- The paper demonstrates that a single-layer MoE transformer can encode task-specific knowledge circuits to achieve perfect expert isolation.
- It formalizes task complexity using template lengths and dictionary sizes, enabling precise expert routing via multi-head attention.
- Empirical results show task-aware routing consistently attains over 88% accuracy, supporting modular interpretability and scalable design.
Introduction
This paper ("A theoretical model for task routing in mixture-of-expert transformers" (2606.14398)) develops a rigorous mathematical framework for explaining task-expert specialization in Mixture-of-Expert (MoE) transformers, especially as applied to discrete structured language tasks. While empirical evidence has demonstrated that MoE transformers naturally partition tasks among specialized expert modules, prior theoretical works largely focused on continuous mixture models and non-attentive architectures, failing to account for the discrete and syntactic nature of language. The present work provides foundational results demonstrating that a single-layer MoE transformer, when constructed appropriately, can encode task-specific knowledge circuits, achieving exact task routing and perfect task-expert isolation. The expressivity and modularity are characterized in terms of syntactic templates and finite key-value dictionaries; expert size is shown to scale additively with the intrinsic complexity of the assigned task.
The authors develop a synthetic knowledge data model based on templates and dictionaries. Templates are sentence patterns with wildcard slots for keys and values, and knowledge tasks consist of finite sets of key-value pairs instantiated in templates. Complexity is formalized as the sum of template lengths and dictionary sizes per task, capturing both syntactic and semantic load. This granular formalization enables precise specification of what constitutes a "task" for the purposes of routing and specialization.
Dense transformer and MoE transformer variants are introduced, with attention heads separating structural tokens from factual tokens. The MoE modification replaces feedforward blocks with a set of expert networks coupled to a gating function; top-1 expert routing activates one expert per token.
(Figure 1)
Figure 1: Architectural schematic showing attention separation of template structure from dictionary tokens and subsequent routing to task-specific experts, where expert size scales with task complexity.
Main Theoretical Results
The first theoretical result establishes that dense single-layer transformers can encode structured knowledge using localized, sparse knowledge circuits. For any collection of knowledge tasks, a transformer can be constructed such that for inputs belonging to a specific task, computation activates a strictly isolated subset of neurons in the feedforward layer and attention heads. The neuron count required per task is bounded by the combined size of the associated templates and dictionary.
The central claim demonstrates that a single-layer MoE transformer, equipped with multi-head attention, can exactly route any input sequence generated from a task's templates to the corresponding expert. Each expert's required width is strictly determined by the number of unique template prefixes and dictionary entries for its assigned task. The attention heads disentangle template structure from factual tokens, enabling the router to leverage structural information for expert assignment. The construction ensures that, with proper linear scaling of the output logits, prediction error can be made arbitrarily small.
Notably, the expressiveness proof sidesteps continuous clustering assumptions prevalent in prior MoE theory. Instead, the analysis operates on discrete symbolic structures, explicitly modeling key-value recall and template parsing. This provides a direct theoretical underpinning for empirical observations of modular knowledge circuits and task specialization in MoE transformers.
Proof Techniques
The constructions employ explicit partitioning of embedding space, gradient-based memorization of finite mappings, and linear independence arguments for attention vector separation. Sparse circuit isolation is achieved by zeroing out off-task blocks in the feedforward layer. The router's linear map is crafted so that structural features (template prefixes) uniquely identify the expert block for a task. Output logits exploit a two-dimensional subspace arrangement, guaranteeing that token prediction probabilities concentrate on valid next tokens for each input prefix.
Empirical Validation
Experiments are conducted with synthetic datasets generated from WikiData5M: templates (relation-specific) and entity pairs are used to instantiate diverse knowledge sentences. MoE transformers are trained with varying auxiliary objectives: cross-entropy alone, cross-entropy plus load balancing, and cross-entropy plus explicit task-router loss.
Task-expert routing distributions are visualized, revealing that only with explicit task-router loss does modular specialization emerge, with clear one-to-one task-expert correspondence. In contrast, cross-entropy and load balancing objectives yield diffuse, unaligned routing patterns.
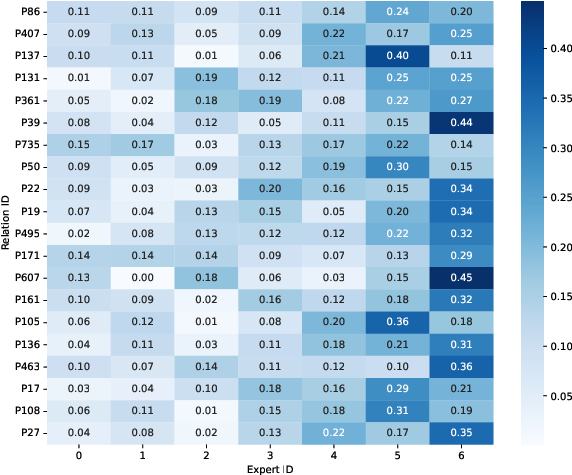
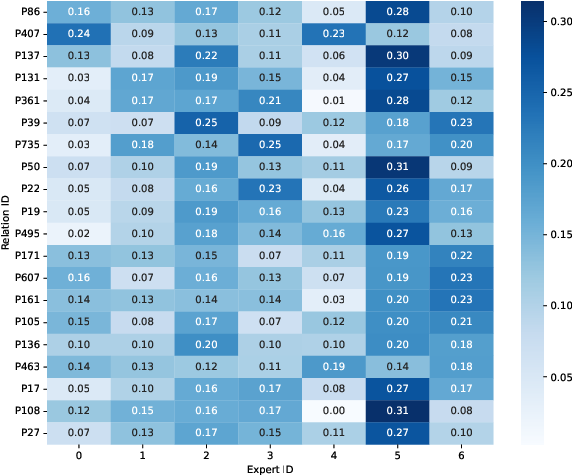
Figure 2: Cross-entropy only loss results in diffuse task-expert routing distributions, lacking modular specialization.
Performance metrics show that task-aware routing produces comparable or superior accuracy across different configurations, with accuracy consistently exceeding 88% in all variants and peaking at over 92% when task-expert alignment is enforced. Expert specialization does not degrade predictive performance and facilitates modularity.
Implications and Theoretical-Practical Interface
The results provide a formal mechanism explaining observed modularity and interpretability phenomena in frontier MoE LLMs, directly supporting mechanistic interpretability claims around localized knowledge circuits and domain-specific expert modules. The mathematical model clarifies how MoE transformers can achieve parameter-efficient specialization—minimizing redundant computation by scaling expert size with actual task complexity, rather than aggregate model size.
Practically, this blueprint may inform future MoE model designs targeting improved interpretability, safer knowledge attribution, and inference-time speedups via reduced active parameter count. Sequence-level routing (as explored in related literature) and deeper MoE layers present promising avenues for extending these theoretical results to more complex settings (e.g., hierarchical grammars, multi-step reasoning chains, and domain adaptation scenarios).
Limitations and Future Directions
The current analysis is restricted to single-layer MoE transformers with template-based synthetic tasks. Extending the theoretical model to deeper architectures, incorporating hierarchical context-free structures, and generalizing to sequence-level routing mechanisms are identified as open problems. Additionally, it is suggested that sequence/global routing (without explicit task labels) may foster higher-level semantic specialization, potentially aligning with unsupervised domain discovery in large-scale pretraining.
Conclusion
This work formally establishes that MoE transformers can exactly modularize discrete knowledge tasks using specialized experts, with expert capacity scaling additively in task complexity. The construction leverages multi-head attention for structural disentanglement and router-based task assignment. Empirical results show that task-aware routing is necessary to achieve modular specialization. The framework supplies a theoretical basis for empirical modularity and interpretable circuits in MoE LLMs and lays the groundwork for future research into scalable, efficient, and interpretable expert architectures in AI.

