Hierarchical Policies from Verbal and Egocentric Human Signals for Natural Human-Robot Interaction
Abstract: For natural human-robot interaction, a robot must understand human intent expressed not only through language but also through nonverbal signals such as gestures and gaze. However, current robot policies rely on language instructions as the sole interface for conveying intent, leaving nonverbal signals unused and placing the full burden of communication. In this work, we present EDITH, a robot framework that captures the human's nonverbal signals through continuous streams of first-person view and gaze from smart glasses, and uses them alongside language instructions as inputs to the robot policy. Our hardware system streams the human's first-person view, gaze, and speech to the robot in real time, transcribing the speech into language instructions. To handle these rich but noisy signals, we design a hierarchical policy in which a high-level policy infers the human's intent and produces a sequence of subtasks, where each subtask is represented as a fine-grained instruction paired with a keyframe that grounds the intent in the scene (e.g., the frame where the human points at the target object). A low-level policy then executes these subtasks. In our experiments on human-robot interactive tasks, EDITH enables the robot to act on the human's nonverbal signals even when intent is expressed only briefly, and significantly reduces user effort to convey intent compared to using language instructions alone. Visit our project page for source code and real-robot demo videos.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to understand people the way we naturally communicate: not just with words, but also with nonverbal signals like where we look and what we point at. The authors built a system called EDITH that lets a robot watch a person’s first-person video from smart glasses, track their eye gaze, listen to their speech, and then use all of that together to figure out what the person wants and do it.
What questions did the researchers ask?
They focused on three simple questions:
- Can a robot understand what a person wants if the person uses short phrases plus quick nonverbal hints (like a glance or a point), instead of long, detailed instructions?
- Can combining nonverbal signals with words make robot interactions feel more natural and less tiring for the person?
- What kind of robot “brain” works best for this—especially when the nonverbal signals are brief or noisy?
How did they do it? (Methods explained simply)
Think of the robot’s control as a team with two roles:
- A high-level planner (like a coach) that understands what the human wants and breaks it into a to-do list of small steps.
- A low-level controller (like a player) that carries out each small step with precise movements.
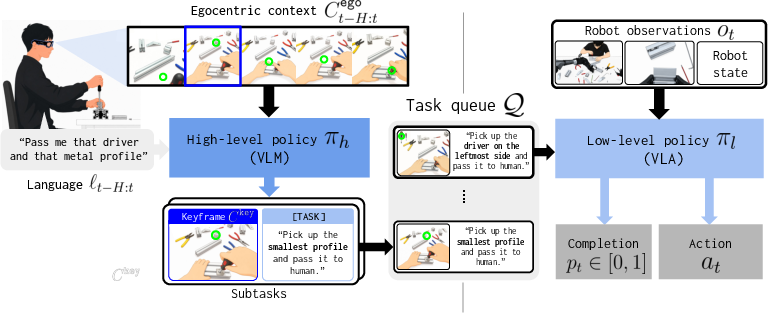
Here’s how EDITH works in everyday terms:
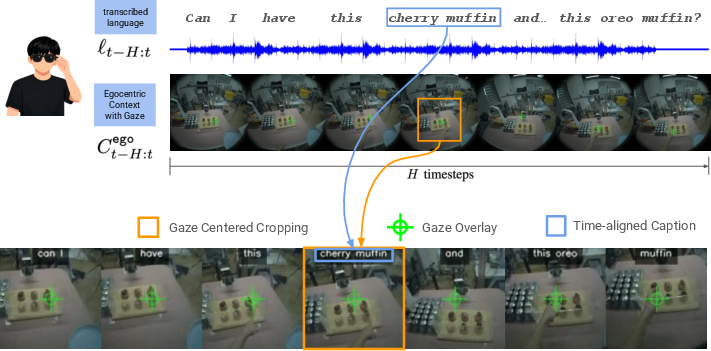
- Smart glasses stream three things to the robot in real time: 1) first-person video (what the person sees), 2) eye gaze (where the person is looking in the video), 3) speech (what the person says, turned into text).
- The high-level planner watches short clips of the recent first-person video with gaze dots and subtitles. It then makes a to-do list. Each to-do item has:
- A clear mini-instruction, like “Pick up the driver with the red handle and hand it to the human.”
- A keyframe: a single snapshot from the video when the human’s nonverbal cue is clearest (for example, the moment they look at or point to the right tool). This grounds the instruction in the exact scene.
- The to-do items go into a queue. While the low-level controller executes the current item, the high-level planner keeps listening and watching for new requests and adds them to the queue if needed. That means the robot can keep up even if the person changes their mind or adds more tasks.
- Training the robot:
- The team recorded demonstrations where a human asked for things with speech and quick nonverbal cues while a teleoperator controlled the robot to do the right actions.
- They split these recordings into small steps, wrote down the mini-instruction for each step, picked the keyframe that best showed the human’s intent, and marked when each step was complete.
- They trained the low-level controller to use both the mini-instruction and the keyframe. To make sure it didn’t ignore either one, they sometimes hid the text or the image during training (“modality dropout”), forcing it to learn to rely on both.
Key terms in plain language:
- First-person view: video from the person’s point of view (what their eyes see).
- Gaze: the exact spot in the video where the person is looking.
- Keyframe: one important snapshot that shows the human’s intent (like the instant you point at “that muffin”).
- High-level vs. low-level policy: planner (makes the to-do list) vs. executor (moves the robot to do it).
What did they test, and what did they find?
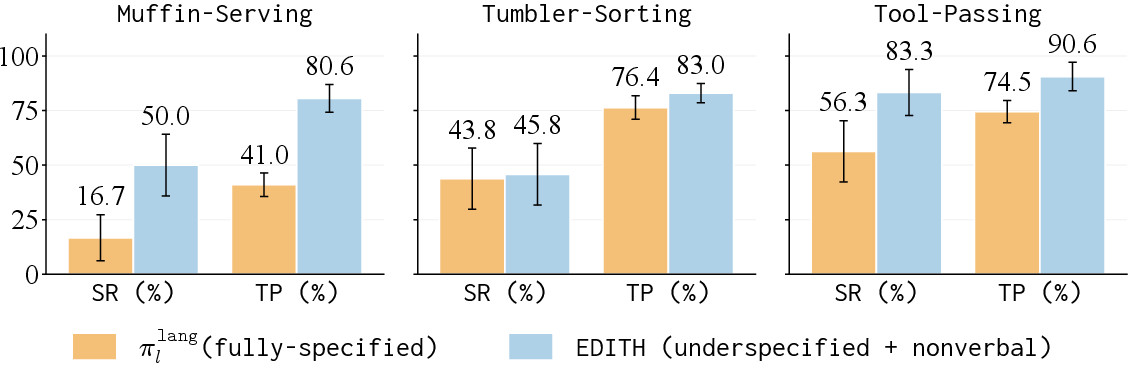
They tried EDITH on three hands-on tasks where words alone are vague, but quick looks or points make the target obvious:
- Muffin-Serving: The human says something like “Give me this muffin, this muffin, and this muffin” while pointing to three different muffins on a crowded display.
- Tumbler-Sorting: The human points to certain tumblers and certain baskets and says where each tumbler should go.
- Tool-Passing: The human is building something and briefly looks at or gestures toward a specific tool or part while saying “Pass me that.”
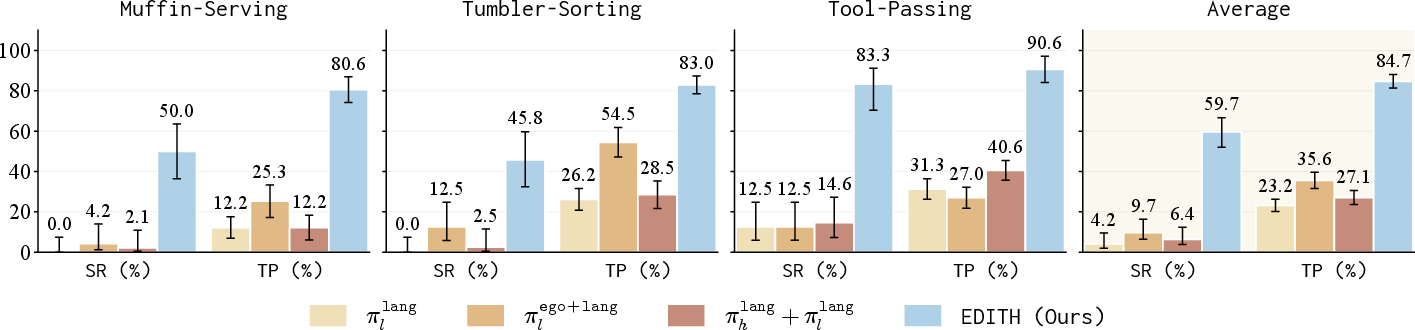
Main results:
- EDITH succeeded much more often than methods that only used language or that tried to stuff all signals directly into a single controller. On average, EDITH succeeded about 60% of the time, while language-only baselines were under about 6.5%.
- A user study with 16 people showed that EDITH made it much easier and less tiring to tell the robot what to do. People didn’t have to spell out every detail; they could just look or point and say a short phrase. The drop in user workload was statistically significant.
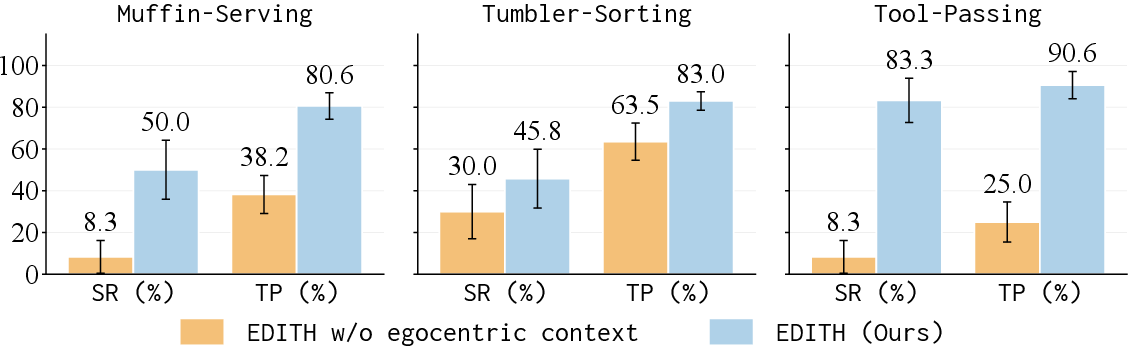
- A key reason EDITH worked well was the keyframe. Without it, performance dropped a lot. The keyframe reduces confusion because it shows the robot exactly what the human meant at the precise moment of the cue.
- EDITH handled distractions better. If a person briefly looked at something unrelated (like a phone), the high-level planner still picked out the right moments when the person actually expressed intent.
Why this matters:
- People rarely give perfect, complete instructions. In real life, we mix quick words with glances and gestures. EDITH lets robots understand that natural style.
Why does this matter, and what’s next?
Implications:
- More natural teamwork with robots: You can interact with a robot the way you would with a person—short phrases plus pointing or looking—rather than long, detailed descriptions.
- Less effort for users: This can help in kitchens, workshops, hospitals, and homes, where your hands are busy and you don’t have time to over-explain.
Future improvements the authors mention:
- Make the high-level planner even more responsive by processing streaming video/audio with lower delay.
- Train with a more diverse set of users so the system works well across different heights, body motions, and gesture styles.
In short, EDITH shows that combining what we say with how we look and gesture helps robots catch on to what we mean—faster, more accurately, and in a way that feels natural.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each point is phrased to be directly actionable for future research.
- Streaming intent inference: How to replace windowed, batch VLM processing with truly streaming, low-latency multimodal intent inference (continuous video, gaze, and speech), including quantified end-to-end latency budgets and trade-offs between accuracy and responsiveness.
- Generalization across users: How to robustly adapt to users with diverse physical attributes (height, arm length, gesturing styles, gaze behavior, eyewear) without per-user calibration; what scale and diversity of training users/environments are sufficient for stable generalization.
- Gaze calibration and drift: How sensitive performance is to gaze-tracker calibration errors, drift over time, and occlusions; need for online self-calibration or confidence-aware use of gaze.
- Multilingual and noisy speech: Robustness to ASR errors, code-switching, heavy accents, background speech/crosstalk, and non-English languages; evaluation with multilingual corpora and speech-in-the-wild conditions.
- Privacy and ethics: How to ensure privacy-preserving processing of egocentric video, gaze, and audio (on-device processing, redaction, encryption); user consent and bystander privacy in real deployments.
- Closed-model dependence: Reproducibility and robustness when replacing the proprietary VLM (Gemini-3.1-Flash-Lite) with open models; quantifying performance gaps and outlining techniques (distillation, constrained decoding, retrieval augmentation) to mitigate VLM hallucinations.
- Keyframe robustness: Failure modes when the VLM selects suboptimal/ambiguous keyframes (e.g., weak or transient nonverbal cues); learning a dedicated, trainable keyframe retriever versus prompting a VLM; incorporating uncertainty/confidence scoring for keyframes.
- Alternative subtask representations: Whether subtask grounding works better with masks, 2D/3D regions, object IDs/tracks, language-referred detections, or 3D keypoints instead of a single RGB keyframe.
- Ambiguity resolution: Mechanisms for active disambiguation (clarification questions, confirmatory gestures, highlighting via AR) when nonverbal signals or language are underspecified or conflicting.
- Dynamic intent changes: Policies for handling mid-execution intent switches, cancelling or reordering queued subtasks, and reconciling stale subtasks with updated user goals.
- Multi-user settings: Disambiguation when multiple humans are present, including attribution of gaze/gestures to the active interlocutor and handling conflicting requests.
- Distraction and irrelevant cues: Beyond the phone-check scenario, robustness to dense, dynamic scenes, moving bystanders, and non-task-related gestures/gaze; systematic stress-testing with varied distractors.
- Unreliable/missing modalities: Graceful degradation when gaze is unavailable, speech drops, or egocentric video is occluded; formal ablations quantifying performance with modality outages and noisy sensors.
- Temporal grounding beyond keyframes: Whether using short intent snippets (temporal segments) or recurrent memory improves grounding compared to a single keyframe, especially for rapidly evolving gestures.
- Queueing and concurrency: Formal analysis of the asynchronous high/low-level interaction, including race conditions, queue overflow, starvation, and recovery strategies after subtask failures.
- Completion detection: How completion probability thresholds are chosen; impact of threshold miscalibration; learning more robust, state-aware termination conditions that reduce premature or delayed transitions.
- Safety and risk: Safety analysis for misinterpretations (e.g., wrong object handed over) and unsafe motions; adding safety monitors, intent confirmation checkpoints, and fail-safe policies.
- Long-horizon tasks: Scaling from short pick-and-place subtasks to lengthy, interdependent activities requiring memory, resource management, and temporal constraints; evaluating cumulative error and recovery.
- Richer manipulation: Extending from parallel-jaw grasping to bimanual coordination, deformables, tools, and contact-rich tasks; how keyframe grounding supports fine manipulation planning.
- Environment generalization: Performance in novel physical layouts, lighting, clutter, and unseen object categories; domain adaptation methods and data augmentation strategies for egocentric streams.
- Hardware variability: Portability to other glasses (different camera/gaze specs), robot embodiments, sensors (IMU, depth on glasses), and mobile platforms; quantifying cross-hardware transfer.
- Data scale and labeling cost: The dataset is relatively small and requires manual segmentation, keyframe selection, and completion labels; need for weak/auto-labeling, self-supervision, or synthetic data to scale.
- Evaluation breadth: Metrics focus on success rate and task progress; missing measures of interaction fluency, time-to-completion, correction burden, safety incidents, and trust—particularly important for HRI.
- User study scope: The user study is limited in size, task diversity, and baselines; open questions on ecological validity in real workplaces, learning effects across sessions, and diverse user populations.
- Alternative planners: Comparison with non-VLM planners (e.g., temporal grounding networks, explicit gesture/gaze estimators, tracking-by-detection) to understand what aspects of planning truly require internet-scale VLM priors.
- Uncertainty modeling: Explicit intent uncertainty estimates (from VLM and gaze) and their propagation through the hierarchy to drive conservative actions or solicit clarification when confidence is low.
- On-device versus cloud compute: Feasibility of running the high-level model on-device for privacy/latency; profiling and system design for real-time guarantees under network variability.
- Integration with perception stacks: Leveraging third-person robot cameras for joint user-target tracking, 3D scene graphs, and cross-view grounding with the egocentric stream for more reliable disambiguation.
- Continual personalization: Methods to adapt online to a specific user’s gaze/gesture idiosyncrasies, with safeguards against catastrophic drift or privacy violations.
Practical Applications
Practical Applications Derived from the Paper
Below are concrete, real-world applications that leverage the paper’s findings, methods, and system innovations (smart glasses streams of first-person view and gaze; hierarchical VLM–VLA policy with keyframe-grounded subtasks; asynchronous intent queue; modality-dropout training). Each item notes sectors, potential tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be piloted now in controlled settings with human oversight and standard cobot safety protocols.
- Cobotic “say-and-point” assistant for tool/part delivery in light manufacturing and assembly
- Sector: Manufacturing, robotics
- What it looks like: Operators wearing smart glasses glance/point at parts/tools while issuing brief utterances; EDITH’s high-level policy detects intents and queues keyframe-grounded subtasks; a cobot fetches and hands over items.
- Tools/products/workflows: ROS 2 package for “intent-to-queue” with keyframe overlays; workstation UI showing queued subtasks and completion probabilities; skill library for pick–handover–place; integration with UR/Franka cells.
- Assumptions/dependencies: Reliable gaze tracking and calibration; low-latency network to robot; well-structured workcell with known SKUs and grasp points; ISO/TS 15066 risk assessment; staff consent for egocentric audio/video.
- Counter service “point-and-serve” robot (e.g., pastry/muffin plating)
- Sector: Food service, hospitality, retail
- What it looks like: Staff briefly points and says “these three” while EDITH disambiguates targets using gaze/point keyframes; robot plates items for pickup.
- Tools/products/workflows: POS integration to record served items; food-safe grippers and sanitation workflows; keyframe visualization for double-check by staff.
- Assumptions/dependencies: Uniform placement and reachable items; food safety compliance; success-rate limits (≈60% in reported tasks) imply staff-in-the-loop supervision.
- Kitting and line-side replenishment by “look-and-name” intent
- Sector: Warehousing, intralogistics
- What it looks like: Picker glances at bins while stating the order; EDITH queues picks to a nearby manipulator or AMR-mounted arm for tote kitting.
- Tools/products/workflows: WMS plugin mapping keyframes to bin/SKU; exception-handling UI for misdetections; skill library for bin picking.
- Assumptions/dependencies: Clear bin labeling; stable lighting and camera coverage; network reliability; safety geofencing around humans.
- Shared autonomy teleoperation with keyframe-grounded task handoffs
- Sector: Remote operations, field robotics
- What it looks like: A remote operator’s egocentric feed and gaze generate keyframes that seed autonomous subtasks (e.g., “grasp that valve”); autonomy executes until completion probability threshold, then returns control.
- Tools/products/workflows: Teleop overlay that shows detected intents and confidence; adjustable completion threshold; logging for post-hoc review.
- Assumptions/dependencies: Adequate bandwidth; low-latency perception; fallback teleop when intent is ambiguous.
- Quality inspection assist: gaze-to-ROI guidance for robotic cameras/tools
- Sector: Manufacturing QA/QC
- What it looks like: Inspector’s brief gaze fixations generate keyframes; robot repositions cameras or markers to suspected defect regions.
- Tools/products/workflows: “Gaze-to-ROI” module; auto-capture routines; traceability linking ROIs to part IDs.
- Assumptions/dependencies: Privacy-preserving handling of gaze; repeatable positioning and part fixturing.
- Research and education platform for multimodal HRI and VLA training
- Sector: Academia, education, developer tooling
- What it looks like: Use the open code/demos to study nonverbal intent grounding, user workload, and hierarchical control; replicate the annotation pipeline (subtask segmentation, keyframe labeling, completion probabilities).
- Tools/products/workflows: Dataset curation tools; modality-dropout training recipe; ablation harness for keyframe vs. language-only policies.
- Assumptions/dependencies: Access to smart glasses (or equivalent), GPUs, and a modest manipulator.
- Policy and compliance starter kit for gaze/audio capture in workplaces
- Sector: Policy, compliance, organizational governance
- What it looks like: Practical templates for consent notices, data minimization, retention schedules, and role-based access for egocentric streams used in HRI pilots.
- Tools/products/workflows: Privacy Impact Assessment (PIA) checklist; data taxonomy and redaction scripts (e.g., on-device ASR, face blurring in stored video); signage and worker briefing materials.
- Assumptions/dependencies: Alignment with GDPR/CCPA and local labor agreements; IT/security review; opt-in procedures.
Long-Term Applications
These require further research, robustness, standardization, or regulatory clearance (e.g., streaming VLMs with low latency, generalization to diverse users/environments, higher reliability).
- Sterile instrument handover in operating rooms via glance-and-ask
- Sector: Healthcare (surgery), medical robotics
- What it looks like: Surgeons convey brief verbal requests with gaze/gesture; robot hands instruments with sub-second responsiveness and near-perfect reliability.
- Tools/products/workflows: IEC/FDA-cleared streaming VLM on edge hardware; sterile-safe grippers; audit logs of intents and handovers.
- Assumptions/dependencies: Regulatory approval; rigorous safety certification; highly robust gaze tracking through PPE; failure handling with scrub nurse override.
- In-home assistance for eldercare and daily living
- Sector: Healthcare, consumer robotics, accessibility
- What it looks like: Residents use minimal speech plus pointing/gaze to request fetch-and-carry, tidying, and handovers across rooms.
- Tools/products/workflows: Mobile manipulation with whole-home mapping; “intent broker” that aligns egocentric keyframes to home inventory; safety and privacy sandboxes (local processing).
- Assumptions/dependencies: Affordable mobile manipulators; strong generalization to cluttered, changing homes and diverse users; on-device models to avoid cloud streaming of private spaces.
- Construction and field service aides for tools/materials
- Sector: Construction, utilities, field robotics
- What it looks like: Workers glance at distant or occluded tools/components; robot retrieves, stages, or holds parts during assembly.
- Tools/products/workflows: Ruggedized vision and gaze capture; skill libraries for irregular objects; multi-modal disambiguation with third-person cameras.
- Assumptions/dependencies: Outdoor lighting, dust, PPE; localization in large, dynamic sites; robust grasp planning for novel shapes.
- Multi-robot “intent broker” that schedules human-requested subtasks across fleets
- Sector: Robotics, manufacturing, logistics
- What it looks like: The high-level policy’s task queue is extended to allocate human-originated subtasks to whichever robot has the right capability and proximity, balancing loads and deadlines.
- Tools/products/workflows: Fleet manager that consumes keyframe-grounded subtasks; skill catalog with capability tags; SLA-aware scheduling.
- Assumptions/dependencies: Standardized subtask schemas; inter-robot coordination; safety certification for concurrent HRC.
- Glasses-free nonverbal intent via exocentric perception
- Sector: HRI, retail, public spaces
- What it looks like: External cameras estimate gaze/pointing to enable customer “point-and-get” interactions (no wearable required).
- Tools/products/workflows: Multi-camera 3D pose and gaze estimation; identity-agnostic intent detection; on-site edge compute.
- Assumptions/dependencies: Accurate third-person gaze estimation in crowds; privacy-by-design and signage; fairness across body types and abilities.
- Streaming, on-device VLMs for sub-200 ms intent recognition
- Sector: Software, edge AI hardware
- What it looks like: VLMs process live egocentric video/audio on glasses or nearby edge boxes to cut latency and reduce data exposure.
- Tools/products/workflows: Hardware acceleration (NPUs) on wearables; model distillation/quantization; continual learning for user-specific adaptation.
- Assumptions/dependencies: Battery and thermals on wearables; efficient video-language architectures; drift detection and recalibration.
- Standards and governance for egocentric HRI data
- Sector: Policy, standards bodies (ISO/IEC/IEEE)
- What it looks like: Open schemas for intent/keyframe records, safety test protocols for nonverbal HRI, and privacy standards for gaze/audio retention and access.
- Tools/products/workflows: Conformance test suites; procurement checklists; third-party audits.
- Assumptions/dependencies: Multi-stakeholder consensus; alignment with labor and accessibility regulations; harmonization across regions.
- Workforce training and micro-credentials in multimodal robot commanding
- Sector: Workforce development, education
- What it looks like: Curricula that teach “speak-and-point” tasking, safety, and exception handling with hierarchical policies.
- Tools/products/workflows: Simulator-in-the-loop practice; standardized assessment; badges recognized by employers.
- Assumptions/dependencies: Adoption by technical colleges and OEMs; simulator fidelity; updates as models evolve.
- Process analytics from aggregated, privacy-preserving intent data
- Sector: Industrial engineering, operations
- What it looks like: Aggregate (de-identified) intent and task-queue logs reveal bottlenecks and layout issues; robots/teams are reconfigured accordingly.
- Tools/products/workflows: Differentially private analytics pipeline; dashboarding; A/B testing of workstation changes.
- Assumptions/dependencies: Strong anonymization; worker council/IRB oversight; clear purpose limitation policies.
Glossary
- binary cross-entropy loss: A standard loss function for binary classification that measures the difference between predicted probabilities and true labels. "We also train a linear head on the frozen VLA backbone to predict with a binary cross-entropy loss."
- closed loop: A control setup where the system continuously uses feedback from observations to update actions. "a language-conditioned policy predicts an action , executes it on the robot, and receives the next observation in a closed loop."
- completion probability: The model’s estimated likelihood that the current subtask has been finished. "Given the subtask at the head of and the robot observation , produces a low-level robot action together with a completion probability :"
- deictic gestures: Pointing or indicating gestures that reference objects relative to the speaker’s context. "nonverbal cues such as deictic gestures, gaze, hand pose, and body motion"
- egocentric context: The first-person sensory stream (images and gaze) capturing what the human sees and attends to. "We hereafter denote the first-person view image and gaze coordinates at timestep as the egocentric context ."
- fine-grained instruction: A detailed, low-level textual command specifying an atomic robot action. "each is a fine-grained language instruction specifying the -th subtask"
- flow-matching action head: An action prediction module trained via flow-matching to generate control commands. "We instantiate as a VLA model with a flow-matching action head~\citep{pi0.5}, and train it with the flow-matching objective~\citep{pi0} by feeding as a first-person image with the gaze marker overlaid."
- flow-matching objective: A training objective that matches probability flows to learn action generation. "and train it with the flow-matching objective~\citep{pi0} by feeding as a first-person image with the gaze marker overlaid."
- hierarchical policy: A control architecture that separates high-level intent inference from low-level action execution. "We therefore design a hierarchical policy that decouples the problem of inferring human intent from producing low-level actions."
- high-level policy: The planning component that infers user intent and decomposes tasks into subtasks. "The hierarchical policy consists of a high-level policy and a low-level policy ."
- keyframe: A specific frame selected from the egocentric stream that visually grounds a user’s intent. "each subtask is represented as a fine-grained instruction paired with a keyframe that grounds the intent in the scene"
- language-conditioned policy: A policy that conditions action selection on both observations and language inputs. "a language-conditioned policy predicts an action "
- low-level policy: The controller that executes subtasks by producing concrete robot actions. "The low-level policy sequentially executes each subtask in at the robot control frequency."
- modality dropout: A training strategy that randomly removes or weakens input modalities to encourage multi-modal reliance. "we introduce modality dropout (Figure~\ref{fig:modality_dropout})."
- NASA-TLX: A standardized workload assessment tool commonly used to measure user task load across several dimensions. "Four NASA-TLX~\citep{hart1988development} items (mental demand, performance, effort, frustration), on a 7-point Likert scale."
- proprioceptive state: The robot’s internal sensing of its own configuration (e.g., joint positions/velocities). "(e.g., RGB images from cameras and the robot's proprioceptive state)"
- subgoal image: An image representation of a desired intermediate state used as a subtask goal. "or a subgoal image~\citep{pi0.7, hamster, susie}."
- subtask: A smaller, atomic unit of work within a larger task, produced by the high-level policy for execution. "Each subtask is represented as a pair of a fine-grained instruction and a keyframe retrieved from the input stream"
- success rate (SR): The fraction of trials in which all required subtasks are completed. "we evaluate using two metrics: success rate (SR) and task progress (TP)."
- System 1 / System 2: A cognitive framework distinguishing fast, intuitive processes (System 1) from slow, deliberative ones (System 2), used here as an analogy for hierarchical control. "Analogous to the System~1 / System~2 view of human cognition~\citep{kahneman2011thinking}, decomposes a complex task into an atomic subtask "
- task progress (TP): The average fraction of subtasks completed per trial. "we evaluate using two metrics: success rate (SR) and task progress (TP)."
- task queue: A first-in-first-out buffer that stores inferred subtasks for sequential execution. "connecting them through a task queue : appends newly identified subtasks to , while pops and executes the subtask at its head."
- teleoperator: A human who remotely controls a robot to perform actions or collect demonstrations. "Each episode involves two participants: a human actor and a robot teleoperator."
- Vision-Language-Action (VLA) model: A model that maps visual inputs and language instructions to robot actions. "We implement by fine-tuning a pre-trained VLA model (e.g., ~\citep{pi0.5}) on our dataset"
- Vision-LLM (VLM): A multimodal model that jointly processes visual and textual inputs for perception and reasoning. "We implement with a VLM (e.g., Gemini-3.1-flash-lite~\citep{gemini3.1flashlite}), leveraging its world knowledge to infer human intent from multimodal context"
- VLM planner: A planning module based on a Vision-LLM that proposes subtask sequences. "and even a hierarchical policy augmented with a VLM planner based on Gemini-3.1-Flash-Lite~\citep{gemini3.1flashlite}"
- Whisper API: An automatic speech recognition interface used to obtain word-level timestamps for transcribed speech. "We obtain word-level timestamps for the captions using the Whisper API~\citep{radford2023robust}."
- window-based processing: Handling streams in fixed-size temporal windows, which can introduce latency. "its reactivity is limited by the high-level policy's latency from window-based processing of the egocentric stream."
Collections
Sign up for free to add this paper to one or more collections.