- The paper demonstrates that RL post-training amplifies pre-learned reasoning strategies through effective strategy selection between forward and backward approaches.
- It employs supervised fine-tuning followed by RL using synthetic finite-field arithmetic to isolate and quantify improvements in reasoning mechanisms.
- Results indicate that diverse SFT data and more challenging RL datasets are crucial to achieving near-perfect accuracy in mixed-strategy models.
Mechanistic Insights into RL Post-Training for Reasoning: Strategy Selection and Improvement
Overview
"Select and Improve: Understanding the Mechanics of Post-Training for Reasoning" (2606.13125) investigates the internal mechanisms by which reinforcement learning (RL) post-training enhances reasoning abilities in LLMs. Using controlled experiments in synthetic finite-field arithmetic, the study isolates and characterizes two primary mechanisms: strategy selection and strategy improvement. The results elucidate the key dependencies of RL effectiveness on pre-RL supervision and RL data design, deliver strong empirical evidence for these mechanisms, and provide actionable insights for future scaling of model reasoning capacities.
Experimental Design
To enable precise mechanistic study, the authors define a synthetic reasoning task over finite fields (GF(11), GF(13)), with abstractly relabeled numerals to neutralize pre-existing mathematical biases of pretrained models. Prompts fall into evaluation (direct calculation via described operations) and inversion (solving for an input that leads to a known outcome) problem types. The training protocol mirrors real-world RL-augmented LLM pipelines: starting with supervised fine-tuning (SFT) from an open-source base model (Qwen2.5-1.5B-Instruct), followed by RL (GRPO) on harder, distribution-shifted problem sets.
Key experimental variables include:
- SFT response strategy: forward-only, backward-only, or a mixture (FB).
- RL data difficulty: number of arithmetic steps, with RL data set at higher difficulty than SFT.
- Problem distribution tilting: variations in evaluation/inversion problem composition in RL data.
- Composition tasks: chained subproblems to evaluate generalization and compositionality.
Mechanism 1: Strategy Selection
The principal mechanism observed is strategy selection, where RL leverages the diversity of reasoning strategies seeded by SFT to learn to route problems to the most suitable reasoning pattern. For FB SFT models (trained on a mixture of strategies), RL rapidly achieves near-perfect accuracy by assigning evaluation problems to forward reasoning and inversion problems to backward reasoning, as visible in the sharp improvement and plateau in learning curves.
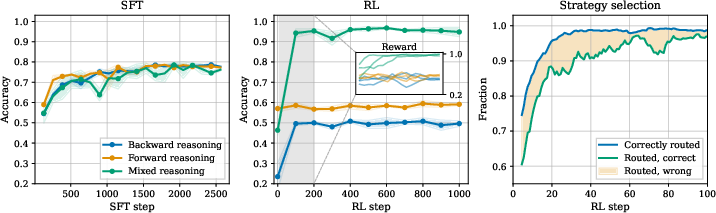
Figure 2: Main results in GF(11) demonstrate both strategy selection and strategy improvement, with the right panel showing that performance gains in mixed models are predominantly due to improved routing between strategies.
This effect is absent in F-only or B-only SFT models: RL cannot compensate for the absence of an alternative strategy, leading to stagnation on out-of-distribution problems. For those models, accuracy improvements during RL are restricted to the strategy represented during SFT.
The role of RL as a strategy selector is reinforced in problem distribution shift experiments. When the RL problem mix is skewed (i.e., evaluation-heavy), the usage of forward reasoning increases commensurately, matching the underlying RL data distribution.
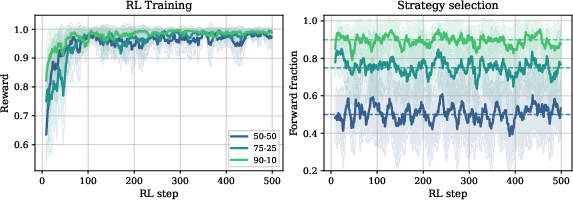
Figure 1: Under skewed RL problem distributions, the model's generation strategy allocation exactly tracks the evaluation/inversion composition in the RL data, confirming RL's amplificatory role in routing.
This makes clear that RL acts mechanistically to amplify and select among pre-existing reasoning circuits available in the model, rather than inducing entirely new algorithms during post-training.
Mechanism 2: Strategy Improvement
A secondary, essential mechanism is strategy improvement, where RL enhances the fidelity and generalization of reasoning patterns already present in the base model. This effect is most pronounced when the RL dataset presents problems of greater difficulty than those encountered during SFT. In these settings, even single-strategy models (F-only or B-only) show gains in accuracy on harder problems, but only when trained on correspondingly hard RL data.
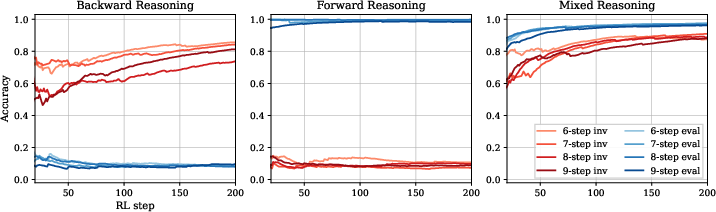
Figure 5: Detailed RL training dynamics indicate that correct routing saturates rapidly (strategy selection), followed by moderate ongoing improvement in solution accuracy (strategy improvement) over extended RL steps.
Further, the study highlights that RL does not generally induce composition abilities de novo. When models are SFT-ed without exposure to compositional problems, RL training on more complex chained tasks does not yield generalization. However, if even limited compositional data is seeded during SFT, RL extends this compositional skill to substantially harder, longer-chained problem instances.
Quantitative Results
The empirical results are robust across GF(11) and GF(13) settings and show the following:
- FB SFT + RL achieves near-perfect pass@1 and aggregate accuracy (∼95−97%) on hard 6–9 (and even 6–15) step problems, with rapid convergence due to routing.
- Single-strategy SFT + RL achieves high accuracy only on problems aligned with their SFT pattern and shows negligible gains on misaligned types.
- Strategy improvement can yield strong gains in solution accuracy for both problem types, but always relies on RL data being harder than SFT, with no improvement when RL data matches SFT difficulty.
- Compositional generalization via RL is strictly contingent on prior exposure to compositional reasoning during SFT.
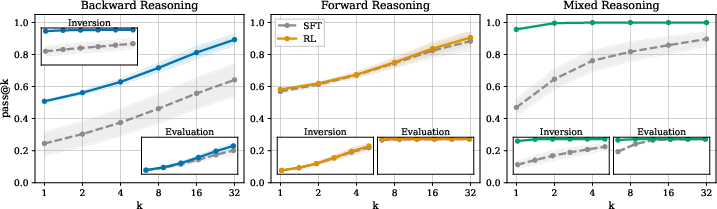
Figure 4: Pass@k improves in mixed-strategy models through RL, rapidly achieving near-perfect performance, while single-strategy improvements are limited to their corresponding problem type.
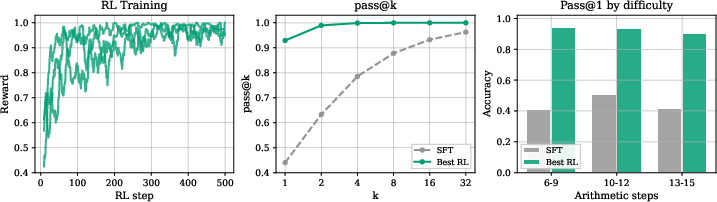
Figure 3: RL on extended-hardness datasets (6–15 step problems) in the mixed setting shows sharp, sustained improvements in both aggregate and disaggregated pass@1 accuracy.
Implications and Theoretical Perspectives
The findings substantiate the view that post-training RL for reasoning tasks primarily acts by exploiting the diversity of prelearned reasoning circuits, amplifying their usage, and refining their efficiency. The model’s ability to generalize and improve is tightly coupled with the breadth and quality of supervision before RL—RL cannot compensate for missing strategies, nor can it readily create new reasoning affordances ex nihilo.
Practically, this highlights that:
- Pre-RL diversity: SFT/pretraining data must encompass the full spectrum of reasoning strategies one wishes to select and improve during RL.
- Difficulty curriculum: RL datasets should be of higher difficulty than pre-RL stages to trigger genuine strategy improvement and generalization.
- Amplification artifacts: Observed increases in certain reasoning behaviors (like backtracking) post-RL may reflect distributional sharpening via selection rather than algorithmic innovation.
Theoretically, these insights clarify and unify previously reported RL phenomena (e.g., "policy sharpening," "amplification," "winner-take-all" behavior) as emergent consequences of mechanistic selection and improvement, not as direct signatures of algorithmic invention.
Future Directions
While the study does not observe RL inducing new emergent strategies, in contrast to some previous reports in more open-ended settings, the controlled nature of the task illuminates that RL’s creative power is currently mediated by SFT-exposed diversity. Key open questions include under what conditions RL can transcend selection/improvement to generate, and not just amplify, new algorithmic structures, as hinted in studies of prolonged RL [e.g., (Liu et al., 30 May 2025)].
Broader implications suggest that advances in scaling LLM reasoning via RL will depend on co-evolution of pre-RL data design and RL curriculum, rather than algorithmic tweaks to RL itself.
Conclusion
This work rigorously demonstrates that RL post-training augments reasoning in LLMs via two tightly coupled mechanisms: strategy selection (problem-to-pattern routing) and strategy improvement (pattern refinement). Both are fundamentally dependent on pre-RL data diversity and RL data difficulty. The study provides a mechanistic foundation for advancing RL-augmented reasoning and calls for integrated training pipelines where data curation is considered on par with algorithmic intervention for scaling LLM capabilities.