- The paper introduces V-GRPO which reformulates ELBO-based surrogates into stable RL objectives for diffusion models.
- It employs group-shared noise control, stratified sampling, and adaptive loss weighting to reduce variance and enhance convergence.
- Empirical results show V-GRPO achieves state-of-the-art performance with significant speedups over traditional MDP-based methods.
V-GRPO: Online RL for Denoising Generative Models with Stable ELBO-based Surrogates
Introduction and Context
The alignment of denoising generative models—especially diffusion and flow-matching models—with human preferences or external reward functions poses a significant challenge, primarily due to the intractability of exact model likelihoods required by policy-gradient-based online reinforcement learning (RL) frameworks. Existing literature circumvents this limitation through either Markov decision process (MDP) factorization, enabling sequential optimization, or via likelihood surrogates rooted in the evidence lower bound (ELBO). However, prior work reports underperformance of ELBO-based approaches on visual generation tasks and high complexity/inefficiency for MDP-based liftings.
"V-GRPO: Online Reinforcement Learning for Denoising Generative Models Is Easier than You Think" (2604.23380) introduces a principled reformulation that directly integrates tractable, pretraining-aligned ELBO-based surrogates into RL for diffusion models, yielding substantial improvements in training efficiency and stability. By combining the Group Relative Policy Optimization (GRPO) algorithm with targeted variance-reduction and gradient-regularization strategies, the authors demonstrate state-of-the-art results across multiple reward functions and datasets, outperforming or matching methods like MixGRPO and DiffusionNFT with significant speedups.
Background: Denoising Generative Models and Policy Optimization
Denoising generative models such as diffusion and flow-matching architectures are built upon continuous or discretized forward processes transforming target data to noise, and vice versa via learned neural networks parameterizing a reverse (denoising) dynamic. Training objectives are typically framed as weighted regression tasks, with common parameterizations including ϵ- (noise), x- (data), and v- (residual) predictions.
Notably, GRPO operates without a value function, using groupwise normalized advantages across a set of sampled outputs. This setup necessitates evaluating importance ratios between current and reference policies, which in standard policy gradient setups would require tractable model likelihoods. For diffusion models, direct marginal likelihood access is intractable, traditionally leading to either (a) sequential MDP liftings with per-timestep kernels, or (b) surrogate objectives such as the negative ELBO.
However, direct use of negative ELBO surrogates historically suffers from instability and lackluster sample quality in visual domains.
V-GRPO: Methodology
The central contribution of V-GRPO is the demonstration that stabilization and variance control transform ELBO-based surrogates into highly effective RL objectives for denoising generative models. The method replaces the marginal output likelihood in GRPO with a Monte Carlo estimate of the ELBO-based loss, leveraging the regression pretraining objective as a tractable control variate.
Key Stabilization Techniques
Surrogate Variance Reduction
- Group-shared Timestep-Noise Pairs: For each prompt, a fixed set of (tj,ϵj) pairs is sampled and applied across all outputs, anchoring the surrogate basis and reducing intra-group stochastic variance.
- Stratified Timestep Sampling: Instead of uniform sampling, the timestep schedule is partitioned and sampled representatively per interval, regularizing contributions across the denoising trajectory.
- Adaptive Loss Weighting: Losses are self-normalized using the x-prediction parameterization, aligning gradient scales across variable noise and denoising levels.
These interventions collectively reduce the coefficient of variation of surrogate magnitudes from 0.230 to 0.128 and attenuate the correlation between surrogate magnitudes and gradient norms.
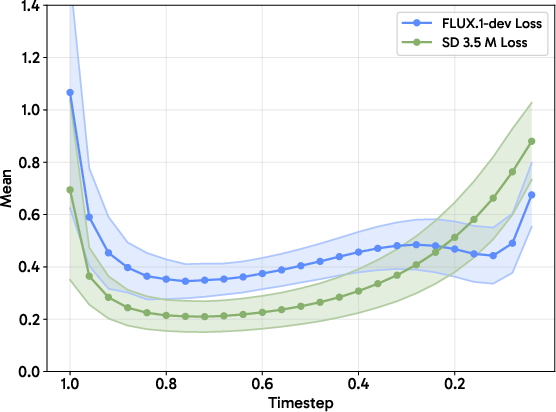
Figure 1: Per-sample loss exhibits significant timestep-dependent variance, motivating group-shared noise/timestep control to stabilize optimization.
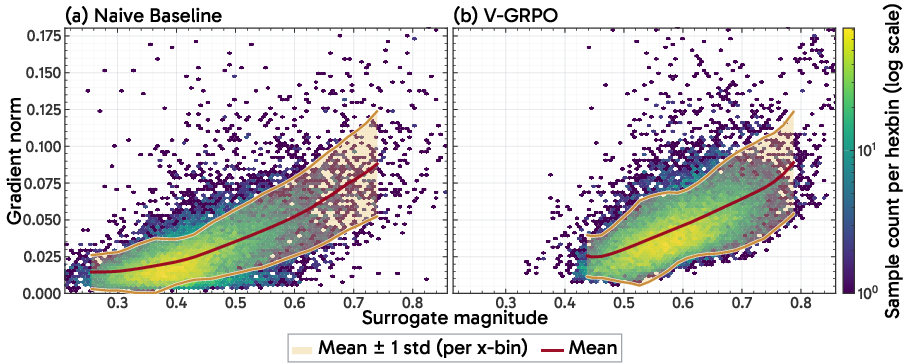
Figure 2: Gradient norm scale is tightly coupled with surrogate loss magnitude; controlling this variance is critical for stable RL training in denoising models.
Gradient Step Regulation
- Importance Ratio Clipping: Applies standard PPO-style clipping to stabilize policy updates.
- KL Penalty: Regularizes against divergence from the previous policy, with a computationally efficient, ELBO-aligned KL that avoids maintaining a second network.
- Advantage Soft-Clipping: Uses tanh-based bounding for advantages, effective in on-policy regimes or when limited sampling steps preclude reliable off-policy ratios.
Selection among these regularization tools is scenario-dependent, e.g., KL penalty for capability retention, soft-clipping in on-policy/low-data settings, and ratio clipping otherwise.
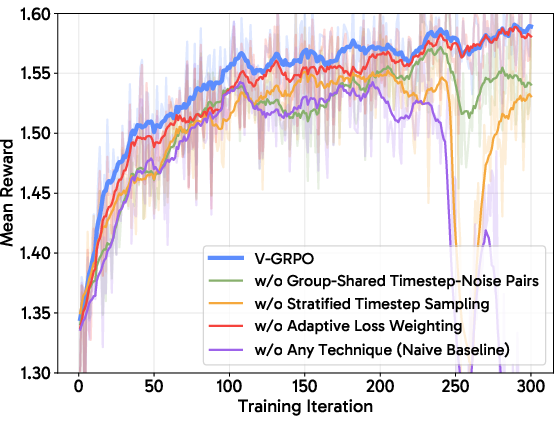
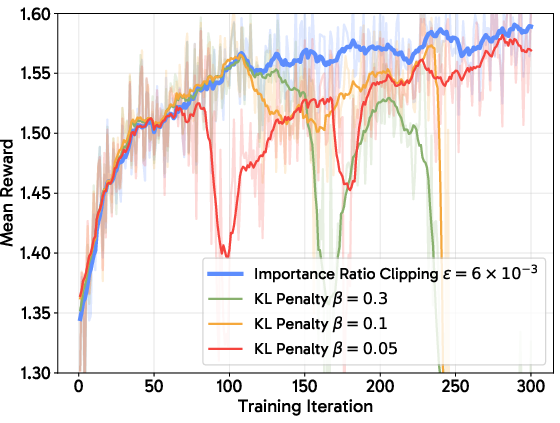
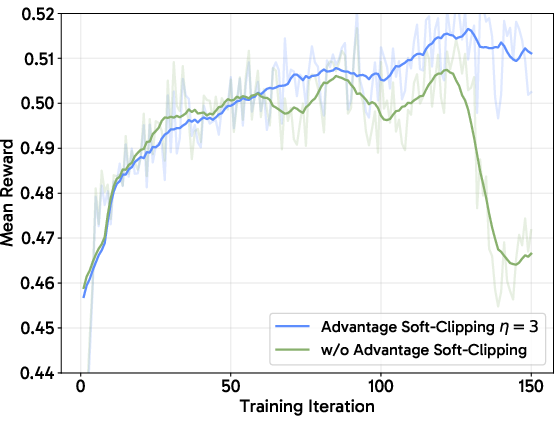
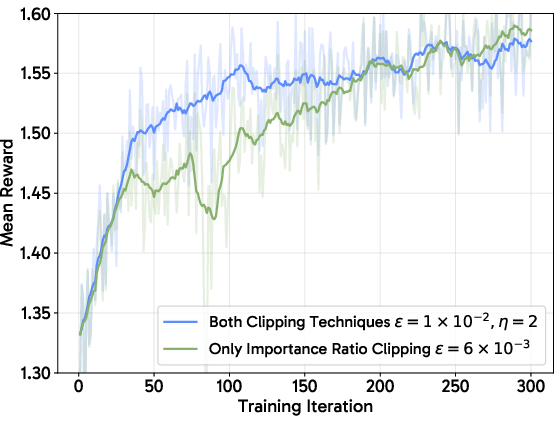
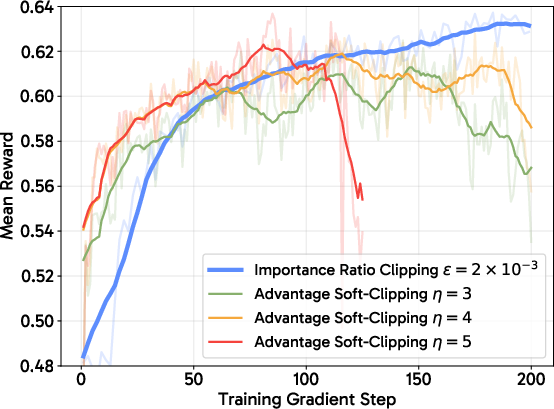
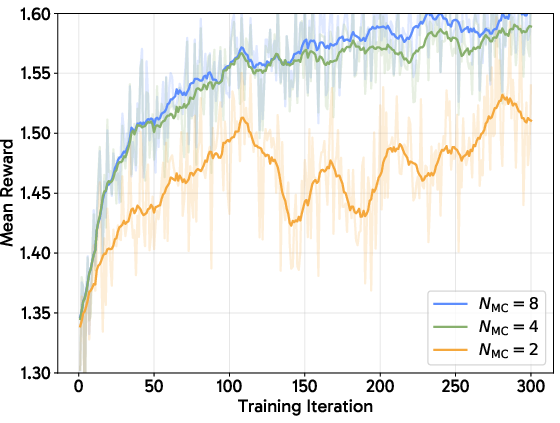
Figure 3: Training FLUX.1-dev without variance reduction techniques leads to divergence or highly unstable progression, confirming the necessity of these strategies.
Empirical Evaluation
Dataset and Baseline Setup
Experiments are carried out on FLUX.1-dev (a guidance-distilled flow model without CFG) and SD 3.5 M (Stable Diffusion variant). Both rule-based (e.g., GenEval, OCR) and model-based (e.g., HPSv2.1, PickScore, UnifiedReward) reward functions are used. Training and evaluation adopt prompt sets and reward normalizations standardized in recent baselines.
Main Quantitative Results
V-GRPO establishes new state-of-the-art results in multi-reward text-to-image synthesis, outperforming MixGRPO by up to 2× in convergence speed and DiffusionNFT by 3× in gradient step count, while requiring fewer function evaluations per update.

Figure 4: Qualitative comparison of FLUX.1-dev: V-GRPO samples exhibit enhanced alignment, text rendering, and style fidelity absent of explicit task-specific reward tuning.

Figure 5: SD 3.5 M main experiment comparison: V-GRPO matches or exceeds baseline performance in coherence, alignment, and stylistic control.
Ablation studies confirm that all surrogate variance reduction components are necessary for optimal performance in less robust models (e.g., FLUX.1-dev), while for inherently robust architectures (e.g., SD 3.5 M), each technique is beneficial but individually less critical.
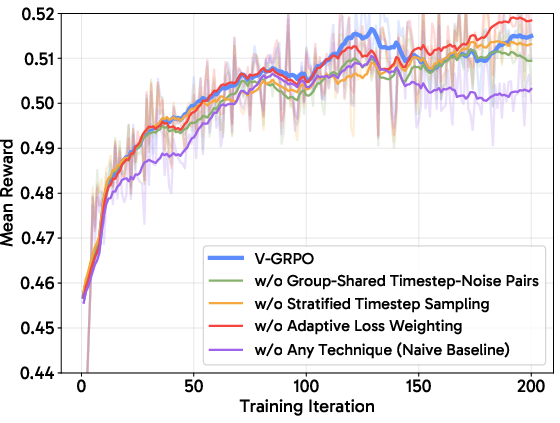
Figure 6: Ablation of surrogate variance reduction on SD 3.5 M; cumulative effect preserves stability, but model robustness mitigates the impact of individual removals.
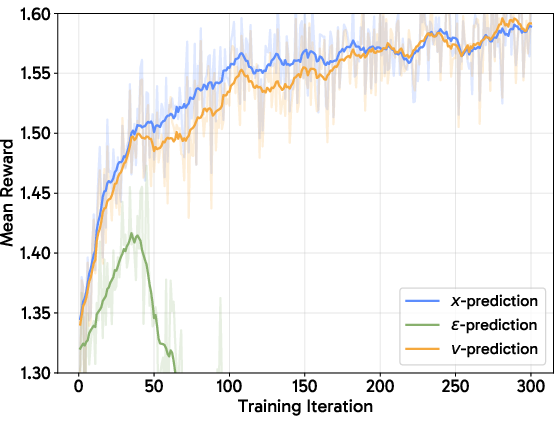
Figure 7: Parameterization of the adaptive loss: x-prediction leads to stable, fast convergence versus collapse for ϵ-prediction.
Regularization, Curriculum, and Hyperparameter Analysis
Advantage soft-clipping stabilizes fully on-policy regimes and low-sample rollouts, while KL penalties improve capability retention across training stages, especially when reward functions shift. Nevertheless, in coarse-reward settings, classic ratio clipping continues to be optimal.
The step count and NFE (number of function evaluations) analysis demonstrates that V-GRPO achieves comparable or higher final reward scores using significantly less compute compared to established baselines.
Theoretical and Practical Implications
The work decisively demonstrates that the prior underperformance of ELBO-based RL surrogates in diffusion models was not an inherent limitation, but rather the product of unchecked estimator variance and suboptimal regularization. Integrating standard pretraining objectives into online RL now becomes not only viable but state-of-the-art, greatly simplifying post-training pipelines.
Practically, this permits tighter integration of pretraining and preference/reward fine-tuning, leveraging second-order samplers and removing the requirement for complex SDE-based MDPs. The approach is architecture-agnostic: it seamlessly accommodates modern flow and diffusion models (including rectified flow and guidance-distilled models), making it broadly relevant.
Theoretically, the results reinforce the variational equivalence among denoising generative models under shared forward processes. The ELBO surrogate’s utility as both a likelihood proxy for RL and a regularizer for policy similarity points to fruitful avenues for unifying variational inference, RL, and generative modeling.
Future Developments
Potential future directions include:
- Extension to Multi-modal and Sequential Domains: Application beyond vision to audio, video, and other complex output spaces.
- Automated Regularization Selection: Dynamic adaptation of variance control and regularization strategies based on model diagnostics.
- Scalable Multi-reward and Human-in-the-loop Training: Harnessing human feedback and diverse reward models in RL-aligned diffusion architectures.
- Theoretical Analysis: Exploring convergence rates, generalization, and robustness properties of ELBO-based surrogates in high-dimensional RL.
Conclusion
V-GRPO establishes ELBO-based RL as a tractable, efficient, and highly performant method for aligning denoising generative models with external rewards. By positioning the pretraining objective as the central optimization target and applying judicious variance-reduction and gradient control, V-GRPO outperforms or matches more complex MDP-based baselines with substantial gains in sample and computational efficiency. These results position stabilized ELBO-based optimization as the natural default for future post-training of large generative models, with broad implications for the integration of reinforcement learning and generative modeling.

