Language Model Teams as Distributed Systems
Abstract: LLMs are growing increasingly capable, prompting recent interest in LLM teams. Yet, despite increased deployment of LLM teams at scale, we lack a principled framework for addressing key questions such as when a team is helpful, how many agents to use, how structure impacts performance -- and whether a team is better than a single agent. Rather than designing and testing these possibilities through trial-and-error, we propose using distributed systems as a principled foundation for creating and evaluating LLM teams. We find that many of the fundamental advantages and challenges studied in distributed computing also arise in LLM teams, highlighting the rich practical insights that can come from the cross-talk of these two fields of study.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language explanation of “LLM Teams as Distributed Systems”
What is this paper about?
This paper looks at what happens when you make a “team” of AI chatbots (LLMs, or LLMs) work together on a task instead of using just one. The authors argue that we can design and evaluate these AI teams much better if we borrow ideas from a field called “distributed systems,” which studies how many computers work together reliably and efficiently. Then they test this idea with experiments and show where teams help, where they hurt, and how to organize them.
What questions are the researchers trying to answer?
In simple terms, they ask:
- When does using a team of AI chatbots make things faster or better than using just one?
- How many AI “teammates” should you use?
- Should there be a leader assigning tasks, or should everyone decide together?
- What kinds of problems cause AI teams to slow down, break things, or waste money and energy?
How did they study it?
They ran coding tasks where multiple AI agents had to work together (like writing a math library, analyzing data, or creating an image with code). They varied two big things:
- Task structure:
- Highly parallel tasks: many pieces can be done at the same time.
- Mixed tasks: some parts can be done in parallel, others must happen in order.
- Highly serial tasks: most steps must happen one after the other.
- Team structure:
- Centralized teams: tasks are pre-assigned (like a teacher handing out roles). This minimizes confusion.
- Decentralized teams: the AIs choose tasks themselves and coordinate by messaging each other (like students deciding who does what as they go).
They measured:
- How much faster teams were compared to one AI (speedup).
- How often things broke (like code tests failing).
- How much they “talked” (number of messages and idle time).
- How much it cost in AI “tokens” (think: how many text-processing units they used).
They also compared these results to classic rules from distributed systems, especially:
- Amdahl’s Law: adding more teammates helps less if a big chunk of the task can’t be done in parallel.
- Tradeoffs between centralized and decentralized designs (consistency vs. flexibility).
- “Stragglers”: slow teammates who hold everyone up.
Key ideas explained with everyday examples
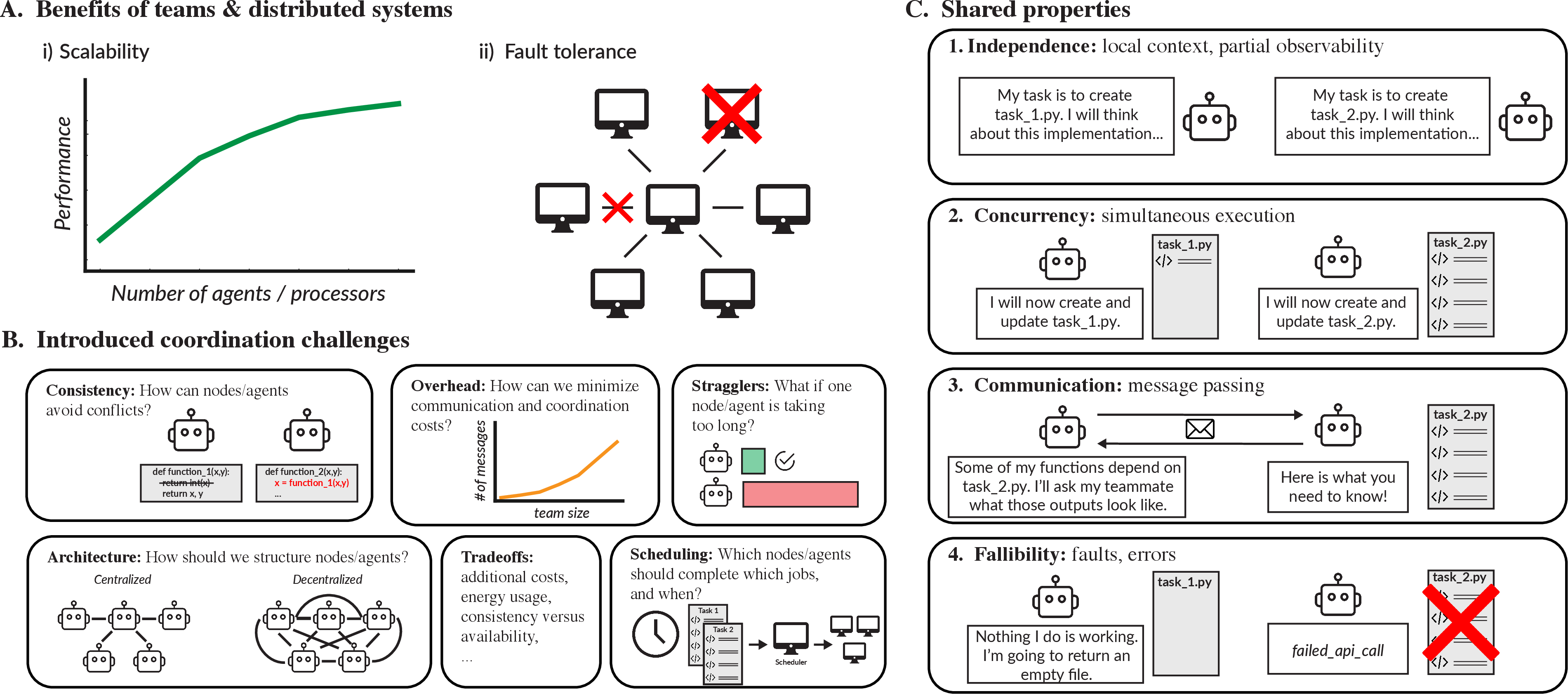
Before the results, here are four properties AI teams share with distributed systems (introduced with an everyday analogy):
- Independence: Each AI has its own view of the project. Like classmates working from their own notes, they don’t automatically know everything the others know.
- Communication: They have to message each other to coordinate, like texting in a group chat.
- Concurrency: They can work at the same time. That can be great—unless two people edit the same file and overwrite each other’s work.
- Fallibility: They make mistakes (like hallucinations or wrong code), just like computers can crash or return bad results.
What did they find?
Here are the main results and why they matter:
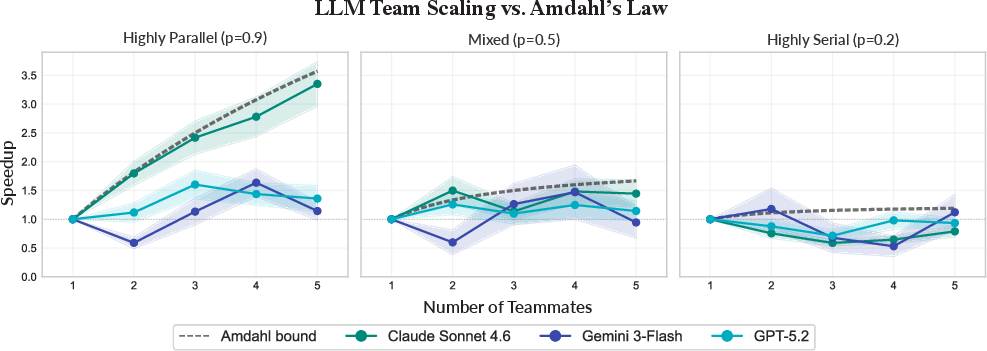
- Teams help most on tasks that can be split up
- What they saw: When tasks were “highly parallel,” adding more AI teammates usually made the work finish faster. When tasks were mostly step-by-step, more teammates didn’t help much.
- Why it matters: This matches Amdahl’s Law from distributed systems. It’s like baking: ten chefs can chop vegetables in parallel, but if the stew must simmer for an hour no matter what, ten chefs don’t make that part any faster.
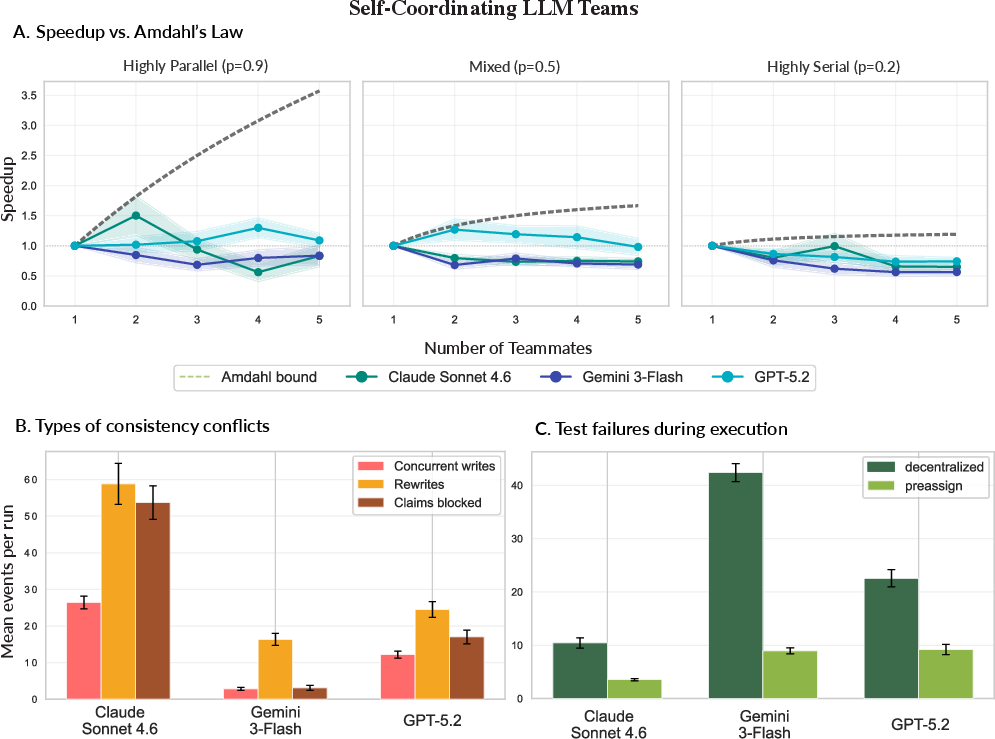
- Centralized (pre-assigned) teams often ran more smoothly
- What they saw: When a “leader” plan pre-assigned tasks, teams had better speedups and fewer problems. When AIs self-organized, they:
- Overwrote each other’s files,
- Tried to do steps out of order,
- Sent lots more messages,
- Spent more rounds talking without making progress,
- Failed more tests along the way.
- Why it matters: This is a classic distributed-systems tradeoff. Centralized control reduces chaos and conflicting updates, but it can have bottlenecks.
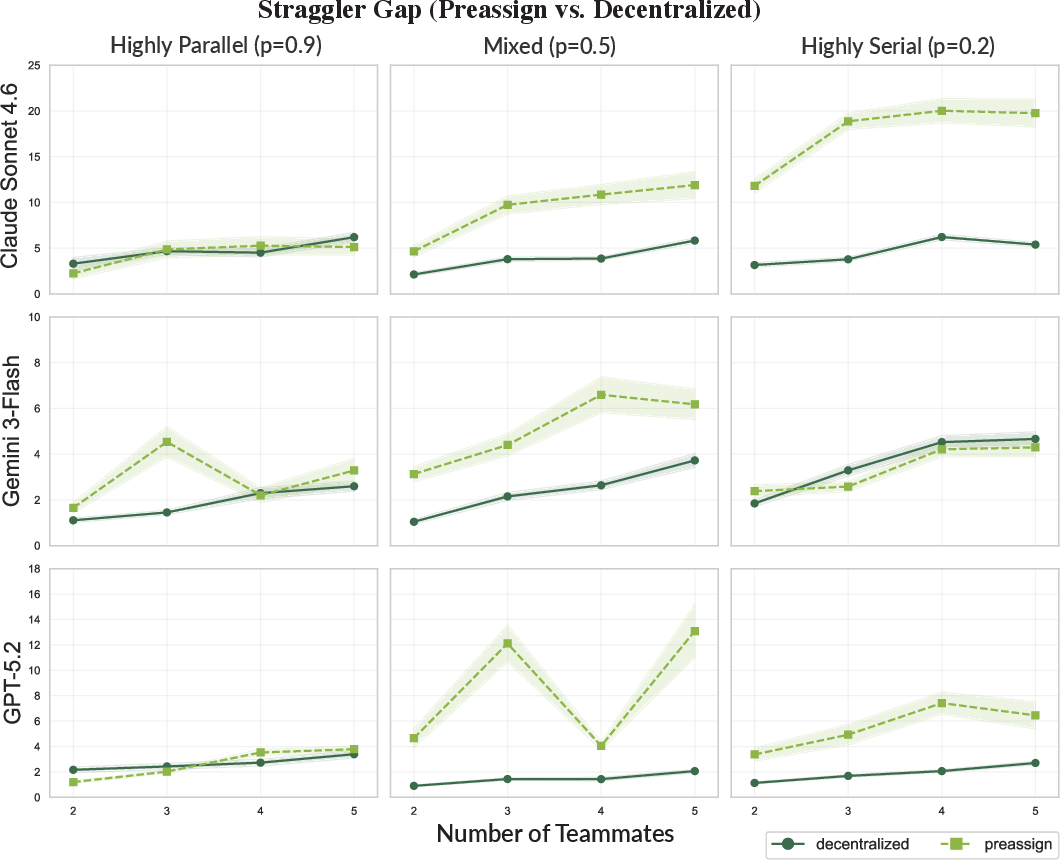
- Decentralized teams are better at handling slow teammates (stragglers)
- What they saw: When nobody was locked into a fixed role, other AIs could pick up unfinished tasks if one agent was slow. This reduced delays from stragglers.
- Why it matters: Flexibility helps when some parts take unpredictably long. It mirrors how big computing systems duplicate slow tasks so someone else can finish first.
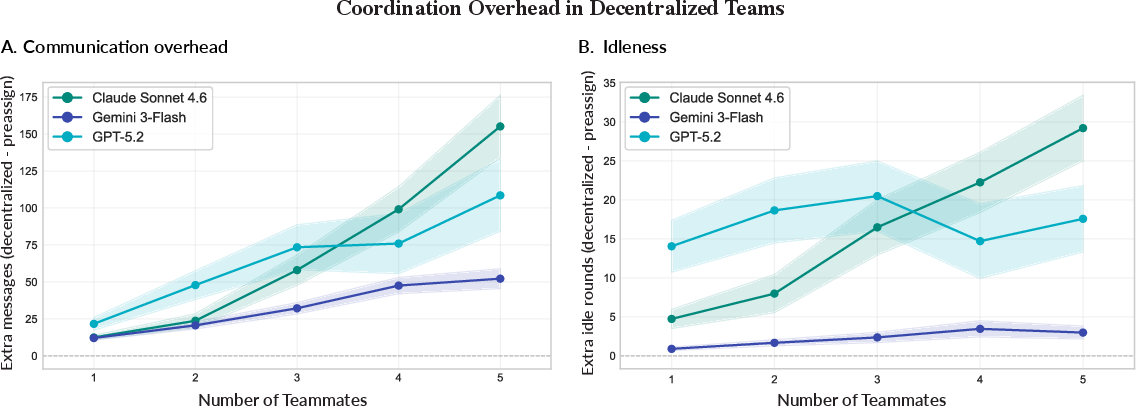
- Communication and coordination have a real cost
- What they saw: Decentralized teams sent more messages and had more “idle rounds” (time spent coordinating without progress). Token usage—the “cost” of AI conversations—often grew faster than the speed benefits, especially on serial tasks.
- Why it matters: Even if teams are faster, they can be less cost-efficient. More teammates can mean more chatter, more tokens, and higher bills.
Why is this important?
- It gives a blueprint: Instead of guessing how to arrange AI teams, we can apply proven ideas from distributed systems to predict when teams will help and how to organize them.
- It saves time and money: Teams aren’t always better. For parallel tasks, teams can shine. For tightly linked steps, adding more agents may waste tokens and energy.
- It reduces errors: Without careful planning, AI teammates can break each other’s work or reinforce mistakes. Clear roles and coordination can prevent that.
What should people designing AI teams take away?
- Match the team to the task:
- Many independent pieces? Teams help—especially with a coordinator.
- Many steps that depend on each other? Teams may not help, or may even slow you down.
- Pick the right structure:
- Centralized (leader assigns tasks): Fewer conflicts and messages, but watch out for single slow teammates holding everyone back.
- Decentralized (self-organizing): More flexible when things are unpredictable, but expect extra messaging, more conflicts, and higher token costs.
- Plan for cost, not just speed:
- Measure both time saved and tokens spent. A small speedup might not be worth a big cost increase.
In short
This paper shows that AI teams behave a lot like groups of computers—and even like groups of people. When work can be done in parallel, teams can be great. When work must happen in order, teams often don’t help. Choosing the right team structure—and knowing the tradeoffs—can make AI teams more reliable, faster, and cheaper to run.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper provides a comprehensive analysis of using distributed systems as a framework for understanding and designing teams of LLMs (LLM teams). However, several areas remain unexplored or underexplored:
- Generalization to Real-world Tasks: The study relies on tasks with pre-specified dependencies. Future work could test the applicability and robustness of this framework on real-world tasks like text analysis, research synthesis, or open-ended reasoning where dependencies must be inferred or discovered dynamically.
- Heterogeneous Teams: The paper focuses on homogeneous agent teams. It is unclear how the framework applies to heterogeneous teams (comprised of different models or capabilities) and whether diversity among agents can lead to superior performance.
- Dynamic Task Structures: The scalability laws and architectural tradeoffs discussed are evaluated using static task structures. Future research is needed to explore how LLM teams perform in dynamic environments with unpredictable changes in task structure or sequencing.
- Fault Tolerance Mechanisms: While distributed systems offer strategies for fault tolerance via redundancy and verification, their adaptation to LLM teams—where agents can hallucinate and produce incorrect outputs—is not covered in-depth. Future studies could explore how distributed system protocols could be modified to address the unique failure modes of LLMs.
- Impact of Communication in Natural Language: The paper does not thoroughly explore how the natural language communication between LLM agents impacts coordination challenges, including ambiguities and interpretation differences, which differ from fixed protocol communications in distributed systems.
- Replication of Dependencies in Learning Processes: The learning process and adaptation mechanisms of LLM teams in relation to replicating and coping with dependencies are not addressed. Future research could focus on adaptive learning mechanisms similar to human learning that account for latent variables and dependencies.
- Resource and Scalability Trade-Offs: The trade-offs between scalability, resource use, and operational budgets are mentioned but not quantitatively analyzed. Further empirical studies quantifying these trade-offs in both static and dynamic operational budgets could provide actionable insights.
- Task-Assisted Design Adaptation: The potential for using distributed systems protocols to assist in the automatic reconfiguration of LLM teams based on task nature and constraints is not discussed. Such adaptability could maximize efficiency and performance.
- Real-world Benchmarking: While theoretical and controlled empirical tests are provided, real-world benchmarking of LLM teams using this framework in diverse application areas is lacking. Further studies that provide benchmarking datasets and metrics across different industries would elucidate practical performance differences.
This list highlights specific areas that future researchers can investigate to deepen our understanding of LLM teams as distributed systems, potentially leading to more efficient, robust, and scalable implementations.
Practical Applications
Immediate Applications
Below are deployable applications that leverage the paper’s findings and distributed-systems framing to improve current LLM-team practice.
- Sector: Software engineering, LLMOps
- Use case: Team-or-not decision gate based on parallelizability
- Product/workflow: Amdahl’s Law “N-planner” that estimates the parallelizable fraction p of a task DAG and recommends team size, architecture (centralized vs. decentralized), or fallback to a single agent
- Assumptions/dependencies: Task can be approximated by a DAG; basic estimation of p (e.g., via static task decomposition or heuristics); access to latency and throughput telemetry
- Sector: Software engineering (agentic coding), DevOps
- Use case: Centralized orchestration for parallelizable coding tasks
- Product/workflow: Leader–worker pattern with preassignment; leader maintains task queue, grants write-locks, merges code, runs tests; workers implement independent functions
- Assumptions/dependencies: Repo write-locks or file-level mutexes; CI tests; frameworks like AutoGen, LangGraph, CrewAI, or custom orchestration
- Sector: Software engineering, Data science
- Use case: Preassigned, parallel data-analysis pipelines
- Product/workflow: Pre-sliced subtasks (data cleaning, EDA, modeling, visualization) assigned to agents with a centralized integrator; scheduled test gates per phase
- Assumptions/dependencies: Clear phase boundaries; reliable evaluation harness; shared artifact store (datasets, notebooks, reports)
- Sector: LLMOps/FinOps, Platform engineering
- Use case: Token-to-speedup guardrails and budgets
- Product/workflow: Policy that deploys teams only when projected speedup ≥ token multiplier; dashboards showing speedup, token multiplier, message counts, idle rounds, conflict rates
- Assumptions/dependencies: Token metering, latency logging, cost targets; SLOs for speed/cost
- Sector: LLMOps, Reliability engineering
- Use case: Straggler mitigation via speculative execution
- Product/workflow: Duplicate slow tasks after a latency threshold; accept first valid result (MapReduce-style replication)
- Assumptions/dependencies: Deterministic validation of outputs (tests, checksums, schema checks); budget to tolerate some redundancy
- Sector: Software engineering, Collaboration tooling
- Use case: Consistency controls for shared artifacts
- Product/workflow: File-level locking, branch-per-task with gated merges, “claim a task” tickets; disallow concurrent writes on the same file; detect and block rewrites
- Assumptions/dependencies: VCS integration; minimal protocol for claiming tasks; test suite to catch regressions
- Sector: LLM frameworks/tooling
- Use case: O(n) communication topologies
- Product/workflow: Star topology (agents talk only to the coordinator) instead of all-to-all; message throttling and batching
- Assumptions/dependencies: Coordinator component; message bus or agent framework supporting topology constraints
- Sector: QA/Testing, Safety
- Use case: Intermediate-test gating to prevent error propagation
- Product/workflow: Require passing tests after each subgraph/phase; automatic rollback or reassign on failure
- Assumptions/dependencies: Fast, granular tests; artifact versioning; rollback capability
- Sector: Product management, Ops
- Use case: “Do nothing” policy for serial tasks
- Product/workflow: If p is low (serial workflows), force single-agent execution or very small teams; disallow decentralized coordination
- Assumptions/dependencies: Simple p-threshold policy; ability to classify workflows as serial/mixed/parallel
- Sector: Education (CS, Systems, AI)
- Use case: Teaching labs using agent teams as distributed systems
- Product/workflow: Course modules where students tune team size/architecture, measure speedup, token cost, conflicts; compare to Amdahl’s/Gunther’s laws
- Assumptions/dependencies: Classroom-accessible LLM APIs; scripted tasks with measurable outcomes
- Sector: Scientific computing, Research tooling
- Use case: Reproducible agent-team experiments with DS metrics
- Product/workflow: Benchmark suites that report speedup, idle rounds, conflict events, token multiplier alongside accuracy
- Assumptions/dependencies: Open tasks/datasets; experiment harness that logs DS-style metrics
- Sector: Compliance, Procurement, Sustainability
- Use case: Cost and energy checks in RFPs for agent platforms
- Product/workflow: Require reporting of token-to-speedup ratios, comms topology, and conflict mitigation; penalize O(n2) communication and uncontrolled replication
- Assumptions/dependencies: Vendors can expose metrics; rough energy-per-token factors available
- Sector: Personal productivity (daily life)
- Use case: Minimalist agent teamwork for routine tasks
- Product/workflow: Single “planner” agent with one “executor” only when subtasks are truly independent (e.g., parallel hotel and flight searches); shared checklist doc with explicit ownership
- Assumptions/dependencies: Users can specify roles; tools for shared notes; small, well-scoped tasks
- Sector: Security/Trust
- Use case: Sycophancy and misinformation dampening via verification
- Product/workflow: Require independent verification agent with separate prompt lineage; enforce majority with justification, not mere votes
- Assumptions/dependencies: Access to external tools/tests; prompts that reward dissent backed by evidence
- Sector: Data platforms, BI
- Use case: Centralized coordination for report generation
- Product/workflow: Coordinator assigns chart/table specs to agents; only coordinator updates the final report; agents write to scratch area
- Assumptions/dependencies: BI layer or doc generation framework; versioned scratch workspace
Long-Term Applications
These applications require further research, standardization, or advances in model capabilities and tooling.
- Sector: LLM frameworks, Operating systems for agents
- Use case: Agent schedulers with DS-grade primitives
- Product/workflow: OS-like runtime offering queues, locks, semaphores, leader election, backpressure, admission control, and preemption for agent teams
- Assumptions/dependencies: Standard APIs for agent coordination; cross-framework adoption; robust observability
- Sector: Tooling/Automation
- Use case: Automatic p-estimation and topology selection
- Product/workflow: Planners that parse tasks, infer dependency graphs, estimate p, predict contention/overhead (USL), and auto-select centralized/decentralized or hybrid topologies and team sizes
- Assumptions/dependencies: Accurate graph extraction from vague specs; performance models validated across domains
- Sector: Collaboration systems, Knowledge management
- Use case: CRDT-like conflict resolution for natural-language artifacts
- Product/workflow: Semantically aware merge for docs/code/plans, tolerant of concurrent edits; reconciliation strategies with model-assisted diffs and intent preservation
- Assumptions/dependencies: Reliable semantic diff/merge; evaluation of semantic correctness, not just syntax
- Sector: Reliability/Safety
- Use case: Fault-tolerant agent teams via consensus/verification
- Product/workflow: Multi-version execution, majority/Byzantine-resilient aggregation, task-level quorum thresholds; probabilistic truth maintenance
- Assumptions/dependencies: Cost-effective redundancy; calibrated uncertainty estimates; ground truth oracles for critical steps
- Sector: Cloud/Serverless, Marketplaces
- Use case: Serverless agent pools with heterogeneous load balancing
- Product/workflow: Pool of diverse base models and roles; schedulers assign tasks based on skill/latency; task stealing and dynamic replication
- Assumptions/dependencies: Cross-model orchestration; skill profiling; cost-aware routing
- Sector: Sustainability, Policy
- Use case: Carbon-aware agent orchestration
- Product/workflow: Scheduler aligns team runs with clean-energy windows; discourages decentralized or large teams when grid carbon intensity is high
- Assumptions/dependencies: Carbon-intensity signals; flexible SLAs; organizational policies
- Sector: Healthcare, Finance, Legal (regulated domains)
- Use case: Safety-assured multi-agent workflows
- Product/workflow: Centralized coordination with verification gates; lineage tracking; audit logs recording conflicts, resolutions, and cost/speed metrics
- Assumptions/dependencies: Domain-specific validation tools; formal review protocols; regulatory acceptance
- Sector: Scientific discovery, R&D
- Use case: Adaptive exploration–exploitation via agent collectives
- Product/workflow: Decentralized exploration with periodic consensus; speculative replication on promising leads; automated pruning of redundant lines
- Assumptions/dependencies: Benchmarks for discovery quality; robust experiment evaluation; budget for replication
- Sector: Standards/Benchmarking
- Use case: Industry-wide metrics for agent-team efficiency
- Product/workflow: Benchmarks that report speedup, token multiplier, O(n) vs. O(n2) comms, conflict/idle rates, straggler gaps; standardized reporting in papers and products
- Assumptions/dependencies: Community adoption; neutral benchmark suites; shared telemetry schema
- Sector: Education/Training
- Use case: Distributed-AI curricula and certifications
- Product/workflow: Certification tracks teaching DS principles for LLM teams, architecture selection, and cost/energy governance
- Assumptions/dependencies: Institutional buy-in; open-source labs; updated textbooks
- Sector: Safety/Governance
- Use case: Procurement and compliance norms for agent systems
- Product/workflow: Policy templates that cap team size by measured p, require centralized control for serial tasks, mandate verification and auditability
- Assumptions/dependencies: Alignment across legal, risk, and engineering; third-party audits
- Sector: Advanced reasoning systems
- Use case: Hybrid centralized–decentralized architectures
- Product/workflow: Systems that switch modes based on live telemetry (conflict rate, idle rounds, straggler gap), e.g., centralized write path with decentralized read/analysis; dynamic rebalancing
- Assumptions/dependencies: Reliable runtime signals; stable control policies; safe hot-swapping of coordination modes
Key Assumptions and Dependencies Across Applications
- Model capability: Findings were shown on coding tasks with current LLMs; generalization to open-ended reasoning relies on model/tool quality.
- Observability: Accurate logging of tokens, latencies, messages, conflicts, and test outcomes is essential to apply the metrics and gates.
- Task structure: Best results come when tasks can be approximated by a DAG; p-estimation is nontrivial in messy real-world workflows.
- Tooling integration: Version control, test harnesses, artifact stores, and orchestration frameworks must expose coordination primitives (locks, queues, claims).
- Cost/energy constraints: Some strategies (e.g., replication, consensus) trade cost for robustness; organizations need explicit budgets and policies.
- Human oversight: Especially in regulated sectors, human-in-the-loop review, audit trails, and fail-safes remain critical.
Glossary
- Amdahl's Law: A scalability law stating the maximum speedup of a system is limited by the serial portion of the workload. "Amdahl's Law formalizes how these constraints limit speedup with available processors under fixed workloads:"
- Architectural trade-offs: Design compromises between system properties (e.g., consistency, performance, robustness) when choosing an architecture. "including consistency conflicts, architectural trade-offs, communication overhead, stragglers, task scheduling, and increased compute, energy, and monetary costs."
- Centralized architectures: Systems where a single coordinator assigns tasks and integrates results to simplify consistency and reduce communication channels. "Centralized architectures, in which one node delegates tasks and integrates results, reduce overhead by routing communication through fewer channels."
- Common-pool resource problems: Economic/game-theoretic settings where multiple agents share a limited resource that can be depleted without coordination. "Experimental studies show that sufficiently capable LLM agents can successfully cooperate in simple economic settings like common-pool resource problems"
- Communication overhead: Extra time and cost incurred by exchanging messages among components in a system. "decentralized LLM teams accumulate substantially more communication and coordination overhead than preassigned teams"
- Concurrent writes: Simultaneous edits to the same shared resource that can overwrite or corrupt state. "Decentralized teams exhibited a substantial number of concurrent writes, in which two or more agents edit the same file simultaneously"
- Consensus: A protocol/mechanism by which distributed components agree on a single value or state despite failures. "fault tolerance through mechanisms such as redundancy, replication, and consensus."
- Consistency: The property that all components observe a coherent view of shared state despite concurrent updates. "Ensuring that all nodes maintain consistency requires synchronization protocols that determine how and when nodes exchange updates and commit results."
- Consistency conflicts: Inconsistencies arising when concurrent operations produce incompatible updates to shared state. "specifically, consistency conflicts and communication overhead"
- Context windows: The limited amount of text an LLM can attend to in a single inference. "context windows bound how much information they can access at once"
- Concurrency: Multiple components performing tasks simultaneously, potentially causing coordination challenges. "Concurrency: In an LLM team, multiple agents are working on tasks simultaneously."
- Contention: Performance degradation from competing for shared resources. "Bottlenecks due to locking, sequential dependencies between subtasks, shared memory accesses, or resource contention force nodes to wait"
- Decentralized architectures: Systems without a single coordinator where components self-assign tasks, trading robustness for higher coordination costs. "Decentralized architectures mitigate this risk by allowing tasks to be assigned dynamically, but at the cost of greater coordination overhead and elevated risk of conflicts"
- Deliberative collectives: Multi-agent setups where agents debate/critique each other to improve reasoning or accuracy. "Some approaches emphasize deliberative collectives, in which multiple agents debate or critique one another to improve reasoning accuracy"
- Fault tolerance: The ability of a system to continue operating despite component failures. "fault tolerance through mechanisms such as redundancy, replication, and consensus."
- Gustafson's Law: A scalability principle modeling performance when workload grows with system size. "including Gustafson's Law, which models performance under scalable workloads"
- Gunther's Universal Scalability Law: A model capturing non-linear and non-monotonic scaling due to coordination and contention. "and Gunther's Universal Scalability Law, which captures non-monotonic scaling due to coordination and contention overhead"
- Hallucinations: LLM-generated outputs that are incorrect or fabricated but presented confidently. "hallucinations, missing relevant context, or failing to respond"
- Heterogeneous load balancing: Distributing tasks across workers with differing capabilities to optimize performance. "algorithms from heterogeneous load balancing"
- Idle rounds: Interaction steps with communication but no completed task progress. "idle rounds, or interaction steps in which agents communicated but did not complete any task progress"
- Independence: Components operate on local state without global knowledge or a global clock. "Independence: LLM agents are independent, maintaining their own local contexts with only partial observability of the state of the broader task and team."
- Kruskal–Wallis test: A non-parametric statistical test for comparing medians across multiple groups. "(Kruskal-Wallis: , )"
- Latency: The time delay between initiating and completing an operation. "models that exhibit greater variance in API latency"
- Load balancing: Assigning work to resources to avoid bottlenecks and maximize throughput. "scheduling and load balancing protocols"
- MapReduce: A distributed computing framework that partitions tasks, processes them in parallel, and aggregates results. "Algorithms like MapReduce duplicate slow or late-stage tasks across multiple workers and accept the earliest completion"
- Mann–Whitney U test: A non-parametric test for comparing differences between two independent groups. "(MannâWhitney , )"
- Message passing: Communication paradigm where components exchange discrete messages rather than sharing memory. "communication (information is exchanged through message passing)"
- Parallelizability: The extent to which a task can be split into independent parts that run concurrently. "performance gains depend primarily on parallelizability, or the extent to which a task can be executed concurrently."
- Partial observability: Agents have limited access to the full system state when making decisions. "with only partial observability of the state of the broader task and team."
- Replication: Duplicating tasks or data across components to reduce latency or increase reliability. "Distributed systems mitigate this problem through replication."
- Single points of failure: Components whose failure can bring down the entire system. "single points of failure."
- Spearman's rho: A rank-based correlation coefficient measuring monotonic relationships. "Spearman , "
- Stragglers: Slow workers whose delays determine overall completion time in synchronized phases. "one slow agent (or ``straggler'') can delay the team as a whole."
- Synchronization protocols: Rules ensuring orderly coordination and consistent state across concurrent components. "Ensuring that all nodes maintain consistency requires synchronization protocols that determine how and when nodes exchange updates and commit results."
- Task scheduling: The allocation and ordering of tasks across resources over time. "including consistency conflicts, architectural trade-offs, communication overhead, stragglers, task scheduling, and increased compute, energy, and monetary costs."
- Temporal consistency violations: Errors from executing tasks out of required order relative to dependencies. "Finally, we observed temporal consistency violations, in which an agent would attempt to implement a task out of order without its predecessor being implemented yet."
- Throughput: The amount of work completed per unit time by a system. "A central motivation for distributed systems is scalable performance: if large-scale computing tasks are decomposed across many nodes, increasing system size can improve efficiency in terms of completion times or throughput."
- Topology: The structure of communication links among agents/nodes affecting performance and scaling. "topology substantially affects scaling and performance"
- Wall-clock time: Real elapsed time as measured by a clock, including all delays. "efficiency was measured using wall-clock time in seconds."
- Wilcoxon signed-rank test: A non-parametric test for comparing paired samples. "Wilcoxon signed-rank, , "
Collections
Sign up for free to add this paper to one or more collections.

