Post-LayerNorm Is Back: Stable, ExpressivE, and Deep
Abstract: LLM scaling is hitting a wall. Widening models yields diminishing returns, and extending context length does not improve fundamental expressivity. In contrast, depth scaling offers theoretically superior expressivity, yet current Transformer architectures struggle to train reliably at extreme depths. We revisit the Post-LayerNorm (Post-LN) formulation, whose instability at scale caused its replacement by Pre-LN in modern LLMs. We show that the central failure mode of Post-LN arises from the ResNet-style residual pathway, which introduces gradient vanishing in deep networks. We present Keel, a Post-LN Transformer that replaces this residual path with a Highway-style connection. This modification preserves the gradient flow through the residual branch, preventing signal vanishing from the top layers to the bottom. Unlike prior methods, Keel enables stable training at extreme depths without requiring specialized initialization or complex optimization tricks. Keel trains robustly at depths exceeding 1000 layers and consistently improves perplexity and depth-scaling characteristics over Pre-LN. These findings indicate that Post-LN, when paired with a Highway-style connection, provides a simple and effective foundation for building deeply scalable LLMs, opening the possibility for future infinite-depth architectures.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how to make LLMs work better by making them deeper—adding more layers—without breaking training. The authors bring back an older design choice called “Post-LayerNorm” (Post-LN) and fix its main problem (training instability) with a simple architectural tweak they call Keel. With Keel, very deep Transformers (even over 1000 layers) train stably and become more expressive, especially at math and code.
What questions are they asking?
- Can we scale LLMs by making them deeper instead of just wider, with longer context windows, or more parameters?
- Why does the original Post-LN Transformer become unstable when it gets very deep?
- Is there a simple change that keeps the good parts of Post-LLN (strong signals from deep layers) but prevents the training from falling apart?
- Does this change actually help in real training—like higher learning rates, better scores, and more stable optimization?
How did they approach it?
Key ideas explained in everyday terms
- Transformers and layers: Think of a Transformer as a stack of many steps (layers) that gradually improve the text understanding. “Deeper” means more steps.
- LayerNorm (LN): A safety check that keeps a layer’s numbers from getting too big or too small, kind of like keeping the volume at a reasonable level.
- Residual/skip connections: A shortcut that lets information jump over a layer. It helps the model learn faster and keeps training stable.
- Pre-LN vs Post-LN:
- Pre-LN: Normalize before you add the shortcut. It’s very stable early on, but deeper layers don’t contribute as much—the shortcut carries most of the learning signal, so the deepest parts don’t improve much.
- Post-LN: Normalize after summing the shortcut and transformed signal. This can make deep layers more impactful, but training becomes unstable because the gradients (the “learning feedback”) get squashed or behave unpredictably.
- Gradients and “vanishing”: Training works by sending error signals backwards (gradients) to adjust earlier layers. In very deep networks, these signals can fade away (vanish), like a whisper getting lost down a long hallway.
- Highway-style connection: An older idea that lets a layer decide how much of the input to “carry” forward versus how much to “transform,” which helps gradients travel better.
What Keel changes
The authors analyzed why Post-LN’s gradients vanish in deep Transformers and traced it to how the shortcut (residual) and transformed signals are mixed before normalization. Their fix, Keel, keeps the overall Post-LN style but changes the residual path to be “highway-like”:
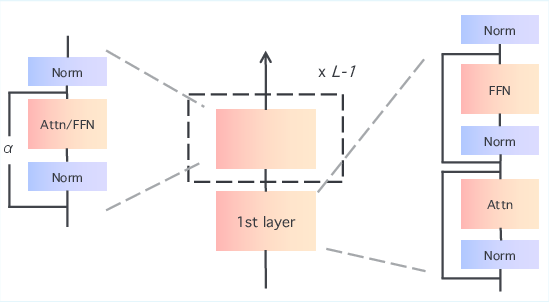
- They scale the shortcut branch by a factor
α(alpha). For very deep models, they setα = L, whereLis the number of sub-layers. This strongly supports the shortcut so gradients don’t fade. - They add a LayerNorm inside the transformation branch, so the transformed signal comes in well-behaved and doesn’t cause wild gradient swings.
- Final LayerNorm (Post-LN) still happens after combining the shortcut and transformed signals.
In simple terms: Keel boosts the shortcut’s “volume” and tidies the transformed signal before mixing, then normalizes the final sum—so both forward information and backward learning signals stay healthy even across hundreds or thousands of layers.
A bit of math intuition (kept simple)
- In vanilla Post-LN, the product of many normalization steps makes the gradient shrink exponentially with depth—so deep layers barely get trained.
- With Keel’s scaling (
α = L) and the extra normalization inside the transform, the gradient magnitude through many layers stays roughly constant (close to 1), so it doesn’t vanish. That means deep layers actually learn.
What did they find?
Here are the main results the authors report:
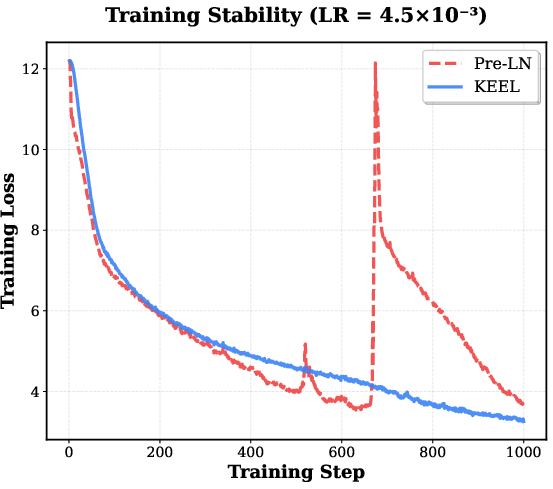
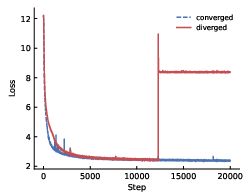
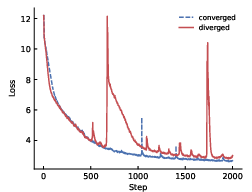
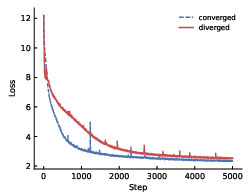
- Stable training at extreme depth: Keel trains smoothly for models with over 1000 layers, whereas standard Post-LN and even Pre-LN struggle or need tricks.
- Higher learning rates without breaking: Keel can handle bigger learning rates during warmup and training, which often means faster and better learning.
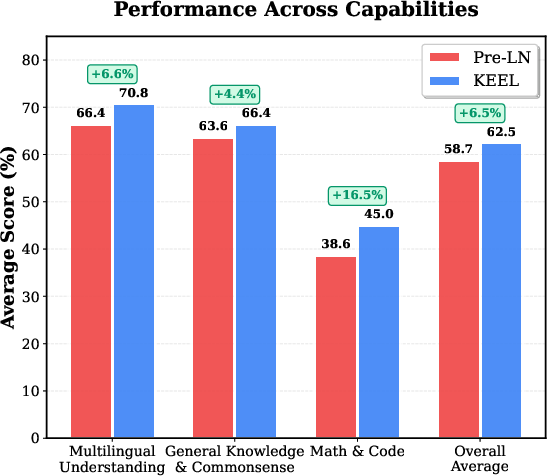
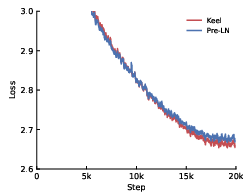
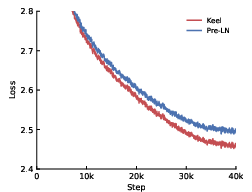
- Better performance across tasks: Keel consistently outperforms Pre-LN across depths (64–1024 layers). It shines especially in math and code, with up to about +16.5% improvement in those areas.
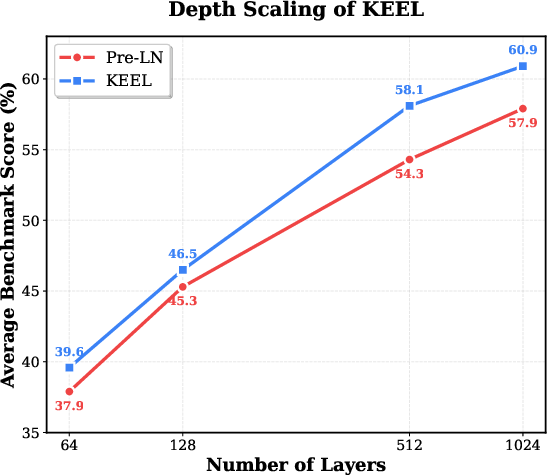
- Stronger depth scaling: As you add more layers, Keel keeps getting better in ways that standard Pre-LN often doesn’t—Pre-LN can plateau or become unstable at high depth.
- No special initialization required: Unlike some prior fixes (like DeepNorm), Keel doesn’t rely on delicate weight setups. The stability comes from the architecture itself.
These findings suggest that the main Post-LN problem wasn’t LayerNorm by itself—it was the way the residual (shortcut) mixed with the transformed signal. Keel’s highway-style scaling plus inner normalization fixes that.
Why does this matter?
If we want LLMs to become much more capable without endlessly increasing width, context window, or total parameters, depth is a promising path. Keel shows a simple and effective way to make very deep Transformers:
- More expressive: Deep layers can model richer, more structured reasoning.
- More trainable: Gradients don’t vanish, so deeper parts actually learn.
- More efficient: Better results at the same size or with the same data budget.
- Future-friendly: The paper hints at “infinite-depth” ideas—architectures that can, in theory, grow very deep without breaking. It also draws parallels to techniques used in sequence models (like test-time training), suggesting cross-pollination between making models handle long contexts and making them handle many layers.
In short, Keel offers a practical design for building deeper, more powerful LLMs by fixing a fundamental training issue—making Post-LN “work again” at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, to guide future research.
- Alpha selection and adaptation: The choice of a fixed scalar α=L is asserted as “critical,” but there is no systematic ablation of alternative α schedules (e.g., per-layer α, learned gates, data-dependent α, or depth-normalized α such as α∝√L). How should α be set across varying depths, changing training regimes, or curriculum schedules where L may vary?
- Dynamic vs. static “highway” gating: The method is described as Highway-style, yet the final design uses a fixed scalar α rather than an input-dependent gate T(x). Would truly learned, data-dependent gates (e.g., sigmoid gates per channel or per head) improve stability or expressivity, and what is the trade-off versus fixed α?
- Inner normalization design space: Keel inserts an additional LN inside F, but does not explore alternatives (RMSNorm vs. mean-variance LN, GroupNorm, ScaleNorm, NoNorm) or placements (before/after attention/FFN subcomponents). What normalization variants and placements maximize stability and performance?
- Sensitivity to LN hyperparameters: Theoretical analysis uses RMS-based LN with γ and β=0, but the empirical sensitivity to ε, γ initialization, γ regularization, and the decision to remove β is not quantified. Do different LN parameterizations materially affect the claimed gradient behavior?
- Theoretical assumptions vs. practice: The gradient product limit to 1 relies on simplified assumptions (e.g., constant γ across layers, abstraction of F’s Jacobian). Under realistic training where γ changes and F is highly non-linear, what conditions guarantee stable gradients? Can tighter, non-asymptotic bounds be established?
- Interaction with residual dropout and stochastic regularizers: The paper does not examine how residual dropout, attention dropout, stochastic depth, or noise injection interact with Keel’s stability guarantees. Do these regularizers undermine or improve the proposed gradient dynamics?
- Optimizer and hyperparameter robustness: Results are shown for AdamW with specific β values and weight decay. How does Keel behave with other optimizers (Adafactor, Lion, SGD+momentum), different β1/β2, weight decay schedules, gradient clipping norms, and mixed-precision (FP8/FP16/BF16)?
- Late-training stability beyond warmup: Max LR is measured during warmup, but there is no systematic analysis of divergence or instability later in training (e.g., mid- or late-stage spikes, catastrophic forgetting, or loss plateaus). Are there stage-dependent failure modes?
- Compute and memory overhead: Keel adds an extra LN per sublayer and scales residuals. The paper does not quantify per-step throughput, memory footprint, activation checkpointing needs, training/inference latency, or energy costs versus Pre-LN/Post-LN/DeepNorm. What is the efficiency trade-off at 512–1024+ layers?
- Width–depth trade-offs: The claim that depth is superior is not supported by controlled comparisons at fixed compute/parameter budgets. How do Keel depth-scaling curves compare to width scaling or hybrid width–depth scaling under equal FLOPs/parameters/tokens?
- Very large-scale validity: Most experiments are at ~3B params and hidden size 1024, with some deeper stacks up to 1024 layers. How do results generalize to larger LLMs (7B, 13B, 70B+), different head counts, bigger hidden sizes, and production-grade training corpora?
- Modality and architecture generalization: The method is evaluated on decoder-only text models. Does Keel transfer to encoder-only (BERT-like), encoder–decoder (T5-like), vision transformers, audio, or multimodal models? Are cross-attention and encoder–decoder attention stable under Keel?
- Attention mechanism variants: A conceptual link to linear attention and TTT is drawn, but there is no empirical validation with linear/recurrent attention, state-space models, or memory-augmented attention. Does Keel synergize with or obviate such mechanisms?
- Long-context behavior: While depth is emphasized, the impact on long-context tasks (e.g., Long Range Arena, Needle-in-a-Haystack, long-document QA) is not evaluated. Does Keel affect attention allocation over long sequences or mitigate attention sink?
- MoE and sparse architectures: The compatibility of Keel with Mixture-of-Experts layers, expert routing stability, and gradient flow across sparse modules is unknown. Does Keel’s residual/normalization structure help or hinder MoE training?
- Positional encoding and embeddings: The interaction with RoPE/ALiBi/relative position encodings and embedding normalization is not analyzed. Do positional schemes affect the proposed gradient dynamics, particularly at extreme depths?
- Calibration and generalization trade-offs: Keel enables larger learning rates and faster loss descent, but the impact on calibration, uncertainty estimation, and out-of-distribution generalization is not studied. Are there generalization–optimization trade-offs?
- Underperformance cases and failure analysis: In several benchmarks (e.g., ARC-Easy at lower depths, HumanEval at 128L), Pre-LN exceeds Keel. The paper does not analyze why, nor provide guidance on when Keel may be suboptimal. What data/task/model properties predict such reversals?
- Perplexity and language modeling metrics: The abstract claims perplexity gains, but the paper does not report standardized perplexity across depths/datasets. Are the task improvements consistent with perplexity reductions?
- Reproducibility and datasets: Key details (full training corpora composition, tokenization, data filtering, augmentation, exact hyperparameters per experiment) are missing or labeled “internal.” Without these, replicability is limited. Can a public recipe and code be released?
- Fine-tuning and instruction tuning: The behavior of Keel under supervised fine-tuning, instruction tuning, preference optimization (RLHF/DPO), and PEFT/LoRA is unexplored. Does Keel retain its stability and performance under downstream adaptation?
- Safety and robustness: Adversarial robustness, toxicity, bias/fairness, and security implications of deeper Keel models are not evaluated. Does enabling extreme depth introduce new safety or robustness issues?
- Ablation depth of the inner LN: The design evolution narrative suggests successive LN is “crucial,” but there are no quantitative ablations isolating the second LN’s effect across tasks, depths, and learning rates. What is the minimal effective normalization needed?
- Formal taxonomy of “Post-LN” with extra LN: The classification argument hinges on the shortcut being normalized, but the community lacks a standard taxonomy for such hybrids. A formal operational definition and comparative analysis against Sandwich-LN, ResidualNorm, and other hybrids is missing.
- Limits of “infinite-depth” claim: While the theory suggests non-vanishing gradients as L→∞, practical constraints (compute, optimization pathologies, representational saturation) are not characterized. What empirical or theoretical limits cap useful depth under Keel?
Glossary
- AdamW: An optimizer that adds decoupled weight decay to Adam to improve generalization. "We adopt the AdamW optimizer with β1=0.9, β2=0.95, and a weight decay of 0.01."
- Admin: A prior normalization strategy for stabilizing deep Transformers. "Previous attempts to revive Post-LN, such as DeepNorm~\citep{deepnorm}, Admin~\citep{admin}, and more recent hybrid normalization strategies~\citep{mixln, hybridnorm}, mitigate some failure modes..."
- Affine weights (LayerNorm): Learnable scale and bias parameters applied after normalization. "All Layer Normalization operations utilize learnable affine weights () but omit the additive bias term () to improve parameter efficiency and stability."
- AGI-Eval: A benchmark suite used to evaluate general AI capabilities. "AGI-Eval {\scriptsize (0-shot)}"
- ARC-Challenge: A difficult subset of the AI2 Reasoning Challenge benchmark. "ARC-Challenge {\scriptsize (25-shot)}"
- ARC-Easy: An easier subset of the AI2 Reasoning Challenge benchmark. "ARC-Easy {\scriptsize (25-shot)}"
- Attention sink phenomenon: A behavior in attention where certain positions absorb attention disproportionately. "akin to the attention sink phenomenon~\cite{attn-sink, streaming-attn}"
- C-Eval: A Chinese-language evaluation benchmark. "C-Eval {\scriptsize (5-shot)}"
- CMMLU: A Chinese Massive Multitask Language Understanding benchmark. "CMMLU {\scriptsize (5-shot)}"
- CommonsenseQA: A commonsense reasoning benchmark. "CommonsenseQA {\scriptsize (0-shot)}"
- Context scaling: Increasing the context window length as a scaling axis. "context scaling grows increasingly expensive"
- Cosine decay: A learning rate schedule that decays following a cosine curve. "then concludes with a cosine decay to ."
- DeepNorm: A normalization method introducing depth-dependent residual scaling for stable training. "To mitigate this issue, DeepNorm~\cite{deepnorm} introduces a depth-dependent scaling factor on the residual branch"
- Decoder-only: A Transformer architecture using only decoder blocks (no encoder), typical for LLMs. "For the decoder-only architectures, and are set to and , respectively."
- DeltaNet: A recent model related to linear attention and test-time training perspectives. "Recent works \cite{deltanet, lact, titans} interpret this recurrence through the lens of Test-Time Training (TTT)."
- Depth scaling: Increasing the number of layers to expand model capacity. "Depth scaling offers a promising path forward."
- Expressiveness: The capacity of a model to represent complex functions or behaviors. "Keel demonstrates superior expressiveness across the entire depth spectrum ranging from 64 to 1024 layers."
- Feed-Forward Network (FFN): The position-wise MLP sublayer in Transformer blocks. "``layer'' refers to the total count of residual connections, which includes both the Attention and Feed-Forward Network (FFN) layers."
- FineWeb-EDU: A web-derived dataset used for training/evaluation. "FineWeb-EDU dataset~\cite{fineweb}"
- Gradient clipping: Limiting the norm of gradients during training to prevent instability. "Gradient clipping is applied with a maximum norm of 1.0."
- Gradient vanishing: The exponential decay of gradients that hampers learning in deep networks. "ResNet-style residual pathway, which introduces gradient vanishing in deep networks."
- GSM-8K: A grade-school math word problem benchmark. "GSM-8K {\scriptsize (5-shot)}"
- HellaSwag: A commonsense inference benchmark for sentence completion. "HellaSwag {\scriptsize (0-shot)}"
- Highway Networks: Deep networks with gated skip connections controlling carry vs transform. "Highway Networks~\cite{highway} were introduced as an early mechanism for training very deep feed-forward architectures."
- Highway-style connection: A gated or scaled residual pathway that regulates signal flow. "We present Keel, a Post-LN Transformer that replaces this residual path with a Highway-style connection."
- HumanEval: A code generation benchmark evaluating functional correctness. "HumanEval {\scriptsize (0-shot)}"
- HybridNorm: A method that mixes Pre-LN and Post-LN blocks for improved stability/expressivity. "HybridNorm~\cite{hybridnorm}, which interleaves Post-LN and Pre-LN blocks throughout the network"
- Jacobian: The matrix of partial derivatives governing gradient propagation through functions. "During backpropagation, gradients must pass through the Jacobian of LayerNorm"
- Keel: The proposed Post-LN Transformer variant with highway-style scaling and inner normalization. "We present Keel, a Post-LN Transformer that replaces this residual path with a Highway-style connection."
- LaCT: A recent model related to linear attention and TTT perspectives. "Recent works \cite{deltanet, lact, titans} interpret this recurrence..."
- LAMBADA: A language modeling benchmark focusing on long-range context prediction. "LAMBADA {\scriptsize (0-shot)}"
- LLM: A high-parameter Transformer-based LLM. "LLM scaling is hitting a wall."
- Layer Normalization (LayerNorm, LN): A normalization technique applied across feature dimensions. "The placement of Layer Normalization (LN), which is a seemingly simple architectural choice, has an enormous effect on depth scaling."
- LLaMA: A family of open LLMs used as a reference baseline. "This enables stable optimization without special initialization and has become the default in modern LLMs such as GPT-3, PaLM, and LLaMA."
- Maximum Tolerable Learning Rate (Max LR): The highest LR a model can sustain without diverging during warm-up. "we measure the Maximum Tolerable Learning Rate (Max LR)."
- MBPP: A code generation benchmark (Mostly Basic Python Problems). "MBPP {\scriptsize (0-shot)}"
- Mix-LN: A hybrid normalization scheme applying Post-LN in lower and Pre-LN in upper layers. "Mix-LN~\cite{mixln}, which applies Post-LN in lower layers and transitions to Pre-LN in upper layers"
- MMLU: A broad knowledge and reasoning benchmark (Massive Multitask Language Understanding). "MMLU {\scriptsize (5-shot)}"
- PaLM: A large-scale LLM referenced as a Pre-LN user. "has become the default in modern LLMs such as GPT-3, PaLM, and LLaMA."
- Perplexity: A language modeling metric measuring predictive uncertainty (lower is better). "Keel trains robustly at depths exceeding 1000 layers and consistently improves perplexity and depth-scaling characteristics over Pre-LN."
- PIQA: A physical commonsense reasoning benchmark. "PIQA {\scriptsize (0-shot)}"
- Post-LayerNorm (Post-LN): Transformer layout applying LayerNorm after residual addition. "We revisit the Post-LayerNorm (Post-LN) formulation, whose instability at scale caused its replacement by Pre-LN in modern LLMs."
- Pre-LayerNorm (Pre-LN): Transformer layout applying LayerNorm before the sublayer transformation. "The Pre-LN formulation~\citep{xiong2020layernorm} inverts the normalization placement:"
- Residual Networks: Architectures using identity skip connections to ease training of deep nets. "Residual Networks~\cite{resnet} replace the Highway gate with a fixed identity path"
- ResNet-style residual path: The standard additive identity skip connection pathway in residual networks. "the ResNet-style residual pathway, which introduces gradient vanishing in deep networks."
- RMS-based Layer Normalization: A variant of LN normalizing by (root-)mean-square magnitude. "We first define the operation of the RMS-based Layer Normalization (LN) used in the -th layer."
- Scaling factor α: A scalar multiplier applied to the shortcut path to regulate gradient/activation flow. "We introduce a scalar to weight the skip connection, creating a highway-like structure."
- SciQ: A science question answering benchmark. "SciQ \ \small 0-shot"
- Skip connection: A direct pathway that bypasses transformations to aid gradient flow. "We introduce a scalar to weight the skip connection, creating a highway-like structure."
- Test-Time Training (TTT): Adapting model parameters or states during inference via a surrogate objective. "Recent works \cite{deltanet, lact, titans} interpret this recurrence through the lens of Test-Time Training (TTT)."
- Titans: A recent model related to stabilized recurrent/linear attention and TTT. "This creates a compelling parallel with recent advancements in sequence modeling, such as Titans or LaCT."
- Warm-up period: An initial phase where the learning rate is gradually increased to stabilize training. "The learning rate increases linearly from $0$ to $\eta_{\text{peak}$ over the warm-up period."
- Weight decay: L2-regularization-like penalty applied via the optimizer to reduce overfitting. "We adopt the AdamW optimizer with β1=0.9, β2=0.95, and a weight decay of 0.01."
- Width scaling: Increasing model width (e.g., hidden dimension) as a scaling axis. "Width scaling saturates quickly"
- Winogrande: A benchmark for pronoun resolution and commonsense reasoning. "Winogrande {\scriptsize (0-shot)}"
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s findings and methods that organizations can adopt now.
- Stable training of ultra-deep LLMs (software, cloud/AI labs)
- Use Keel blocks to train 128–1024+ layer decoder-only Transformers with higher peak learning rates and fewer divergence events, improving time-to-accuracy and depth utilization over Pre-LN.
- Potential tools/workflows: PyTorch/HuggingFace Keel module; DeepSpeed config with alpha=L per sub-layer count; RMSNorm without bias; AdamW (β1=0.9, β2=0.95), gradient clipping, higher LR warmup schedules; pipeline+activation checkpointing for deep stacks.
- Assumptions/dependencies: Retraining is required (not a drop-in swap for existing Pre-LN checkpoints); careful counting of sub-layers to set α=L; sufficient memory bandwidth and parallelism.
- Higher-learning-rate optimization recipes (MLOps, training efficiency)
- Operationalize “Maximum Tolerable Learning Rate” as a stability KPI and adopt Keel to safely push larger peak LRs for faster convergence without specialized initialization.
- Potential tools/workflows: LR sweep automation that logs Max LR; early training monitors using the three divergence criteria (loss stagnation, irrecoverable instability, optimization degradation).
- Assumptions/dependencies: Monitoring/alerting pipelines; reproducible data pipelines; scheduler support for warmup + cosine decay.
- Domain-specialized LLMs with better math/code reasoning (software, education, finance, developer tools)
- Train or continue-pretrain code/maths-focused models using Keel to exploit the observed +16.5% gains in math/code domains vs. Pre-LN at comparable depth.
- Potential products: IDE copilots with improved synthesis/debug; math tutoring chatbots; financial analytics assistants (SQL, spreadsheet automation).
- Assumptions/dependencies: Access to domain corpora and licensing; evaluation harnesses (HumanEval, MBPP, GSM-8K); alignment/guardrails for safety.
- Cost/performance gains at fixed parameter budgets (cloud cost optimization, energy)
- Replace width-scaling with depth-scaling under Keel to improve expressivity-per-parameter, potentially lowering training compute to reach a target quality.
- Potential workflows: Budget-aware architecture search that prioritizes deeper Keel stacks over wider Pre-LN baselines; pipeline-parallel depth partitioning to improve device utilization.
- Assumptions/dependencies: Activation checkpointing to control memory; careful latency/throughput modeling (deep models can increase token latency).
- Safer training runs in production (AI platform reliability)
- Reduce catastrophic divergence incidents at large depth and aggressive LRs using Keel’s stabilized residual pathway and additional LN.
- Potential tools: Training runbooks that codify Keel’s init (gamma-only LN, no beta), first sublayers as Pre-LN (no α), gradient clipping, and LR ceilings discovered via Max LR evaluations.
- Assumptions/dependencies: Adherence to the implementation details; CI for sanity checks on layer counts and α configuration.
- Long-context model training with orthogonal attention upgrades (NLP systems)
- Combine Keel with existing long-context techniques (RoPE, FlashAttention, GQA, sparse/linear attention) to improve optimization stability while scaling sequence length.
- Potential products: Document/intelligence assistants for legal and biomedical records with more consistent training at depth.
- Assumptions/dependencies: Long-context memory optimizations; data curation for long-sequence tasks; empirical validation for target domains.
- Academic benchmarking and theory replication (academia)
- Use Keel to study extreme-depth scaling laws, gradient dynamics, and expressivity vs. Pre-LN under controlled datasets and token budgets.
- Potential tools: Open-source Keel reference block, depth-scaling benchmark suite (64–1024+ layers), Max LR reporting in papers/model cards.
- Assumptions/dependencies: Transparent datasets and compute budgets; community benchmarks to ensure fair comparisons.
- Training diagnostics and model cards (policy, transparency)
- Report Max LR and divergence criteria alongside standard metrics to improve training transparency and reproducibility claims.
- Potential workflows: Extend model cards with stability envelopes (peak LR ranges, depth limits) and training anomaly logs.
- Assumptions/dependencies: Organizational policy buy-in; standardized logging and retention.
- Faster continued pretraining and instruction tuning (industry R&D)
- Apply Keel to CPT and instruction-tuning phases to support higher LRs with reduced instability, shortening iteration cycles on foundation models.
- Potential tools: Keel-aware LoRA/adapters for deep stacks; curriculum schedules that exploit stable large-step training.
- Assumptions/dependencies: Re-implementation of blocks within finetuning frameworks; validation of learning-rate scaling in each phase.
- Depth-friendly parallelization plans (HPC, systems)
- Prefer deeper architectures for improved pipeline parallelism across many accelerators, easing model-parallel pressure from width.
- Potential workflows: Pipeline partitions by sub-layer; interleave attention/FFN stages to balance bubbles; activation rematerialization tuned for deep stacks.
- Assumptions/dependencies: Compiler/runtime support; profiling and schedule tuning; cross-node bandwidth.
Long-Term Applications
These opportunities build on the paper’s results but require further research, scaling, or engineering before broad deployment.
- Infinite-depth or dynamic-depth Transformers (software, energy)
- Move toward architectures with unbounded or adaptive depth, leveraging Keel’s non-vanishing gradients to support learned halting/early-exit for per-token compute control.
- Potential products: Latency-aware LLMs that adapt depth per query; energy-saving inference for mobile/edge.
- Assumptions/dependencies: Robust dynamic-depth controllers; calibration to maintain quality under early exit; compiler/runtime support.
- Narrow-and-deep on-device models (edge AI, robotics, IoT)
- Replace width with depth to fit memory-constrained environments while improving expressivity per parameter.
- Potential products: On-device task assistants, robotic planners with better logical depth, local coding aides.
- Assumptions/dependencies: Quantization/pruning for very deep stacks; memory-efficient KV/state handling; heat/latency constraints on-device.
- Depth-wise test-time training (TTT) and sequence-depth unification (research, novel architectures)
- Exploit the paper’s depth–sequence TTT duality to design models that adapt online across layers (depth) during inference, similar to recurrent state updates over time.
- Potential tools: Depth-wise meta-learning objectives; “optimizer-in-the-architecture” designs adapted from linear attention TTT.
- Assumptions/dependencies: New objectives, stability analyses, and safety/robustness studies for adaptive inference.
- Hardware and compiler co-design for deep stacks (semiconductors, systems)
- Architect accelerators and compiler passes that exploit repeated, stabilized blocks (weight streaming, kernel fusion, intra-layer reuse) across 1000+ layers.
- Potential products: Depth-optimized ASICs/ISAs; scheduler passes that minimize activation traffic for Keel-style nets.
- Assumptions/dependencies: Vendor roadmaps, software stacks (XLA, Triton), standardized Keel blocks.
- New scaling laws and capability forecasting (academia, policy)
- Establish depth-centric scaling laws (quality vs. depth vs. tokens) to refine compute governance and capability predictions.
- Potential outputs: Policy briefs guiding compute allocation, environmental impact assessments when substituting width with depth.
- Assumptions/dependencies: Public datasets of deep-model runs; cross-lab replication; standardized reporting (Max LR, divergence envelopes).
- Agentic systems and planning-intensive tasks (autonomy, enterprise workflows)
- Deploy deeper Keel-trained models for hierarchical planning, tool-use, and multi-step reasoning (e.g., software engineering, supply chain optimization).
- Potential products: Stronger agent frameworks for codebases, data pipelines, logistics planning.
- Assumptions/dependencies: Tool integration (APIs, sandboxes), safety layers for execution, rigorous evals on planning benchmarks.
- Scientific and mathematical discovery assistants (healthcare, materials, physics)
- Train Keel-based reasoning models to assist with hypothesis generation, theorem proving, protocol optimization, and code-driven simulations.
- Potential products: Lab copilots; theorem-proving LMs; AutoML-for-science loops with stronger math/code competence.
- Assumptions/dependencies: Curated scientific corpora; verification pipelines; regulatory and IP controls.
- Sector-specific reasoning copilots (finance, law, engineering)
- Build high-precision copilots that rely on deep-chain reasoning (regulatory compliance analysis, risk modeling, formal specs).
- Potential products: Finance risk/code copilots, legal reasoning aides, engineering design validators.
- Assumptions/dependencies: Domain data access and compliance (HIPAA, GDPR, SOX); guardrails for sensitive outputs; human-in-the-loop review.
- Safety, evaluations, and governance adapted to depth (policy, AI safety)
- Update capability and risk evaluation protocols to account for depth-driven gains (especially in coding/math), including red-teaming for newly emergent behaviors.
- Potential outputs: Depth-aware eval tracks; model cards with depth/stability disclosures; procurement standards that compare depth vs. width impacts.
- Assumptions/dependencies: Community benchmarks; standardized risk taxonomies; regulatory engagement.
- Distillation and dynamic compute allocation (inference efficiency)
- Distill very-deep Keel models into shallower student nets or build mixture-of-depth experts that route tokens to minimal sufficient depth.
- Potential products: Tiered inference endpoints (fast vs. thorough modes), cost-aware serving.
- Assumptions/dependencies: Effective depth-aware distillation methods; routing policies; serving infrastructure.
- Interoperability with long-context, linear, and state-space models (research, product)
- Combine Keel with linear/state-space attention for scalable sequence+depth regimes (very long docs + very deep reasoning).
- Potential products: Enterprise retrieval+reasoning systems for e-discovery, biomedical literature, codebases.
- Assumptions/dependencies: Stability at joint extremes (depth × length); memory management; end-to-end evals.
- Environmental impact reduction via depth-first scaling (sustainability, policy)
- If depth yields better quality-per-flop than width, retrain sustainability strategies around deep Keel stacks, potentially lowering energy to a target capability.
- Potential outputs: Carbon accounting methods that consider depth scaling; procurement guidance for greener training.
- Assumptions/dependencies: Independent LCA studies; reproducible comparisons across depth/width regimes; hardware efficiency co-factors.
Collections
Sign up for free to add this paper to one or more collections.