The Myth of Expert Specialization in MoEs: Why Routing Reflects Geometry, Not Necessarily Domain Expertise
Abstract: Mixture of Experts (MoEs) are now ubiquitous in LLMs, yet the mechanisms behind their "expert specialization" remain poorly understood. We show that, since MoE routers are linear maps, hidden state similarity is both necessary and sufficient to explain expert usage similarity, and specialization is therefore an emergent property of the representation space, not of the routing architecture itself. We confirm this at both token and sequence level across five pre-trained models. We additionally prove that load-balancing loss suppresses shared hidden state directions to maintain routing diversity, which might provide a theoretical explanation for specialization collapse under less diverse data, e.g. small batch. Despite this clean mechanistic account, we find that specialization patterns in pre-trained MoEs resist human interpretation: expert overlap between different models answering the same question is no higher than between entirely different questions ($\sim$60\%); prompt-level routing does not predict rollout-level routing; and deeper layers exhibit near-identical expert activation across semantically unrelated inputs, especially in reasoning models. We conclude that, while the efficiency perspective of MoEs is well understood, understanding expert specialization is at least as hard as understanding LLM hidden state geometry, a long-standing open problem in the literature.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple overview
This paper looks at how Mixture‑of‑Experts (MoE) LLMs decide which “experts” to use for each word they read or generate. Many people assume different experts specialize in clear topics like math, code, or sports. The authors argue that’s a myth. They show the routing mostly follows the shape of the model’s internal representations (its “geometry”) rather than human-friendly categories like “math expert.” In short: similar internal states lead to similar experts, and that explains most “specialization.”
What were the big questions?
- What actually causes expert “specialization” in MoE models?
- Do the experts line up with human ideas of topics or domains?
- How stable and predictable are expert choices across different models, prompts, and layers?
How did they study it? (With simple analogies)
First, a few key ideas in everyday language:
- MoE model: Imagine a school with many classrooms (experts). Each token (word piece) goes to a few classrooms for processing.
- Router: A hallway monitor who gives each classroom a score for a token and picks the top ones. The router is a simple linear rule—like using a ruler to project a point on a line—no fancy curves.
- Hidden state: The model’s internal “picture” of a token, like coordinates on a map showing where that token sits in idea-space.
- Load balancing: A rule that tries to keep classrooms from getting overcrowded, spreading tokens out more evenly.
What they did:
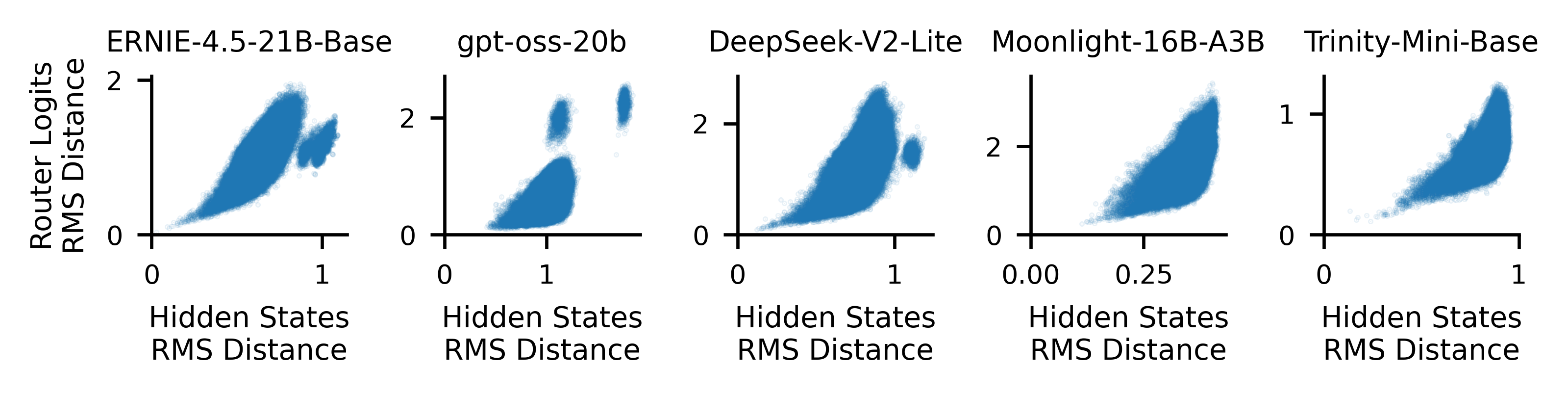
- Math proof and measurements: They proved that if two tokens end up with similar internal coordinates (hidden states), the router will give them similar classroom scores, so they’ll visit similar experts. They then checked this on several real MoE models.
- Sequence-level tests: They pooled (averaged) token information from whole sentences or documents and compared how similar the internal representations were to how similar the expert usage was. More similar representations → more similar expert usage.
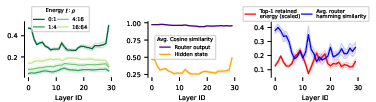
- Training behavior: They analyzed how the “keep classes balanced” rule affects routing. They showed it tends to ignore features that many tokens share, so experts don’t all get the same tokens.
- Stress tests: They checked tricky cases:
- Different models solving the same math problem.
- Same prompt vs the continuing generated text (“prefill” vs “rollout”).
- Early layers vs deeper layers.
- In‑distribution (normal) inputs vs shuffled/reversed (out‑of‑distribution) inputs.
What did they find, and why does it matter?
Here are the main findings, with simple explanations:
- The router follows geometry, not topic labels.
- Finding: Because the router is a linear projector, similar hidden states produce similar expert scores. That means “specialization” shows up because of where tokens land on the model’s internal map, not because experts have built‑in topic roles.
- Why it matters: We shouldn’t assume there’s a “math expert” just because math texts activate certain experts—what we’re seeing may just be clusters on the internal map.
- Load balancing suppresses shared directions.
- Finding: The “keep classrooms balanced” rule pushes the router to ignore common features shared by many tokens (like everyone wearing the same school uniform). This keeps tokens from all piling into the same experts.
- Why it matters: This explains why training with small, not‑very‑diverse batches can cause “specialization collapse” (everyone ends up in the same or similar experts). The router chases moving “shared features” and can’t find stable, useful differences.
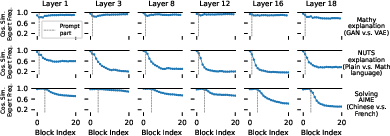
- Expert usage is context‑dependent and layer‑dependent.
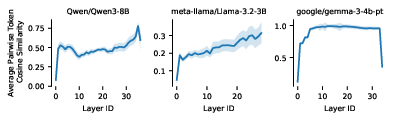
- Finding: The same word (“apple”) in different contexts gets routed differently in deeper layers. Early layers reflect the word itself; later layers reflect how it interacts with the whole sentence.
- Why it matters: You can’t label an expert just by the word it sees—context matters, especially deeper in the network.
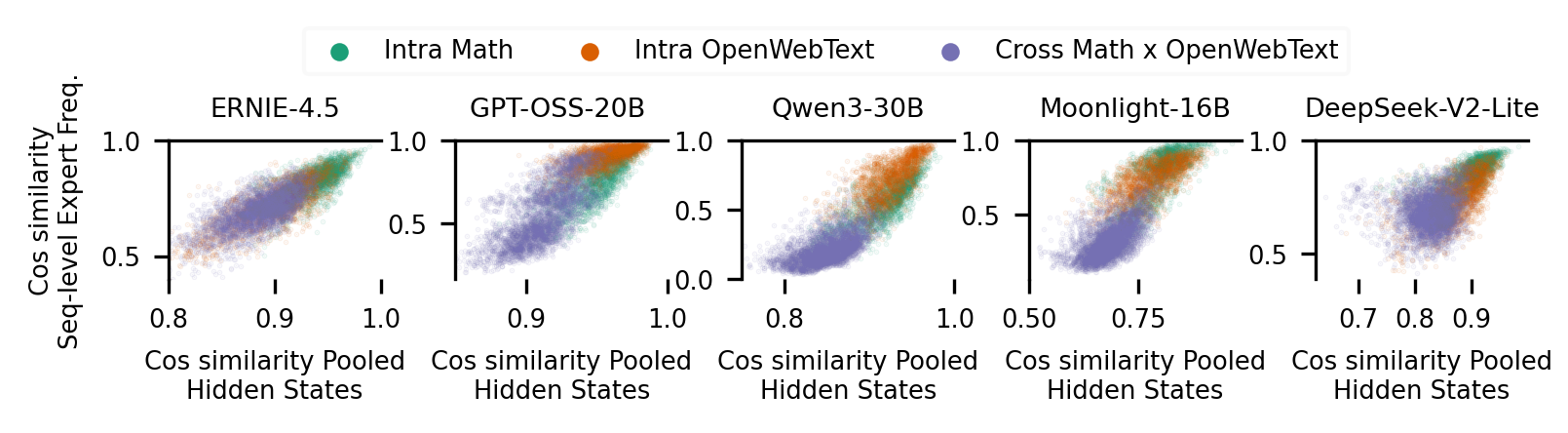
- Similar inputs activate similar experts; dissimilar inputs might still share experts.
- Finding: At the sequence level, more similar hidden states → more similar expert usage. But the reverse isn’t guaranteed: different inputs can still end up using similar experts.
- Why it matters: This makes “reading” experts to understand content tricky. Expert patterns aren’t a neat one‑to‑one map to topics.
- Different models solving the same problem do not use the same experts.
- Finding: Two different MoE models answering the same math question overlap only about 60% in their most-used experts—about the same as if they answered different questions.
- Why it matters: Expert choices aren’t a stable “signature” of the problem. Model‑specific differences matter a lot.
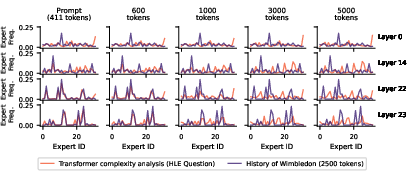
- Prompt routing doesn’t predict generation routing.
- Finding: During the prompt (prefill), expert usage can look nearly identical across different prompts. Once the model starts generating, the patterns can stay similar or diverge sharply—and you can’t tell which will happen just from the prompt.
- Why it matters: If you only look at the prompt, you might misunderstand how experts behave during the actual answer.
- Deep layers can “collapse” during the prompt, then split during generation.
- Finding: In some models, very different prompts use almost the exact same experts in the last layers while reading the prompt. But once the model starts writing, their expert usage separates.
- Why it matters: It’s risky to judge specialization from prompt‑only tests. Also, pruning experts based on prompt behavior can look harmless—but it hurts once generation starts.
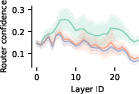
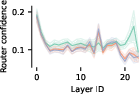
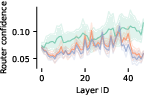
- Routers are less confident on jumbled inputs (OOD).
- Finding: When sentences are shuffled/reversed (nonsense), the router’s top score is lower. That matches the idea that the router learned to align with normal data patterns.
- Why it matters: Router confidence can help detect out‑of‑distribution inputs.
Simple implications and potential impact
- Interpreting experts is hard: Understanding which experts fire is at least as hard as understanding the model’s internal map (the hidden‑state geometry)—a long‑standing open problem. Don’t expect simple “math expert/coding expert” labels to hold up.
- Training tips: Keep batches diverse and tune load balancing carefully. Otherwise, routing can collapse and waste the benefits of MoE (experts become redundant).
- Evaluation tips: Don’t judge specialization from prompts alone. Check full generations and multiple models. Look across layers, not just one.
- Practical uses:
- Out‑of‑distribution detection: Router confidence can flag weird inputs.
- Privacy caution: Because routing depends on hidden states, expert patterns may leak information about inputs as a side channel.
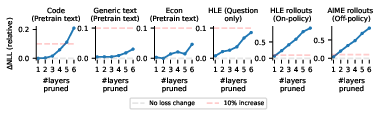
- Pruning with care: Experts that seem unnecessary during prefilling can be crucial during generation.
Takeaway
MoE “specialization” mostly reflects where tokens sit on the model’s internal map. That map—not topic labels—drives which experts are used. So, while MoEs are great for efficiency, making their expert choices understandable to humans is a much tougher challenge.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances a geometric account of MoE routing but leaves several concrete issues unresolved. Future work could address the following:
- Formal link from logit similarity to discrete expert selection
- Theoretical results bound router logit differences via hidden-state projections, but do not rigorously translate these bounds to top‑k expert overlap (a discontinuous operation). Can we derive probabilistic guarantees relating logit bounds to expected overlap under realistic logit distributions and gating noise?
- Assumptions behind Proposition 1
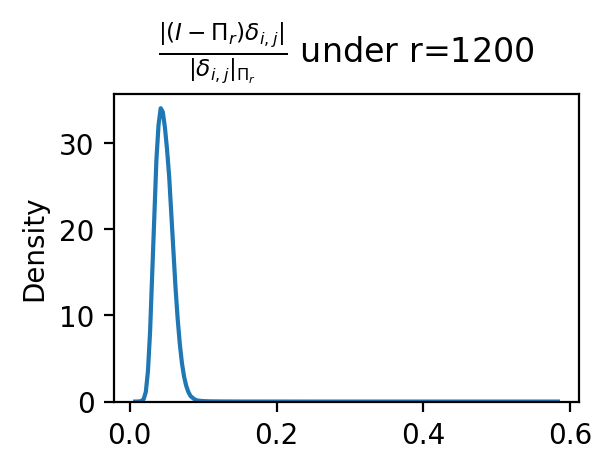
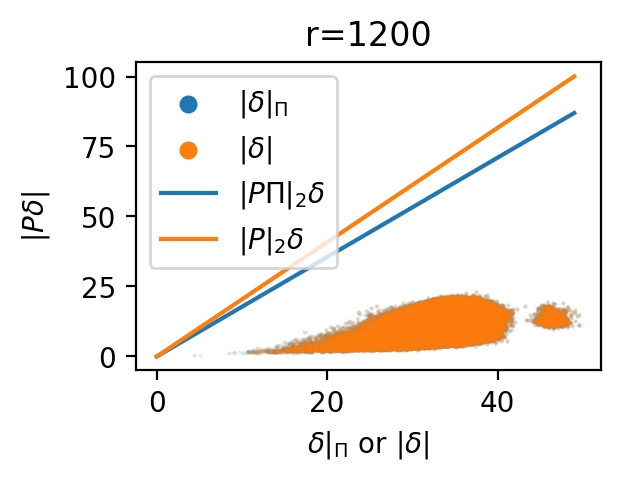
- The bound relies on “variance concentrated in top‑r directions” and an SVD-based projector; r is not algorithmically selected and robustness to heavy-tailed spectra or anisotropic noise is untested. How sensitive are conclusions to choice of r and to non-ideal spectra across layers and datasets?
- Informal and restrictive load-balancing theory
- Proposition 2 assumes the small-logit regime and a simplified loss. Do routers in practice operate in this regime, and does the suppression of shared directions persist when logits are large and balancing losses follow real implementations (e.g., auxiliary with capacity constraints)?
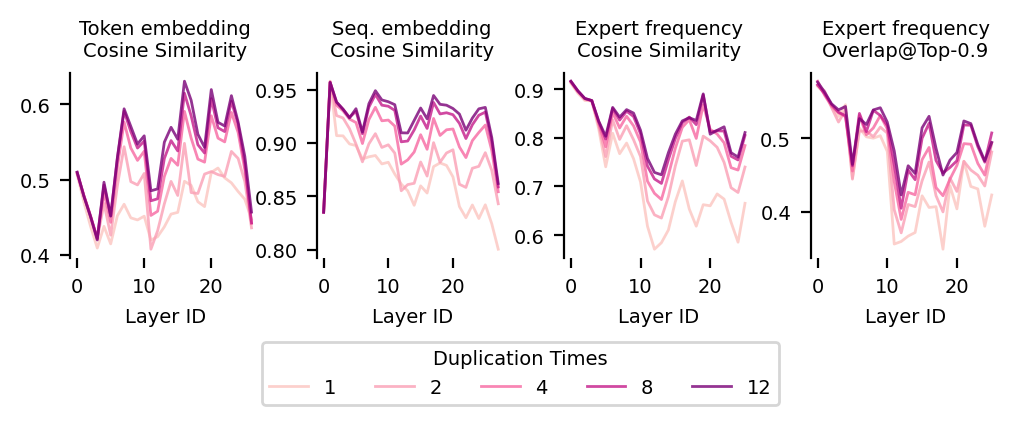
- Lack of controlled pretraining experiments
- The hypothesized causal role of load balancing, batch diversity, and data heterogeneity in shaping P’s alignment with the data subspace is not tested via controlled training sweeps (varying auxiliary coefficient, micro/global batch, curriculum, capacity factor). Can controlled ablations causally validate the suppression mechanism and replicate “specialization collapse”?
- Generality across router designs
- Analyses focus on linear routers without bias and standard top‑k. Many MoEs add jitter/noise, biases, learned temperature, expert capacity/dropping, shared experts, or non-linear gating. Do the geometric conclusions hold and how do these design choices alter alignment and specialization?
- Mapping from hidden-state geometry to interpretability
- The work argues that understanding specialization reduces to understanding hidden-state geometry but does not propose tools to interpret which geometric directions correspond to semantics, syntax, or computation. What representation axes drive routing in different layers, and can we causally steer them?
- Prefill vs generation dynamics: mechanism and control
- Router “collapse” during prefilling is observed in some models and hypothesized to stem from output-format regularities, but is not causally tested. How do prompts, system templates, decoding parameters (temperature/top‑p), and early-output scaffolds control collapse and the subsequent divergence during rollout?
- Cross-model specialization divergence for identical problems
- Different models solving the same math question share only ~60% of top‑p experts, but the drivers (architecture, tokenizer, data, router init, balancing schedules) are not disentangled. Can same-architecture, same-data, multi-seed training isolate which factors dominate cross-model divergence?
- OOD detection via router confidence: realism and calibration
- OOD is simulated by shuffling/reversing tokens; real OODs (domains, dialects, modalities, adversarial texts) are not evaluated. How does router confidence perform under realistic OOD, with ROC/AUPR and calibration metrics, and does performance depend on load balancing, depth, or sparsity ratio?
- Depth-wise evolution and rank collapse
- Hidden-state correlation growth with depth is shown in some models; the cause, dependence on architecture (pre-/post-norm), and mitigation are not studied. Can architectural variations or regularizers (e.g., anti-collapse objectives) modulate depth-wise routing diversity without hurting performance?
- Scope across tasks and languages
- Experiments emphasize English web/math and a few reasoning/instruction models. Do the findings hold across multilingual, code-heavy, speech-text, or multimodal MoEs, and in low-resource settings where specialization is claimed to help most?
- Dataset-level pooling choices
- Sequence similarity relies on pooled hidden states and cosine metrics (details deferred). How do alternative pooling strategies (CLS-like tokens, attention-weighted pooling, layer ensembles) affect the correlation between sequence similarity and expert usage?
- Role of attention vs FFN geometry
- The analysis centers on residual-stream hidden states; the contribution of attention outputs vs MLP activations to routing geometry is not separated. Can we attribute routing-relevant directions to attention heads or FFN subspaces?
- Capacity factor and k/E sensitivity
- The impact of sparsity level (k/E), capacity constraints, and top‑1 vs top‑2/top‑k routing on specialization stability and alignment is not quantified. Are there scaling laws linking sparsity, r (effective rank), and specialization robustness?
- Expert redundancy and “committee” characterization
- While a shared “committee” of frequently-used experts is discussed, redundancy and functional overlap among those experts are not quantified. Can we measure and reduce redundancy without harming performance, and do committee experts encode generic computations (e.g., syntax) across domains?
- Privacy implications not evaluated
- Although routing patterns may leak information, the paper offers no quantitative leakage assessment or mitigations (e.g., noise injection, aggregation, or obfuscation) and does not explore the trade-off with performance/efficiency.
- Robustness to tokenization and positional encodings
- Effects of tokenizer choices and positional encoding variants on hidden-state geometry and routing are not examined. Do certain tokenization schemes induce stronger shared directions and thus more collapse?
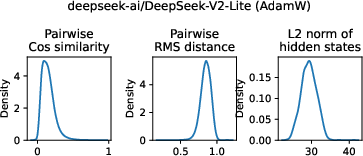
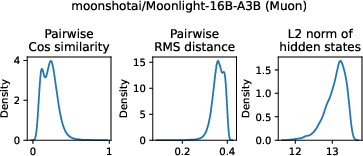
- Sensitivity to normalization and training optimizers
- Differences between auxiliary-free (e.g., Muon) and auxiliary-based training are observed but not systematically dissected. How do optimizer choices, normalization schemes, and weight decay interact with router–data alignment?
- Causal interventions on geometry
- Beyond duplication, there are no interventions that directly modify hidden-state directions (e.g., projecting out top PCs, steering vectors, or subspace perturbations) to test causal effects on routing and specialization.
- Downstream performance linkage
- The relationship between specialization patterns and task performance is not established beyond NLL changes under pruning. Do specific specialization profiles predict accuracy, robustness, or reasoning quality, and can we optimize for beneficial profiles?
- Scaling behavior and emergence over training
- The evolution of PΠ_r alignment, hidden-state spectra, and specialization over training epochs and with model size is not studied. Are there predictable phases where specialization emerges, saturates, or collapses?
- Non-language MoEs and cross-modality
- The conclusions are not tested in vision, speech, or multimodal MoEs, where input geometry and router usage could differ substantially. Do geometry-driven routing principles generalize across modalities?
- Top‑k stochasticity and stability
- The impact of router noise/jitter and sampling stochasticity on expert overlap and reproducibility (within and across seeds) is not quantified. How stable are specialization patterns under repeated runs and minor input perturbations?
- Limits of sample sizes in SVD-based analyses
- Many SVD and alignment measurements use small batches (e.g., 16 sequences), which may bias principal directions. How do results change with much larger, more diverse samples and across different domains?
Practical Applications
Immediate Applications
The following applications can be deployed with current MoE LLMs and training stacks by leveraging the paper’s findings that expert routing is a linear projection of hidden states and that load-balancing suppresses shared hidden-state directions. Each item notes sectors, potential tools/workflows, and key dependencies.
- Stronger OOD gating via router confidence
- Description: Use the router’s max-softmax over expert logits as an additional OOD score; the paper shows this confidence drops on out-of-distribution sequences (e.g., reversed/shuffled inputs).
- Sectors: software/SaaS, safety, healthcare, finance
- Tools/workflows: Add a router-confidence threshold before generation to trigger fallbacks (e.g., a safer dense model, extra moderation, human handoff).
- Assumptions/dependencies: Token-choice, linear routers; observed alignment between router and in-distribution hidden-state subspace; threshold tuning per-deployment.
- Two-phase inference optimization (prefill vs decode)
- Description: Exploit observed “router collapse” in later layers during prefilling—many prompts use near-identical experts—by pruning or caching experts in deeper layers for prefill only, then re-enabling full routing for decode when divergence appears.
- Sectors: cloud inference, edge AI, software
- Tools/workflows: Phase-aware routing policy; expert caching/warming; NLL-based regression tests (as in paper’s pruning study).
- Assumptions/dependencies: Collapse is model- and training-regimen-dependent; verify on your model (don’t generalize from prompts to decode).
- Training diagnostics for healthy specialization
- Description: Monitor hidden-state geometry and router–data alignment to detect dead or homogenized routers and specialization collapse.
- Sectors: model training (industry/academia)
- Tools/workflows: Track ||PΠ_r|| (router–subspace alignment), token-wise hidden-state correlation across depth, expert-usage entropy; alert on rising hidden-state rank collapse or over-suppressed directions.
- Assumptions/dependencies: Access to activations; SVD/approximate PCA on batches; linear router.
- Safer load-balancing configuration
- Description: Adjust batch size and LB coefficients to avoid over-suppressing shared directions (paper links small micro-batches to specialization collapse).
- Sectors: model training ops
- Tools/workflows: Increase global batch/diversity; prefer global over micro-batch LB; sweep LB strength; monitor expert-usage variance.
- Assumptions/dependencies: Existing LB objective; sufficient batch diversity.
- Privacy hardening of routing telemetry
- Description: Treat expert selections as a potential side channel (routing ≈ function of hidden states); limit or obfuscate logged routing traces.
- Sectors: security/privacy, policy, consumer apps
- Tools/workflows: Disable per-request expert-ID logging; aggregate at session level; add noise; encrypt/protect router traces; add governance for routing data retention.
- Assumptions/dependencies: Threat model where attackers access routing events; compliance requirements.
- More reliable specialization analysis practices
- Description: Avoid interpreting specialization from prompts alone—paper shows prefill patterns often fail to predict generation-phase routing.
- Sectors: interpretability, evaluation
- Tools/workflows: Run full rollouts for specialization audits; report layer- and phase-specific routing; use sequence-level pooled hidden states and expert-frequency similarity for comparisons.
- Assumptions/dependencies: Access to decoding traces; compute budget for rollouts.
- Data curation to encourage useful specialization
- Description: Increase dataset diversity to produce less-correlated hidden states (particularly at deeper layers), supporting more informative routing.
- Sectors: training data engineering
- Tools/workflows: Mix domains/languages/styles; curriculum that prevents over-dominant shared directions; track hidden-state correlation per batch.
- Assumptions/dependencies: Diversity translates to geometric dispersion in hidden states; router LB won’t over-suppress informative shared factors.
- Capacity planning and hot-spot mitigation in serving
- Description: Use observed expert-usage overlap distributions to anticipate hot experts and balance placement.
- Sectors: cloud serving, systems
- Tools/workflows: Collect per-layer/phase expert heatmaps; colocate hot experts with more memory/compute; autoscale expert replicas.
- Assumptions/dependencies: Stable usage profiles at deployment scale; telemetry availability.
- Robust ensemble gating and diversity measurement
- Description: Low cross-model expert overlap on the same task (≈60% in math) signals complementary trajectories; exploit this to diversify ensembles.
- Sectors: finance, healthcare, safety-critical decision support
- Tools/workflows: Route queries to multiple MoEs with low overlap; ensemble or confidence-weight their outputs; monitor overlap as a diversity metric.
- Assumptions/dependencies: Cross-model routing visibility; ensemble overhead is acceptable.
- Rapid regression tests for MoE health
- Description: Use triangle-shaped relation (hidden-state similarity ⇒ similar routing; dissimilar hidden states → similar or dissimilar routing) as a quick health check across updates.
- Sectors: ML Ops
- Tools/workflows: Fixed token/sequence pairs; track hidden-state vs routing distance scatter; flag drift/change in “triangle” geometry.
- Assumptions/dependencies: Consistent evaluation protocol; stable tokenization.
Long-Term Applications
These opportunities likely require additional research, development, or scaling to realize production value. They aim to translate the paper’s geometric account of specialization into new training methods, safer systems, and better tools.
- Geometry-aware router objectives
- Description: Design training losses that shape hidden-state geometry toward semantically aligned directions rather than purely balancing load, improving interpretability and controllability of specialization.
- Sectors: foundational model training, interpretability
- Tools/workflows: Multi-objective router training (balance + geometry alignment terms); probing-based constraints on subspaces; contrastive or supervised signals for desired separation.
- Assumptions/dependencies: Reliable proxies for “semantic” axes; avoiding catastrophic trade-offs with perplexity/throughput.
- Adaptive, phase- and layer-aware sparsity
- Description: Dynamically vary k (top-k experts) across layers and between prefill and decode to match observed collapse/divergence patterns, reducing compute without hurting quality.
- Sectors: inference systems
- Tools/workflows: Online estimators of routing diversity; controllers that raise k in decode and lower k in prefill; guardrails via NLL monitors.
- Assumptions/dependencies: Fast, stable diversity estimates; minimal overhead for dynamic gating.
- Predictive expert scheduling for multi-tenant serving
- Description: Forecast expert demand from early-layer/prefill signals to prefetch weights, pre-allocate bandwidth/slots, and avoid contention.
- Sectors: cloud platforms, edge appliances
- Tools/workflows: Lightweight forecasters on router logits/hidden-state subspace; admission control using predicted hot experts; priority queues.
- Assumptions/dependencies: Forecastability from early signals; stable traffic patterns.
- Privacy-preserving MoE designs
- Description: Reduce routing side-channel leakage with DP gating, secure enclaves for routers, randomized/obfuscated expert IDs, or per-tenant routing partitions.
- Sectors: security/privacy, policy, regulated industries
- Tools/workflows: DP noise on logits; hardware enclaves; rotating expert mappings; compliance frameworks around routing telemetry.
- Assumptions/dependencies: Tolerable utility loss; hardware support; clear privacy budgets.
- Robustness and anomaly detection via routing fingerprints
- Description: Use deviations in router confidence or expert-usage profiles as early detectors of adversarial inputs, jailbreaks, or distribution shifts.
- Sectors: trust & safety, SOCs, enterprise SaaS
- Tools/workflows: Baseline fingerprints by domain; detectors on sudden divergence in layer- or phase-specific routing; automated mitigation policies.
- Assumptions/dependencies: Low false positives; resilience to adaptive attacks.
- Targeted expert specialization via curriculum and divergence learning
- Description: Combine data curricula that widen hidden-state dispersion with objectives that encourage expert divergence (e.g., domain-targeted experts).
- Sectors: verticalized LLMs (healthcare, finance, legal)
- Tools/workflows: Domain-tagged batches; layerwise routing supervision; expert divergence regularizers.
- Assumptions/dependencies: High-quality domain signals; avoiding capacity underuse.
- Cross-model routing harmonization for interoperability
- Description: Align hidden-state subspaces or routers across models to make expert usage more consistent, enabling modular reuse or consistent audit trails.
- Sectors: enterprise platforms, compliance
- Tools/workflows: Shared router initialization; subspace alignment or CCA; multi-model co-training with routing consistency penalties.
- Assumptions/dependencies: Nontrivial to align independently trained representations; risk to performance.
- Explainability grounded in representation geometry
- Description: Develop tools that explain expert usage through the lens of learned subspaces rather than human-readable “domains,” recognizing the paper’s limits on interpretability.
- Sectors: AI governance, education, research
- Tools/workflows: Layerwise subspace visualizations; token-to-subspace attribution; trajectory-aware explanations from prompt to decode.
- Assumptions/dependencies: Usable UX for geometric explanations; stakeholder acceptance.
- Task-aware dataset/design to mitigate deep-layer collapse
- Description: Proactively design prompts/templates and training data that avoid overly uniform final-layer states that trigger prefill collapse.
- Sectors: product UX, content-generation tools
- Tools/workflows: Alternative chat templates; prompt augmentation to increase late-layer variability without harming quality.
- Assumptions/dependencies: Empirical tuning; model-specific behaviors.
- Router architectures beyond linear projections
- Description: Explore non-linear routers or attention-based gating that can better disentangle semantically meaningful directions from shared ones, if compute permits.
- Sectors: foundational research, high-end serving
- Tools/workflows: Mixture-of-attention routers; kernelized or low-rank non-linear gates; distillation back to linear routers for inference.
- Assumptions/dependencies: Throughput/latency budgets; stability in training.
- Benchmarks and evaluations for long-sequence, phase-aware specialization
- Description: Create standardized evaluations that compare prefill vs decode routing, across layers and domains, for long inputs and reasoning chains.
- Sectors: academia, open-source ecosystems
- Tools/workflows: Public leaderboards with routing metrics; paired prompt/rollout suites; reporting best practices.
- Assumptions/dependencies: Community adoption; privacy-safe logging.
- Distillation or compression guided by decode-phase experts
- Description: Use decode-phase expert usage (more consequential than prefill) to select experts to distill into smaller dense models or to prune experts.
- Sectors: edge/embedded AI, cost-sensitive deployments
- Tools/workflows: Collect decode-phase usage; distill per-expert knowledge to dense submodules; prune low-impact experts.
- Assumptions/dependencies: Accurate attribution of quality to experts; careful validation to avoid regressions.
In summary, the paper reframes MoE “specialization” as an effect of hidden-state geometry and shows that load balancing, depth, and phase (prefill vs decode) critically shape routing. This yields immediate opportunities for better monitoring, safer and cheaper serving, OOD detection, and privacy hygiene—while motivating longer-term research in geometry-aware training, adaptive routing, and privacy-preserving MoE systems.
Glossary
- Attention sink: A phenomenon where the first token receives disproportionately high attention, influencing measurements and behavior. Example: "attention sink~\citep{sun2024massive}"
- Auxiliary load balancing loss: An additional training objective encouraging experts to be used evenly to avoid collapse or redundancy. Example: "trained with AdamW and auxiliary load balancing loss."
- Auxiliary-free load balancing: Training that achieves balanced expert usage without using an explicit auxiliary load-balancing loss term. Example: "trained with Muon and auxiliary-free load balancing."
- Decoder-only LLM: A LLM architecture that uses only the decoder stack of a transformer for autoregressive generation. Example: "Decoder only LLM"
- Detokenization: A processing stage that maps token sequences back into human-readable text during or after generation. Example: "detokenization, feature engineering, prediction ensembling, and residual sharpening"
- Euclidean distance: A standard geometric distance measure used here to quantify similarity between hidden states in a projected space. Example: "we measure the similarity between the hidden states using the Euclidean distance in a data-dependent space"
- Expert overlap: The extent to which two inputs or runs use the same experts, often quantified by set overlap metrics. Example: "Expert overlap (Jaccard similarity at Top-, Eq.~\eqref{eq:overlap_at_p})"
- Expert specialization: The tendency of different experts to focus on distinct inputs or features, leading to input-dependent routing. Example: "Expert specialization is crucial for MoE's practical performance:"
- Feed-forward network (FFN): The per-expert multilayer perceptron submodule that processes token representations within MoEs. Example: "feed-forward network (FFN)"
- Hidden state geometry: The structure and organization of hidden representations in vector space that governs behavior like routing. Example: "understanding expert specialization is at least as hard as understanding LLM hidden state geometry"
- Jaccard similarity: A set-based similarity metric measuring intersection over union, used here to quantify expert overlap. Example: "Jaccard similarity at Top-"
- Layer normalization: A normalization technique applied per token across features to stabilize training. Example: "layer normalization and a residual connection"
- Load-balancing loss: A router regularizer that promotes uniform expert utilization across tokens or batches. Example: "load-balancing loss suppresses shared hidden state directions"
- Maximum softmax probability: A confidence score taken as the largest class probability after softmax, used to detect OOD inputs. Example: "measured by maximum softmax probability, Eq.~\eqref{eq:conf_def})"
- Mixture of Experts (MoEs): Architectures that route tokens to a subset of expert networks to increase capacity without proportional compute. Example: "Mixture of Experts (MoEs) are now ubiquitous in LLMs"
- Micro-batches: Small subsets of data used to compute intermediate gradients; too-small micro-batches can harm specialization. Example: "applied on small micro-batches (rather than the large global-batches)"
- Operator norm: The largest singular value of a linear operator, used to bound how much it can amplify vectors. Example: " denotes operator norm (maximum singular value)"
- Orthogonal matrix: A matrix whose rows (and columns) are orthonormal, preserving norms and angles. Example: "an orthogonal matrix"
- Orthogonal projector: A linear map projecting vectors onto a subspace, minimizing reconstruction error. Example: "Define the orthogonal projector onto the corresponding principal subspace"
- Out-of-distribution (OOD): Inputs that deviate significantly from the training data distribution and can reduce router confidence. Example: "out-of-distribution (OOD)"
- Pre-norm: A transformer variant where layer normalization is applied before each sublayer. Example: "we assume a pre-norm formulation"
- Prefill phase: The stage where the model processes the prompt tokens before generating new tokens. Example: "during the prefill phase"
- Prediction ensembling: A processing stage where multiple predictive signals are combined within the model. Example: "prediction ensembling"
- Rank-collapse phenomenon: The reduction in the effective dimensionality of hidden states with depth, increasing similarity across tokens. Example: "rank-collapse phenomenon"
- Residual connection: A skip connection that adds the sublayer output to its input to ease optimization. Example: "a residual connection"
- Residual sharpening: A stage describing how final layers accentuate decisive features via residual pathways. Example: "residual sharpening"
- Residual-stream dimension: The size of the vector space in which residual representations are maintained across layers. Example: "residual-stream dimension"
- Right singular vectors: Basis vectors from SVD corresponding to input-space directions ordered by variance. Example: "right singular vectors"
- Rollout: The process of autoregressively generating tokens after the prompt, which can alter routing patterns. Example: "rollout-level routing"
- Routing logits: The pre-softmax scores produced by the router to select which experts to activate. Example: "the MoE router computes routing logits"
- Self-attention: A mechanism allowing each token to attend to all others in the sequence to compute contextualized representations. Example: "self-attention"
- Side channel: An indirect signal that can leak information about inputs, such as expert selection patterns. Example: "they constitute a side channel that can leak information"
- Singular value decomposition (SVD): A matrix factorization that decomposes data into orthogonal directions and associated singular values. Example: "singular value decomposition"
- Softmax: A normalization transforming logits into a probability distribution over experts. Example: "softmax"
- Sparse mixture (of expert blocks): The design where only a small subset of experts is activated per token, saving compute. Example: "a sparse mixture of expert blocks"
- Sparse upcycling: A training strategy that adapts or reuses parameters sparsely, which may limit specialization. Example: "sparse upcycling during training"
- Token-choice routing: A policy where each token independently selects a small subset of experts. Example: "This token-choice routing formulation"
- Top-k experts: The k experts with the highest routing logits for a token, selected for processing. Example: "top- experts"
- Top-p: A cumulative-probability threshold used to select a subset based on mass, here applied to expert frequencies. Example: "Top-"
- Trace: The sum of diagonal elements of a matrix, used to quantify energy retained in a projection. Example: "The trace of router's projection"
Collections
Sign up for free to add this paper to one or more collections.