- The paper introduces SA-SLM, which uses a Variational Information Bottleneck to distill smooth, expressive intent from raw semantic states.
- It integrates closed-loop, self-reward training to align generated speech with intended emotion, prosody, and naturalness.
- Empirical results show significant improvements in pitch variance and emotion alignment, outperforming larger baseline models.
Self-Aware Speech LLMs for Expressive Speech Generation
Introduction
The separation between semantic intent and acoustic realization in Speech LLMs (SLMs) fundamentally impedes expressive speech generation, resulting in outputs that are content-correct but prosodically flat and emotionally unconvincing. The "semantic understanding–acoustic realization gap" emerges from current SLMs' inability to explicitly transmit temporally coherent intent to the speech synthesis stack and their lack of realization-level self-supervision during training. The presented work addresses these limitations by proposing the Self-Aware Speech LLM (SA-SLM), which explicitly bridges what the model "thinks" (its internal semantics and intent) with how it "speaks" (its generated acoustic output), endowing the architecture with both intent and realization awareness.
Existing SLM Architectures and Limitations
Mainstream SLM architectures can be broadly categorized into modular multi-head and unified single-head frameworks. Modular designs employ a shared LLM backbone and specialized heads for text and speech, while unified architectures treat interleaved speech-text as a unique vocabulary and require extensive, tightly aligned corpora.
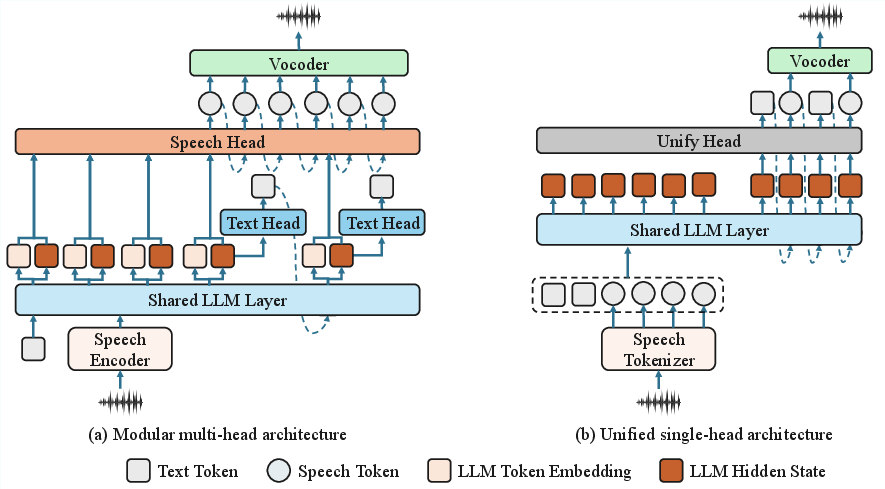
Figure 1: Contrasting current SLM architectures—(a) modular multi-head and (b) unified single-head—highlighting the architectural bottleneck in intent transmission for expressive speech.
Both paradigms fail to robustly communicate high-level, temporally stable expressive intent to the generative speech module. Instead, raw hidden states typically optimized for text next-token prediction are reused directly, leading to a dominance of token-aligned information in expressive control—a poor match for utterance-level expressiveness, prosody, and emotion. Additionally, open-loop training protocols merely align acoustic output with external labels or targets, completely bypassing self-verification of expressive realization fidelity.
SA-SLM: Unified Intent-Acoustic Alignment
SA-SLM addresses these compositional and training deficiencies with two interlocked innovations: (1) intent-aware bridging through a Variational Information Bottleneck (VIB) that distills temporally smooth expressive variables from LLM hidden states, and (2) realization-aware alignment achieved via closed-loop, rubric-based self-reward training where the model serves as its own critic.
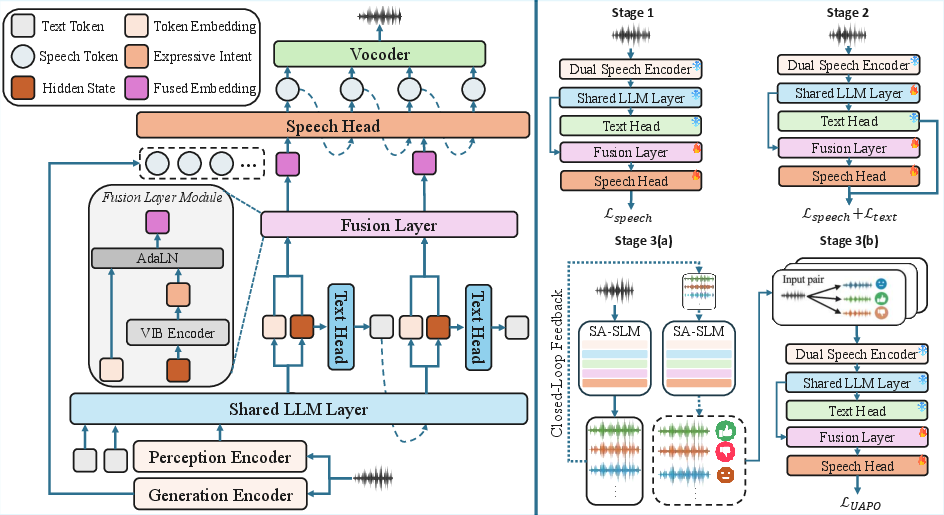
Figure 2: The SA-SLM framework: Left panel—VIB-based intent disentanglement; Right panel—realization-aware training with stages from acoustic bootstrapping to self-reward alignment.
Intent-Aware Bridging via VIB
SA-SLM integrates a VIB objective that compresses fast-varying LLM semantic states into a latent variable representing temporally smooth, expressive intent. This variable zyi modulates speech token embeddings via Adaptive LayerNorm, separating expressive control from token-level lexical content. Temporal smoothness is enforced through an Ornstein–Uhlenbeck prior within the bottleneck, favoring the preservation of utterance-level emotional and prosodic attributes while penalizing high-frequency, lexical-aligned features. Empirical representation analyses demonstrate that the VIB latent variable achieves substantially elevated emotion cluster separability over both token and raw hidden state representations (64.5% vs. 18.1% and 41.4%).
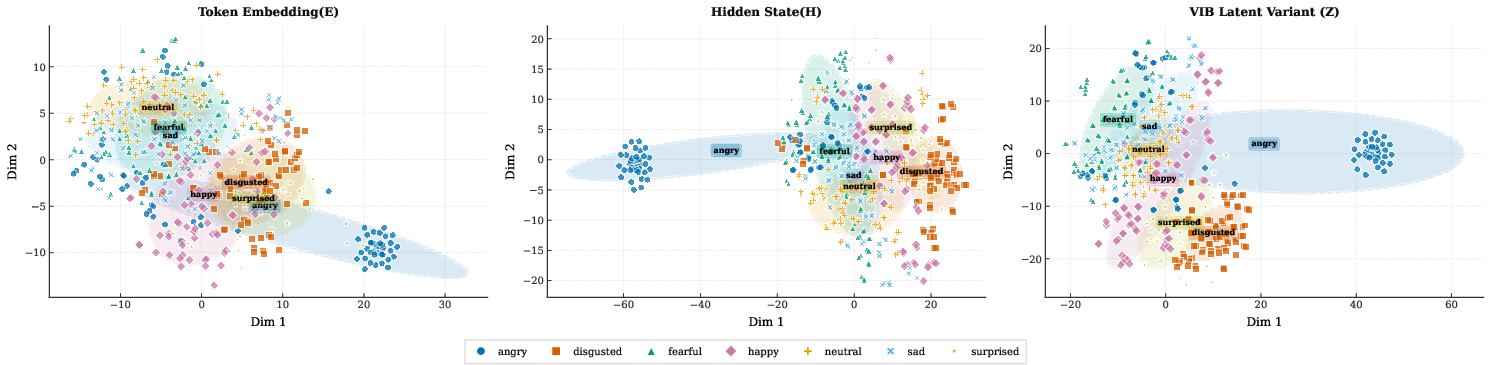
Figure 3: t-SNE emotion cluster visualization—VIB-derived latents enable superior emotion separation relative to token or LLM state representations.
Realization-Aware Alignment via Self-Reward
To ensure generated speech reflects the model's own intended expression—not just external targets—SA-SLM leverages a self-reward signal based on rubric-based, utterance-level scoring of emotion, prosody, and naturalness, with hard gating for intelligibility. In this closed-loop protocol, the model generates multiple candidate outputs, internally scores them relative to an anchor, and optimizes its policy via Utility-Anchored Preference Optimization (UAPO). Both self-derived (3B) and oracle (30B) reward critics are evaluated, demonstrating the broad applicability and scalability of the approach.
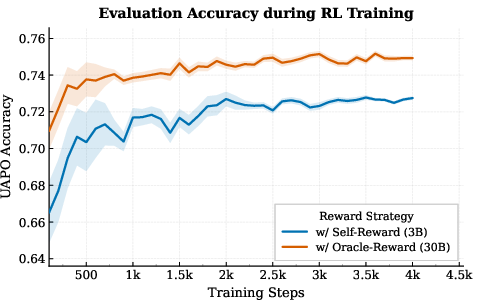
Figure 4: Self-reward alignment dynamics—UAPO with larger (oracle) reward models enables faster, more stable convergence and better expressive alignment.
Experimental Results
SA-SLM (3B parameters) is trained on 800 hours of expressive speech and systematically evaluated against SOTA open-source and closed models on the EchoMind benchmark, with both objective (e.g., WER, F0-Var, EmoAlign) and subjective (emotion, prosody, naturalness, overall) metrics. Notably, SA-SLM surpasses all industry SLM baselines—including Qwen3-Omni-30B (10× larger)—in expressive metrics, and approaches the closed-source GPT-4o-Audio within 0.08 points on overall subjective quality.
Key numerical results:
- F0-Var (pitch variance): SA-SLM 63.44 vs. Qwen3-Omni-30B 49.76, showing much richer pitch dynamics.
- EmoAlign (text-speech emotion alignment): 35.61% vs. Qwen3-Omni-30B 25.03% (10.58 point gain).
- Overall subjective quality: 4.33 vs. Qwen3-Omni-30B 4.25, and 0.08 below GPT-4o-Audio (4.41).
- Naturalness: SA-SLM 4.49 vs. CosyVoice2 (oracle emotion label) 4.34, indicating that end-to-end expressive modulation outperforms label-driven TTS in spontaneous quality.
Ablation studies confirm that both VIB-driven modulation and acoustic context grounding are necessary for optimal expressive and intelligible speech. Naive fusion of intent and content harms intelligibility, while removing acoustic context degrades both expressiveness and robustness.
Implications and Future Directions
SA-SLM demonstrates that dedicated, modular architectures with explicit cross-modal alignment protocols outperform naive model scaling for expressive generation, and achieve near-parity with massive, closed models at a fraction of the scale and data. The VIB-based bottleneck offers an extensible mechanism for intent disentanglement, while self-critique via closed-loop preference optimization provides scalable, domain-agnostic realization alignment.
Practically, this approach enables the construction of interactive spoken agents capable of robustly conveying nuanced emotions, prosody, and speaker intent with high subjective quality—important for domains such as empathetic dialogue, education, and entertainment. Theoretically, this architecture opens avenues for general cross-modal generative alignment and more interpretable, controllable models across expressive domains.
Future trajectories include scaling the reward critic for more robust self-improvement, extending the intent modulation to additional paralinguistic signals, and applying the closed-loop paradigm to multi-turn, real-time dialogue. Broader application to music, singing, and multimodal style transfer are also facilitated by the current framework.
Conclusion
The presented Self-Aware Speech LLM architecture establishes a formal pathway linking semantic intent with expressive acoustic realization via VIB-driven disentanglement and closed-loop self-reward. The resulting model yields state-of-the-art open-source expressiveness and approaches commercial systems in subjective and objective performance. The general methodology offers a scalable, foundational blueprint for intent-aligned, high-fidelity generative speech modeling and broader cross-modal expressive generation.