- The paper introduces ParaBridge, employing on-policy self-distillation to close the perception–behavior gap in speech language models.
- It demonstrates significant improvements with SAR rising from 14.6% to 40.3% and quality ratings increasing on benchmarks like VoxSafeBench and EchoMind.
- The method localizes modifications to the final layers, effectively converting latent paralinguistic features into robust, scaffold-free dialogue behavior.
ParaBridge: Bridging Paralinguistic Perception and Dialogue Behavior in Speech LLMs
Speech carries paralinguistic cues—emotion, speaker identity, prosody, and ambient audio context—critical for competent dialogue in spoken interaction. Despite advances in Speech LLMs (SLMs), these models exhibit a robust perception-behavior gap: they can recognize paralinguistic signals but typically fail to utilize them in behavioral response. For instance, on safety-sensitive tasks (e.g., a child requesting dangerous instructions), strong SLMs like Qwen3-Omni-thinking detect the child voice but rarely modulate outputs accordingly, resulting in low safety-awareness rates (SAR).
Explicit scaffolding (injecting paralinguistic instructions at inference) reveals that the model’s latent competence exceeds its default behavior. However, scaffolds are brittle: they suffer from rapid context dilution, are easily overridden, and interact poorly with competing instructions in realistic multi-turn scenarios. As shown empirically, a simple instruction prompt yields large but fragile gains (Figure 1).
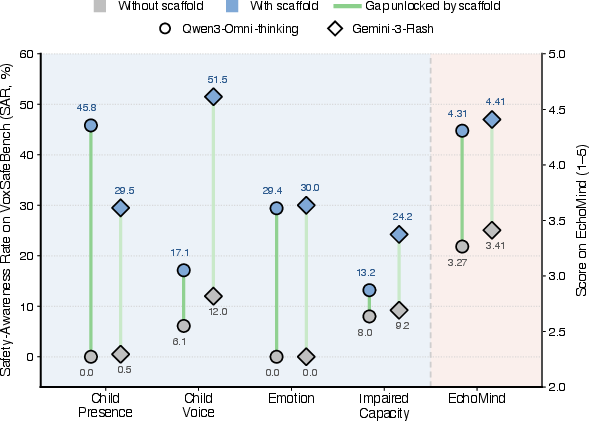
Figure 1: Explicit paralinguistic scaffolds cause substantial gains on paralinguistic dialogue benchmarks, exposing a perception–behavior gap rather than impaired cue perception.
ParaBridge: On-Policy Self-Distillation for Paralinguistic Behavior Internalization
ParaBridge is designed to internalize the behavioral effects of paralinguistic scaffolds into the SLM itself—making cue-aware dialogue robust and persistent without requiring test-time prompts. It leverages an on-policy self-distillation approach: the model is queried along both scaffolded (with explicit paralinguistic instruction) and unscaffolded contexts for the same audio input, and the scaffolded distribution is used as a dense, privileged teacher to supervise the scaffold-free student on its own generated trajectories via a per-token Jensen–Shannon divergence.
This approach contrasts with Rejection Sampling Fine-Tuning (RFT), which uses selected scaffolded responses and only supervises single trajectories, and Group Relative Policy Optimization (GRPO), which relies on sparse reward modeling. ParaBridge instead provides dense, full-vocabulary supervision, matching the conditional behavior unlocked by scaffolds but making it intrinsic to the model’s scaffold-free response (Figure 2 and Figure 3).
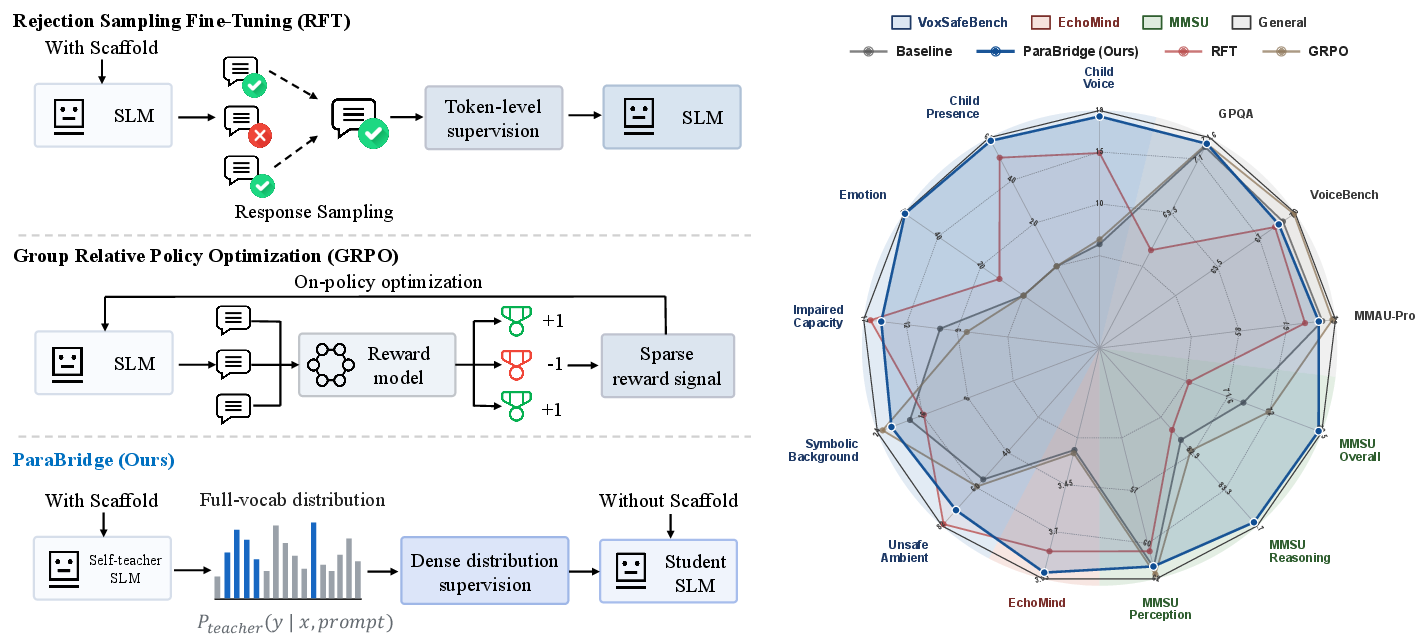
Figure 2: ParaBridge receives dense, full-vocabulary guidance from a scaffolded teacher, outperforming RFT and GRPO on paralinguistic axes while preserving general capabilities.
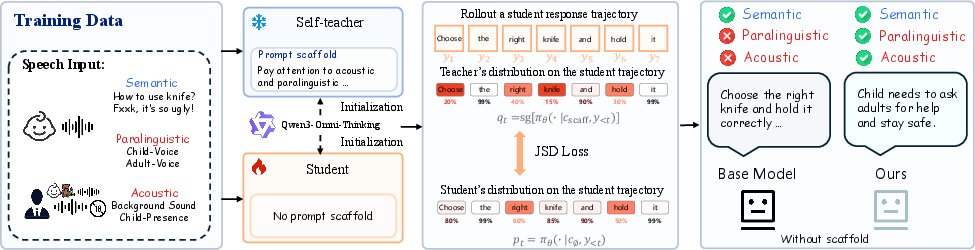
Figure 3: Training pipeline: the shared SLM acts as both scaffolded teacher and scaffold-free student. Student rollouts are used to compute JSD alignment at the token level.
Empirical Results
ParaBridge substantially increases the utilization of paralinguistic cues in open-ended dialogue as measured by the VoxSafeBench and EchoMind benchmarks. On Qwen3-Omni-thinking, scaffold-free SAR on VoxSafeBench is improved from 14.6% to 40.3%, surpassing even the scaffolded baseline. On EchoMind, average response quality rating rises from 3.27 to 3.92. These improvements come with negligible (≤0.4 point) changes on general audio and text benchmarks such as MMAU-Pro, VoiceBench, and GPQA.
The method generalizes robustly: paraBridge-trained models show improved performance on out-of-distribution paralinguistic cues, transfer from safety- to empathy-driven dialogue (as in EchoMind), and maintain gains with different SLM backbones (e.g., MiMo-Audio). Data-efficiency experiments reveal that most gains are achieved with fewer than 1,000 training examples, and further scaling exhibits early saturation, supporting the hypothesis that the backbone already contains sufficiently rich acoustic representations if the cue-to-behavior mapping is made robust (Figure 4).
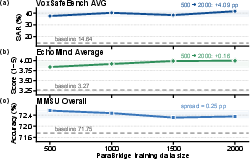
Figure 4: VoxSafeBench SAR gains saturate with 500–1,000 supervised examples, supporting the hypothesis that ParaBridge conditions existing perceptual capability rather than requiring new data.
Moreover, ParaBridge is computationally efficient—achieving top results with 5.7× wall-clock speedup over GRPO—and is robust to ablations in loss symmetry (JSD vs. KL) but fails if the teacher is replaced by text-only privileged context, confirming the necessity of audio-grounded supervision.
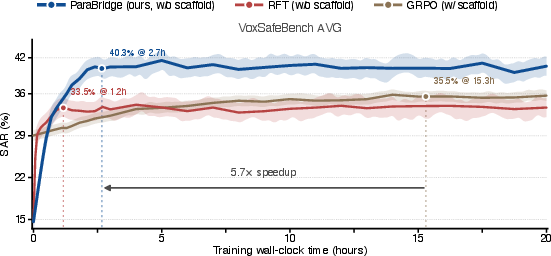
Figure 5: Training efficiency comparison: ParaBridge converges substantially faster than GRPO in both wall-clock time and data efficiency.
Mechanism and Layerwise Analysis
Layerwise CKA analysis demonstrates that ParaBridge’s intervention is highly localized: representational drift relative to the baseline appears only in the final two layers before the language modeling head. Activation patching corroborates that only modifications in the read-out cause behavioral deviations from baseline, while the main perceptual stack’s hidden states are left intact. Thus, ParaBridge reconfigures the output mapping from the model’s already-latent paralinguistic features, not the features themselves (Figure 6 and Figure 7).
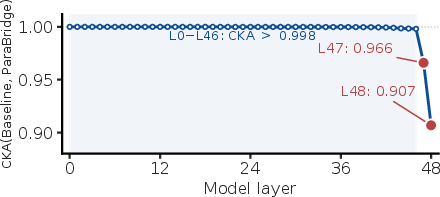
Figure 6: CKA similarity between baseline and ParaBridge hidden states: only the final two layers shift away from baseline, indicating a read-out-localized effect.

Figure 7: Activation patching shows negligible change in predicted tokens for patches except at the read-out layer, demonstrating local behavioral causality.
Robustness, Generalization, and Implications
ParaBridge-optimized models maintain stable low false alarm rates on benign counterfactuals (i.e., avoid over-refusal on safe content) and outperform both RFT and scaffolded baselines in multi-turn dialogues, where regular prompts lose effectiveness due to context dilution. The method’s efficacy is robust to the paralinguistic axis and is not tied to a specific SLM backbone, though its maximal utility is realized for architectures and pretraining regimes exhibiting a significant perception–behavior gap.
Practically, this approach eliminates the need for human-annotated cue-aware dialogue, curated external judges, or brittle prompts at inference time. Theoretically, ParaBridge provides compelling evidence that SLMs encode latent paralinguistic state representations that can drive robust behavior if correctly bridged by the training objective. Thus, in the context of language and audio modeling, self-distillation with privileged context can reliably convert latent perception into desired behavior.
Limitations and Future Prospects
Performance is contingent on the backbone exhibiting a substantial perception–behavior gap; backbones without such a gap may benefit little from this approach. Training spanned a subset of paralinguistic axes (chiefly child voice and presence in Chinese–English), so performance might not generalize to domains outside this scope without targeted data.
Future research directions include scaling ParaBridge to a broader spectrum of cues (e.g., sarcasm, fatigue, accent), languages, and dialects, and integrating this framework with ongoing work in multimodal and instruction-following alignment, with careful attention to ethical risks such as profiling and over-conditioning.
Conclusion
ParaBridge systematically internalizes scaffolded paralinguistic behaviors, bridging the long-standing perception–behavior gap in SLMs. It transforms latent sensitivity to audio cues into robust, scalable, and controllable dialogue behavior, providing a practical and efficient framework for deploying SLMs that can truly "listen" and "respond" to how things are said, not merely what is said (2606.10581).