) may exploit verifier idiosyncrasies; effects on out-of-distribution performance and robust generalization are not examined.
- Multiple correct answers with heterogeneous utility: C(x) may contain answers with differing desirability; the framework does not incorporate preferences among correct answers.
- Multi-step reasoning and intermediate rewards: Chain-of-thought, step-level verification, and reward shaping over trajectories (not just final answers) are not integrated into the analysis.
- Guidance on designing Bernstein coefficients under constraints: The recipe to approximate h′ via Bernstein polynomials does not address practical coefficient choices that minimize estimator variance or computational cost for small M.
- Quantifying estimator variance across Z_i families: Systematic comparison of variance, bias, and signal-to-noise across the proposed conditional-linear Z_i forms is missing.
- Numerical stability near t→0 for log scaling: Potential gradient explosion and instability for J_log when pθ(C|x) is tiny are not analyzed; safeguards or regularizers are not proposed.
- Off-policy correction and importance weights: If sampling deviates from πθ (e.g., safety filters, hybrid decoders), unbiasedness and corrections are not discussed.
- Task types without well-defined C(x): For open-ended tasks (summarization, creative writing) with fuzzy correctness, how to define C(x) and the implications for J_h are left unresolved.
- Skip-step policy when no correct answers: The effect of skipping updates on convergence dynamics, bias, and sample efficiency is not analyzed; alternative strategies are not compared.
- Computational and memory considerations: The cost of large M, variance normalization, and scaling to long sequences is not addressed; practical trade-offs are unclear.
- Effect of monotone h on optimization dynamics across prompts: While global optima are invariant to monotone rescaling for expressive models, local training dynamics and sample efficiency differences across tasks are not characterized.
- Relationship to existing RLHF objectives beyond GRPO/REINFORCE: How other widely used methods (e.g., PPO with reward models, DPO variants) fit into this monotone-rescaling framework is not mapped out.
- Benchmarks and evaluation protocols: No proposed metrics or standardized settings to compare different h choices in terms of training speed, sample efficiency, stability, or final accuracy.
Practical Applications
Overview
This paper shows that many reinforcement learning (RL) post-training methods for LLMs with binary rewards (e.g., “correct” vs. “incorrect”) are equivalent to stochastic gradient ascent on a monotone transform of the probability of correctness conditioned on a prompt. Concretely:
- Rejection sampling fine-tuning approximates optimizing the log of the correctness probability.
- GRPO approximates optimizing an arcsine-square-root transform of the correctness probability.
- A general recipe maps any desired monotone transform h to implementable advantage weights via a Bernstein polynomial construction.
This unified perspective enables practical choices about objectives, instrumentation, and algorithm design in RLHF/RLAIF pipelines. Below are applications that can be acted on now and those that require further research and scaling.
Immediate Applications
The following items can be implemented with current tooling and infrastructure.
- RLHF objective transparency and instrumentation (industry, academia; software)
- What to do: Instrument training pipelines to estimate and track pθ(C|x) (the probability of correctness) and the implied h being optimized (identity, log, arcsin√, log-odds, etc.). Log the effective hM induced by chosen weights Z_i (including M and ε for GRPO) and monitor training as monotone rescaling of correctness probability.
- Tools/products/workflows: “Correctness Probability Monitor” integrating with PyTorch/TensorFlow training loops; dashboards showing per-domain pθ(C|x) distributions and h-curves.
- Assumptions/dependencies: Requires reliable binary evaluation (autograder, verifier, human labelers). The base model must have nonzero probability of producing correct answers.
- Advantage weight composer library for RLHF/RLAIF (industry, academia; software)
- What to do: Build a modular library that, given a desired h, generates advantage weights Z_i via the Bernstein polynomial recipe (Section reweightings), including variants that approximate log, log-odds, or arcsin√ transforms.
- Tools/products/workflows: “Objective Composer” package with ready-made advantage policies (REINFORCE, GRPO, rejection sampling, BNPO-like beta-based normalizations) and a function-to-weights compiler.
- Assumptions/dependencies: Requires sampling M responses per prompt and access to per-sample binary rewards; relies on independence assumptions used in the derivations.
- Rejection sampling fine-tuning for autogradable tasks (industry; software, coding assistants, math)
- What to do: For domains with robust automatic correctness checks (e.g., code generation with unit tests, equation solving with verifiers), use the rejection sampling update that averages gradients over correct samples to approximate optimizing J_log.
- Tools/products/workflows: “Rejection Sampling FT” plug-in for code LLMs (run unit tests; only update on passing outputs); math tutors with exact-checkers.
- Assumptions/dependencies: Requires sufficiently high pθ(C|x) to find correct samples in reasonable time; autograder quality (low false positives/negatives) strongly affects feasibility.
- Practical GRPO tuning via the h-perspective (industry, academia; software)
- What to do: Use M and ε as explicit “objective shape” knobs. Small ε and larger M approximate the arcsin√ transform; larger ε moves toward identity (REINFORCE). Select schedules based on observed pθ(C|x): e.g., increase ε early to stabilize when p is low, reduce ε later to accentuate gradients as p rises.
- Tools/products/workflows: “GRPO Objective Shaper” with suggested ε/M schedules keyed to pθ(C|x) bands; automated ablation harnesses.
- Assumptions/dependencies: Requires reliable measurement of sample reward variance; assumes binary rewards and correct normalization mechanics.
- Data triage and curriculum gating by correctness probability (industry, academia; education, software)
- What to do: Filter or stage prompts where pθ(C|x) is too low to be learnable by binary-reward RLFT (as the paper notes, no algorithm can progress if no correct samples can be found). Defer these prompts to supervised data collection or augmentation.
- Tools/products/workflows: “Curriculum Gate” that estimates pθ(C|x) and routes prompts to RLFT vs. supervised augmentation; active data collection for rare-correctness prompts.
- Assumptions/dependencies: Needs quick pθ(C|x) estimators (batch sampling); relies on available supervised or synthetic data pathways for too-hard items.
- Standardized reporting of RLHF objectives for transparency (policy, industry, academia)
- What to do: Include the objective transform (h), sampling regime (M, ε), and verifier specs in model cards and RLHF documentation to clarify what is being optimized and under what evaluation assumptions.
- Tools/products/workflows: “RLHF Transparency Report” templates; compliance-ready metadata fields.
- Assumptions/dependencies: Requires consensus on reporting standards; hinges on the organization’s ability to summarize verifier reliability.
- Education pipelines with autograding FT (industry, academia; education)
- What to do: Build domain-specific corpora of autograded questions (math, programming exercises) and apply RS/GRPO updates to improve correctness while tracking pθ(C|x).
- Tools/products/workflows: Learning platform integrations with autograders; scheduled RS updates; real-time dashboards of correctness probability per skill.
- Assumptions/dependencies: High-quality autograders; careful handling of multi-answer correctness sets C(x).
Long-Term Applications
These items require further research, scaling, or development beyond current practice.
- Adaptive objective scheduling (h-schedules) across training phases (industry, academia; software)
- What to do: Develop schedulers that adapt h over time (e.g., identity → arcsin√ → log/log-odds) to stabilize early training and amplify gradients as the model improves, guided by pθ(C|x) estimates.
- Tools/products/workflows: “Objective Scheduler” for RLHF pipelines with policy-driven transitions in Z_i and sampling parameters.
- Assumptions/dependencies: Requires robust measurement and control of optimization dynamics; needs empirical validation for stability and generalization.
- Objective composer for domain- and risk-specific h (industry, academia; healthcare, finance, legal)
- What to do: Design h functions reflecting domain risk profiles (e.g., harsh penalties for low correctness in safety-critical tasks via log-odds-like transforms) and compile them into advantage weights via Bernstein approximation.
- Tools/products/workflows: Domain-specific objective catalogues; governance layers for objective choice and audits.
- Assumptions/dependencies: Strong, reliable verifiers; careful calibration to avoid pathological optimization when pθ(C|x) is near 0 or 1; regulatory alignment.
- Reward evaluation infrastructure as a service (industry; software, education, coding, math)
- What to do: Build scalable “verification engines” for binary correctness in more domains (e.g., broader code testing, theorem checking, fact verification), enabling practical RS/GRPO-style RLFT.
- Tools/products/workflows: “Autograder-as-a-Service” with APIs; test synthesis; coverage analysis; correctness attestation.
- Assumptions/dependencies: Coverage and reliability of verifiers; domain complexity; guarding against adversarial exploitation.
- Benchmarking and guidelines for choosing h (academia, policy; cross-sector)
- What to do: Systematically compare rescalings (identity, arcsin√, log, log-odds, beta-CDF variants) across tasks to establish when choice of h materially affects outcomes and optimization stability.
- Tools/products/workflows: Shared benchmarks with binary rewards; community best-practices documents.
- Assumptions/dependencies: Task diversity; standardization of evaluation; openness of training logs for reproducibility.
- Safety-critical RLHF frameworks with rigorous verification (industry, policy; healthcare, finance, legal)
- What to do: Couple the h-based RLFT with high-assurance verifiers and formal governance (e.g., approved objective transforms, audit trails) for domains where correctness and compliance are paramount.
- Tools/products/workflows: Regulated pipelines; audit tooling reporting h, M, ε, verifier specs and failure modes.
- Assumptions/dependencies: Mature verification technology; regulatory acceptance; extensive testing for distribution shifts.
- Multi-label and nuanced correctness modeling (academia, industry; education, knowledge systems)
- What to do: Extend binary reward setups to richer correctness sets C(x) and multi-label structures, analyzing how h interacts with multiple “correct” outputs and ambiguity.
- Tools/products/workflows: Verifiers that enumerate or score multiple valid outputs; objective shaping for multi-label distributions.
- Assumptions/dependencies: Availability of ground-truth sets; careful handling of partial credit and non-binary grading.
- Fairness- and distribution-aware rescaling (academia, policy; cross-sector)
- What to do: Study whether monotone rescaling shifts emphasis across subpopulations or prompt types; design corpus-level weighting and fairness-aware objective composition to avoid systematic neglect or overemphasis.
- Tools/products/workflows: “Fairness Objective Composer” that combines h choices with corpus weights; diagnostic tooling for subgroup pθ(C|x).
- Assumptions/dependencies: Access to subgroup labels and fairness criteria; verifiers without biased error patterns.
- Extending the framework beyond single-turn binary rewards (academia; software, robotics)
- What to do: Generalize the h-transform perspective to multi-step reasoning, partial-credit rewards, and non-binary signals; analyze credit assignment and variance reduction under richer reward structures.
- Tools/products/workflows: Multi-turn RLHF variants with structured evaluation; theoretical tools for non-binary reward transforms.
- Assumptions/dependencies: New derivations beyond binary rewards; scalable evaluation for complex tasks.
Notes on feasibility across applications:
- The base model must already achieve nontrivial correctness (pθ(C|x) > 0) for RLFT to make progress.
- Reliable verification engines are the core dependency; weak or biased evaluators undermine the objectives.
- The practical effect of h choice is task- and data-dependent; while objectives are monotone transforms of correctness probability, optimization dynamics and compute costs differ materially.
- Large M (samples per prompt) and small ε improve approximation to target h but increase compute; schedules can balance cost and stability.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example.
- Advantage (RL): A weighting factor applied to sampled actions to adjust gradient updates based on how good an outcome is relative to a baseline. "The weights are often called advantages in the RL literature."
- Approximate dynamic programming: Methods that approximate solutions to dynamic programming problems, commonly used in reinforcement learning to handle large or complex state spaces. "Though traditionally associated with sophisticated tree search and approximate dynamic programming, reinforcement learning takes on a unique character in the post-training of LLMs."
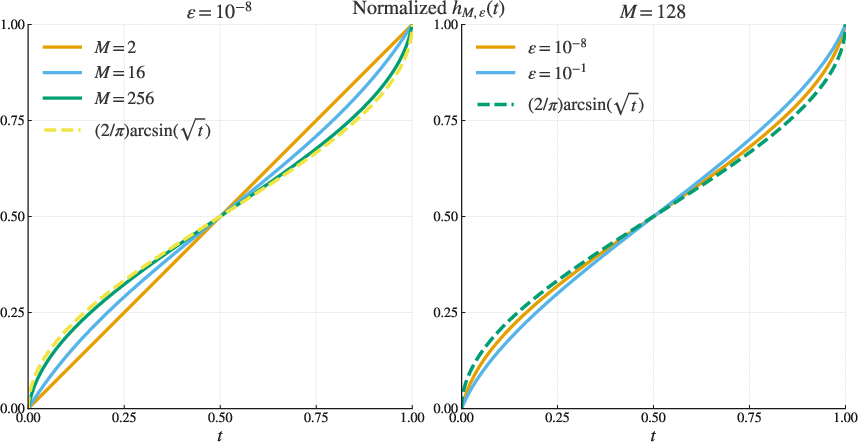
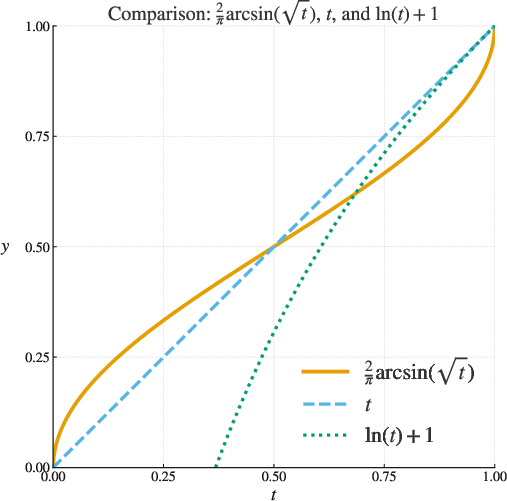
- Arcsine of the square root: A nonlinear transform given by , used as an objective scaling in some RL finetuning methods. "In particular, the transformation associated with rejection sampling algorithms is the logarithm and that associated with the GRPO algorithm is the arcsine of the square root."
- Bernstein polynomial: A polynomial form used for approximating continuous functions, forming a basis with good convergence properties on . "the derivative of in~\eqref{eq:costm} is a Bernstein polynomial, which provides a basis in which to approximate any continuous function:"
- Bernstein polynomial expansion: Expressing a function as a sum of Bernstein basis polynomials to approximate it over an interval. "It turns out the answer is related to the Bernstein polynomial expansion of ; we discuss this in Section~\ref{sec:conclusion}."
- Beta distribution: A continuous probability distribution on parameterized by two shape parameters, often used to model probabilities and proportions. "rescalings based on normalizing by the pdf of the beta distribution have also been considered, e.g., in~\cite{xiao2025bnpo} and their associated loss functions which approximate the corresponding cdfs of the beta distribution can be deduced from~\ref{sec:reweightings}."
- Binomial distribution: A discrete distribution giving the number of successes in a fixed number of independent Bernoulli trials with the same success probability. "Averaging over , we find that"
- Cp (smoothness class): The class of functions that are p-times continuously differentiable. "if e.g., is for ."
- Conditional distribution: A probability distribution of a random variable given the value of another variable. "Say our goal is to fit a conditional distribution to a set of example input-output pairs ."
- Cumulative distribution function (CDF): A function that maps a value to the probability that a random variable is less than or equal to that value. "rescalings based on normalizing by the pdf of the beta distribution have also been considered, e.g., in~\cite{xiao2025bnpo} and their associated loss functions which approximate the corresponding cdfs of the beta distribution can be deduced from~\ref{sec:reweightings}."
- GRPO (algorithm): A reinforcement learning finetuning method for LLMs that normalizes policy gradients by reward variance or standard deviation. "The GRPO algorithm~\citep{shao2024deepseekmath} is another renormalization of the sampled gradients."
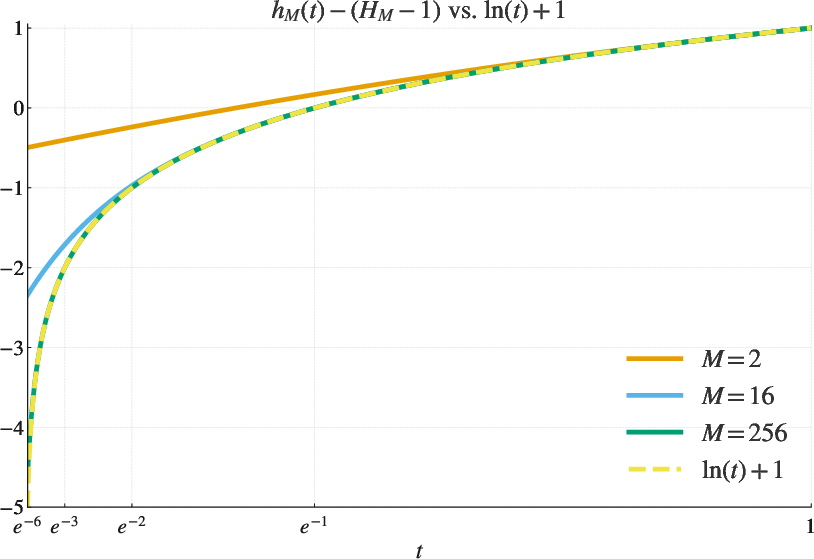
- Harmonic number: The sum of reciprocals of the first M positive integers, . "where is the th harmonic number; see Figure~\ref{fig:log}."
- Hinge loss: A loss function used primarily in support vector machines, penalizing misclassified points and those within the margin. "Thus, arguing whether GRPO or REINFORCE is best is like arguing whether log loss is better than hinge loss for classification problems."
- Leave-one-out: A technique where one item is excluded from a set to compute a statistic, often used for variance reduction or independence arguments. "Specifically, define rewards and the leave-one-out total rewards ."
- Log odds: The logarithm of the odds ratio, , often used for probabilistic modeling and classification. "replacing the standard deviation by the variance in GRPO yields a function close to the log odds rescaling: ."
- Log trick: A technique in probability and RL used to convert gradients of probabilities into expected gradients of log-probabilities. "We use an analysis that mimics the log trick used to derive Williams' REINFORCE algorithm."
- Log-loss: The negative log-likelihood objective used in probabilistic supervised learning. "This algorithm maximizes the standard log-loss objective~\eqref{eq:log-loss}."
- Maximum likelihood estimator (MLE): A parameter estimate that maximizes the likelihood of observed data under a statistical model. "the global objective does not have a natural interpretation as a maximum likelihood estimator unless there is a single correct answer in ."
- Monotone rescaling: Applying a strictly increasing transformation to an objective, preserving ordering but changing optimization dynamics. "So again, like the rejection sampling algorithm from Section~\ref{sec:rejection}, the GRPO algorithm is optimizing a monotone rescaling of the probability of achieving a correct answer."
- Monotone transform: A strictly increasing function applied to a quantity, maintaining order while altering scale. "can be viewed as stochastic gradient ascent on a monotone transform of the probability of a correct answer given a prompt."
- Multilabel problem: A supervised learning setting where each input can have multiple correct labels. "The objective is more analogous to the multilabel problem in supervised learning where many labels can be counted as correct for a particular example data-point."
- Policy gradient: A class of RL algorithms that optimize policy parameters by estimating gradients of expected returns. "Williams' REINFORCE algorithm and other policy gradient algorithms have enough degrees of freedom that understanding what they do when applied to particular optimization problems is not always transparent."
- Probability density function (PDF): A function that describes the relative likelihood of a continuous random variable taking on a particular value. "rescalings based on normalizing by the pdf of the beta distribution have also been considered, e.g., in~\cite{xiao2025bnpo} and their associated loss functions which approximate the corresponding cdfs of the beta distribution can be deduced from~\ref{sec:reweightings}."
- Regularized incomplete beta function: The cumulative distribution (CDF-like) function associated with the beta distribution, often used in integrals over the unit interval. "where is the regularized incomplete beta function."
- REINFORCE (algorithm): A foundational policy gradient method that uses sampled returns to form an unbiased gradient estimator. "Williams' REINFORCE algorithm"
- Rejection sampling: A sampling technique that draws from a target distribution by accepting samples from a proposal distribution based on a criterion. "This can be achieved by rejection sampling, which falls slightly outside of Algorithm 1."
- Stochastic gradient ascent: An optimization method that updates parameters using noisy gradient estimates to maximize an objective. "We show that several popular algorithms for reinforcement learning in LLMs with binary rewards can be viewed as stochastic gradient ascent on a monotone transform of the probability of a correct answer given a prompt."
- Sup norm: The maximum absolute difference (uniform norm) between functions over an interval. "In this case the derivative converges in the norm at a rate $1/M$, and the same result holds for by the fundamental theorem of calculus~\citep{adell2022asymptotic}."
- Variance reduction: Techniques to decrease the variability of gradient estimates or estimators, improving optimization stability and efficiency. "Typically, algorithm designers motivate the choice of by appealing to variance reduction."
Collections
Sign up for free to add this paper to one or more collections.