- The paper presents a theoretical framework that quantifies shortcut risks in multi-step search tasks by analyzing evidence co-coverage, single-clue selectivity, exposed constants, and prior-knowledge binding.
- It introduces FORT, a systematic synthesis pipeline that generates robust deep search tasks using graph construction, question formulation, and adversarial refinement to neutralize shortcuts.
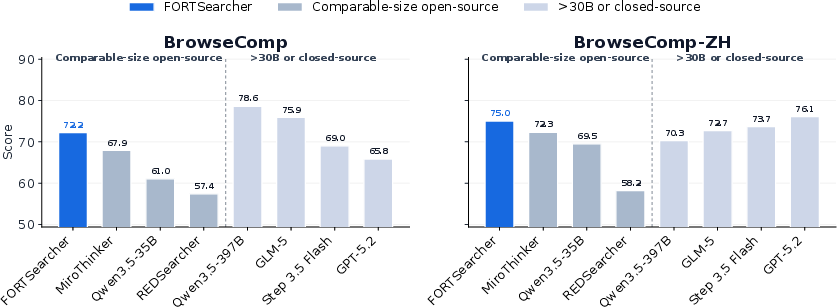
- Empirical evaluations show that FORT-Searcher achieves state-of-the-art results on challenging benchmarks, significantly increasing search cost and reducing shortcut exploitation.
FORT-Searcher: Synthesis of Shortcut-Resistant Deep Search Tasks for Training Search Agents
Introduction and Motivation
Recent advances in LLM-based agents have prompted a surge in datasets and benchmarks for long-horizon tool-augmented search. However, most existing datasets fail to enforce actual search difficulty: superficial increases in the structural complexity of questions—more hops, richer evidence graphs—do not force search agents to perform non-trivial multi-turn evidence collection, planning, or reasoning. The answer often appears through semantic or environmental shortcuts, such as exposed constants, over-selective clues, or parametric memorization, allowing agents to bypass significant parts of the intended process.
This paper introduces a shortcut-aware theoretical framework for search-task difficulty, with explicit characterization of four actionable shortcut risks: evidence co-coverage, single-clue selectivity, exposed constants, and prior-knowledge binding. Based on this framework, the authors propose FORT (Framework Of Shortcut-Resistant Training-data synthesis), a system that programmatically synthesizes search tasks that are structurally and behaviorally resistant to shortcut exploitation. The shortcut-resistant tasks are used to train a new agent, FORT-Searcher, which achieves state-of-the-art performance among comparable-size open-source models on challenging deep search benchmarks.
Shortcut-Aware Difficulty Framework
The authors formalize multi-constraint, agentic retrieval tasks as tuples consisting of an answer space, set of clue-like constraints, and a retrieval interface. They propose that true difficulty depends not just on the intended constraint structure, but on the cost of the cheapest identifying route that an agent can use in the context of actual retrieval and their own prior knowledge.
A concrete agent can exploit:
- Evidence co-coverage: When a single evidence source verifies multiple constraints, multi-hop reasoning collapses into a single retrieval.
- Single-clue selectivity: Overly discriminative clues let the answer be isolated early, bypassing further evidence acquisition.
- Exposed constants: Surface-level exposure of answer-bearing constants makes downstream queries trivially executable.
- Prior-knowledge binding: Parametric memorization lets the model answer with zero search.
These phenomena are not merely artifacts of flawed question-writing but stem from a fundamental disconnect between intended and realized task hardness.
The framework’s core is a decomposition of realized search cost into route-level lower bounds that depend on selectivity, evidence dispersion, and dependency depth, plus a solver-side component reflecting prior utility. The authors introduce trajectory-level diagnostic metrics—solving cost, answer hit time, and prior-shortcut rate—to quantitatively capture these shortcut risks in existing datasets.
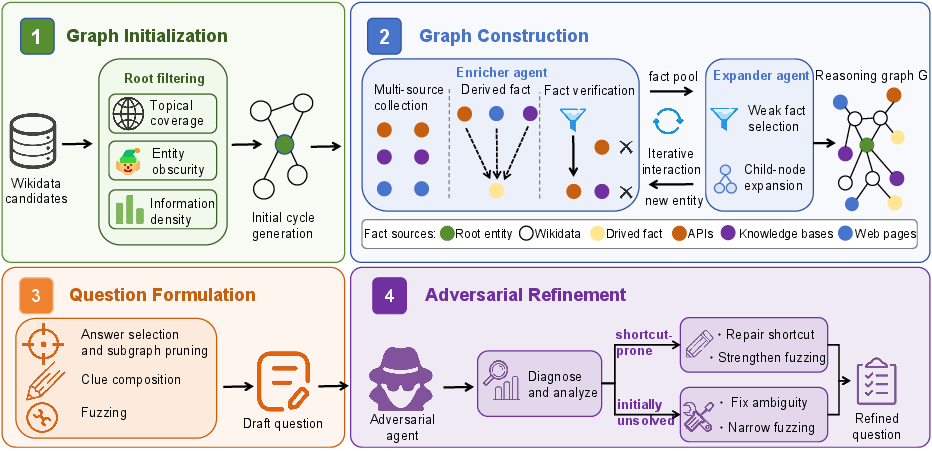
The FORT Data Synthesis Pipeline
FORT engineering operationalizes shortcut control through a four-stage pipeline:
- Graph Initialization
- Begins with long-tail entities to attenuate prior-knowledge binding.
- Prefers cycle-based subgraphs over linear chains to reduce premature constant exposure.
- Graph Construction
- Expands the evidence graph via multi-source fact enrichment.
- Extracts atomic and derived facts (coincidence bridging, aggregation, arithmetic encoding) from heterogeneous evidence.
- Filters for generic clues, minimizes single-clue selectivity, and disperses evidence sources to minimize co-coverage.
- Question Formulation
- Renders constraint subgraphs into surface questions while suppressing explicit entity names and literal values.
- Employs exact-value fuzzing strategies (category generalization, range relaxation, meta-attribute descriptions) to prevent shortcut search paths.
- Adversarial Refinement
Empirical Results and Analysis
The authors fine-tune a 3B-parameter agent (FORT-Searcher) solely via supervised learning on FORT trajectories. Evaluation on BrowseComp, BrowseComp-ZH, xbench-DeepSearch, and Seal-0 reveals:
Theoretical and Practical Implications
The expressive, formal difficulty framework clarifies that apparent multi-hop or compositional structure does not guarantee long-horizon search. Real-world agent training should emphasize not just the complexity of intended reasoning paths but also ensure that all obvious shortcut mechanisms are neutralized. By introducing operational diagnostics at the trajectory level—solving cost, answer hit time, prior-shortcut rate, evidence dispersion, and more—this work closes the gap between synthetic data construction and practical search agent evaluation.
On the practical side, FORT’s methodology can be directly adopted or extended for any agent that must robustly perform non-trivial tool-augmented web-based information-seeking. The adversarial refinement paradigm sets a new standard for meaningful dataset hardness: mere scale and complexity are not sufficient, but must be coupled with brute-force, automated adversarial scrutiny.
Future Directions
The FORT-Searcher framework motivates several lines of future research:
- Integration of RL (rather than SFT alone) with shortcut-resistant trajectories to directly optimize for robust, exploration-heavy policies.
- Extension of adversarial refinement via stronger and more diverse adversaries, multi-lingual pipelines, or more complex retrieval interfaces.
- Application to search tasks beyond text, such as structured databases, code, and multimodal retrieval.
- The development of open datasets with even stronger ground-truth identification of shortcut triggers, enabling more rigorous ablations of agentic failure modes.
Conclusion
This work provides both a formal and practical foundation for the next generation of deep search agent training. FORT-Searcher demonstrates that shortcut-resistant synthesis, enforced at both structural and behavioral levels, unlocks deeper, more generalizable search behavior even with moderate model scale and only SFT. The implications for LLM agent benchmarking, dataset curation, and open-domain tool reasoning are broad and will likely persist as agents become further integrated into complex real-world environments.