- The paper introduces a teacher-aligned distillation approach that reduces diffusion steps from 8 to 2 while maintaining high image fidelity.
- It employs distribution-aligned adversarial learning and step-decoupled parameterization to stabilize training and enhance output quality.
- End-to-end training with iterative regularization bridges the gap between rapid sampling and state-of-the-art image synthesis benchmarks.
High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
Introduction and Motivation
This paper addresses the critical computational limitations inherent to diffusion-based T2I models by pushing the efficiency frontier of few-step generation. While 4–8 step distillation produces high-quality samples, compressing the denoising process to just two steps has consistently resulted in a dramatic drop in sample fidelity, attributed to severe optimization and capacity constraints. The authors propose Z-Image Turbo++, a framework for high-quality 2-step image generation distilled from an 8-step Z-Image Turbo teacher, and introduce three methodologically orthogonal components: (1) Distribution-Aligned Adversarial Learning, (2) Step-Decoupled Parameterization, and (3) End-to-End Training with Iterative Regularization. The results significantly narrow the gap between 2-step models and strong 8-step models in both quantitative and qualitative benchmarks.

Figure 1: Images generated by Z-Image Turbo++ with only 2 steps. Best viewed with zoom.
Core Methodology
Distribution-Aligned Adversarial Learning
A central innovation is the use of teacher (8-step student) generated images, rather than external "real" images, as the target distribution in the GAN loss during distillation. Empirical analysis shows that this subtle change in the discriminator's real sample selection eliminates adversarial training instabilities and persistent low-level artifacts present when using natural images. The authors argue that distributional alignment is crucial: by using teacher distributions as real samples, the adversarial signal provides relevant gradients within the attainable support of the 2-step student, avoiding unattainable manifolds emphasized by external datasets.

Figure 2: Adversarial training with different real-sample sources. From top to bottom and left to right: 8-step teacher samples, 2-step student trained with external real images, and with teacher-generated images, respectively.
This claim is substantiated by divergence patterns in GAN loss:
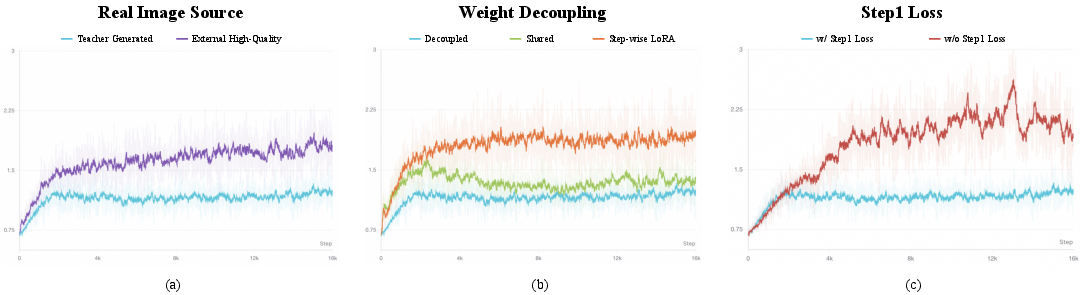
Figure 3: Generator GAN loss curves under different training settings.
When real images are used, GAN loss grows throughout training, indicating irreconcilable distributional gaps. When using teacher outputs, the GAN loss stabilizes and converges, leading to markedly improved synthesis quality.
Step-Decoupled Parameterization
The capacity demands of 2-step generation are fundamentally distinct from those in multi-step models as each denoising stage must traverse a large segment of the noise-to-data trajectory. The paper introduces per-step parameter isolation, initializing two independent models (one for each denoising step) from the teacher weights and updating them separately during training. This architecture doubles the effective capacity compared to a tied-weight backbone and de-correlates step-specific modeling burdens. Comparative experiments with LoRA-based per-step adaptation versus full decoupling show the latter yields consistently lower GAN loss and superior benchmark scores, especially on language-sensitive axes.
End-to-End Training with Iterative Regularization
The 2-step setting enables true end-to-end pipeline optimization, unrolling both denoising modules and propagating gradients from the final output all the way to the first step. This is intractable in 4+-step models due to memory and gradient instability. However, naively omitting any constraint on the intermediate output (after the first denoising step) degrades performance and destabilizes training. Thus, the authors explicitly retain a loss on the intermediate state (step-1 loss) to anchor the generation process in the pretrained model’s inductive bias toward iterative denoising, ensuring transfer efficiency from large-scale teacher models.

Figure 4: Visual comparison showing degraded quality when step-1 loss is removed.
Experimental Results
Comprehensive benchmarks on OneIGBench, LongTextBench, GenEval, and DPGBench validate the effectiveness of the proposed pipeline. Z-Image Turbo++ nearly matches 8-step models in overall T2I quality, photorealism, and text rendering, and outperforms strong 2-step baselines including direct Z-Image Turbo (2-step) and TwinFlow.
Qualitatively, Z-Image Turbo++ achieves sharper textures, higher detail preservation, more coherent text, and fewer systematic artifacts.

Figure 5: Qualitative comparison among 8-step Z-Image-Turbo, TwinFlow, and Z-Image Turbo++, demonstrating improved quality–efficiency trade-off for the proposed method.
Ablation studies demonstrate the individual necessity of all three components. Distribution-aligned GAN substantially suppresses artifacts, decoupled parameterization is critical for text and compositional understanding, and the step-1 loss is indispensable for stable iterative generation.
Theoretical and Practical Implications
This methodology establishes that aggressively compressed diffusion generation (2 steps) can achieve fidelity and instruction-following ability within the range of state-of-the-art 8-step distillations—provided that the teacher’s distribution is leveraged as the optimization anchor and that capacity is allocated optimally between the denoising phases. The results challenge the dominant intuition that adversarial targets must utilize true data, raising fresh questions about effective support alignment in fast-sampling diffusion-GAN hybrids. The approach implicitly connects to recent advancements in distillation and score alignment, such as Distribution Matching Distillation and hybrid adversarial methods, and provides a concrete instantiation for end-to-end differentiable few-step generation.
Limitations and Future Perspectives
Despite the substantial reduction in compute per sample, the main limitation is parameter storage due to duplicating model weights for each step. Text rendering and complex compositional understanding still exhibit minor degradation relative to the 8-step teacher. Future work may investigate memory-parameter trade-offs, progressive step-reuse strategies, and applications in RL-based preference alignment for T2I generation.
Conclusion
Z-Image Turbo++ demonstrates that strong high-resolution 2-step image generation is possible via carefully aligned adversarial distillation, per-step model specialization, and judicious regularization of the underlying iterative process. The method provides a competitive alternative for real-time diffusion-based T2I applications while opening up new research directions on capacity allocation, distribution alignment, and training protocol optimization in ultra-few-step generative modeling (2606.12575).