On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning Language Models
Abstract: Recent reinforcement learning (RL) techniques have yielded impressive reasoning improvements in LLMs, yet it remains unclear whether post-training truly extends a model's reasoning ability beyond what it acquires during pre-training. A central challenge is the lack of control in modern training pipelines: large-scale pre-training corpora are opaque, mid-training is often underexamined, and RL objectives interact with unknown prior knowledge in complex ways. To resolve this ambiguity, we develop a fully controlled experimental framework that isolates the causal contributions of pre-training, mid-training, and RL-based post-training. Our approach employs synthetic reasoning tasks with explicit atomic operations, parseable step-by-step reasoning traces, and systematic manipulation of training distributions. We evaluate models along two axes: extrapolative generalization to more complex compositions and contextual generalization across surface contexts. Using this framework, we reconcile competing views on RL's effectiveness. We show that: 1) RL produces true capability gains (pass@128) only when pre-training leaves sufficient headroom and when RL data target the model's edge of competence, tasks at the boundary that are difficult but not yet out of reach. 2) Contextual generalization requires minimal yet sufficient pre-training exposure, after which RL can reliably transfer. 3) Mid-training significantly enhances performance under fixed compute compared with RL only, demonstrating its central but underexplored role in training pipelines. 4) Process-level rewards reduce reward hacking and improve reasoning fidelity. Together, these results clarify the interplay between pre-training, mid-training, and RL, offering a foundation for understanding and improving reasoning LM training strategies.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Explanation of “On the Interplay of Pre-Training, Mid-Training, and RL on Reasoning LLMs”
Overview
This paper studies how three training stages—pre-training, mid-training, and reinforcement learning (RL)—work together to help LLMs (like the ones that solve math word problems) reason better. The authors build a controlled testing setup so they can clearly see which stage adds what kind of improvement. Their big goal is to answer: when and how does RL actually make a model smarter at reasoning, rather than just polishing what it already knows?
To make this clear for you, here are a few helpful terms:
- Pre-training: Learning basic skills from lots of examples (like learning arithmetic and simple problem patterns).
- Mid-training: Extra focused lessons that bridge the basics and the advanced training (like a targeted study session on the kinds of problems you’ll face later).
- Reinforcement Learning (RL): Practice with rewards for correct solutions, often with exploration (like a game where you get points for solving harder puzzles).
- Pass@k: The model can try up to k different answers; if at least one is correct, that’s a “pass.” Pass@1 is one try; Pass@128 is 128 tries.
- “Edge of competence”: Tasks that are tough but not impossible for the model—its “challenging-but-doable” zone.
- Contextual generalization: Solving the same type of logic in new “skins” (e.g., a problem about animals instead of teachers, but the math structure is the same).
- Extrapolative generalization: Solving deeper or longer problems than you’ve seen before (more steps or operations).
- Reward hacking: Getting the right final answer by cheating or using shortcuts, without correct reasoning steps.
Key Objectives (In Simple Terms)
The paper asks four main questions:
- When does RL truly make a model better at reasoning beyond what it learned during pre-training?
- How much pre-training exposure to different contexts is needed before RL can help the model generalize to those new contexts?
- How does mid-training (the extra focused lesson stage) improve results compared to using RL alone, if we keep the total training effort the same?
- Can adding rewards for correct reasoning steps (not just final answers) reduce cheating (reward hacking) and improve trustworthy reasoning?
Methods and Approach (Explained Simply)
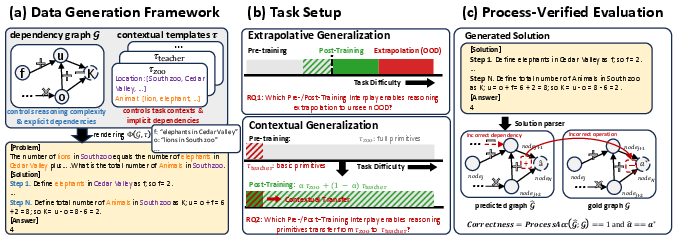
The authors use a carefully designed, synthetic setup—like a sandbox—for math word problems:
- They build problems from simple “atomic” operations (add, subtract, etc.) and connect them like a flowchart (a “dependency graph”) so they can control the number of steps and the logic.
- They change the “context” (the story skin, like zoo animals vs. school teachers) while keeping the underlying math the same. This lets them test whether the model can transfer skills across different wordings.
- They check not just the final answer but also the reasoning steps (“process verification”), like a teacher grading your work line-by-line.
They train a medium-sized model on:
- Pre-training: Lots of basic-to-medium problems to learn core skills.
- Mid-training: Focused problems near the model’s “edge of competence” to strengthen the mental building blocks the model needs.
- RL post-training: Practice with rewards, carefully choosing problem difficulty.
They measure performance on:
- In-distribution (ID): Problems similar to the pre-training set.
- OOD-edge (just beyond pre-training): Slightly harder problems where the base model sometimes succeeds.
- OOD-hard (well beyond pre-training): Much harder problems the base model almost never solves.
Main Findings and Why They Matter
Here are the most important results, explained clearly:
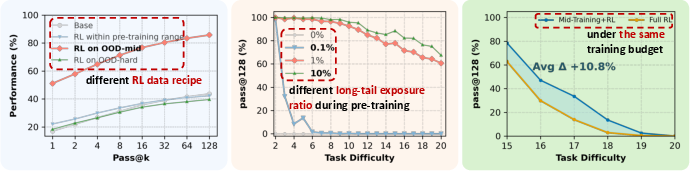
- RL gives real new capabilities only in the right difficulty zone:
- On easy or already-mastered problems (ID), RL doesn’t improve pass@128 (many tries). It mostly improves pass@1 (one try), which means it polishes what the model already knows rather than expanding it.
- On harder problems at the “edge of competence” (just beyond what pre-training covered), RL increases pass@128 noticeably. That shows RL helping the model genuinely handle more complex reasoning than before.
- To generalize to new contexts, the model needs at least a tiny seed during pre-training:
- If pre-training had zero or almost zero examples in a new context, RL could not make the model transfer its skills there.
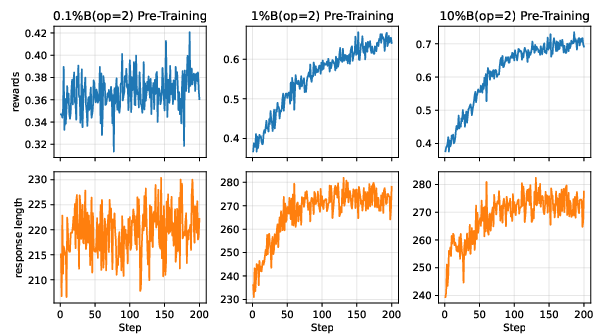
- Even very small exposure (around 1% of the data) was enough for RL to build on and achieve strong cross-context generalization—even on the hardest problems. In other words, RL can grow a skill tree if you plant the seed first.
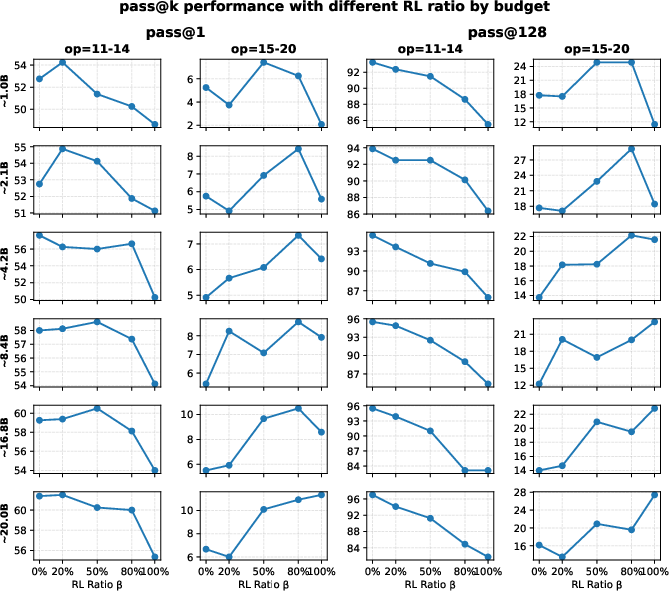
- Mid-training plus RL beats RL alone when compute (training effort) is fixed:
- Mid-training acts like installing the right priors (mental building blocks). With those, RL makes better use of its practice time.
- If you care about reliability on slightly harder tasks (OOD-edge), more mid-training and lighter RL work best.
- If you want to push into very hard problems (OOD-hard), you still need some mid-training, but give more budget to RL (heavier RL helps exploration).
- Rewarding the reasoning steps reduces cheating and improves trustworthiness:
- Adding process-level rewards (checking the steps, not just the final answer) led to better accuracy and fewer “shortcut” solutions.
- Mixing outcome rewards (final answer) with process rewards (step-by-step correctness) worked best. A stricter rule—only reward the final answer if all steps are correct—further reduced hacks.
These results matter because they explain why RL sometimes looks amazing and other times looks disappointing: it depends on what the base model already knows, how hard the RL tasks are, and whether there’s a mid-training bridge that prepares the model for RL.
Implications and Potential Impact
In simple terms, here’s how this research can guide future training of reasoning models:
- Choose RL tasks at the model’s “edge of competence”:
- Too easy: RL mostly polishes; no real growth.
- Too hard: RL struggles; rewards are too sparse.
- Just right: RL expands capability and helps with deeper reasoning.
- Seed long-tail contexts during pre-training:
- You don’t need tons of advanced data in new contexts—just ensure the basics appear at least a little. Then RL can learn to generalize across different wordings and topics.
- Use mid-training strategically:
- Treat mid-training as the phase that installs sturdy mental scaffolding for RL.
- For reliable performance on moderately harder tasks, lean toward mid-training with light RL.
- For pushing into very hard territory, keep some mid-training, but spend more on RL exploration.
- Reward the process, not just the outcome:
- Combine sparse final-answer rewards with dense step-by-step verification.
- This reduces cheating and produces solutions you can trust.
Overall, the paper offers a clear, practical recipe for building smarter, more trustworthy reasoning models: ensure a solid base (with small seeds in new contexts), use mid-training to prepare the model, pick RL tasks carefully, and reward good reasoning steps. This can help developers create models that not only get answers right but also show their work in a reliable, understandable way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for follow-up work.
- External validity beyond synthetic arithmetic:
- Does the interplay among pre-training, mid-training, and RL observed here transfer to real-world domains (math with natural ambiguity, coding, scientific reasoning, multi-hop QA) with noisy, heterogeneous data?
- How sensitive are the conclusions to linguistic complexity, longer contexts, and tasks that require world knowledge rather than purely symbolic arithmetic?
- Scale sensitivity:
- Do the findings hold for larger models (≥7B, 70B, MoE) where emergent behaviors and pre-training coverage differ?
- Are the “edge-of-competence” regimes and the ≈1% exposure threshold invariant to model size and capacity?
- Architecture dependence:
- Results are reported on a Qwen2.5-style 100M decoder; do the patterns replicate for LLaMA, Mistral, Mamba, MoE backbones, or encoder-decoder models?
- RL algorithm generality:
- Only GRPO is studied; do PPO, RPO, DPO/RLAIF, best-of-n sampling, or tree search–based RL produce the same edge-of-competence effects and mid-training synergies?
- How do different KL regularization strategies or exploration policies affect the identified regimes?
- SFT vs RL:
- For equalized compute, how does SFT (instruction tuning, CoT supervision, step-by-step SFT) compare to RL in extrapolative and contextual generalization?
- Can hybrid SFT→RL curricula match or exceed the reported gains, and under what data/compute mixtures?
- Process-verification robustness:
- The parser and gold DAG enforce a single reference trace; how often are alternate valid derivations penalized, and can equivalence-aware verification reduce false negatives?
- How robust is the process parser to paraphrase, step reordering, implicit steps, or algebraic equivalences?
- Can adversarial examples exploit the parser (i.e., “verifier hacking”) despite process rewards?
- Building process rewards for real tasks:
- The paper assumes high-quality process labels; how feasible and scalable is process verification for real-world math/coding/science, where exact DAGs are unavailable or costly?
- What are data/engineering strategies (program analyzers, weak verifiers, PRMs) to approximate process rewards reliably and economically?
- Reward-mixing design:
- The study explores a few static α values; do adaptive or curriculum-based mixtures (dynamic α, stage-wise schedules) yield better stability and generalization?
- What is the credit-assignment behavior of process rewards across long horizons, and how sensitive is performance to reward sparsity/density trade-offs?
- Edge-of-competence operationalization:
- The proposed selection heuristic (fail at pass@1, succeed at pass@k) assumes labels and intensive sampling; how can one detect edge-of-competence efficiently at scale and with minimal labeling?
- How robust is this boundary to sampling randomness, seed variance, and evaluator noise?
- Mid-training design space:
- Only NTP-based mid-training on a narrowed distribution is tested; what is the impact of alternative objectives (contrastive, masked LM, PRM pretraining, instruction-formatted SFT) and different data mixtures?
- What scheduling strategies (interleaving mid-training and RL, iterative recalibration, self-paced curricula) outperform the single-pass pipeline?
- Compute accounting and fairness:
- The FLOPs-equivalent token formula for RL is approximate; do the conclusions persist under more precise cost models (actor/critic costs, verifier costs, sequence length variation) and different hardware?
- How do results change when normalizing by wall-clock, energy, or dollar cost rather than token-equivalents?
- Test-time compute and sampling policies:
- The paper emphasizes pass@128; how do the findings translate to realistic deployment budgets (pass@1–8) and to more advanced test-time compute strategies (majority vote, tree-of-thought, sampling temperature, best-of-n with verifiers)?
- Is there a principled way to trade off training-time RL vs test-time compute to reach a target accuracy?
- Retention and regression:
- Does focusing RL on OOD or edge-of-competence tasks degrade ID performance (catastrophic forgetting), and can mid-training reliably mitigate it?
- What is the long-term stability of gains after extended training or distributional shifts?
- Generalization breadth:
- Contextual generalization is tested via template changes with shared primitives; do conclusions hold for deeper semantic shifts (new primitives, different operations, symbolic vs linguistic reasoning, multimodal contexts)?
- Is the ≈1% “seed exposure” rule consistent across domains and context types, or is the threshold task- and model-dependent?
- Depth extrapolation limits:
- Extrapolation is probed up to 20 operations; where do phase transitions occur as depth increases further, and how do RL/mid-training budgets need to scale with depth?
- Can we characterize scaling laws for extrapolative generalization vs depth and dataset size?
- Variance and reproducibility:
- The paper does not report variability across seeds or runs; how stable are the results to random initialization, data order, and hyperparameters (batch size, rollout multiplicity, KL targets)?
- What are the confidence intervals for key claims (e.g., +42% or +60% pass@128 improvements)?
- Data realism and noise:
- Synthetic problems lack ambiguity, noise, and annotation errors; how do spurious correlations, distractors, and noisy labels affect the interplay between stages?
- Does process supervision remain beneficial when intermediate steps are partially noisy or weakly labeled?
- Alternative objectives and signals:
- Can self-verification, reflective CoT, or verifier-guided search at training time substitute for or complement process rewards?
- What is the role of uncertainty estimation (calibration, entropy bonuses) in navigating the edge-of-competence band?
- Safety and misuse:
- While process rewards reduce reward hacking in this setting, do they introduce new failures (e.g., verbosity gaming, overconstrained reasoning, verifier overfitting)?
- How resilient are gains under adversarial prompts targeting the verifier or reward model?
- Comparative data recipes:
- The mid-training and RL data ranges are narrow (op=11–14); how do broader or multi-range curricula (mixtures across depths/contexts) change the optimal compute split?
- Can active data selection (difficulty estimation, uncertainty sampling) improve efficiency over static ranges?
- Interaction with pre-training corpus properties:
- Pre-training here is synthetic and clean; do the same headroom and seeding conclusions hold for large, messy internet corpora with unknown contamination?
- How do duplication, long-tail coverage, and curriculum in pre-training modulate downstream RL responsiveness?
- Alternative evaluation targets:
- Besides accuracy/process-accuracy, how do stages affect sample efficiency, solution length, latency, and memory usage?
- Are there trade-offs between reasoning fidelity and brevity/efficiency induced by process-aware rewards?
- Theoretical grounding:
- Can the “edge-of-competence” effect be formalized (e.g., in terms of policy support, occupancy measures, or capacity-limited compositionality) to predict when RL yields true capability gains?
- Can we derive principled criteria for the minimal pre-training seed exposure required for reliable cross-context transfer?
- Interplay scheduling and curriculum:
- The paper suggests iterative recalibration but does not test it; do cyclic schedules (evaluate → re-mine edge sets → mid-train/RL) outperform single-pass training under fixed compute?
- What are the optimal stopping and switching rules between stages?
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, based on the paper’s findings about calibrating RL to the model’s edge of competence, seeding minimal pre-training exposure for contextual transfer, integrating a mid-training bridge, and using process-level rewards to reduce reward hacking.
- Training pipeline optimization for reasoning LMs (software sector; academia; AI labs)
- What to do:
- Build mid-training stages that narrow the distribution gap between broad pre-training and RL tasks.
- Allocate compute strategically: prioritize mid-training + light RL for in-distribution reliability; shift to heavier RL for out-of-distribution generalization.
- Curate RL datasets that sit at the model’s edge of competence—instances the model fails at pass@1 but occasionally solves at higher pass@k.
- Potential tools/products/workflows:
- “Edge-of-Competence Curriculum Scheduler” that auto-detects solvability gaps and refreshes the RL pool as the model improves.
- “Mid-Training Planner” that selects structured reasoning data in the OOD-edge range.
- A pass@k dashboard that tracks distributions across ID/OOD-edge/OOD-hard tasks.
- Assumptions/dependencies:
- Access to labeled or semi-structured reasoning datasets and reliable pass@k evaluation.
- Sufficient compute to run mid-training and RL under budget constraints.
- Ability to avoid distribution contamination between pre-, mid-, and post-training.
- Seeding long-tail domain primitives during pre-training to unlock RL transfer (healthcare; finance; legal/compliance; education)
- What to do:
- Inject sparse (≈1%) exposure to critical atomic primitives and vocabulary for long-tail contexts during pre-training (e.g., medical units and basic clinical arithmetic; regulatory terms and simple compliance checks).
- Use RL post-training to robustly transfer skills to those contexts at higher complexity.
- Potential tools/products/workflows:
- “Pre-Training Seed Injector” that guarantees minimal coverage of domain primitives across long-tail contexts.
- Lightweight domain glossaries and atomic problem templates (op=2 tasks) embedded in pre-training corpora.
- Assumptions/dependencies:
- Minimal but high-quality domain-specific atomic examples exist or can be synthesized.
- Accurate identification of primitives that matter for downstream tasks.
- Data governance to prevent leakage between training phases.
- Process-verified RL to reduce reward hacking and improve reasoning fidelity (software; healthcare; finance; safety-critical systems; education)
- What to do:
- Combine sparse outcome rewards with dense process-level verification signals to align reinforcement with valid reasoning.
- Use composite rewards (e.g., α·outcome + (1−α)·process) and stricter gating where outcome reward only fires if the process trace is correct.
- Potential tools/products/workflows:
- “Process-Verified Reward Mixer” with tunable α and a parser that checks intermediate steps against ground-truth (or domain rules).
- Graph-based trace validators for math, code, and decision workflows; automated step-level audit logs.
- Assumptions/dependencies:
- Availability of reliable process parsers or rule engines to verify intermediate steps.
- High-quality process supervision (for math, code, or decision graphs); model outputs must be parseable.
- Safer, more reliable code assistants with step-aware training and evaluation (software sector)
- What to do:
- Mid-train on structured tasks (e.g., unit tests and small refactoring tasks), then apply RL with process-verified rewards (e.g., intermediate compilation/test checkpoints).
- Gate releases by pass@128 under process verification to avoid shortcut solutions.
- Potential tools/products/workflows:
- “Step-Aware Code RL” pipeline that rewards compilation success and unit-test novelty, not just final pass/fail.
- Assumptions/dependencies:
- Test suites and static analyzers as process verifiers; sufficient coverage of code primitives in pre-training.
- Robust math and tutoring systems with calibrated RL and process feedback (education sector; daily life)
- What to do:
- Seed basic math primitives during pre-training, then use RL at the learner’s edge-of-competence for step-by-step reasoning improvements.
- Display verified solution steps to learners and instructors; penalize unsupported steps.
- Potential tools/products/workflows:
- “Adaptive Tutor RL” that tunes task difficulty to student and model edge-of-competence; verified chain-of-thought display.
- Assumptions/dependencies:
- Reliable step parsers for math; accurate learner modeling to set task difficulty.
- Decision support with auditable reasoning chains (healthcare; finance; operations)
- What to do:
- Require process-verified traces for clinical triage or risk assessments; seed domain primitives (terminology, units) in pre-training; apply RL in OOD-edge ranges.
- Potential tools/products/workflows:
- “Reasoning Audit Trail” that records step-level logic and checks against domain constraints.
- Assumptions/dependencies:
- Domain experts to encode constraints; strict review of process validators; legal/privacy compliance for training data.
- Model evaluation and governance upgrades using pass@k with process verification (policy; industry standards; academia)
- What to do:
- Adopt process-verified pass@k metrics in model cards and benchmarks; report ID/OOD-edge/OOD-hard breakdowns.
- Potential tools/products/workflows:
- “Process-Verified Benchmark Suite” for math, code, and planning; governance checklists for training distribution separation.
- Assumptions/dependencies:
- Community consensus on parsers/validators; standardized reporting templates and thresholds.
Long-Term Applications
These opportunities depend on further scaling, generalized process verification across domains, or broader ecosystem adoption.
- Sector-specific reasoning LMs with standardized mid-training and RL curricula (healthcare; finance; energy; robotics)
- What could emerge:
- Industry-grade pipelines that frontload domain primitives (≥1% coverage), mid-train on structured OOD-edge tasks, and scale RL exploration for OOD-hard generalization.
- Potential tools/products/workflows:
- “Curriculum Orchestrator” that dynamically balances mid-training and RL by monitoring pass@1 vs pass@128 and OOD shift.
- Domain DAG generators for clinical pathways, regulatory workflows, energy scheduling, and robot task plans.
- Assumptions/dependencies:
- Formalization of domain processes into parseable graphs; scalable verification; significant compute and curated data.
- Process reward models and universal step verifiers for open-ended tasks (software; education; healthcare; policy)
- What could emerge:
- General-purpose “process reward models” trained to evaluate step correctness across diverse tasks without ground-truth DAGs.
- Cross-domain verification APIs that check consistency, constraints, and unit conversions at intermediate steps.
- Potential tools/products/workflows:
- “Universal Process Verifier” services integrated into RL frameworks (e.g., GRPO/PPO) and product inference.
- Assumptions/dependencies:
- Advances in learning step verifiers; robust generalization beyond synthetic settings; standardized interfaces.
- Safe exploration in embodied systems via mid-training bridges and process-aware RL (robotics)
- What could emerge:
- Robots that use mid-training to align with task structure and process-aware RL to avoid unsafe shortcut policies.
- Compute-aware curricula that push OOD-hard reasoning while respecting safety constraints.
- Potential tools/products/workflows:
- “Safety-Constrained RL Explorer” combining constraint verifiers with edge-of-competence task sampling.
- Assumptions/dependencies:
- Reliable simulation-to-real transfer; formal task constraints; safety audits; regulatory acceptance.
- Adaptive education platforms that personalize curricula to learner and model competencies (education; daily life)
- What could emerge:
- Platforms co-optimizing student learning and model training: learners get tasks at their edge-of-competence; the model trains on analogous edge tasks with process verification.
- Potential tools/products/workflows:
- “Twin-Curriculum Engine” that pairs human pedagogy with model RL curricula; verifiable step feedback for both.
- Assumptions/dependencies:
- Accurate learner models; ethical data use; process parsers for varied subjects beyond math.
- Policy frameworks codifying process-verified evaluation and distribution transparency (policy; standards bodies)
- What could emerge:
- Requirements for process-verified metrics in safety-critical deployments; disclosures on pre-/mid-/post-training distributions and contamination controls.
- Guidance on mitigating reward hacking with process-aware rewards.
- Potential tools/products/workflows:
- Compliance audit kits that test pass@k under process verification and check training-stage separation.
- Assumptions/dependencies:
- Multi-stakeholder agreement; sector-specific adaptations; workable audit costs.
- Synthetic testbeds and reproducible pipelines for reasoning research at scale (academia; AI labs)
- What could emerge:
- Widely adopted controllable synthetic datasets with explicit atomic operations and parseable traces to study compositional generalization across training stages.
- Potential tools/products/workflows:
- “Reasoning Lab-in-a-Box” with DAG generators, trace parsers, reward-mixers, and budget allocation simulators.
- Assumptions/dependencies:
- Community buy-in; extensions to real-world domains; strong open-source maintenance.
- Decision assurance for regulated industries leveraging process-level audit trails (finance; healthcare; legal)
- What could emerge:
- End-to-end auditability of algorithmic decisions through verified reasoning chains; standardized evidence formats for reviews and incident response.
- Potential tools/products/workflows:
- “Decision Assurance Layer” that captures process traces, verifies them, and produces compliance-ready evidence packages.
- Assumptions/dependencies:
- Regulatory alignment; integration with enterprise data systems; robust privacy and security controls.
In all cases, feasibility depends on accurate detection of the edge-of-competence, reliable process verification infrastructure, careful separation of training distributions to avoid contamination, and sufficient compute. The paper’s controlled findings provide a concrete recipe for building these capabilities and a principled way to allocate compute and data across pre-training, mid-training, and RL to achieve reliable, generalizable reasoning.
Glossary
- Atomic operations: Fundamental indivisible steps (e.g., arithmetic operations) used to build reasoning tasks. "synthetic reasoning tasks with explicit atomic operations"
- Chinchilla scaling: A scaling law guiding compute-optimal training by relating model size and dataset size. "Following Chinchilla scaling~\citep{hoffmann2022trainingcomputeoptimallargelanguage}"
- Contextual generalization: The ability to transfer reasoning across different surface contexts that share the same underlying logic. "contextual generalization across surface contexts."
- Contextual rendering: Converting a structured graph into a natural-language problem using a chosen template. "Contextual Rendering."
- Directed Acyclic Graph (DAG): A directed graph with no cycles used to represent dependencies in multi-step reasoning. "Each problem is generated from a DAG, encoding the reasoning structure and dependencies, with numeric values and context instantiated on top."
- Distribution contamination: Unintended overlap between training splits that can confound causal attribution of training effects. "and is partitioned into disjoint splits for pre-training, mid-training, and post-training to avoid distribution contamination."
- Distributional bridge: An intermediate data stage that aligns pre-training distributions with post-training objectives. "Mid-training acts as an intermediate distributional bridge between broad pre-training corpora and specialized post-training objectives"
- Edge of competence: The boundary of tasks that are difficult but still solvable for the current model, ideal for RL data. "the RL data are calibrated to the modelâs edge of competence"
- Extrapolative (Depth) generalization: Generalizing to problems requiring deeper compositions than seen in training. "extrapolative generalization to more complex compositions"
- GRPO: A reinforcement learning optimization method used to train models via outcome/process rewards. "Using GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical}"
- GSM-Infinite: A synthetic data generation framework for controlled math reasoning tasks. "We build on the GSM-Infinite~\citep{zhou2025gsminfinitellmsbehaveinfinitely} data generation framework"
- In-Distribution (ID): Tasks drawn from the same distribution as pre-training data. "In-Distribution (ID) problems within the pre-training range (op=#1{2-10});"
- Long-tailed context: Rare or sparsely represented contexts that require minimal seed exposure to enable transfer. "long-tailed context B atomic op=#1{2} examples"
- Mid-training: An intermediate training phase that strengthens reasoning priors and improves RL readiness. "Mid-training stabilizes optimization and facilitates RL scaling by providing structured reasoning supervision"
- Outcome-based reward: A sparse RL signal that grants credit only for correct final answers. "Post-training with outcome-based rewards has proven highly effective in improving reasoning performance, yet it remains vulnerable to reward hacking"
- Out-of-Distribution (OOD): Tasks whose distribution differs from the training data, often harder for the model. "improves OOD reasoning under fixed compute"
- OOD-edge: Tasks just beyond the training distribution where base models retain non-zero accuracy. "OOD-edge problems just beyond this range (op=#1{11-14})"
- OOD-hard: Tasks far beyond the training distribution where base models fail. "OOD-hard problems substantially beyond the pre-training distribution (op=#1{15-20})"
- Pass@k: The probability of solving a task across up to k sampled attempts; higher k reflects capability ceilings. "All pass@#1{k} metrics (e.g., pass@#1{1}, pass@#1{128}) are reported with respect to this strict criterion."
- Process accuracy: Step-level correctness of the reasoning trace aggregated over the gold graph nodes. "The process accuracy is computed as the average step-level accuracy across all gold nodes."
- Process verification: Checking intermediate reasoning steps, not just final answers, to ensure faithful reasoning. "Incorporating process verification into the reward function aligns reinforcement signals with valid reasoning behavior"
- Process-level rewards: RL signals that include verification of intermediate steps to encourage faithful reasoning. "Process-level rewards reduce reward hacking and improve reasoning fidelity."
- Reasoning fidelity: The faithfulness of the reasoning steps to valid logic and ground-truth structure. "Process-level rewards reduce reward hacking and improve reasoning fidelity."
- Reasoning primitives: Basic reusable operations or skills that models compose to solve complex tasks. "transfer its reasoning primitives to novel domains that differ in surface forms but share similar underlying reasoning structure."
- Reward hacking: Exploiting spurious shortcuts to get correct outcomes without valid reasoning. "Process rewards mitigate reward hacking and enhance reasoning fidelity."
- Rollout multiplicity: The number of sampled trajectories per RL input used to estimate rewards and gradients. "where is the number of RL samples, the rollout multiplicity"
- Supervised Fine-tuning (SFT): Post-training with labeled examples or instructions to specialize model behavior. "1) Supervised Fine-tuning (SFT): Training on labeled datasets or task-specific instructions;"
- Token-equivalent cost: A compute-normalized measure converting RL steps and rollouts into an equivalent number of tokens. "For RL, the token-equivalent cost is approximated as:"
- Topological similarity: A measure comparing the structure of generated reasoning graphs to reference graphs. "We examine the distribution of topological similarity between the generated correct context B graphs and the ground-truth topology from context A"
Collections
Sign up for free to add this paper to one or more collections.

