- The paper presents a dual-framework approach combining simulation and user studies to causally evaluate human personality traits and AI attributes.
- It finds that while personality dominates in simulations, AI transparency exerts a stronger impact on user outcomes in real-world studies.
- Results highlight that calibrated transparency is critical, as its effects on negotiation success and trust vary by context.
Imperfectly Cooperative Human-AI Interactions: A Causal Analysis of Human and AI Attributes in Simulation and User Studies
Introduction
The proliferation of human-AI interaction research has yielded robust insights concerning fully cooperative settings, yet the dynamics of imperfectly cooperative human-AI scenarios remain comparatively underexplored. The paper "Imperfectly Cooperative Human-AI Interactions: Comparing the Impacts of Human and AI Attributes in Simulated and User Studies" (2604.15607) provides an authoritative experimental and analytical framework for dissecting the relative influences of human personality traits and AI agent attributes in such settings. This work employs parallel, large-scale simulation and user studies to quantify how manipulations of user Extraversion/Agreeableness and AI characteristics (Transparency, Warmth, Expertise, Adaptability, Theory of Mind) impact negotiation and deception-oriented tasks.
Experimental Design and Methodology
The core methodological innovation lies in the dual-framework paradigm: extensive controlled simulations using Sotopia-S4—enabling joint manipulation of both user traits and AI attributes—are complemented by a Prolific user study in which human participants interact with identically parameterized AI agents.
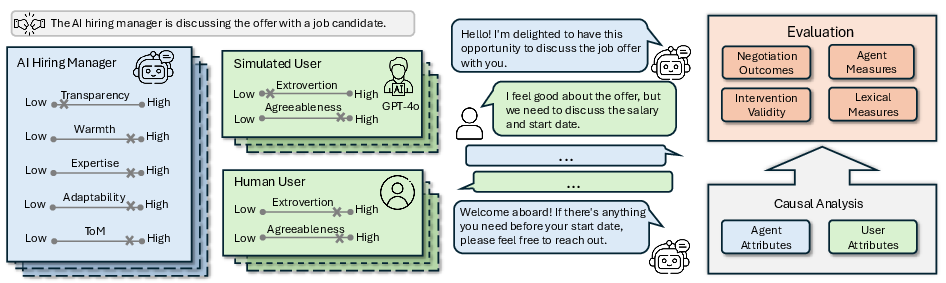
Figure 1: Dual-framework study design for evaluating imperfectly cooperative human-AI interactions. Controlled simulation (LLM agents and persona-matched users) complements human user studies with matched AI configurations.
The simulation study utilizes a 5 × 5 × 4 factorial design, crossing five scenario types (high/low-stakes job negotiation, three AI-LieDar deception scenarios), five AI interventions, and four user personality archetypes (combinations of high/low Extraversion and Agreeableness). User studies retain all but the personality manipulation, collecting these as quasi-experimental covariates. Each scenario endpoint and dialogue is subjected to multi-dimensional evaluation using Sotopia-Eval for LLM-based metrics, survey-based subjective measures, and lexical analyses targeting socio-emotional-cognitive content.
Causal inference is conducted via structural equation modeling (SEM), enabling rigorous quantification of effect sizes and directionalities for each trait/intervention relative to scenario-level and relational outcomes.
Results: Divergences and Convergences Between Simulation and Human Data
Impact of Personality vs. AI Attributes
A key finding is the context-dependent inversion of effect dominance:
Scenario-Specific Findings
Nuanced Effects and Causal Trade-offs
The negative user response to increased AI Transparency, especially in high-stakes/competitive settings, suggests that transparency is not unconditionally beneficial—it can improve some communication/process metrics while simultaneously signaling strategic intent and undermining perceived honesty and outcome satisfaction. This transparency trade-off is consistent across both negotiation and deception contexts.
Implications and Theoretical Integration
Practical Implications for Human-Centered Agent Design
The findings establish that:
- Grounding agent evaluation in pure simulation is insufficient for high-stakes, imperfectly aligned scenarios; human-in-the-loop validation remains essential.
- Personality-based manipulations and evaluations in LLMs, while directionally plausible, lack the intensity and socio-emotional nuance observed in real human-AI interactions (cf. [Duan et al., 2025]; [Petrov et al., 2024]).
- Transparency must be parameterized—optimizing for continual maximization may degrade human trust and satisfaction when agent and user goals diverge.
- Objective algorithmic evaluation (LLM-as-judge) is not a reliable proxy for user experience: alignment is scenario-specific and limited.
Theoretical Insights and Relation to Contemporary Work
This work contributes to expanding trust and human-AI teaming theory from fully cooperative to imperfectly cooperative settings, echoing calls for richer, multidimensional trust models that include moral, relational, and dispositional axes ([Malle & Ullman, 2021]; [Nguyen et al., 2025]; [Wildman et al., 2024]). It also substantiates the premise that human-AI interaction dynamics—and the effectiveness of design interventions—are irreducible to main-effect models and demand careful scenario/context-dependent causal analysis ([Vaccaro et al., 2024]).
The simulation-user divergence parallels limitations in the current use of LLM-generated digital twins for simulating human populations ([Argyle et al., 2023]; [Li et al., 2025]; [Cui et al., 2023]). Results caution against deploying LLM-based simulations or evaluators for deployment-sensitive domains (e.g., hiring, negotiation, deception) without rigorous parallel benchmarking against human-in-the-loop ground truth.
Directions for Future Research
Advancing the design and evaluation of AI agents for operational settings featuring complex, competitive cooperation (e.g., hiring, bargaining, customer service) will require:
- Richer, scenario-specific transparency and adaptability controls capable of dynamic calibration to context and stakeholder sensitivity.
- Continuous development and validation of LLM-based persona and simulation frameworks, with systematic ground-truthing against human behavioral data (cf. [Zhou et al., 2025]; [Park et al., 2024]).
- Integration of multi-modal behavioral signals—beyond verbal responses—into trust/reputation/adaptivity modeling pipelines.
Conclusion
This study demonstrates that the relative causal strength of human personality traits and AI design characteristics in imperfectly cooperative human-AI interactions is highly scenario-dependent and modulated by the nature of the evaluation (simulation vs. human users). Objective and subjective measures frequently diverge, particularly regarding the impact of transparency and trust-related outcomes. These results underscore the need for calibrated transparency strategies and rigorous human-in-the-loop evaluation regimes when developing trustworthy agentic AI for complex socio-technical settings.
Figure 1: Dual-framework study design for evaluating imperfectly cooperative human-AI interactions with simulation and user studies.
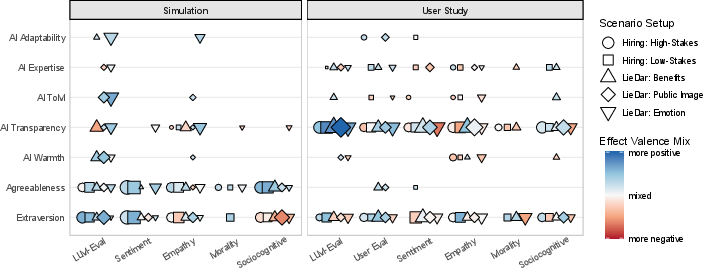
Figure 2: Significant causal effect strengths, per intervention and outcome group.
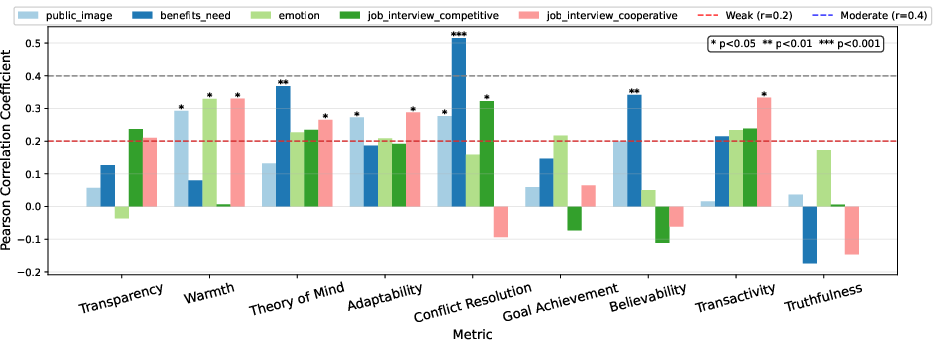
Figure 3: Normalized Pearson correlations between LLM-based and user study evaluation metrics.