Decentralized Multi-Agent Systems with Shared Context
Abstract: Multi-agent systems (MAS) can scale LLM reasoning at test time by decomposing complex problems into parallel subtasks. However, most existing MAS rely on centralized orchestration, where a main agent assigns work, collects outputs, and merges results. As the number of subtasks grows, this controller becomes a communication and integration bottleneck. We propose Decentralized LLMs (DeLM), a MAS framework that decentralizes coordination through parallel agents, a shared verified context, and a task queue. Agents asynchronously claim subtasks, read accumulated progress, perform local reasoning, and write back compact verified updates. The shared context acts as a common communication substrate, enabling agents to build on one another's verified progress without routing every update through a central controller. Empirically, DeLM improves both software-engineering test-time scaling and long-context reasoning. On SWE-bench Verified, DeLM achieves the best performance across Avg.@1, Pass@2, and Pass@4, with gains of up to 10.5 percentage points over the strongest baseline, while reducing cost per task by roughly 50%. On LongBench-v2 Multi-Doc QA, DeLM achieves the highest average accuracy across four frontier model families, improving over the strongest baseline by up to 5.7 percentage points. The code is available on our project website at https://yuzhenmao.github.io/DeLM/.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What This Paper Is About (Overview)
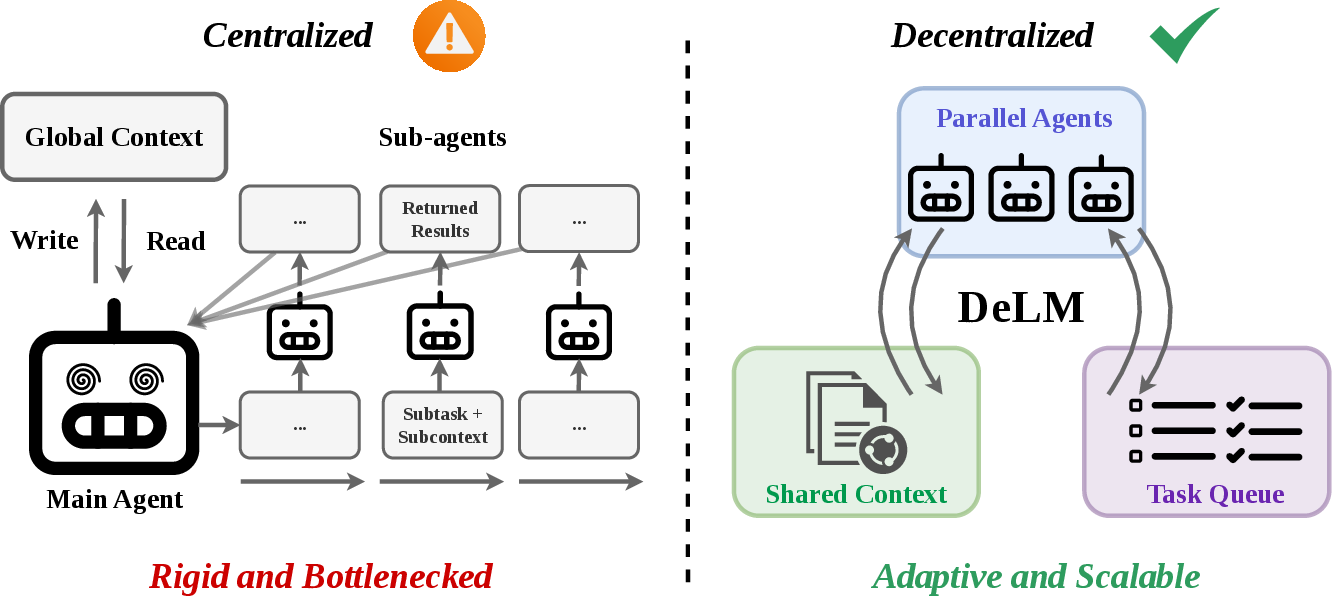
This paper introduces a new way for teams of AI agents to work together called Decentralized LLMs (DeLM). Think of a tough task like fixing a software bug or answering a question that requires reading lots of long documents. Instead of one big AI doing everything alone, many smaller AI “agents” work in parallel. The trick is how they share what they learn. Most systems use a “boss” agent to collect and redistribute updates, which becomes a traffic jam. DeLM removes the boss and lets agents coordinate through a shared, verified workspace so they can help each other faster and more reliably.
The Main Questions
In simple terms, the paper asks:
- Can many AI agents solve problems better if they coordinate without a single boss?
- How can agents share useful progress without flooding each other with too much text?
- How do we make sure shared information is correct so one agent’s mistake doesn’t mislead the others?
- Does this approach actually work better on real tasks like fixing code and reading many documents?
How DeLM Works (Methods, with simple analogies)
Imagine a group project board used by a class:
- There’s a shared bulletin board (the shared context).
- There’s a to-do list (the task queue).
- Students (agents) pick tasks, do work, and post short, checked updates so others can use them.
Here are the key ideas:
- Parallel agents, no single boss: Instead of one leader telling everyone what to do, each agent picks up a ready task from the shared to-do list whenever it’s free. This avoids waiting for the “boss” and speeds things up.
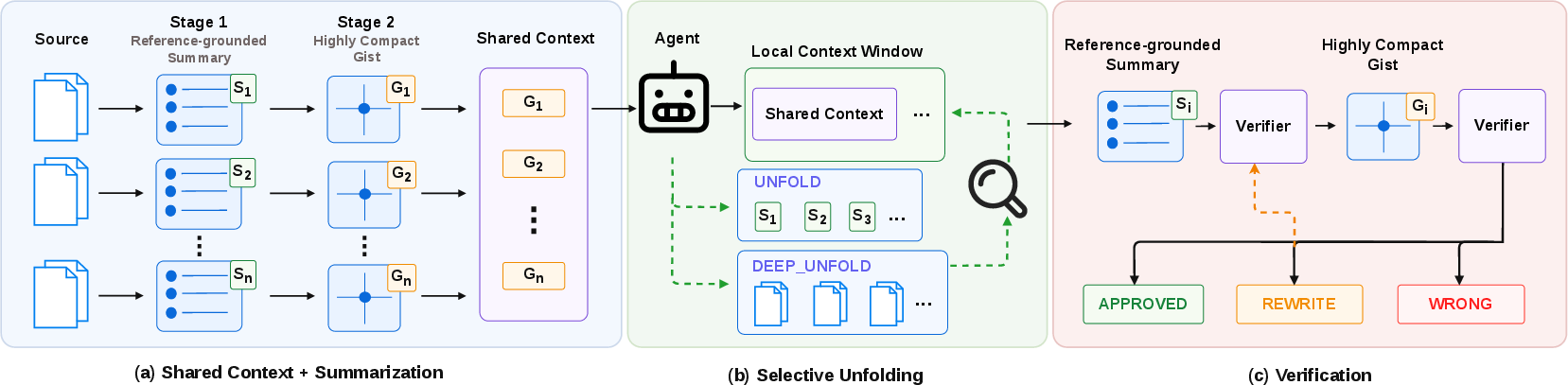
- Shared, verified context: Agents post short “sticky notes” called gists to the shared board. Before a note goes up, it’s fact-checked (verified) against real evidence (like the original document or code). If it’s shaky, it gets rejected or fixed first. This prevents wrong info from spreading.
- Compact, unfoldable notes: Gists are small and easy to read. If someone needs more detail, they can “unfold” the gist to see a longer summary and, if needed, the original source. Think: a headline → a paragraph summary → the full article.
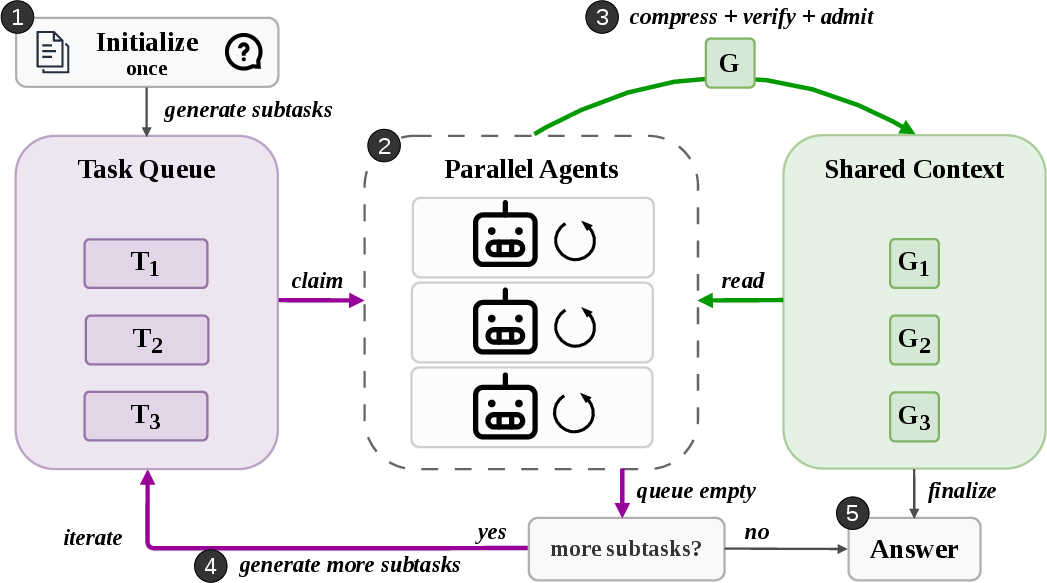
Putting it all together, DeLM follows five simple stages:
- Get started: Split the big problem into smaller subtasks and add them to the queue.
- Work in parallel: Agents claim tasks, read what’s already on the board, and think locally.
- Share carefully: They compress their findings into short gists and verify them before posting.
- Add more tasks if needed: If the queue is empty but the job isn’t done, a finished agent can propose new subtasks.
- Finalize: When there’s enough good information on the board, an agent writes the final answer.
Why this helps:
- No bottleneck: Without a boss merging everything, progress doesn’t get stuck.
- Less noise: Short, verified gists keep the board clean and useful.
- Fast reuse: Everyone benefits immediately from others’ discoveries, including useful failures.
What They Found (Results)
The authors tested DeLM on three kinds of tasks.
- Fixing real software bugs (SWE-bench Verified)
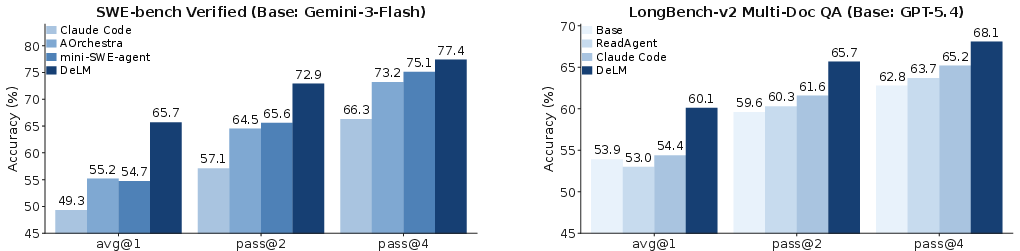
- What this is: Agents explore large codebases, propose changes, and run tests to check if the bug is fixed.
- Result: DeLM solved more problems while costing about half as much per task compared to strong baselines. For example, with 4 attempts (Pass@4), it reached about 77.4% and cut cost by roughly 50%.
- Why it worked:
- Sharing failures: If one agent proves “this path doesn’t work,” others won’t waste time repeating it.
- Keeping constraints: Important “don’ts” (like “don’t merge these filters”) stay on the board as rules, so later agents don’t accidentally break them.
- Patch summaries: Short, verified notes summarize fixes so others don’t have to read long logs to understand the key idea.
- Answering questions from many long documents (LongBench-v2 Multi-Doc QA)
- What this is: Agents need to find and connect clues across lots of long files (finance, government, news, law, academic papers).
- Result: DeLM got the best average accuracy across four different top-tier models, improving by up to 5.7 percentage points over the strongest baseline.
- Why it worked:
- Hierarchical summaries: First build a compact, verified map of the whole document set, then zoom into the most relevant parts. This avoids getting lost and missing key cross-document links.
- Verification: Incorrect claims are blocked before they hit the shared board, so later reasoning stays on solid ground.
- Data-heavy, code-like aggregation tasks (OOLONG) and combining with RLM
- What this is: Many entries must be precisely counted, filtered, or compared (closer to data processing than conversation).
- Result: DeLM alone wasn’t as strong here as a code-driven method (RLM), which uses a programming loop to compute exact results. But when combined (DeLM + RLM), the hybrid got the best accuracy and lowest cost. This shows the two approaches complement each other: DeLM is great for sharing and coordinating knowledge, while RLM is great at exact, program-like aggregation.
Why This Matters (Implications)
- Faster teamwork for AIs: By removing the “boss” and using a shared, verified workspace, many agents can truly cooperate in parallel without tripping over each other.
- More reliable reasoning: Admission-time verification keeps bad info out of the shared space, so one agent’s mistake doesn’t become everyone’s problem.
- Handles big, messy problems: The compact-then-unfold approach lets agents keep an overview of huge contexts and dive deep only when necessary, saving time and cost.
- Practical gains: On tough, real-world tasks like software bug fixing and multi-document questions, DeLM both boosts accuracy and reduces cost.
- Flexible foundation: DeLM can plug into other systems (like RLM) for tasks that need precise, code-like calculations, pointing to a future where different reasoning styles work together smoothly.
In short: DeLM shows that giving AI agents a shared, verified “bulletin board” and a common to-do list lets them think together more effectively, scale to bigger problems, and do it all more efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces DeLM and demonstrates promising empirical results, but several aspects remain underspecified or unexplored. Future work could address the following points:
- Scalability analysis: No formal or empirical characterization of DeLM’s throughput, latency, and accuracy as the number of agents/subtasks grows (e.g., scaling curves, wall-clock time, step counts, queue wait times, contention under high parallelism).
- Concurrency control: Missing details on handling simultaneous writes, conflicting updates, and race conditions in the shared context (e.g., versioning, atomicity, locking/CRDT semantics, last-writer-wins risks).
- Conflict resolution: Unclear policies when agents produce contradictory but “verified” gists, and how the finalization step reconciles disagreements or uncertainty.
- Verification reliability: The LLM-based verifier’s precision/recall is not measured; failure modes (false positives/negatives) and domain-dependent calibration are not analyzed, nor are alternatives like tool-based or rule-based verifiers.
- Provenance guarantees: Insufficient description of machine-checkable citations, evidence anchoring, and provenance tracking to ensure gists and summaries reliably map to specific raw spans and remain auditable.
- Task decomposition policy: The algorithms behind GenerateSubtasks and GenerateMoreSubtasks are unspecified; their criteria, heuristics, and sensitivity to problem structure and agent capabilities are not empirically studied.
- Queue governance: The choice to let the “most recently completed” agent decide whether to enqueue more subtasks may bias coordination; fairness, robustness to agent failure, and consensus alternatives are not evaluated.
- Memory management: Lack of policies for gist/summary eviction, prioritization, and compaction under context limits; no analysis of memory pressure or retrieval latency in large shared states.
- Chunking and unfolding: No systematic evaluation of chunk size, segmentation strategies, or error rates in gist→summary→raw unfolding (e.g., mislocalizations, missed evidence, cost/accuracy trade-offs).
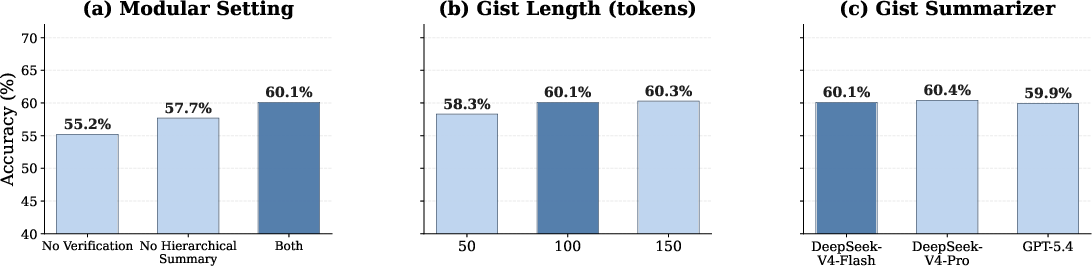
- Parameter sensitivity: While gist length and summarizer choice are ablated, critical knobs like number of agents, queue scheduling policies, verification thresholds, retry limits, and selective-unfold top-k are not explored.
- Baseline breadth: Comparisons omit other established MAS frameworks (e.g., AutoGen, OpenDevin, LlamaIndex Agents); tool parity and orchestration differences could confound results.
- Statistical rigor: Accuracy gains lack significance tests for SWE-bench; variability across seeds/runs, robustness to sampling parameters, and confidence intervals on Pass@X are not reported.
- Throughput vs. cost: Cost breakdowns (summarization, verification, unfolding, agent reasoning) and their sensitivity to token prices/caching are not provided; wall-clock latency measurements are absent.
- Failure case analysis: Limited discussion of DeLM’s failure modes beyond OOLONG; need systematic characterization of when verification or summarization misleads, or when shared context propagates subtle errors.
- Security and adversarial robustness: No treatment of poisoning attacks on shared context, prompt-injection defenses, malicious agent behavior, or integrity guarantees for admitted updates.
- Privacy and access control: Shared context may contain sensitive code/data; policies for redaction, role-based access, and compliance (PII, IP restrictions) are not addressed.
- Generalization across domains: Beyond SWE-bench, LongBench-v2, and OOLONG, applicability to math reasoning, scientific workflows, planning, or interactive/streaming environments remains untested.
- Real-time constraints: Coordination under latency budgets, deadline-aware scheduling, and throughput/latency trade-offs for online tasks are not evaluated.
- Heterogeneous agents: Effects of mixing agent roles, tools, and base models (vs. homogeneous agents) on performance, diversity, and coordination quality are not studied.
- Tool integration semantics: How tool outputs (grep/bash/tests) are verified and admitted, and how environment interactions (e.g., flaky tests, non-determinism) are handled remain unclear.
- Centralization vs. decentralization costs: No direct measurement of coordination overhead (e.g., communication bandwidth, serialization bottlenecks) comparing DeLM to peer-to-peer messaging and centralized controllers.
- Finalization algorithm: The procedure to compose the final answer from shared context (evidence weighting, tie-breaking, uncertainty propagation) is unspecified and unvalidated.
- Hybrid DeLM+RLM design: The synergy is reported but the decision policy (when to use code-mediated vs. natural-language shared state), integration architecture, and generality across tasks are not detailed.
- Reproducibility: Many implementation details are deferred to appendices (e.g., dependency-aware queueing, verification prompts), but those specifics and their impact on replicability are not provided here.
- Ethical considerations: Potential biases introduced by summarization/verification models, transparency to users, and auditability of multi-agent decisions are not discussed.
- Deployment considerations: Guidance on monitoring, observability, failure recovery, resource scheduling, and enterprise integration of a shared context store is absent.
Practical Applications
Practical Applications of “Decentralized Multi-Agent Systems with Shared Context” (DeLM)
Below we map the paper’s core ideas—decentralized coordination via a verified shared context, admission-time verification, hierarchical gists with selective unfolding, and a task queue—into concrete use cases. We group them by time-to-deploy and note sector fit, candidate tools/products/workflows, and key assumptions/dependencies affecting feasibility.
Immediate Applications
These can be deployed today using current LLMs, standard developer tooling, and cloud infrastructure.
- Software defect triage, patching, and CI co-pilots (Sector: Software)
- What: Parallel agents explore hypotheses across a codebase; compact, verified patch summaries and reusable constraints reduce redundant exploration; integrate with test suites to gate admission.
- Tools/workflows: “DeLM-for-CI” plugin (GitHub/GitLab), per-repo shared-context store (gist + hierarchical summaries + raw pointers), verifier using unit tests and static checks, code-review assistant that cites verified evidence.
- Assumptions/dependencies: Access to repo/tests, sandboxed execution, reliable verifier prompts/unit tests; privacy for proprietary code.
- Repo-aware onboarding and code search assistants (Sector: Software)
- What: Build a verified, unfoldable knowledge layer over large repos; engineers query design decisions, constraints, and change rationale without reading full histories.
- Tools/workflows: Incremental indexer that maintains gist/summary/raw triads; IDE extension to unfold details on demand; admission-time verification against commit messages/tests.
- Assumptions/dependencies: Continuous indexing, versioning and permissions; cost control for large repos.
- Multi-document enterprise QA (legal, finance, government, academic research) (Sectors: Legal, Finance, Government, Education)
- What: Agents process different document clusters in parallel and share verified gists; finisher composes answers with traceable citations.
- Tools/workflows: “Evidence Board” UI storing compact gists linked to hierarchical summaries and raw passages; selective unfolding; verifier checks claims against cited spans.
- Assumptions/dependencies: Accurate chunking, robust citation checking, content access rights, PII/redaction policies.
- Compliance and audit summarization (Sectors: Finance, Healthcare, GovTech)
- What: Summaries of regulatory obligations (e.g., SOX, HIPAA, GDPR) with binding constraints preserved in shared context; verified cross-doc mappings from policies to controls.
- Tools/workflows: Compliance workspace with constraint gists; integration with control libraries and audit logs; admission-time verification against regulations and authoritative guidance.
- Assumptions/dependencies: Up-to-date regulation corpora, legal review; strict auditing and provenance.
- Incident response and SRE triage (Sector: IT/Cloud)
- What: Agents analyze logs, dashboards, and config diffs in parallel; verified failures/constraints prevent rework, reduce MTTR.
- Tools/workflows: DeLM runbook orchestrator; log-unfolders (Kibana/CloudWatch); patch summaries tied to postmortems.
- Assumptions/dependencies: Secure access to telemetry; rate limits on unfolding; verifier grounded in metrics/alerts.
- Customer support knowledge ops and case deflection (Sectors: Software, E-commerce, Telecom)
- What: Build a verified shared context from tickets, KBs, and forums; agents propose answers with backed citations; negative findings (what won’t work) become reusable constraints.
- Tools/workflows: Zendesk/Salesforce integration; gist maintenance for hot issues; auto-suggest with citations.
- Assumptions/dependencies: Ticket privacy, PII handling; drift management for evolving products.
- Editorial fact-checking and research assistance (Sectors: Media, Think Tanks)
- What: Admission-time verification prevents unsupported claims from entering story memos; cross-document links captured in compact gists.
- Tools/workflows: “Evidence ledger” with append-only verified entries; newsroom plugins; human-in-the-loop acceptance gate.
- Assumptions/dependencies: Access to source material; strong citation policies; legal review.
- Insurance claims file triage and summarization (Sector: Insurance)
- What: Multi-doc claims packages analyzed with verified findings and constraints (coverage limits, exclusions); agents avoid re-reading long attachments.
- Tools/workflows: Claims console with gist/summary/raw; admission-time checks against policy terms and loss descriptions.
- Assumptions/dependencies: PHI/PII compliance; document normalization/ocr; integration with core systems.
- E-discovery and FOIA processing (Sectors: Legal, Government)
- What: Parallel review across large corpora; verified summaries reduce review burden; selective unfolding for privileged or responsive content.
- Tools/workflows: Discovery platform connector; chain-of-custody logs; sampling-based verifier audits.
- Assumptions/dependencies: Discovery protocols; strong auditability; role-based access.
- Research literature review and meta-analysis scaffolding (Sectors: Academia, Biotech, Pharma)
- What: Agents partition literature, share verified claims and qualifiers; later agents unfold only needed papers/sections for depth.
- Tools/workflows: Scholar/PMC connectors; citation-grounded verifier; hypothesis board with FAIL/FACT constraints.
- Assumptions/dependencies: Access to full texts; correct citation parsing; domain-specific verifiers.
- Cost-optimized LLM orchestration layer (Cross-sector)
- What: Lower token cost via compact sharing and selective unfolding; admission-time verification reduces downstream retries.
- Tools/workflows: “GistOps” SDK; shared-context service (with versioning and metadata); model router (cheap summarizer + strong reasoner).
- Assumptions/dependencies: Observability to tune gist budgets; stable API latency; caching.
- Personal study/knowledge assistant for multi-source materials (Sector: Daily life/Education)
- What: Verified notes across textbooks, lecture slides, and papers; unfold details only as needed; flag unsupported assertions.
- Tools/workflows: Local document import; per-note citations; verifier tuned for textbooks.
- Assumptions/dependencies: Local privacy; OCR quality; compute budget on-device or via private cloud.
Long-Term Applications
These require further research in verification robustness, scalability, safety, domain tooling, and/or organizational change.
- Autonomous software teams at scale (Sector: Software)
- What: Multi-agent “teams” executing feature development, refactors, and migrations with shared verified plans, constraints, and patch summaries; fewer central bottlenecks.
- Tools/workflows: Project-wide task queues, dependency-aware scheduling, semantic code maps, automatic design reviews.
- Assumptions/dependencies: Reliable spec tracking; strong admission gates (tests, formal checks); long-horizon coordination; governance over code changes.
- Scientific discovery engines and automated labs (Sectors: Academia, Biotech, Materials)
- What: Agents explore hypotheses, plan experiments, and update a shared evidence state from papers, code, and instruments; failed trials are reusable constraints.
- Tools/workflows: LIMS/ELN integration; simulator and instrument control; provenance-preserving “evidence graph.”
- Assumptions/dependencies: High-fidelity verifiers (statistics, methods), safe experiment planning, alignment with lab safety norms.
- Longitudinal care planning and diagnostics (Sector: Healthcare)
- What: Parallel agents analyze EHR notes, labs, imaging reports; verified gists ensure decisions rely on supported evidence with qualifiers and temporal context.
- Tools/workflows: EHR connectors, medical ontology-aware verifiers, explainable care-plan composer.
- Assumptions/dependencies: Regulatory approval, PHI governance, clinical validation, robust temporal reasoning.
- Policy analysis, regulatory drafting, and public comment synthesis (Sectors: Government, Public Policy)
- What: Agents process statutes, rulemakings, impact analyses, and comments; shared-context constraints prevent reopening invalid simplifications; traceable rationale.
- Tools/workflows: Evidence ledger for civic records; public-facing provenance; bias audits on admission-time verification.
- Assumptions/dependencies: Political/administrative buy-in, transparency standards, equitable data access.
- Enterprise evidence ledger and knowledge graph (Sectors: Cross-industry)
- What: An org-wide, append-only, verified “evidence ledger” underpinning analytics, decision support, and compliance, updated by agent swarms.
- Tools/workflows: Versioned gist/summary/raw storage; schema mapping; governance dashboards; cross-domain agents.
- Assumptions/dependencies: Data integration at scale, lineage tracking, role-based controls, legal retention policies.
- Hybrid programmatic–agentic analytics (DeLM + RLM) (Sectors: Finance, Ops, BI)
- What: Natural-language shared context for evidence discovery combined with code-mediated REPL for exact aggregation, counting, and reconciliation.
- Tools/workflows: Dual-plane executor (state-based agents + programmatic operators), reconciliation verifiers, structured answer validators.
- Assumptions/dependencies: Reliable composition of NL and code steps; determinism for audit; sandboxed execution.
- Multi-robot and IoT swarm coordination via shared verified state (Sectors: Robotics, Manufacturing, Logistics)
- What: Decentralized task claiming and compact, verified updates reduce central bottlenecks in fleets; peers build on verified progress/failures.
- Tools/workflows: Shared blackboard/tuple-space with safety guards; real-time verifiers (sensors, SLAM, constraints).
- Assumptions/dependencies: Hard real-time constraints, safety certification, robust perception-to-text interfaces.
- Energy grid monitoring and response (Sector: Energy)
- What: Agents analyze heterogeneous telemetry and maintenance records; admission-time verification and constraints capture safe operating envelopes.
- Tools/workflows: OT/IT connectors, event-driven task queues, operator-in-the-loop approvals.
- Assumptions/dependencies: Cybersecurity, latency bounds, regulatory compliance, fail-safe designs.
- Advanced regulatory reporting and risk engines (Sector: Finance)
- What: Cross-document risk synthesis with verified citations (filings, covenants, disclosures); parallel hypothesis testing with binding constraints.
- Tools/workflows: Financial ontology verifiers, temporal reconciliation, audit-ready evidence trails.
- Assumptions/dependencies: Access to up-to-date filings; low hallucination tolerance; legal accountability.
- AI governance, auditability, and provenance standards (Cross-sector)
- What: Admission-time verification, evidence-linked gists, and append-only shared context as primitives for compliant AI systems; standardized “evidence objects.”
- Tools/workflows: Evidence schema, verification benchmarks, attestations, external auditors.
- Assumptions/dependencies: Industry standards, regulator engagement, interoperable logs.
- Crisis coordination and situational awareness (Sectors: Emergency Management, Defense)
- What: Distributed agents process multi-source reports in parallel; verified updates prevent rumor propagation; decision-makers consume compact, reliable gists.
- Tools/workflows: Multimodal ingestion (text, imagery), verifiers tied to trusted sources, graded trust levels.
- Assumptions/dependencies: Information integrity, secure comms, human oversight.
- Cross-lingual knowledge synthesis (Cross-sector)
- What: Hierarchical summaries and admission-time verification across languages to combine global evidence with compact, verifiable context.
- Tools/workflows: Multilingual summarizers/verifiers, translation alignment, cross-lingual citation checking.
- Assumptions/dependencies: Language coverage, domain-specific terminology accuracy.
Notes on Feasibility and Dependencies (Common Across Applications)
- Model capabilities: Requires reliable base models for reasoning and lighter models for summarization; admission-time verifiers must be conservative to avoid propagating unsupported claims.
- Systems and data: A scalable shared-context store (gist/summary/raw with versioning), dependency-aware task queue, selective unfolding, and strong observability/cost controls.
- Domain integration: Tooling to ground verification (tests, retrieval, code execution, ontologies); connectors to EHRs, ERPs, ticketing, or regulatory corpora.
- Security and compliance: Role-based access, redaction/PII handling, audit logs, and provenance; domain-specific validation and approval workflows.
- Human-in-the-loop: Many domains still need expert review at admission or finalization; organizational adoption and change management are critical.
Glossary
- admission problem: Treating whether to include an agent’s update as a gated decision that requires checking before it enters shared state. "DeLM treats each shared-context update as an admission problem."
- admission-time verification: Verifying an update against its supporting evidence before admitting it to the shared context. "DeLM mitigates this risk through admission-time verification."
- agentic: Describing systems or baselines where autonomous agents plan, act, and reason to solve tasks. "ReadAgent~\citep{lee2024human} is an agentic long-context baseline"
- backing storage: Secondary storage that holds detailed data not kept in the always-visible working set, retrieved on demand. "while and the raw store serve as backing storage."
- centralized orchestration: Coordination via a main controller that assigns, collects, and merges subtask results from agents. "most existing MAS rely on centralized orchestration"
- coarse-to-fine access pattern: Starting from compact summaries and selectively expanding to detailed evidence only when needed. "This coarse-to-fine access pattern enables coordination over the full problem"
- demand paging: An OS-inspired mechanism where detailed content is loaded only when required. "Selective unfolding acts like demand paging"
- gist: A compact, verified summary entry that distills useful information for reuse by other agents. "The key design choice is that contains gist entries rather than raw traces."
- hierarchical summarization: A two-level compression process that builds intermediate summaries before forming compact gists. "admission-time verification and hierarchical summarization contribute to these gains."
- long-context reasoning: Reasoning over inputs too large to fit comfortably in a single prompt, often spanning many documents. "The second is long-context reasoning, such as multi-document question answering"
- Multi-agent systems (MAS): Collections of interacting agents that decompose and solve tasks collaboratively. "Multi-agent systems (MAS) offer a natural way to scale LLM reasoning at test time."
- Pass@k: A test-time scaling metric indicating whether at least one of k attempts succeeds on a task. "DeLM achieves the best performance across Avg.@1, Pass@2, and Pass@4"
- peer-to-peer communication: Agents messaging each other directly rather than via a shared state or central controller. "This design also differs from peer-to-peer communication, where agents exchange messages directly."
- programmatic inspection: Using tools and code to inspect, parse, or manipulate inputs during reasoning. "Claude Code is a tool-augmented agentic baseline that performs programmatic inspection and context compression"
- Read-Eval-Print Loop (REPL): An interactive programming loop used to inspect and aggregate information via code execution. "through a code-mediated Read-Eval-Print Loop (REPL)"
- Recursive LLMs (RLMs): Models that recursively select context segments, issue sub-calls, and compose partial answers. "Recursive LLMs (RLMs)~\citep{zhang2025recursive} process long contexts by recursively selecting context segments, issuing sub-calls, and composing the resulting partial answers."
- scatter--gather: A parallel coordination pattern where work is scattered to workers and results are gathered synchronously. "through a synchronous scatter--gather loop"
- selective unfolding: Expanding a gist into its supporting summaries or raw evidence only when more detail is needed. "Both and the raw content remain in backing stores and can be recovered through selective unfolding."
- shared context: A global state that holds compact, verified progress for all agents to read and build upon. "The shared context acts as a common communication substrate"
- shared, verified context: A shared state where entries are verified before admission so that agents rely on curated information. "DeLM lets agents coordinate asynchronously through a shared, verified context."
- state-based communication: Coordinating via persistent shared state rather than re-encoding decisions into prompts. "Coordination therefore becomes state-based, with useful findings, failures, and constraints accumulating as shared problem state"
- task queue: A global list of pending subtasks that agents can asynchronously claim and execute. "parallel agents, a shared context, and a task queue"
- test-time scaling: Improving performance by allocating more computation or parallel agents during inference. "The first is test-time scaling, where multiple agents can explore different hypotheses or pursue alternative reasoning paths in parallel"
Collections
Sign up for free to add this paper to one or more collections.

