- The paper introduces StepsNet, a progressive residual architecture that effectively overcomes shortcut degradation and width constraints.
- It splits input channels and stacks progressively wider sub-networks to sustain signal flow and enhance deep model performance.
- Empirical results show significant improvements in accuracy, throughput, and memory efficiency across various tasks.
Step by Step Network: Overcoming Depth Limitations in Residual Architectures
Introduction and Motivation
The exponential representational capacity of deep neural networks is well-established in theoretical literature, indicating that deeper models can, in principle, learn more complex functions than shallow ones. Residual architectures such as ResNet have enabled practical scaling to hundreds of layers without optimization collapse. However, despite their successes, empirical evidence shows that simply increasing depth in contemporary architectures often fails to yield proportional performance improvements, even with stable training. Analysis in "Step by Step Network" (2511.14329) identifies two core limitations responsible for the diminished returns of extreme depth: shortcut degradation and constrained width under computational budgets. This work introduces StepsNet, a macro-architectural reparameterization that addresses these limitations by progressive, channel-wise residual processing, decoupling width and depth scaling.
Analysis of Deep Residual Challenges
Shortcut Degradation
Residual connections are designed to facilitate gradient flow and information propagation by summing the input to a block with its nonlinear transformation. In standard implementations, the variance of features increases with depth, causing early inputs' contributions (the shortcut) to diminish as layers accumulate more noisy residual terms. This shift negatively affects both forward signal transmission and backward gradients. The shortcut ratio γl=σlσ0 quantifies the proportion of preserved input signal at layer l and declines precipitously in deep architectures, as demonstrated by empirical measurements in DeiT models.

Figure 1: Shortcut ratio γl sharply drops with depth in standard DeiT, while Steps-DeiT sustains high shortcut preservation across layers, mitigating degradation and facilitating optimization.
Width-Depth Trade-Off
Under a fixed FLOP budget, increasing the depth of a model mandates a proportional reduction in layer width, per O(C2D) scaling for typical attention and MLP blocks. Theoretical results indicate that networks with insufficient width, despite extreme depth, cannot universally approximate complex functions. This architectural bottleneck is a key constraint, leading to suboptimal performance in very deep residual models compared to shallower, wider baselines operating with the same computational cost.

Figure 2: StepsNet architecture mitigates the width-depth trade-off by splitting channels and stacking progressively wider sub-networks, enabling deeper models with fixed width and computation.
The Step by Step Network Architecture
StepsNet reformulates residual architectures to address both shortcut degradation and width limitation. The basic idea is to split the input feature along the channel dimension and process it sequentially with sub-networks of increasing width. Concretely, an input x is decomposed into [x1,x2,...,xn] and processed by a stack of networks F1,F2,...,Fn, where each Fi operates on the aggregation of previously computed outputs and a new channel group. This progressive strategy preserves input information, prevents early shortcut collapse, and allows for concurrent scaling of depth and width beyond the limitations of monolithic residual blocks.
Empirical Validation
Experiments across ImageNet-1K, COCO detection, ADE20K segmentation, and WikiText-103 language modeling confirm that StepsNet consistently outperforms conventional residual baselines at increased depth, often with identical parameter count and computation. Notably, StepsNet achieves marked gains in both training and test accuracy as depth increases, where standard models plateau or even degrade.
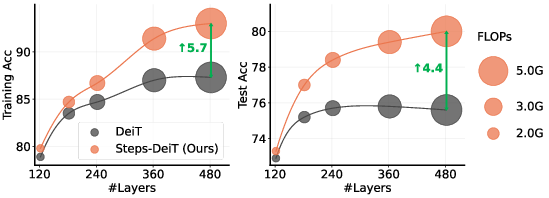
Figure 3: In deeper scaling experiments, standard DeiT accuracy stagnates while StepsNet leverages added depth for significant gains in both train and test performance.
Throughput and Memory Efficiency
StepsNet design induces improved computational throughput and memory efficiency due to reduced width penalties at large depths. Evaluations indicate 1.3x–1.4x throughput advantage and lower memory consumption compared to equivalently deep standard models, facilitating practical deployment of deeper architectures even on constrained hardware.
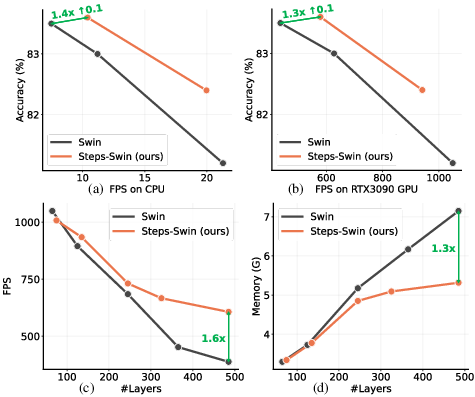
Figure 4: StepsNet models deliver superior throughput-accuracy and memory-accuracy trade-offs on both CPU and GPU across varying depths.
Broad Task Generality
StepsNet's macro-architecture is agnostic to micro-level block designs (convolutional, Transformer, or hybrid structures), as validated by performance improvements in ResNet, DeiT, Swin Transformer, and language modeling architectures. Integration with advanced block components further boosts results, demonstrating the versatility of the approach.
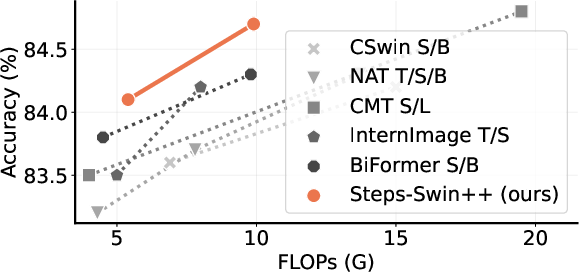
Figure 5: StepsNet consistently surpasses state-of-the-art methods on ImageNet-1K classification benchmarks.
Implications and Prospects
StepsNet's architectural paradigm enables deeper networks to actualize their theoretical expressivity without succumbing to optimization instability or width starvation. From a practical standpoint, this facilitates the construction of ultra-deep models for tasks demanding intricate pattern recognition. Theoretically, StepsNet invites further exploration of progressive feature channel allocation and multi-path residual stacking as general tools for overcoming scaling bottlenecks.
In language modeling, the persistent validity of StepsNet in decoder-only Transformer settings (as demonstrated on WikiText-103) suggests that similar macro-architectural reparameterizations could be applied for efficient scaling of autoregressive and sequence models, potentially contributing to advances in reasoning tasks as depth increases.
The macro design's compatibility with various micro optimizations (initialization schemes, normalization, attention variants) positions StepsNet as a robust base for further neural architecture search and automated design methods.
Conclusion
"Step by Step Network" establishes a principled and empirically validated macro-architecture for deep networks, resolving both shortcut degradation and width constraints inherent in standard residual models. By progressive channel-wise processing and narrow-to-wide stacking, StepsNet unlocks performance gains at large depths within fixed computational budgets, generalizing across architectures and tasks. This work provides a solid foundation for future explorations in scalable architectural design, advancing the frontier of deep model capacity and applicability.