- The paper demonstrates that post-training stages (CPT, SFT, and RL) uniquely impact both in-domain and out-of-domain performance in biological reasoning models.
- Supervised fine-tuning improves ID accuracy but causes over-specialization, while reinforcement learning effectively recovers and enhances OOD robustness.
- Stage-specific adaptation capacity, particularly through asymmetric LoRA allocation, is crucial for balancing performance trade-offs across genomic, transcriptomic, and proteomic tasks.
Post-Training Dynamics in Biological Reasoning Models
Overview of Post-Training Composition and Generalization Regimes
"How Post-Training Shapes Biological Reasoning Models" (2606.16517) presents an extensive empirical and conceptual analysis of scientific reasoning models in biology, focusing on how continued pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning (RL) distinctly impact model generalization across genomics, transcriptomics, and proteomics. The study utilizes controlled experiments over more than 100 models, systematically varying backbone selection, post-training allocation, and LoRA adaptation capacity. Both in-domain (ID) and out-of-domain (OOD) performance are evaluated using biologically meaningful splits across three benchmark tasks: pathway prediction, drug target identification, and protein function prediction.
The authors establish that post-training stages are not additive in their contributions—each stage alters the generalization landscape non-monotonically. CPT aligns the model with biological language and enhances downstream adaptation. SFT reliably improves ID accuracy but induces overspecialization, resulting in progressive OOD accuracy degradation. RL, deployed from robust SFT checkpoints with task-specific rewards, consistently recovers and enhances OOD robustness, shifting the generalization frontier.
Figure 1: Distinct generalization regimes arise from backbone choice, CPT, SFT, and RL, evaluated ID and OOD across DNA, RNA, and protein tasks.
Supervised Fine-Tuning: Overfitting and Trade-Offs
SFT demonstrates marked improvements in ID performance, yet at the cost of OOD robustness. With increased training epochs or data, ID accuracy follows a monotonically rising trajectory, whereas OOD performance peaks prematurely and subsequently declines. The induced trade-off is robust across modalities and model sizes, exemplified numerically in DNA with ID accuracy climbing from $0.68$ to $0.90$ as epochs increase, but OOD accuracy peaking near $0.73$ and receding thereafter. RNA and protein tasks exhibit analogous trends.
ID gains from scaling data (rather than epochs) yield more stable OOD improvements but are subject to diminishing returns, plateauing rapidly after an initial phase. This over-specialization reflects a shift from generality toward distributional specificity.
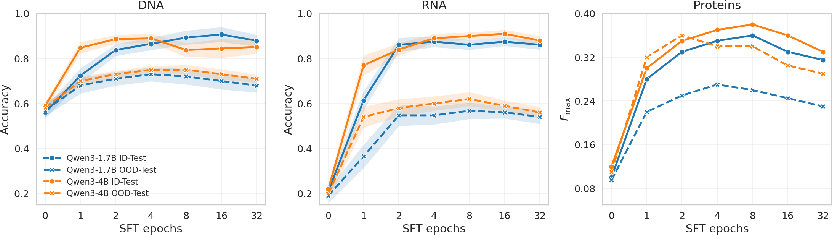
Figure 2: SFT increases ID performance but reduces OOD robustness; OOD peaks early and declines with continued fine-tuning, indicating over-specialization.
Reinforcement Learning: OOD Robustness Recovery
RL, initialized from strong SFT checkpoints, alters the ID-OOD trade-off, primarily enhancing OOD performance. RL shifts the generalization frontier efficiently—most OOD gains are realized in the earliest RL epochs, with diminishing marginal returns beyond those. RL is consistently superior in restoring OOD robustness lost during SFT, with improvements of up to $0.08$ in absolute OOD Fmax in protein tasks.
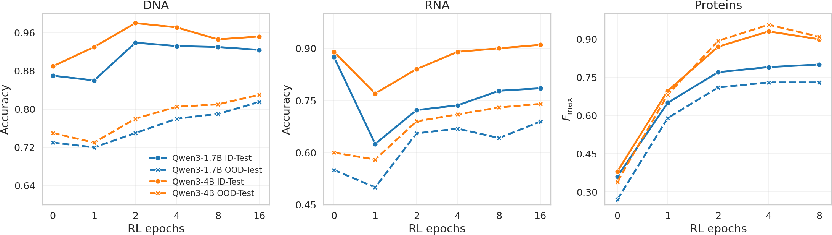
Figure 3: RL increases both ID and OOD performance, with largest OOD gains and diminishing returns after the first few epochs.
Continued Pre-Training: Foundation for Effective Adaptation
Pre-training on domain-relevant biological corpora (CPT) proves critical, especially for smaller backbones. CPT enhances both SFT and RL stages—downstream gains are maximized after RL, particularly OOD. CPT increases effectiveness by aligning models with biological language, thereby facilitating subsequent post-training adaptation.
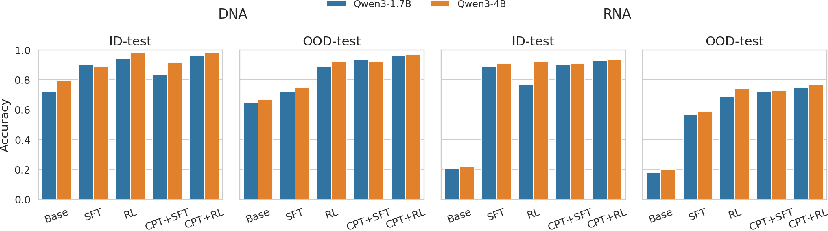
Figure 4: CPT improves SFT and RL, with large OOD gains after RL when adapted to biological language prior to post-training.
Adaptation Capacity: Stage-Specific LoRA Allocation
Optimal adaptation requires asymmetric LoRA rank allocation. SFT benefits from high-rank adapters, capturing task structure and reasoning complexity, while RL achieves comparable gains with significantly lower ranks. This asymmetric strategy is empirically validated across RNA and DNA, demonstrating that effective post-training pipelines must tailor adaptation capacity to the demands of each stage.
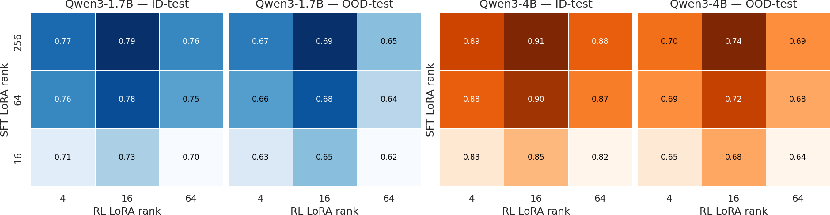
Figure 5: Higher LoRA rank is essential for SFT, but the RL stage requires only low-rank adaptation for optimal ID and OOD performance.
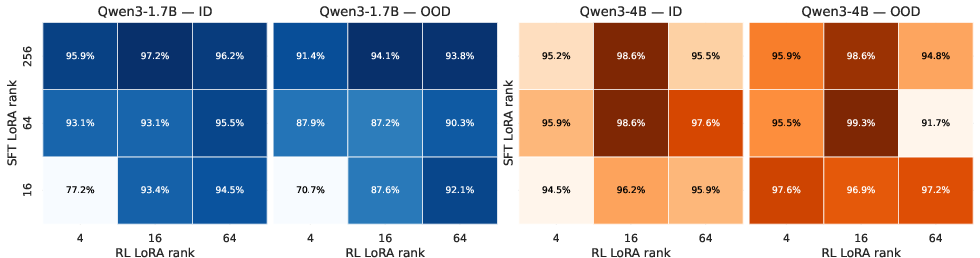
Figure 6: Results in pathway prediction (DNA) tasks confirm asymmetric LoRA allocation across SFT and RL.
Training Dynamics Across Modalities and Backbones
Strong backbones (e.g., Gemma 4 E2B, Qwen3-4B) raise the absolute performance ceiling but retain the qualitative ID-OOD trade-offs induced by SFT and RL. RL has more robust and monotonic improvements with larger models, with OOD accuracy rising by up to $0.15$ across RL epochs. The structure of training dynamics—ID gains from SFT, OOD gains from RL—remains consistent across modalities and architectures.
Fixed-Budget Post-Training: SFT–RL Allocation
Under fixed epoch or data budgets, optimal ID-OOD trade-offs arise from brief SFT followed by extensive RL. Maximum OOD accuracy is achieved with 1–3 SFT epochs preceding RL, whereas greater SFT allocations favor ID accuracy but compromise OOD performance. RL without a supervised warm start performs significantly worse, indicating the necessity for sequential stage allocation.
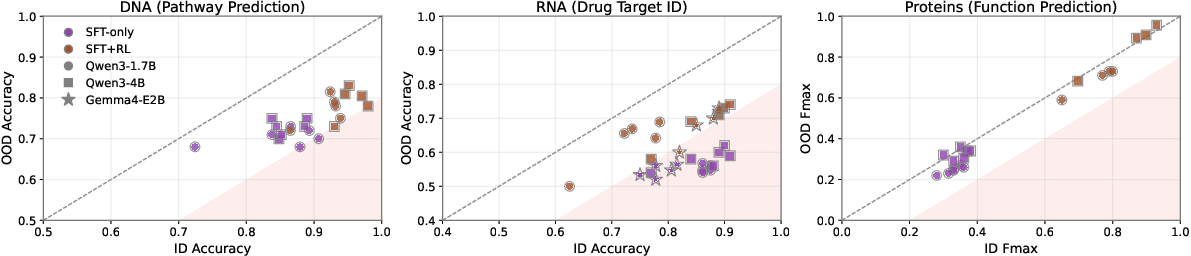
Figure 7: RL shifts the ID-OOD performance frontier universally across DNA, RNA, and protein reasoning tasks.
Theoretical and Practical Implications
The findings have direct implications for scientific reasoning models in biology:
- Monotonic scaling of supervision does not produce monotonic generalization: Overspecialization under SFT is a deterministic effect of matching the training distribution at the expense of cross-domain transfer.
- RL is necessary for OOD robustness, but only after sufficient SFT initialization: Reward-driven optimization recovers and surpasses lost OOD generalization, contingent upon supervised competency.
- Training stage allocation and adaptation capacity are critical: Naive uniform scaling wastes compute and capacity; competitive biological reasoning models require precise allocations and stage-dependent adaptation strategies.
- CPT is indispensable for aligning general-purpose LLMs to scientific domains: Even generic biological corpora confer significant downstream benefits.
Theoretically, the paper exposes non-monotonic scaling laws in biological reasoning contexts distinct from code or mathematics, where OOD problems are structurally divergent rather than superficially different. It suggests that the generalization failures induced by post-training are more pronounced in biological systems due to genuine mechanism variation. Practically, the results guide post-training protocol design, optimize compute allocation, and inform capacity distribution for multimodal biological models.
Future Directions
Open questions include compute-normalized studies to identify optimal SFT–RL trade-offs, integration of richer reward models, robust evaluation of intermediate reasoning traces, and benchmarking across broader biological workflows. The impact of reward design and initialization quality on the efficacy of RL warrants deeper investigation. Generalization beyond biology—across other scientific modalities—should be systematically explored.
Conclusion
This study decisively demonstrates that the composition and allocation of post-training stages govern the generalization properties of biological reasoning models. SFT enhances ID performance but narrows robustness; RL recovers and strengthens OOD transfer. CPT, SFT, and RL exert distinct effects and demand stage-specific capacity and compute. Effective adaptation in scientific AI hinges not only on model scaling, but on controlling post-training dynamics and resource allocation. The findings provide clear design principles for robust biological modeling and extend to broader domains requiring scientific reasoning and cross-domain generalization.

