- The paper introduces a multi-stage framework combining explicit cognitive CoT reasoning and RL-based alignment to overcome semantic dominance in audio dialogue.
- It leverages the LIME-440K dataset and a novel EIPS pipeline to markedly improve emotion recognition accuracy from 24% to 46% in conflict scenarios.
- The approach decouples semantic and acoustic cues to generate nuanced empathetic responses, setting the stage for advanced multimodal affective models.
CogAudio-LLM: Cognitive Affective Reasoning and Empathetic Response Alignment in Audio LLMs
Introduction
This paper addresses the critical limitations of Audio LLMs (ALMs) in affective spoken dialogue: the persistent issue of semantic dominance, where text-biased pre-training suppresses the influence of paralinguistic acoustic cues, and the absence of psychological reasoning depth, resulting in generic, emotion-agnostic responses. The authors propose CogAudio-LLM, a framework that integrates a cognitive psychological Chain-of-Thought (CoT) reasoning mechanism with a novel multi-stage training paradigm and reinforcement learning (RL)-based alignment. Central to this framework are the LIME-440K dataset—engineered for strict semantic-acoustic decoupling—and the EIPS reasoning structure, which together drive significant improvements in both fine-grained emotion recognition and nuanced empathetic response generation.
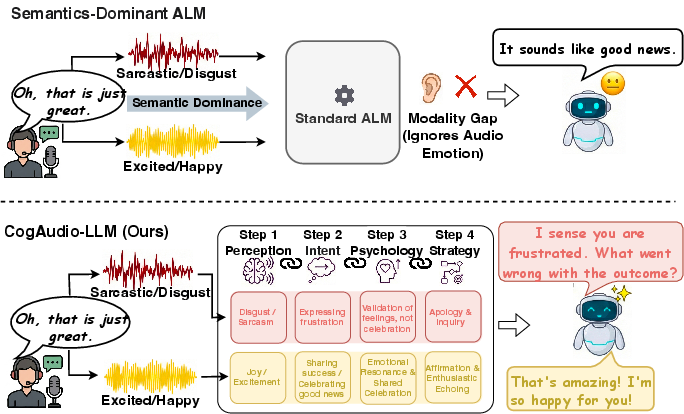
Figure 1: Standard ALMs misjudge emotions due to semantic dominance and the modality gap. In contrast, CogAudio-LLM uses a 4-step EIPS cognitive framework to ensure precise empathetic alignment.
LIME-440K Dataset
The LIME-440K dataset is constructed to decouple textual content from emotional valence, challenging models to rely fully on paralinguistic information for affect recognition. The core "one-text, multi-emotion" sampling guarantees that acoustically distinct emotional states are mapped to lexically identical prompts, effectively disrupting the text-to-emotion shortcut that conventional ALMs exploit. Data augmentation with re-annotated open resources and expressive TTS—controlling for emotion intensity and environmental noise—further expands coverage and robustness.
The CoT annotation protocol is automated via LLM distillation and carefully quality-controlled, encoding the EIPS (Emotion Perception, Intent Extraction, Psychological Modeling, Strategy Formulation) framework at scale. This explicit separation of emotional cues, psychological inference, and strategy ensures the training data itself scaffolds high-level affective reasoning capabilities.
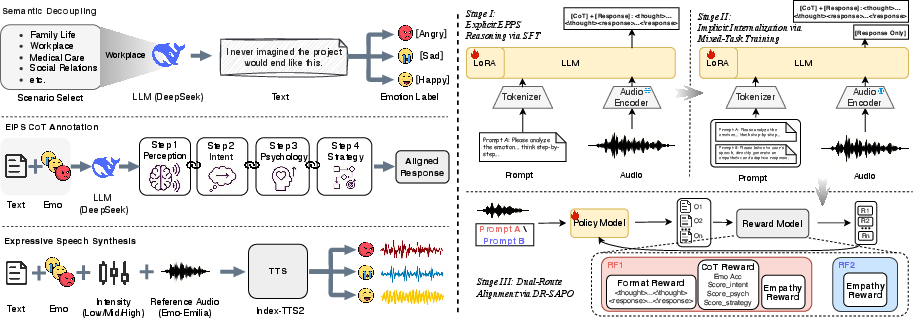
Figure 2: The pipeline of data generation and model training. Left: Construction of the LIME-440K dataset via semantic decoupling, EIPS CoT annotation, and expressive synthesis. Right: The three-stage training architecture of CogAudio-LLM, encompassing explicit reasoning SFT, implicit mixed-task internalization, and DR-SAPO dual-route alignment.
CogAudio-LLM Architecture and Training Paradigm
CogAudio-LLM employs a three-stage training paradigm targeting explicit and implicit internalization of cognitive reasoning:
Stage I – Explicit EIPS Reasoning (Supervised Fine-Tuning):
The core model, Qwen2.5-omni, is fine-tuned to generate the full EIPS reasoning chain and final response, mapping input audio to explicit cognitive analysis and empathetic strategy. This rigid scaffolding severs model reliance on textual semantics, directly mapping acoustic information to affect and psychological inference.
Stage II – Implicit Internalization (Mixed-Task Training):
A hybrid training regime where the model alternates between generating explicit EIPS chains and direct empathetic responses (without intermediate reasoning output). This step induces the internalization of the EIPS pathway, enabling scalable deployment without verbose generation yet preserving response quality rooted in cognitive reasoning.
Stage III – Dual-Route Soft Adaptive Policy Optimization (DR-SAPO, RL-based):
A reinforcement learning stage refines dual policy heads: one optimizing for logical rigor in full CoT reasoning (rewarding cognitive completeness and format correctness), the other maximizing empathy and psychological insight in the response-only generation. Soft gating and route-specific reward allocation ensure stable credit assignment for both explicit and implicit cognitive processes. Human and LLM-based evaluators enforce external validity for reward signals.
Experimental Protocol and Results
Evaluations are performed on both speaker-holdout and spontaneous speech benchmarks, including ESD-Test and ICASSP HumDial-EIBench, with test splits specifically designed to expose "semantic-acoustic conflict" scenarios (e.g., sarcasm, forced affect) to measure the model's ability to resolve information from acoustics versus misleading semantics.
Across all metrics, CogAudio-LLM demonstrates a stark performance delta over previous ALMs and commercial closed models including GPT-4o-Audio; specifically:
- On semantic-acoustic conflict sets, baseline models (including GPT-4o-Audio, GLM-4-Voice, and Kimi-Audio) show empathy scores below 2.0, confirming failure to resolve paralinguistic affect in spite of world knowledge and context priors.
- CogAudio-LLM achieves an LLM- and human-evaluated empathy score of 2.91 and 3.16, respectively, on conflict sets—substantially higher than the closest competitors.
- Fine-grained emotion classification accuracy almost doubles over the base LLM (Qwen2.5-omni) in semantic-acoustic conflict scenarios, as shown by a jump from 24.0% to 46.0%.
- The ablation study reveals the necessity of both explicit CoT supervision and dual-route RL: implicit internalization without RL yields empathy scores equivalent to explicit EIPS reasoning, but combining both mechanisms pushes implicit response scores to 2.91, indicating successful induction of internalized affective logic.
Implications and Future Directions
Practical implications are immediate: CogAudio-LLM sets a new bar for affective conversational models, demonstrating that robust empathetic response is achievable only by explicitly decoupling semantic and paralinguistic channels and scaffolding psychologically informed reasoning into the model architecture and training process. The necessity of explicit multi-step affective reasoning further invalidates prior techniques reliant on lightweight acoustic embeddings or simple prompt engineering.
Theoretically, this work demonstrates that cognitive modeling frameworks adapted from psychology can be operationalized at web scale via automated LLM-powered annotation and RL-based policy optimization. The dual-route DR-SAPO approach highlights the importance of route-specific optimization and reward allocation in aligning both cognitive rigor and response pragmatics.
The residual domain gap between synthetic TTS data and spontaneous micro-prosodic variation remains—future work should target unsupervised or self-supervised adaptation from in-the-wild affective speech. Further, extending multi-stage cognitive alignment to multimodal (e.g., audio-visual) and multilingual contexts may accelerate generalization and mitigate bias.
Conclusion
CogAudio-LLM advances the field of affective spoken dialogue by tightly integrating large-scale semantic-acoustic decoupled data, structured cognitive reasoning, and reinforcement-aligned training. These components collectively yield reliable emotion recognition and context-aware empathetic response, even in the presence of semantic-pragmatic conflicts. The release of the LIME-440K dataset and EIPS framework provides a long-term foundation for rigorous study and engineering of affective intelligence in ALMs.

