- The paper introduces a Norm-Agnostic Residual Network that decomposes the residual stream into separate norm and direction components to ensure balanced layer contributions.
- It demonstrates significant improvements in depth efficiency and training loss, achieving a 120× reduction in norm accumulation compared to standard models.
- The approach enables adaptive compute via a geometric Mixture-of-Depths routing mechanism, facilitating efficient low-precision inference and scalable deep networks.
Scaling Adaptive Depth with Norm-Agnostic Residual Networks
Motivation and Structural Limitations in Deep Residual Networks
Traditional residual architectures enable the stable training of deep networks by providing a direct identity gradient path, thereby circumventing vanishing and exploding gradient issues [he2016deep, vaswani2017attention, elhage2021mathematical]. However, empirical and theoretical analyses increasingly reveal inherent inefficiencies in depth utilization: later layers contribute progressively weaker updates to the representation, tending toward near-identity maps and producing highly correlated residual streams with increased depth [sun2025curse, csordas2025depth, gromov2025unreasonable, men2025shortgpt]. Moreover, deep layers in both standard and pre-norm Transformer variants are often observed to be expendable, with minimal degradation when skipped [veit2016residual, sajjad2022effect]. These phenomena suggest that the additive residual stream structure induces increasing norm growth, effectively diluting the impact of layer updates as model depth increases. While normalization variants (pre-norm, post-norm, sandwich-norm) attempt to mitigate gradient issues, none explicitly control the per-layer influence relative to the residual norm, resulting in architectural bias toward attenuated gradients (especially in early layers) and inequitably allocated compute across model depth [xie2023residual, sun2026cursedepthlargelanguage, brody2023expressivityrole].
The proposed Norm-AGnostic (NAG) architecture decomposes the residual stream Rl at each layer into separately propagated norm (ρl) and direction (Rˉl) components. This separation ensures that layer contributions induce controlled rotations in representation space, independent of the residual norm magnitude. Layer outputs are centered and orthogonalized with respect to Rˉl, normalized to fixed scale, and modulated by a trainable scalar αl and an input-dependent norm-modulator ml (a convex combination of sigmoid gates aligned to learned preferred directions). Updates are then added exclusively to the direction channel, while the induced norm increase is tracked in the separate norm lane, preserving numerical precision in log-space. This construction facilitates efficient kernel fusion and introduces negligible parameter overhead.
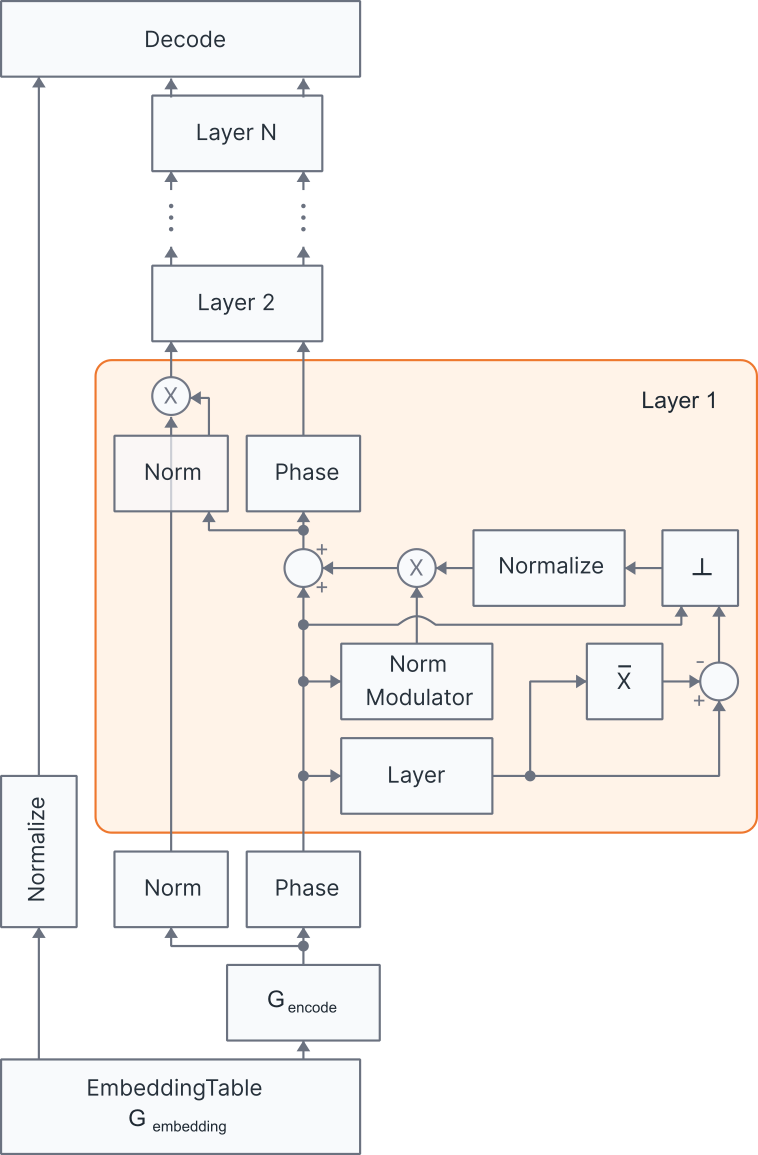
Figure 1: Schematic of the norm-agnostic architecture showing explicit separation of norm and direction propagation, layerwise orthogonalization, norm modulation, and transport of the norm update.
At decoding, token logits are computed via cosine similarity between final normalized direction RˉL and normalized embedding-table rows, with the decoded distribution's sharpness governed by the transported norm—a learned prediction temperature.
Experimental Results: Depth Efficiency, Geometric Stability, and MoD
NAG delivers improved loss and downstream accuracy relative to matched baselines, with benefits amplifying as depth increases. In depth ablation studies, NAG consistently outperforms baseline Transformers in HellaSwag accuracy, and achieves substantially lower training losses across all width-to-depth ratios. Notably, NAG achieves an approximately 120× reduction in residual-stream norm accumulation compared to baseline models, resulting in effective parameter equality and mitigating norm-dependent inhibition through depth.
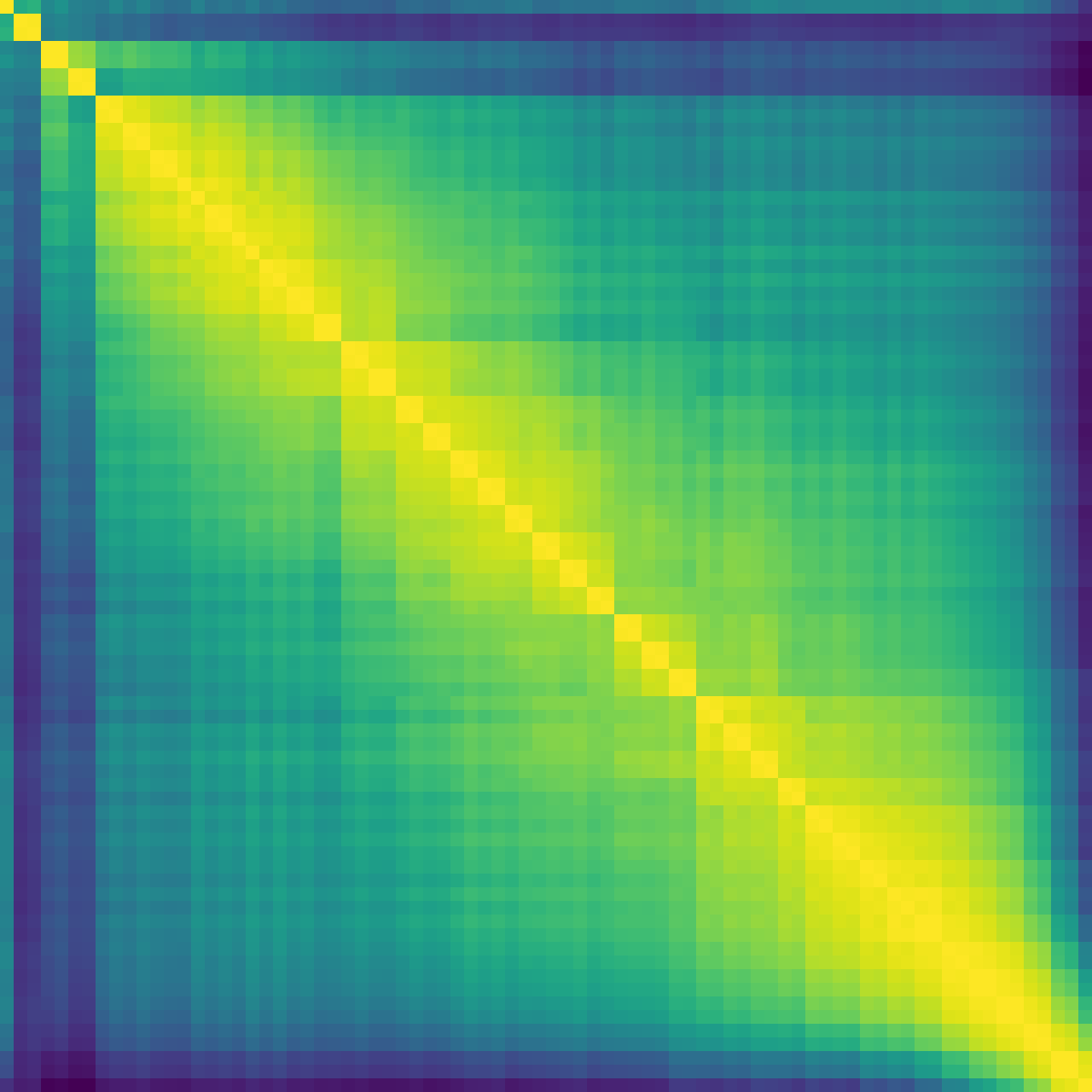
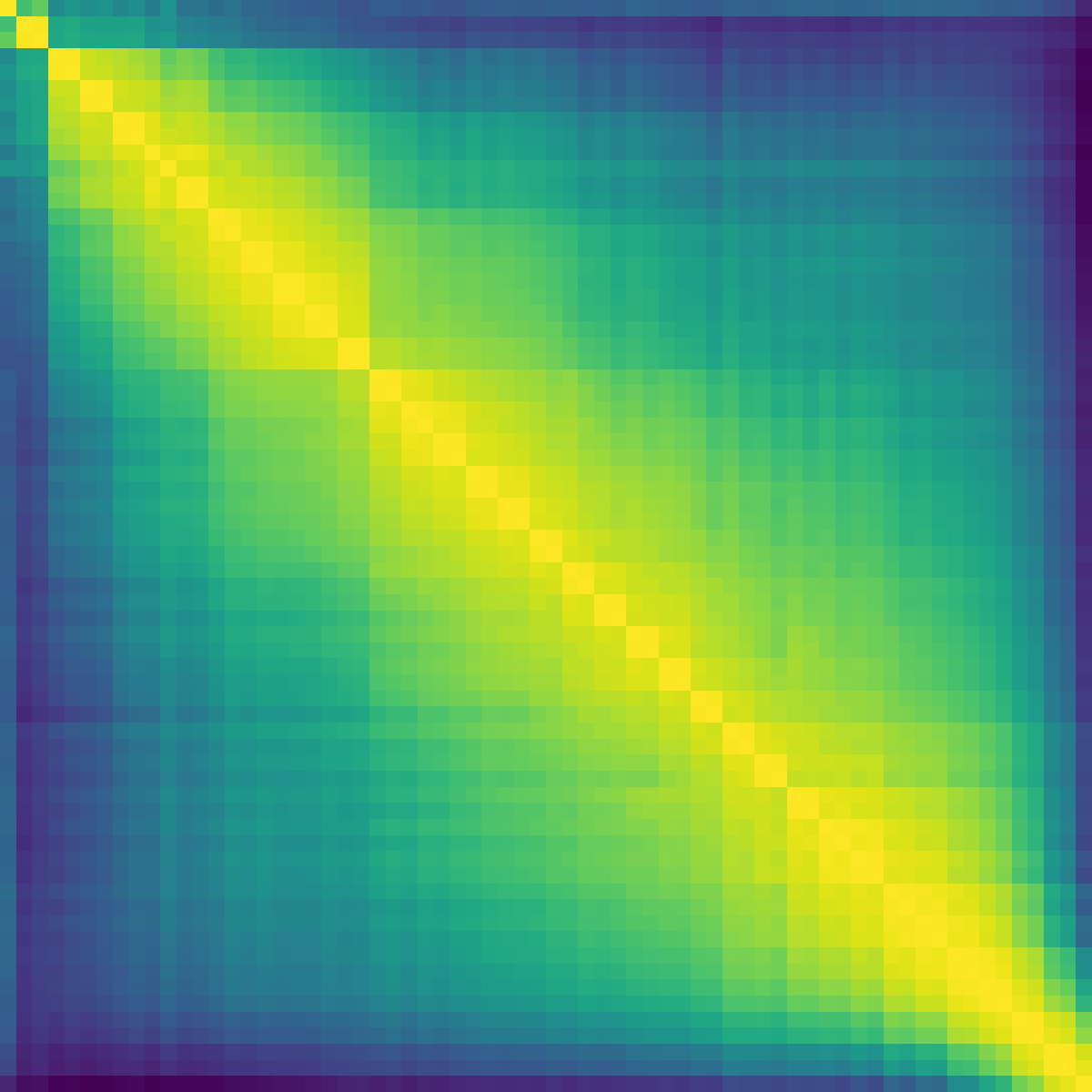
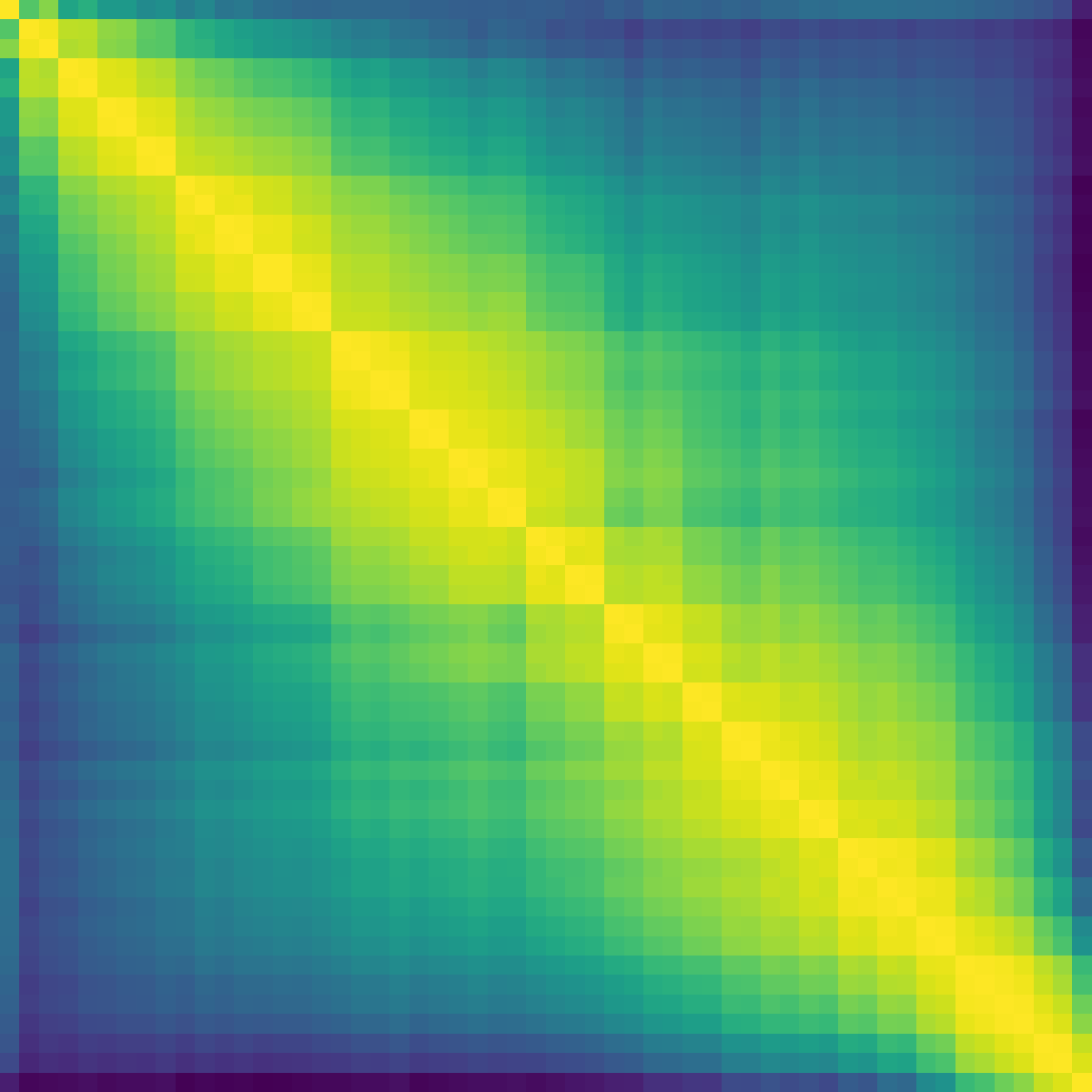
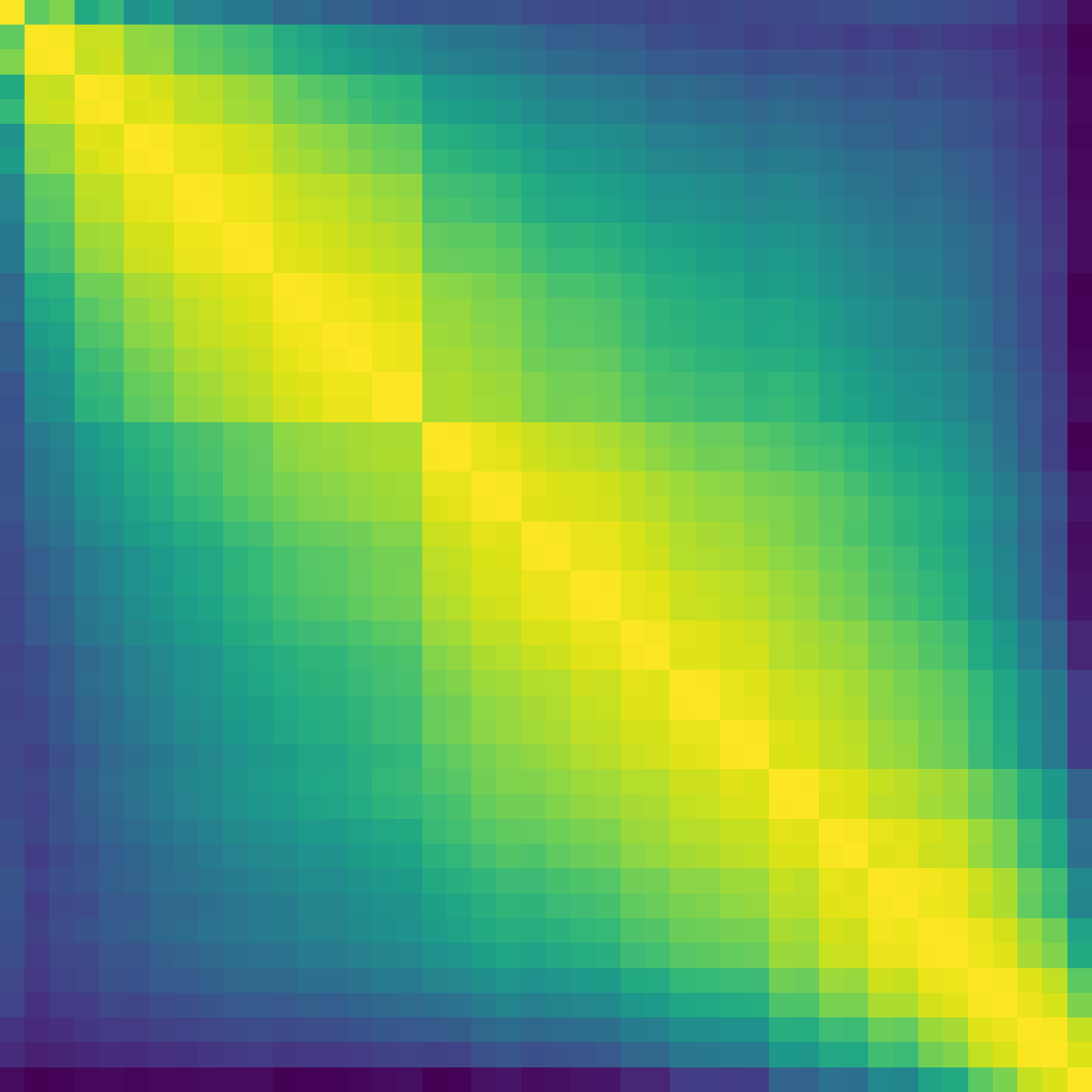
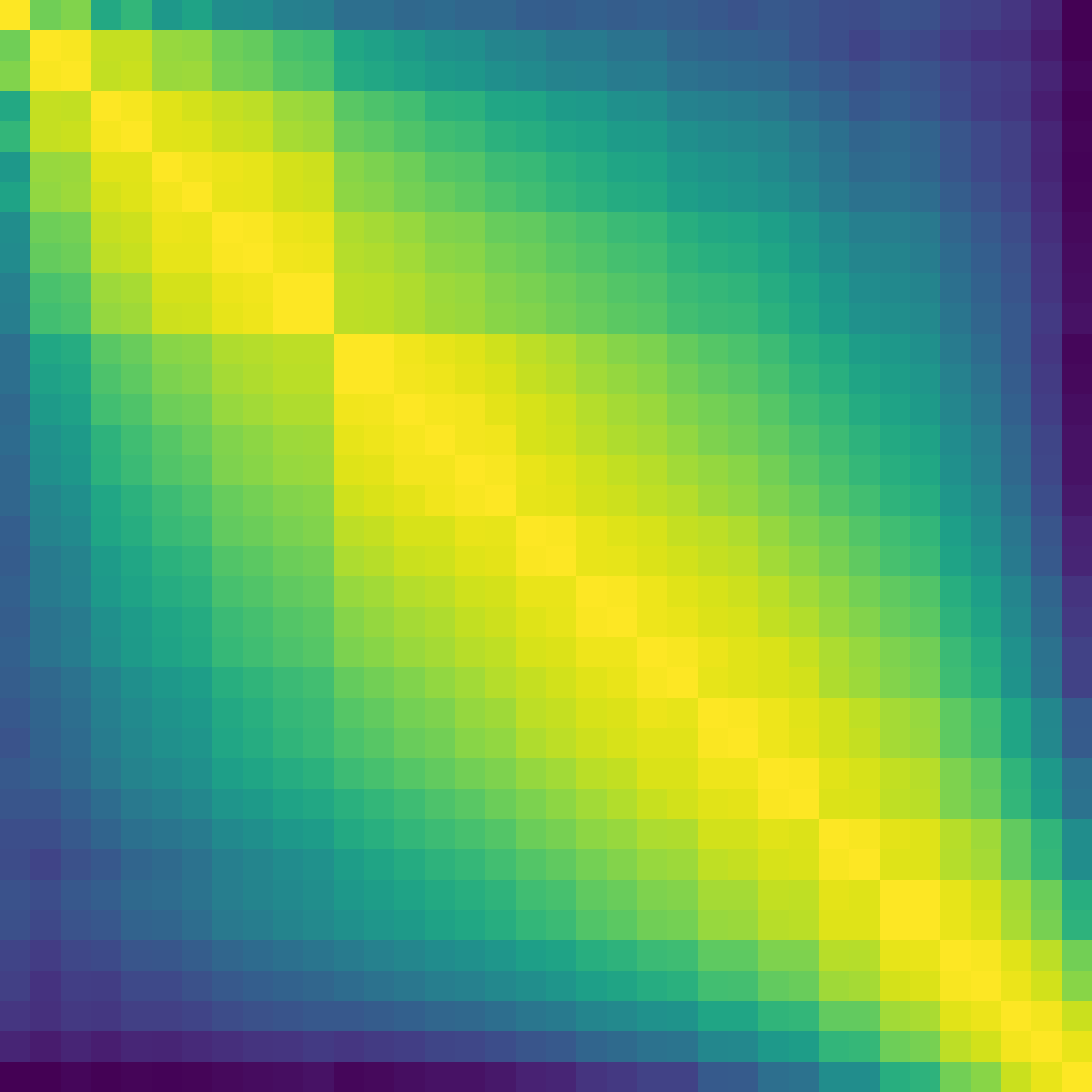
Figure 2: Model ratio 20 depth analysis illustrates the loss curves and layerwise contribution equalization enabled by NAG.


Figure 3: Baseline comparison reveals norm accumulation and diminished layer effectiveness in standard architectures.
Covariance-spectrum analysis of normalized residual directions demonstrates increased directional concentration (lower total variance) without effective-rank collapse, confirming that NAG suppresses norm-induced noise while preserving representation richness. Layerwise scaling factors αl and realized mean-gain remain invariant with depth, indicating balanced layerwise computational influence. Preferred-direction analysis shows local correlation across depth, suggesting consecutive layers operate in serially-related subspaces and supporting a conditional state-machine interpretation.
NAG substantially improves weight centering, reduces activation outliers, and enhances quantization suitability—key for deploying efficient low-precision inference. Moreover, attention-sink analysis reveals that NAG eliminates vertical-band (sink) patterns in post-softmax attention matrices, instead distributing attention mass broadly without persistent dependence on fixed initial tokens, further facilitating quantization [xiao2024streamingllm, gu2025attentionsink].
Adaptive Compute via Mixture-of-Depths (MoD)
NAG architecture naturally enables an interpretable, geometric skipping criterion for MoD: layer execution is triggered for tokens only if the predicted normalized rotation exceeds a threshold, measured relative to the layer's maximum possible angular update. This geometrically principled routing mechanism obviates the need for an auxiliary learned router, improves loss for MoD compared to standard router approaches, and allows skipping both attention and MLP/MoE blocks with negligible loss degradation up to moderate skip rates (20–25%).
Iso-compute experiments demonstrate that, for fixed parameter count and KV-cache budget, MoD under NAG matches full-depth performance when compute savings are reinvested to train on more tokens. Forward-pass cost and executed parameters are proportionally reduced, enabling adaptive depth scaling and compute-efficient inference, marking MoD as a viable pretraining strategy [raposo2024mixture].
Implications, Theoretical Reflections, and Future Directions
These findings identify residual-stream norm control as a fundamental scaling axis for Transformer architectures. NAG guarantees uniform layerwise influence, eliminates norm-induced inhibition, and paves the way for unbounded scaling in depth—potentially supporting latent program execution of arbitrary length without discrete token bottlenecks. The geometric MoD routing exposes transparent, interpretable compute allocation per token and per layer, and supports simultaneous sparsity in both width (via MoE) and depth. Open problems include optimal tuning of sparsity ratios, system-level tradeoffs, and exploiting NAG for iterative or recurrent residual computation paradigms [csordas2024moeut, geiping2026scaling].
Conclusion
Scaling deep residual architectures necessitates explicit control over residual-stream norm and directional updates. NAG, by decoupling magnitude from direction and enabling adaptive, geometry-driven layer skipping, remedies long-standing inefficiencies in depth utilization and unlocks new paradigms in depth scaling, compute allocation, and quantization robustness. Practically, it enables compute-efficient, extremely deep models compatible with pretraining-time MoD, supporting extensive token throughput and parameter efficiency (2606.16112).