- The paper presents a modality-aware hybrid post-training method that applies RL-based preference optimization exclusively to text tokens while using dense supervision to stabilize acoustic outputs.
- Empirical results demonstrate significant gains in intelligence (IQ) and expressiveness (EQ), outperforming full-token preference models with improvements of up to 5.2 points in IQ.
- Dynamic gating with EMA smoothing ensures training stability and a balanced IQ–EQ trade-off, offering a robust framework for future end-to-end multimodal dialogue models.
WavAlign: Adaptive Hybrid Post-Training for End-to-End Spoken Dialogue Models
Background and Motivation
End-to-end spoken dialogue models integrate both speech understanding and speech generation in a single backbone, theoretically offering superior expressiveness and perceptual abilities compared to cascaded text-based pipelines. Despite impressive advances, current open-source end-to-end architectures exhibit suboptimal semantic competence and paralinguistic expressiveness, often failing to outperform modular systems. The application of RL-based preference optimization, successful in text and vision modalities, proves challenging for spoken dialogue due to weak cross-modal gradient coupling, noisy acoustic rewards, and fragile credit assignment. These issues manifest prominently when sequence-level preference objectives are applied over mixed text–speech outputs, leading to instability and failure modes including semantic–acoustic trade-offs, acoustic drift, and degraded speech quality.
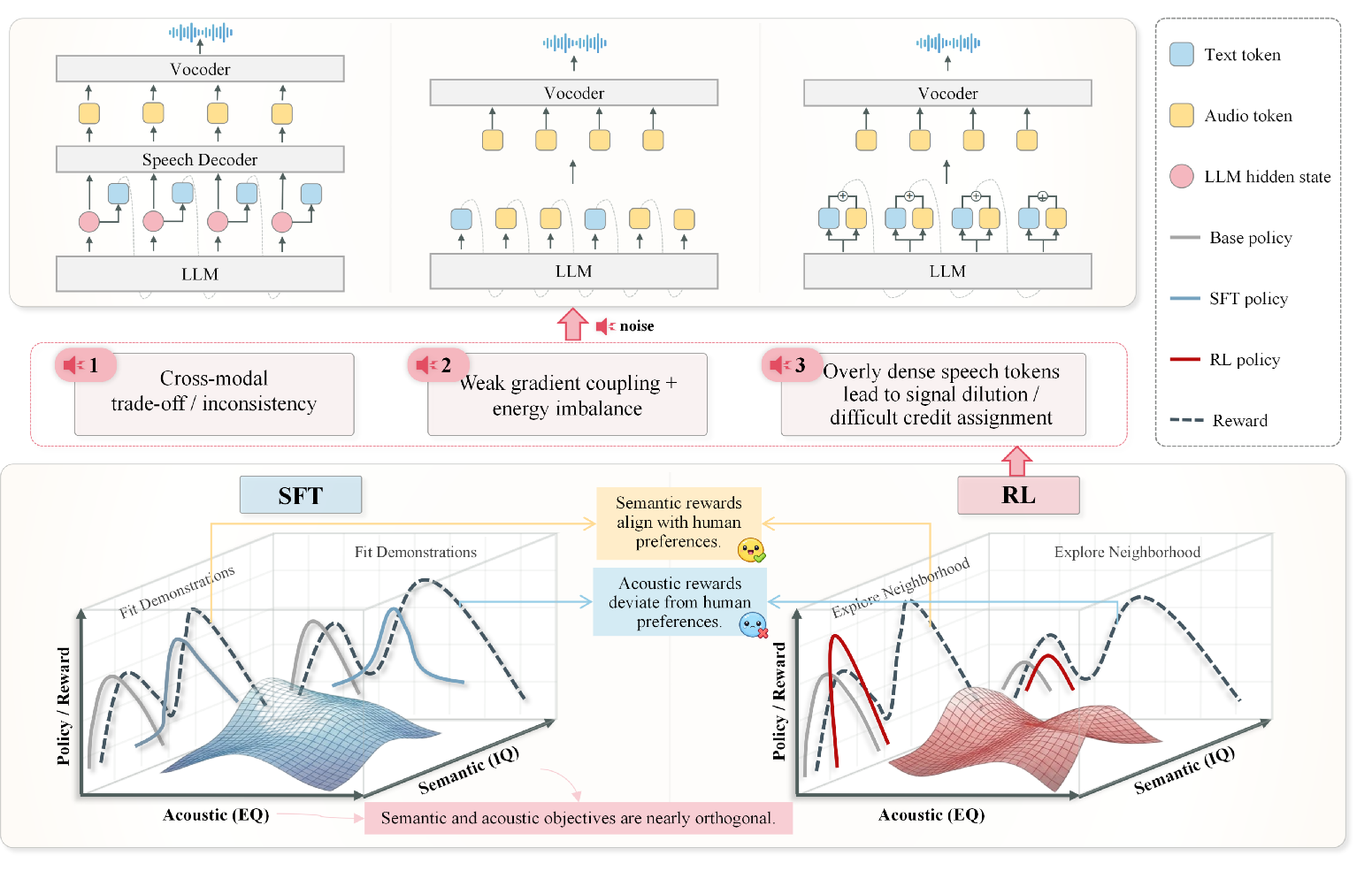
Figure 1: Motivation and failure mode of unified RL for end-to-end spoken dialogue models, revealing cross-modal instability and semantic–acoustic trade-offs.
Methodological Analysis
Objective Decomposition and Empirical Observations
WavAlign rigorously characterizes the optimization landscape for spoken dialogue models, partitioning token-wise log-likelihood into semantic (text) and acoustic (speech) components. Empirical analysis demonstrates that dense supervision via SFT induces coherent and substantial distribution shifts, stabilizing acoustic attributes, whereas preference optimization (PO/RL) is inherently local under trust-region constraints, producing modest, localized effects on token probabilities.
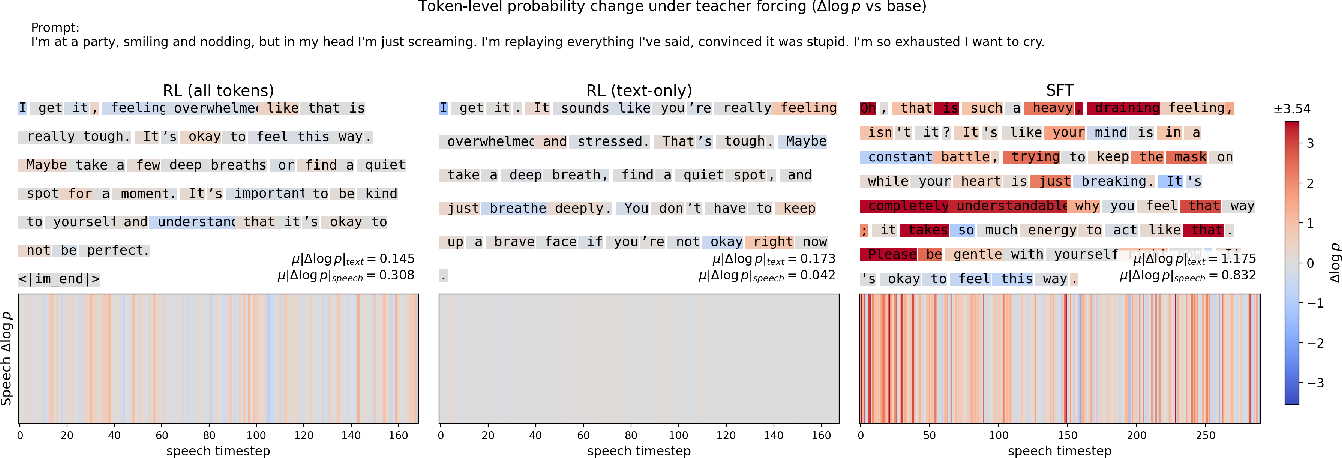
Figure 2: Token-level probability change under teacher forcing (Δlogp vs. base) for the same prompt, showing global shifts for SFT, and localized effects for preference optimization.
Reward-model consistency studies confirm that semantic preference judgments, whether by human or automatic judges, are significantly more reliable and stable than acoustic evaluations, driving the recommendation to restrict preference-driven updates to text-token regions and rely on dense supervision as a distribution anchor for speech tokens.
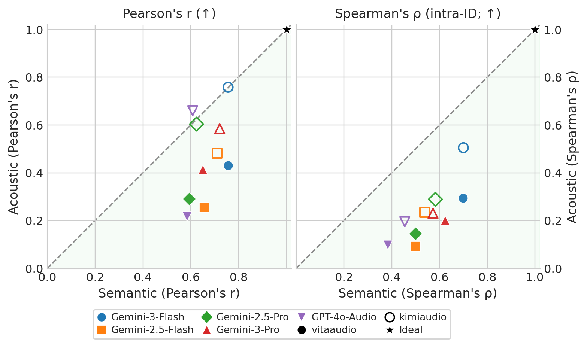
Figure 3: Judge/reward-model agreement with human evaluation demonstrates stronger and steadier semantic assessment compared to acoustic dimensions.
Gradient geometry analysis further reveals a severe cross-modal energy imbalance: the semantic gradient component dominates, while acoustic gradients under preference objectives are nearly orthogonal and high variance, destabilizing prosody and timbre when assigned indiscriminately across speech tokens.
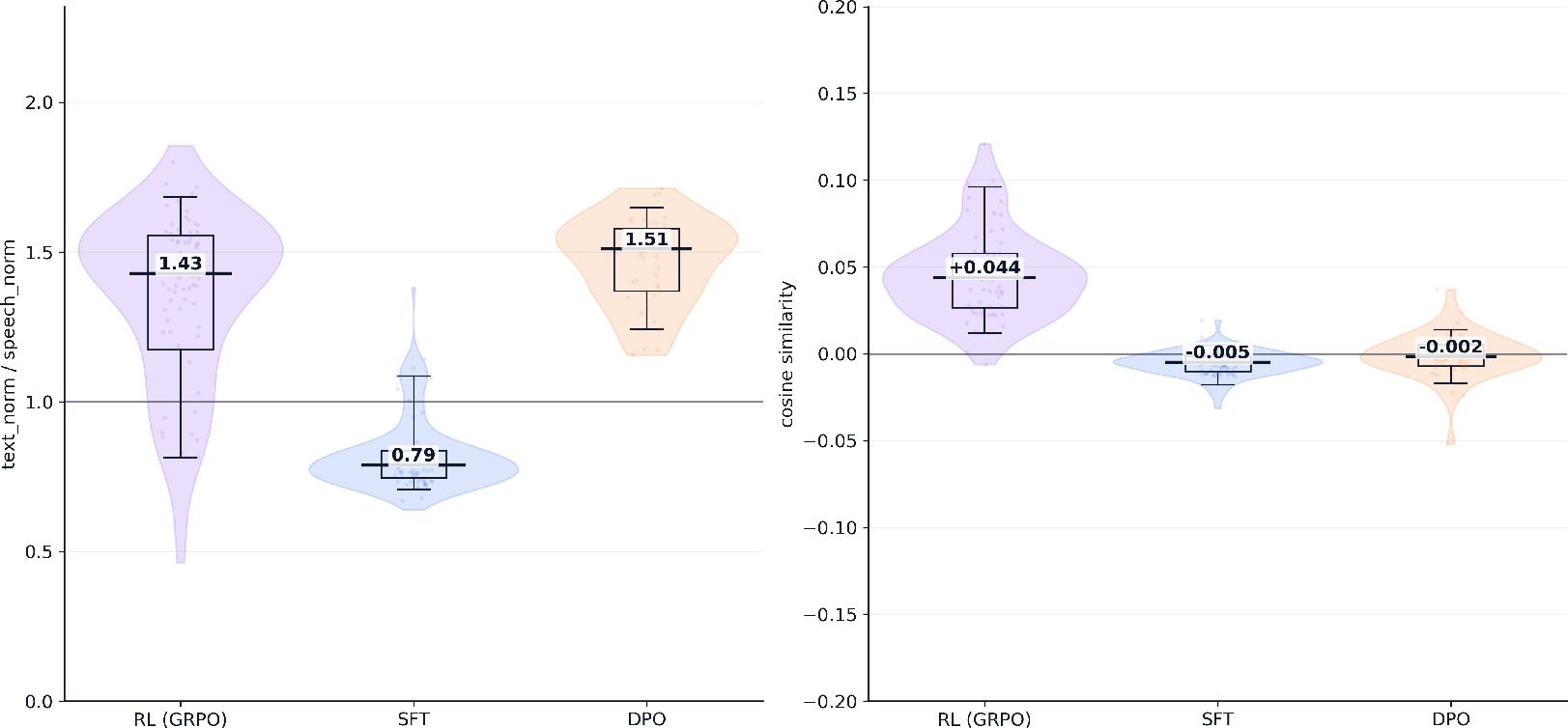
Figure 4: Empirical geometry of text vs. speech gradients across objectives, with preference gradients overwhelmingly concentrated on semantic regions.
Repeated sampling studies uncover lower acoustic discriminability compared to semantic dimensions, validating the need for adaptive rollout gating.
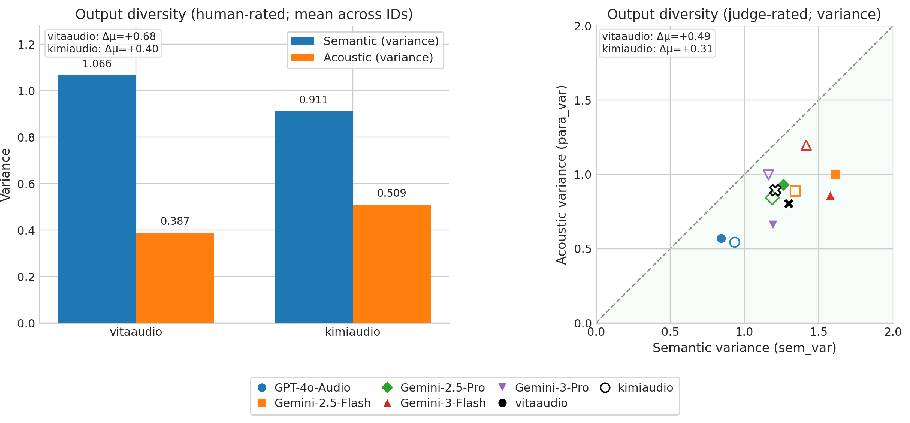
Figure 5: Semantic vs. acoustic diversity under repeated sampling, showing weaker acoustic discriminability.
Dynamic Hybrid Objective Design
Motivated by these findings, WavAlign proposes a modality-aware, single-stage adaptive hybrid post-training recipe. The core recipe:
- Applies PO (RL, DPO, or GRPO) exclusively to text tokens, shaping semantic dialogue behavior.
- Uses SFT as a distribution anchor for acoustic behavior, anchoring speech token outputs.
- Introduces a lightweight gating system to adaptively balance SFT and PO, based on rollout reliability and reward discriminability.
Dynamic weighting, smoothed by EMA, is implemented such that preference optimization is activated only when rollouts are directionally reliable and discriminative, mitigating noisy updates while preserving semantic refinement.
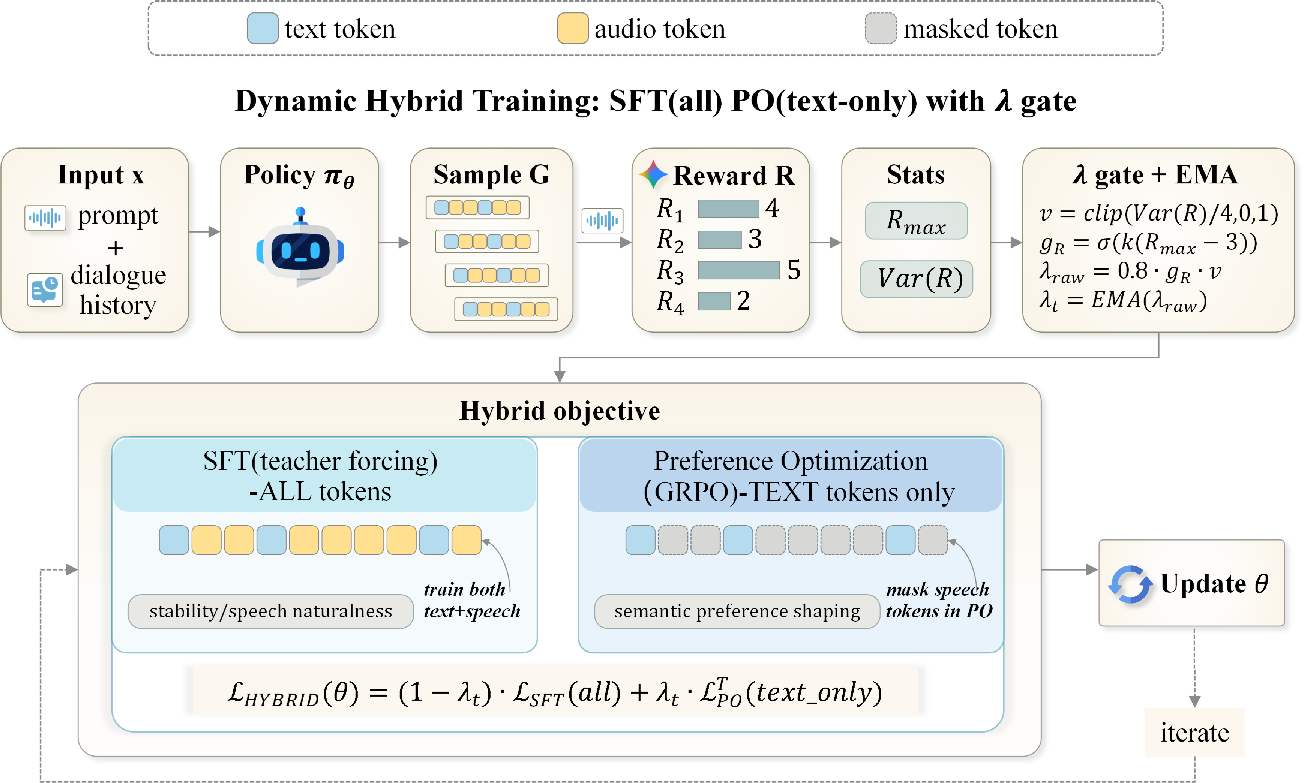
Figure 6: Overview of the proposed single-stage adaptive hybrid post training, with dynamic gating and modality-aware updates.
Experimental Evaluation
Benchmarks and Comparative Results
The methodology was evaluated across two representative architectures (VITA-Audio (Long et al., 6 May 2025), interleaved; KimiAudio (KimiTeam et al., 25 Apr 2025), parallel) and three comprehensive benchmarks: VoiceBench (Chen et al., 2024), OpenAudioBench, and VStyle (Zhan et al., 9 Sep 2025). Metrics jointly measure intelligence (IQ: reasoning, knowledge, safety) and expressiveness (EQ: paralinguistic attributes).
Key experimental results:
- IQ: WavAlign's dynamic hybrid post-training achieves the highest aggregate IQ scores, surpassing both SFT and full-token preference baselines by 2.0–5.2 points across benchmarks. Text-token restriction of preference optimization is essential; full-token PO fails to yield broad gains and often degrades speech quality.
- EQ: The dynamic hybrid objective yields a 0.2–0.6 average EQ improvement over SFT and baseline hybrids, particularly in role play and empathy dimensions, with catastrophic drift avoided.
- Pareto Efficiency: WavAlign uniquely achieves a favorable IQ–EQ trade-off, dominating both axes and avoiding the alignment tax observed in teacher-forced SFT alone.
Statistical human preference studies show approximately 4:1 win-to-loss ratios for WavAlign over baseline models in both helpfulness and naturalness axes, with p<0.001.
Ablation and Analysis
Ablation studies demonstrate:
- Optimization scope is critical: text-token-only preference gradients sharply outperform all-token variants in both IQ and EQ.
- Dynamic weighting outperforms fixed SFT/RL mixtures; EMA smoothing is necessary for training stability.
- Larger rollout group size (G) enhances IQ but saturates EQ gains.
- Dynamic λt rises as rollout quality improves, stabilizing in the [0.35,0.55] regime during convergence.
Theoretical and Practical Implications
The results validate a principled division of labor for mixed-modality post-training: semantic refinement via preference optimization and acoustic stability via dense supervision. The dynamic gating mechanism paves the way for more robust, scalable RL in complex multimodal generative settings. The adaptive hybrid method generalizes across architectures and benchmarks, providing a template for future developments in end-to-end spoken dialogue modeling, especially as reward modeling for acoustic attributes matures.
Practically, WavAlign enables consistently intelligent and expressive spoken dialogue agents, substantially advancing the state of the art and informing future RLHF/RLAIF protocols for multimodal models. Theoretically, it highlights the necessity of modality-aware update allocation and lays groundwork for more discriminative, token-level reward modeling.
Future Directions
- Improvements in acoustic reward modeling and token-level credit assignment will permit even finer-grained optimization, likely enhancing expressive speech further.
- Integration of PPO-based speech-token updates and advanced audio judges may address current limitations in acoustic supervision.
- Modality-aware post-training approaches are broadly applicable to other multimodal generative architectures, including vision–language and audio–visual dialogue domains.
Conclusion
WavAlign introduces an adaptive, modality-aware hybrid post-training framework for end-to-end spoken dialogue models, effectively harmonizing semantic intelligence and paralinguistic expressiveness. By systematically restricting preference optimization to semantic regions and anchoring speech tokens via dense supervision, the method overcomes longstanding issues in cross-modal RL, achieving superior IQ–EQ performance and robust acoustic stability across diverse architectures and benchmarks. This work establishes a rigorous blueprint for future multimodal post-training and optimization strategies.