Unifying Object-Centric World Models and Diffusion Policy: A Hierarchical Framework for Multi-Stage Robotic Tasks
Abstract: Visual world models have shown great potential in learning complex system dynamics. Recent advancements leverage these models as transition functions within Model Predictive Control (MPC) frameworks to solve various control tasks. When applied to robotics, however, they are limited to single-stage tasks such as reaching or grasping, and struggle with multi-stage ones that demand complex sequential planning. In this work, we introduce WorldDP, a world model framework designed for multi-stage robotic manipulation. Our hierarchical approach utilizes a high-level world model as a transition function to optimize for feasible subgoals during runtime, which are subsequently reached by a low-level Diffusion Policy. To further aid in learning dynamics and planning, we incorporate object-centric representations that decouple environmental entities and enable us to plan sequentially with respect to each. Evaluated across several robotics benchmarks, WorldDP consistently outperforms existing baselines, validating that coupling the world model's physically grounded planning with diffusion policy's efficient execution yields superior multi-stage performance.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching robots to handle multi-step jobs, like “press a button to unlock a drawer, then open the drawer, then move an object.” The authors introduce a system called WorldDP that combines two ideas:
- a “world model” that thinks ahead to plan the big steps (subgoals), and
- a “diffusion policy” that actually carries out each small step smoothly.
By working together, these two parts help robots succeed at longer, more complicated tasks than before.
What questions did the researchers ask?
They focus on simple, practical questions:
- How can a robot plan several steps in the right order to finish a task shown by a goal photo?
- Can we make planning easier by letting the robot think about each object separately (like “the red cube,” “the handle,” “the button”) instead of just looking at the whole image?
- If we let a planner pick good subgoals and a separate controller execute them, does the robot do better?
- What tools make planning more reliable: trying many possibilities at once, and knowing when the robot is actually touching an object?
How did they do it?
Here is the approach, explained with everyday ideas:
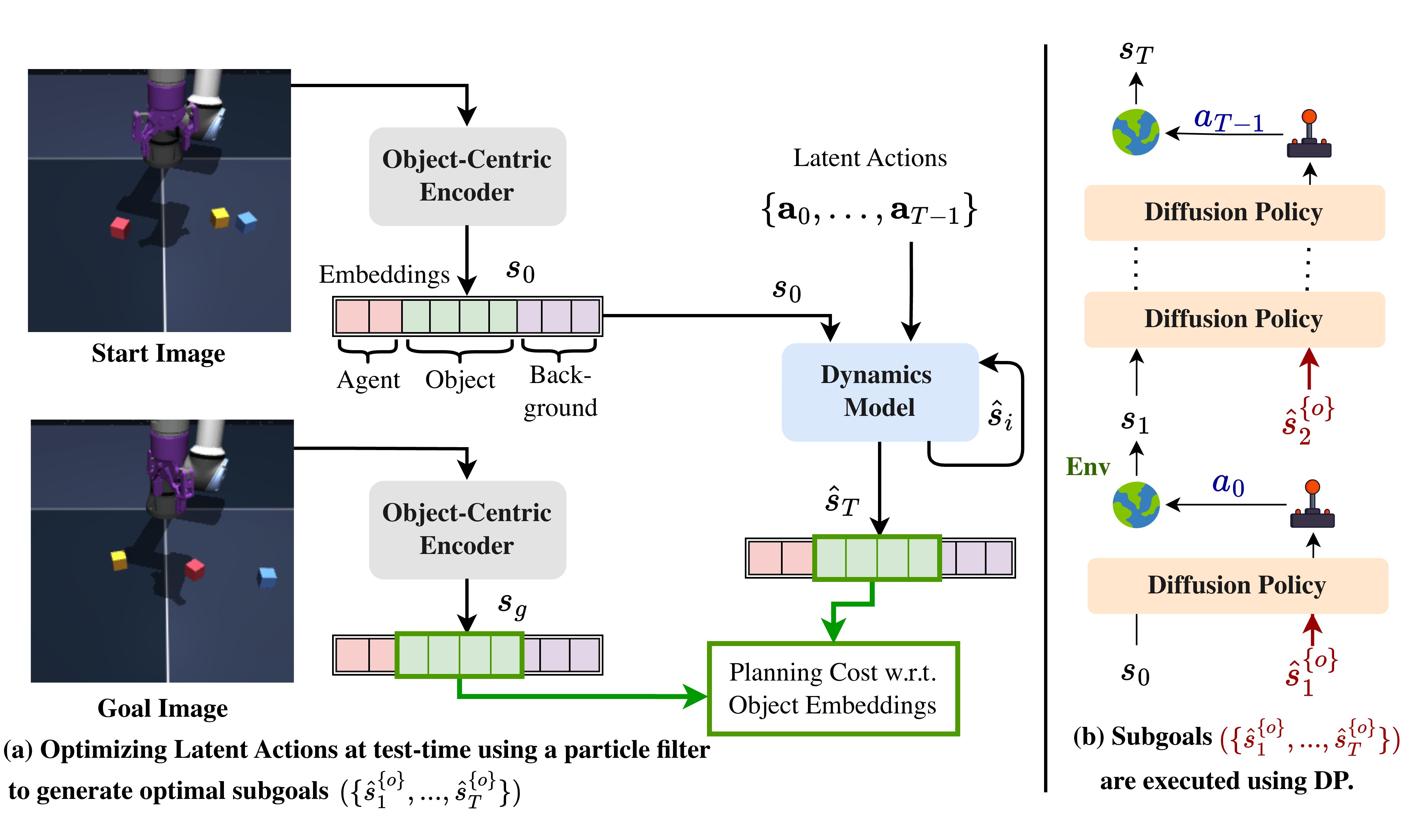
1) Seeing the world as separate objects
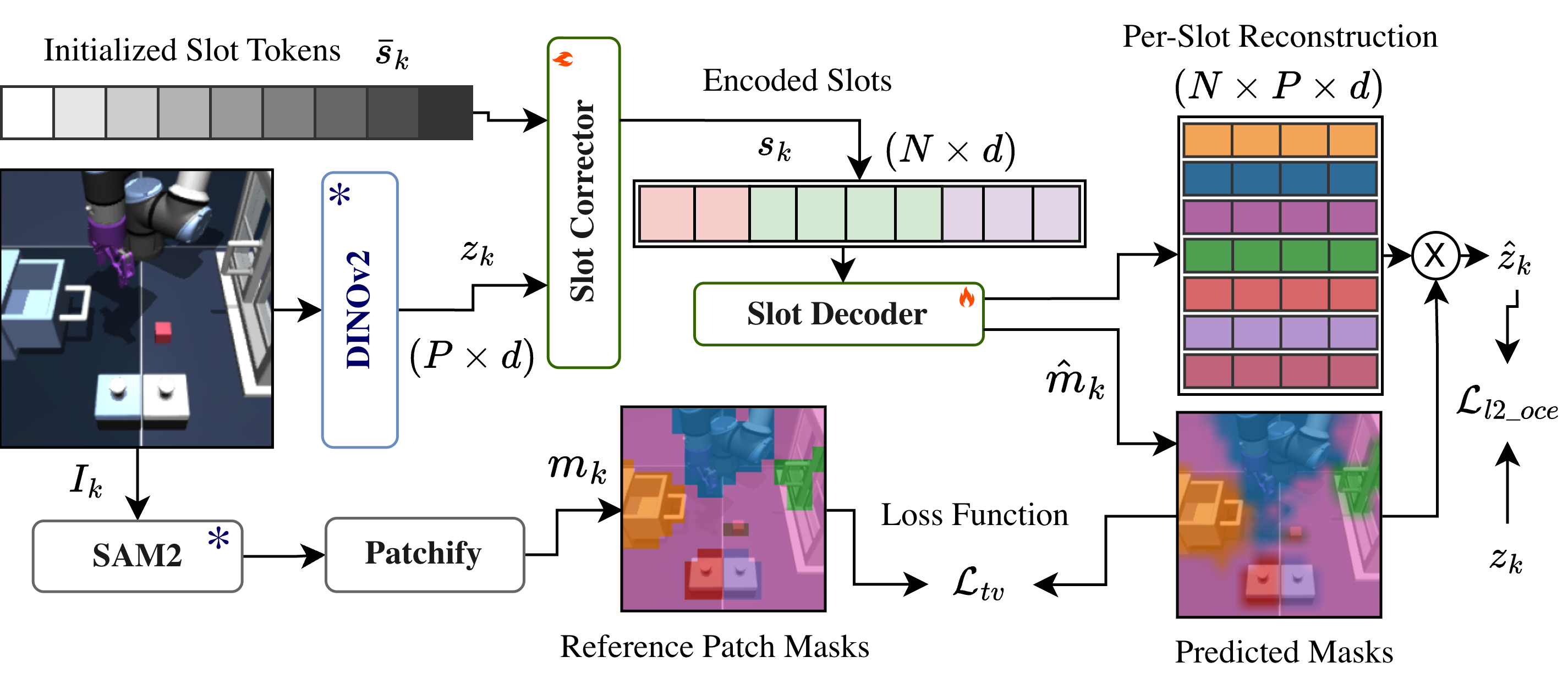
Instead of treating a picture as one big grid of pixels, the system breaks it into “object slots” (one for the robot arm, one for each cube, one for the background, etc.). Think of it like labeling pieces in a board game: each piece gets its own simple description. This helps the robot pay attention to the specific things it needs to move.
To train this, they:
- Use a strong vision model to turn each image into features.
- Use another tool (similar to an automatic “cut-out” helper) to guide which pixels belong to which object.
- Learn compact “object embeddings” so each object is represented by a short vector (a list of numbers).
2) Learning to predict what happens next (the world model)
The world model is like a mental simulator. Given:
- the current object descriptions, and
- a sequence of possible actions, it predicts what the scene will look like a few steps into the future. Imagine pausing a game, choosing some joystick moves, and previewing how each piece will shift.
3) Planning by trying many guesses at once (particle filter)
To choose good subgoals, the system tries lots of different action plans in parallel (like sending out many scouts to test different paths). This is called a particle filter. It keeps the best candidates and refines them over several rounds.
To score each candidate plan, it looks at:
- How close each object’s predicted state gets to the goal image’s objects (distance in the learned object space).
- A “contact” signal that encourages meaningful moments (like when the gripper actually grabs a handle), so subgoals happen at the right times (e.g., “hand on handle” before “pull handle”).
4) A skilled helper for short moves (diffusion policy)
Once the high-level planner picks a subgoal (like “hand touches the handle”), a diffusion policy handles the short, precise motion to get there. You can think of the world model as the “strategist” and the diffusion policy as the “athlete” that executes the next move smoothly and quickly.
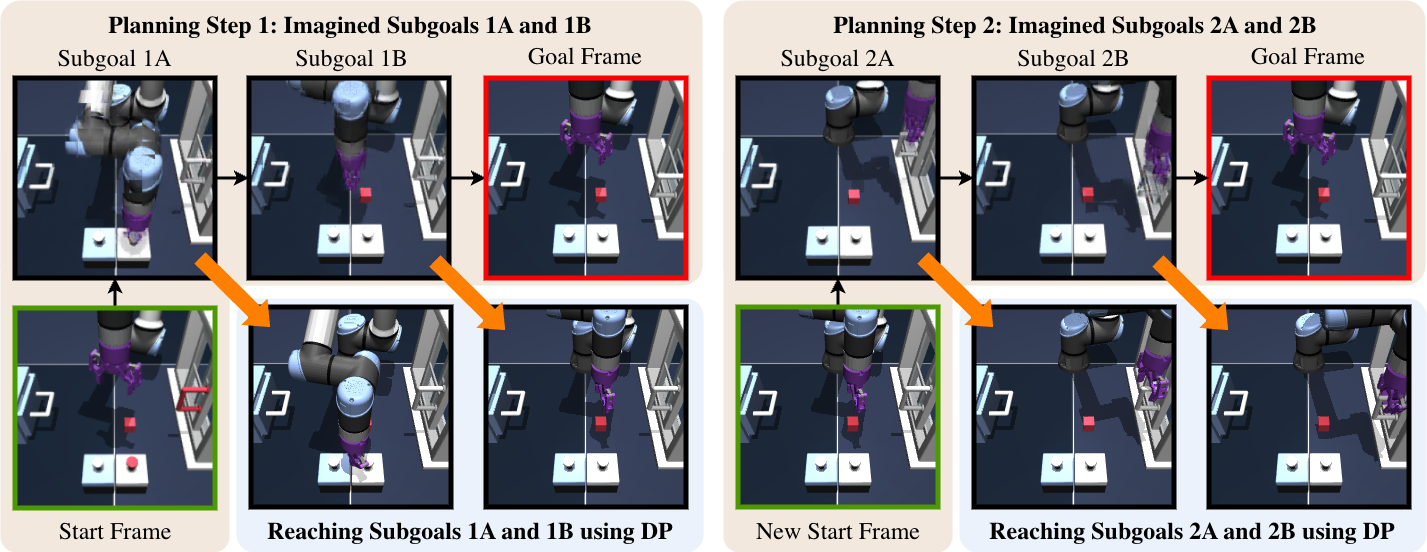
5) Doing multi-stage tasks step by step
For tasks with multiple parts (like moving three cubes), the system:
- Plans subgoals for one object,
- Executes them,
- Looks at the new scene,
- Plans the next subgoals for the next object,
- And repeats, until it matches the final goal picture.
What did they find?
On a set of robot tasks, especially multi-step ones, WorldDP worked better than other methods. Highlights:
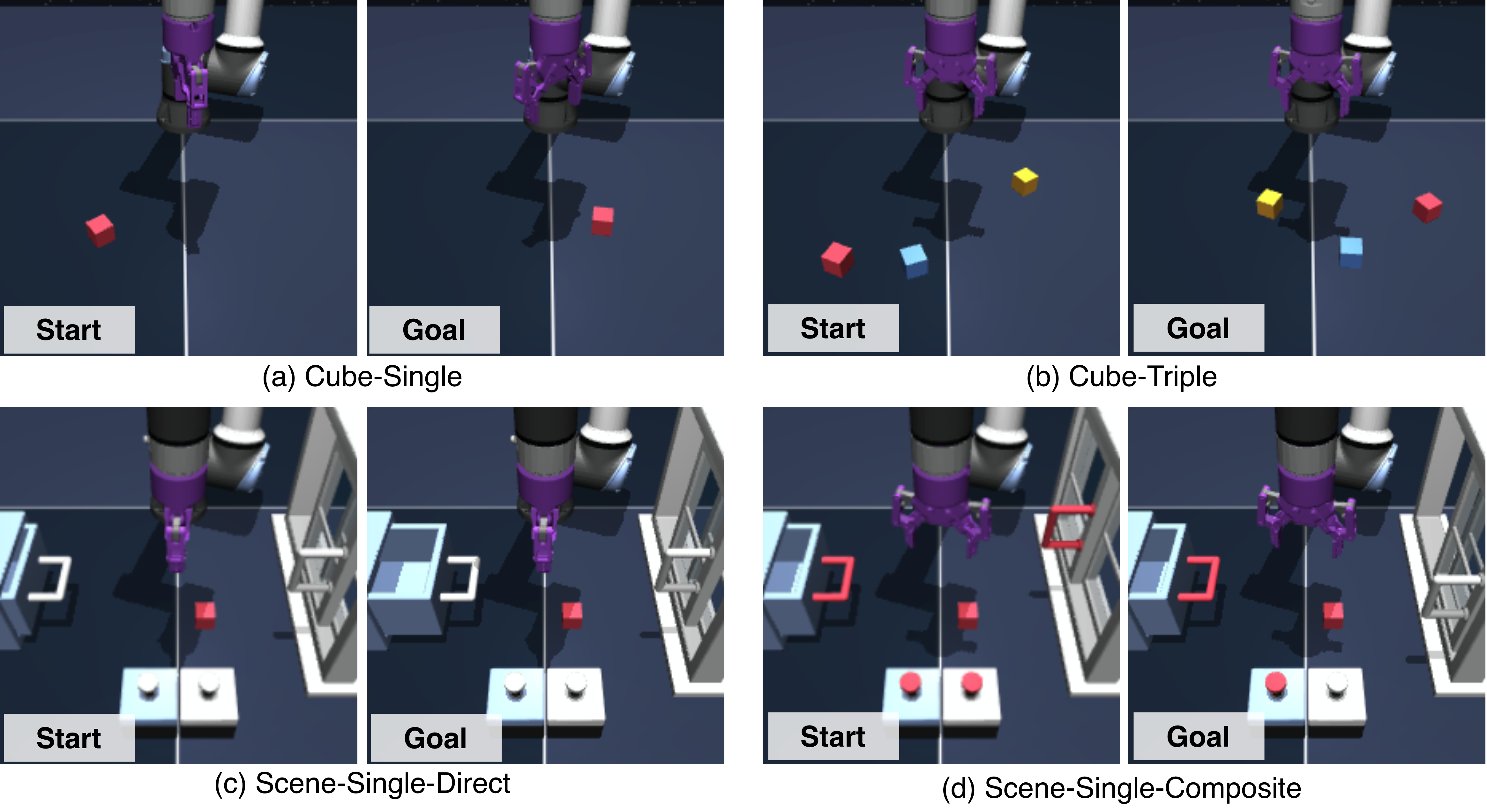
- On a three-cube rearrangement task, it succeeded far more often than baselines, including:
- Reaching the correct spot for at least one cube in all test runs (100%),
- Correctly placing two cubes most of the time (72%),
- Getting all three cubes right much more often than others (30%).
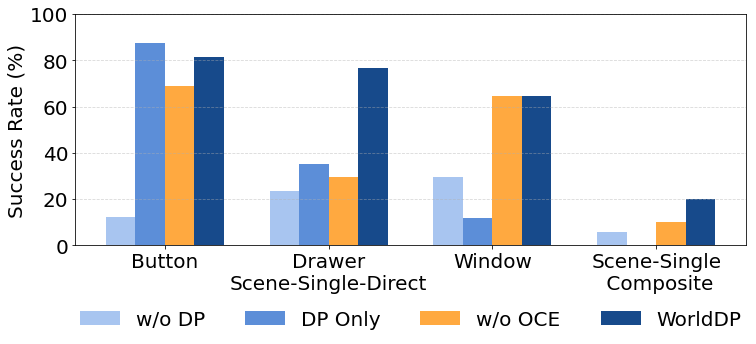
- On tasks like “press the right button, then open the drawer/window,” it matched or beat other systems on the full multi-step goal.
- A simple “diffusion policy alone” struggled on long tasks (it’s good at short moves, not long plans).
- A “world model alone” struggled to execute small, precise motions.
- Combining them (WorldDP) gave the best of both: smart plans plus reliable execution.
They also tested pieces of the system:
- Removing the object-centric view made performance drop. Focusing on each object separately helps both learning and planning.
- Replacing the “many guesses” planner (particle filter) with a single-shaped search method hurt performance. Trying many different ideas in parallel is important because there are many valid ways to solve a task.
- Removing the contact signal made subgoals less meaningful (e.g., missing the “grab” moment), and performance fell.
Why does this matter?
This work shows a practical way to get robots to do longer, more realistic chores by:
- Letting a planner think far ahead in terms of objects and key moments, and
- Letting a fast controller handle the fine-grained motions to reach each subgoal.
If developed further, this could help robots perform useful, multi-step tasks at home, in labs, or in factories—like tidying multiple items, preparing tools in order, or operating simple mechanisms.
The authors note some limitations and next steps:
- Goals are images; in the future, the robot could plan from language instructions (“Put the red block on the blue one”).
- Planning with many guesses can be slow; speeding it up or using smarter search could help.
- Better training strategies might improve the world model even more.
In short, WorldDP offers a clear recipe: think in objects, plan big steps, execute small steps well. This makes complex robot tasks much more achievable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research:
- Real-world validation: All results appear in simulation (OGBench variants); robustness to real sensor noise, latency, calibration drift, friction variability, and hardware constraints (e.g., joint limits, singularities) remains untested.
- Camera assumptions: The method assumes a static external camera; performance under moving/egocentric cameras, multi-view setups, changing extrinsics, or viewpoint shifts is not evaluated.
- Goal specification scope: Goals are image-based; extensions to language goals, symbolic constraints, or mixed goal modalities (text + image + constraints) are not explored.
- Data efficiency: Each environment uses ~2M frames of “play” data; scaling down data requirements, leveraging pretraining, simulation-to-real transfer, or data augmentation is not studied.
- Generalization across tasks and embodiments: Separate models per environment were trained; cross-task transfer, cross-embodiment generalization (e.g., to different manipulators), and plug-and-play reuse of components are open.
- Long-horizon scalability: Success on the hardest tasks is still limited (e.g., 30% for 3-cubes, 20% full composite); what limits scaling in horizon length, number of objects, or dependency depth is not dissected.
- Failure mode analysis: A systematic breakdown of failure sources (world-model prediction error vs. subgoal quality vs. DP tracking vs. contact misprediction vs. perception) is missing.
- Computational footprint: Particle Filter (PF) planning incurs up to 2 minutes of overhead; profiling, parallelization, GPU/TPU batching, and comparisons to gradient-based/planner-in-the-loop alternatives are not provided.
- PF sensitivity and design: No analysis of PF hyperparameter sensitivity (Q, M, L, σ), degeneracy, resampling strategies, or learned proposal distributions; comparisons to hybrid PF–gradient methods remain open.
- Maintaining plan diversity: PF ultimately selects a single plan; maintaining and leveraging a plan distribution for risk-sensitive or contingency planning is unexplored.
- Subtask ordering and causal reasoning: Subgoal sequencing across objects appears heuristic; learning task graphs, preconditions/effects, and automatically inferring the required manipulation order from goal images is not tackled.
- Contact predictor supervision: The source of contact labels and their reliability are not specified; learning contact from weak/unsupervised signals, integrating tactile/proprioception, and generalizing to varied contact types are open.
- Critical state detection beyond contact: Other pivotal events (e.g., alignment, constraint satisfaction) are not modeled; learning a richer “key-event” prior for subgoal discovery is open.
- Object-centric Encoder (OCE) reliance on SAM2: Training depends on SAM2-generated masks (privileged segmentation); robustness to SAM2 errors, removal of external supervision, and self-supervised object discovery are open.
- Patch-level granularity limits: OCE operates over DINOv2 patches, producing coarse masks and potentially missing small objects; evaluating higher-resolution features, pixel-space decoders, or multi-scale slots is needed.
- Slot identity and correspondence: Handling variable object counts, identity switches, multiple instances of similar objects, occlusions, and slot birth/death is not analyzed.
- Out-of-distribution objects: Generalization to unseen object categories, novel shapes, textures, or deformables/transparent objects is untested.
- 3D reasoning: The system is primarily 2D-visual; integrating depth, multi-view 3D features, or implicit 3D representations for geometry- and pose-aware planning is absent.
- Cost function grounding: The object-embedding MSE is assumed to correlate with physical distance/pose; quantitative calibration (embedding-to-geometry) and incorporation of explicit geometric/pose costs are missing.
- Uncertainty awareness: The world model is trained with MSE and used deterministically; uncertainty estimation (e.g., ensembles, diffusion rollout variance) and risk-aware planning are not explored.
- Exposure bias in training: Teacher forcing with autoregressive inference can cause compounding errors; scheduled sampling, consistency training, or latent rollouts during training are not tested.
- Constraint handling and safety: Collision avoidance, joint/velocity limits, self-collision, and environmental constraints are not explicitly enforced in planning.
- Low-level controller scope: The DP horizons (40 vs. 100) are fixed; adaptive horizon selection, switching policies, or MPC-like DP variants are not investigated.
- Integration with feedback control: The DP acts via IK; closed-loop control with model-based low-level controllers, impedance control, or learned residuals could improve precision but are not explored.
- Replanning frequency and triggering: Policies for when to replan, detect subgoal completion, or recover from deviations are not formalized or compared.
- Multi-agent and mobile manipulation: Extensions to dual-arm systems, hand manipulation, or mobile-base + arm coordination (higher DoF action spaces) remain open.
- Learning proposal seeds: PF seeds are hand-crafted from end-effector to workspace keypoints; learning seed distributions or leveraging value/prior networks is not examined.
- Training curriculum: No staged/curriculum training (simple→complex tasks), or subgoal pretraining, is explored to improve long-horizon performance.
- Representation learning choices: DINOv2 is frozen; impact of fine-tuning, domain-adaptive pretraining, or robotics-specific encoders (e.g., action-aware or proprioception-augmented) is not assessed.
- Proprioception and multi-modal sensing: Visual-only world model/state; incorporating proprioception, force/torque, tactile, or audio signals into OCE and dynamics is unexplored.
- Evaluation breadth and statistics: Only success rates on 50 episodes per task are reported; confidence intervals, time-to-success, path efficiency, smoothness, and safety metrics are absent.
- Reproducibility details: Many planning hyperparameters are in the appendix; public code, seeds, and ablation breadth (e.g., number of slots N, mask threshold) impact reproducibility and were not fully detailed here.
- Real-time deployment: Feasibility on embedded or edge hardware, latency budgets for closed-loop control, and energy/compute trade-offs are not evaluated.
- Cross-task planning from a single goal: For Scene-Single-Composite, how the system identifies and plans prerequisite actions (e.g., “press the correct button first”) purely from the goal image lacks a general, learned mechanism.
- Subgoal quality metrics: There is no quantitative metric or diagnostic to assess subgoal “goodness” (e.g., reachability, alignment with critical events) beyond end-task success.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be deployed with modest engineering effort in controlled or semi-structured environments, leveraging the paper’s object-centric world model, particle-filter-based subgoal planning, and goal-conditioned diffusion policy execution.
- Manufacturing and Logistics (Robotics, Software)
- Multi-object pick-and-place cells
- What: Sequentially pick and place multiple items into bins, trays, or kits (e.g., e-commerce order kitting, electronics assemblies).
- How (from the paper): Use the Object-Centric Encoder (OCE) over DINOv2 features for entity-aware state; plan subgoals per object with the Particle Filter (PF) MPC and contact-aware cost; execute each subgoal via a 40-step goal-conditioned Diffusion Policy (DP) with IK control and depth-based grasp correction.
- Tools/products/workflows:
- “Planner-Executor” ROS 2 node: World model planner outputs subgoal embeddings; DP module outputs short action bursts; IK controller executes trajectories.
- Data pipeline for reward-free “play” collection on the target cell; SAM2-guided segmentation to bootstrap OCE training.
- Assumptions/dependencies: Fixed camera or calibrated extrinsics; consistent lighting; training data from the target cell; similar end-effector DoFs (x,y,z,yaw,gripper); on-prem GPU for training and initial PF planning (~minutes per new task/goal); reliable IK; depth sensor for grasp fine-tuning.
- Drawer/door/button station operations
- What: Open/close bins/drawers, press buttons (e.g., QA stations, changeover procedures).
- How: Object-centric optimization with a contact predictor to generate “critical” subgoals (e.g., handle contact), followed by DP execution.
- Tools/workflows: Predefine goal images (open drawer, closed drawer, button state), periodically update from quality inspection cameras.
- Assumptions: Mechanism geometry seen during training; contact predictor trained with approximate labels or heuristics; moderate runtime planning overhead accepted.
- Warehousing and Retail Automation (Robotics)
- Consolidation/staging tasks with multi-stage constraints
- What: Retrieve from locked compartments (press button → open door → retrieve item → place).
- How: Sequential, per-object/world-entity subgoal planning; MPC loop replans after each subgoal.
- Dependencies: Reliable perception of latches/handles; sufficient play data capturing mechanisms’ operation; stable camera placements.
- Lab and R&D Automation (Academia, Industry R&D)
- Reproducible multi-stage manipulation benchmarks and rapid prototyping
- What: Evaluate new grasp strategies, policies, or hardware on multi-stage tasks; quickly prototype hierarchical planners.
- How: Swap in the OCE and PF-MPC with contact-aware cost; plug in your policy at the DP layer; test on OGBench-like tasks.
- Tools/products: Training scripts to learn OCE, CDiT dynamics, DP on reward-free data; visualization utilities for slot masks and rollouts.
- Assumptions: Compute access (single H100 class GPU sufficient per the paper); SAM2 or similar segmentation available to supervise OCE masks.
- Human-in-the-Loop/Teleoperation Assist (Robotics, Software)
- Subgoal suggestions and shared autonomy
- What: Provide candidate subgoals to an operator for long-horizon tasks; operator approves/edits; robot executes locally via DP.
- How: Run PF planner to propose multi-modal subgoal sequences; present ranked options; execute with short-horizon DP.
- Dependencies: UI/UX layer for subgoal visualization; latency tolerance for initial PF planning; calibration between human-specified goals and vision encoder.
- Robotics Education and Training (Academia, Education)
- Teaching hierarchical planning concepts with low annotation cost
- What: Course labs where students collect play data and train a planner-executor stack without rewards.
- How: Use SAM2-guided OCE training, CDiT for dynamics, PF for subgoal optimization, and DP tracking.
- Assumptions: Access to an arm (e.g., UR series) or high-fidelity sim; prepared datasets; pre-trained DINOv2 and SAM2 weights.
- Developer Tools and Middleware (Software)
- Object-centric perception module for existing policies
- What: Use OCE as a drop-in feature extractor to make policies object-aware, even without adopting full WorldDP.
- How: Train OCE with SAM2 guidance; feed slot embeddings to existing controllers/policies.
- Dependencies: Availability of segmentation model; adaptation to policy input format.
- Benchmarking and Evaluation (Academia, Standards)
- Multi-stage manipulation benchmarks for “goal-image” specifications
- What: Adopt OGBench-style evaluation with robust metrics for multi-object sequences and mechanism operation.
- How: Provide standardized goal-image tasks; share planning and tracking baselines (WorldDP stack).
- Assumptions: Community access to standardized datasets and evaluation protocols.
Long-Term Applications
These opportunities require further research, scaling, or integration with broader systems (e.g., language interfaces, cross-embodiment generalization, real-time constraints).
- General-Purpose Home Robotics (Robotics, Consumer)
- Household assistance and tidying
- What: Multi-stage tasks like fetching an item from a cabinet (press button → open door → retrieve → place), organizing shelves, setting tables.
- Path to deployment:
- Extend to unstructured, cluttered, multi-view settings.
- Replace image-goal input with language goals (e.g., “put the blue mug in the top-left cabinet”).
- Reduce planning latency via gradient-based or massively parallel PF/CEM on accelerators.
- Dependencies: Robust perception under changing illumination and occlusions; multi-camera support; better small-object slot segmentation; safety certification for in-home operation.
- Elder care and assistive tasks
- What: Opening drawers/wardrobes, picking up dropped items, fetching objects.
- Path: Integrate force/torque sensing for reliable contact detection; learn domain-agnostic contact predictors; ensure fail-safe behaviors.
- Assumptions: Regulatory compliance, human-robot interaction safety, privacy-preserving perception.
- Healthcare Facilities and Hospitals (Robotics, Healthcare)
- Supply retrieval and station setup
- What: Open/close storage, retrieve consumables, prepare stations, multi-object rearrangement in treatment rooms.
- Path: Strong generalization across diverse cabinets/handles; integration with hospital IT (task scheduling), sterile operation constraints.
- Dependencies: Certified hardware, strict safety and hygiene protocols; robust perception for varied object types.
- Advanced Manufacturing and Assembly (Robotics, Software)
- Complex assemblies with multi-object and mechanism interactions
- What: Multi-stage assembly sequences (e.g., insert → fasten → place), door/fixture operations, coordinated tool use.
- Path: Extend world model to force/torque and tool-use dynamics; integrate with PLCs and MES for step validation; reduce planning compute to seconds.
- Dependencies: High-fidelity play data covering tools/fixtures; synchronization with factory automation standards (OPC UA, ISA-95).
- Warehouse/Logistics at Scale (Robotics)
- Fleet-level hierarchical planners
- What: Many robots share a cloud-based planner that proposes subgoals tailored to each station/task; local DPs execute.
- Path: Cloud-native PF/MPC services; multi-robot task allocation; curriculum learning for long-horizon tasks.
- Dependencies: Low-latency comms; edge compute fallback; robust sim-to-real transfer.
- Software Ecosystem and Tooling (Software, AI Platforms)
- WorldDP-as-a-Service
- What: Cloud API offering object-centric embeddings, subgoal optimization, and reference DP; developers call it with goal images (later, language).
- Path: Containerized microservices for OCE/CDiT/PF/DP; observability and safety constraints; billing and SLAs.
- Assumptions: Secure data handling; scalable GPU orchestration; domain adaptation modules.
- Multi-Modal Goal Specification (AI + Robotics)
- Language and sketches as goals
- What: “Put the red book on the top shelf, then close the cabinet.”
- Path: Vision-Language-Action integration: map language to object-centric goal embeddings and contact schedules; use the same planner/executor.
- Dependencies: Large-scale aligned data; grounding language in object-centric slots; evaluation standards.
- Cross-Embodiment and Transfer Learning (Academia, Robotics)
- Transfer across robot arms, grippers, and workcells
- What: Train once on play data from one robot/cell; transfer planning and DP to another with minimal adaptation.
- Path: Normalize action spaces; learn embodiment-invariant slots; domain randomization and meta-learning.
- Dependencies: Diverse multi-embodiment datasets; calibration pipelines.
- Policy and Standards (Policy, Industry Consortia)
- Benchmarking and safety guidelines for hierarchical planners
- What: Standards for multi-stage vision-guided manipulation evaluation (datasets, protocols); safety thresholds for planner latency and failure modes.
- Path: Industry-academia consortia; public benchmarks for entity-centric planning; define contact detection evaluation.
- Assumptions: Stakeholder alignment; data-sharing agreements; privacy best practices.
- Hardware Acceleration and Real-Time Optimization (Semiconductors, Robotics)
- Dedicated accelerators for PF/MPC over latent dynamics
- What: Achieve sub-second subgoal optimization for on-robot planning.
- Path: Kernel fusion for PF sampling/rollouts; TPU/GPU/FPGA acceleration; differentiable planners with hardware support.
- Dependencies: Compiler/toolchain support; co-design with model architectures.
Cross-Cutting Assumptions and Dependencies
These factors affect feasibility across many applications:
- Sensing and calibration
- Static or calibrated camera views; availability of depth sensors for fine-grained grasp correction; robust lighting conditions.
- Data availability
- Reward-free play data representative of target tasks/objects/mechanisms; SAM2 or alternative segmentation for OCE mask supervision; contact labels or heuristics for training a contact predictor.
- Compute and latency
- Offline training requires modern GPUs; test-time PF optimization currently adds up to ~2 minutes before execution—needs acceleration for time-critical tasks.
- Controller integration
- Reliable inverse kinematics and low-level controllers; safety interlocks; compliance with industrial standards.
- Generalization and robustness
- Domain shifts (new camera angles, object textures) require adaptation; small objects may be underrepresented in patch-level features without improved slot learning.
- Safety and compliance
- Human-robot interaction safety, especially in public or healthcare settings; policy constraints on video data storage and processing.
These immediate and long-term pathways translate the paper’s innovations—object-centric world modeling, contact-aware subgoal planning with particle filters, and diffusion-policy execution—into deployable capabilities, while acknowledging practical constraints and research frontiers.
Glossary
- Adaptive Layer Normalization: A conditioning variant of LayerNorm where scale and shift are adapted based on a context vector to inject conditioning signals into a network. "This embedding conditions the CDiT model through Adaptive Layer Normalization layers."
- Action encoder: A module (here, transformer-based) that compresses a sequence of actions into a compact latent representation for conditioning dynamics models. "The action sequence ... is compressed into a latent action embedding via a transformer-based action encoder~\citep{zhang2026hierarchical}."
- Autoregressive rollouts: Sequential prediction where each next state is generated by feeding the previous predicted state back into the model. "Autoregressive rollouts through generate predicted state trajectories"
- Conditional Diffusion Transformer (CDiT): A diffusion-style transformer that predicts future states conditioned on inputs (e.g., actions), used here for dynamics modeling. "We adopt the Conditional Diffusion Transformer (CDiT) architecture used in \cite{goswami2025world}."
- Contact predictor: A learned model that estimates the probability of contact between the robot and each object to guide subgoal selection. "We train a lightweight MLP contact predictor that maps state to an -dimensional vector of contact probabilities."
- Cross-Attention: An attention mechanism that lets one set of queries attend to another set of keys/values; used to refine object slots from image patches. "These slots are refined by a Slot Corrector through recursive passes of cross-attention and Gated Recurrent Unit (GRU) blocks;"
- Cross-Entropy Method (CEM): A sampling-based optimization algorithm that iteratively updates a distribution toward elite samples. "most world-model-based planning relies on optimization techniques like the Cross-Entropy Method (CEM)"
- DINOv2: A self-supervised vision transformer producing strong patch-level image embeddings used as visual backbones. "utilize patch-level features from large-scale encoders like DINOv2~\citep{oquab2023dinov2} or V-JEPA~\citep{assran2025v}"
- Diffusion Policy: A policy that generates action sequences via a diffusion generative process, effective for robust short-horizon control. "A low-level, goal-conditioned diffusion policy (DP) then sequentially tracks and executes these subgoals to solve the task."
- End-effector: The robot’s tool or gripper at the tip of its kinematic chain used to interact with the environment. "The action space consists of commanded changes to the end-effector's coordinates, yaw, and gripper opening."
- Hierarchical optimal control: A multi-level control paradigm where high-level planning sets subgoals and low-level controllers execute them. "This paradigm is widely used in hierarchical optimal control~\citep{falcone2008hierarchical, li2021planning, fang2019dynamics}"
- Inverse kinematics: Computing joint commands to achieve a desired end-effector pose in task space. "are executed on the manipulator via an inverse kinematics controller."
- Joint Embedding Predictive Architecture (JEPA): A representation-learning framework that predicts future embeddings rather than pixels, enabling latent-state dynamics. "more recent methods often adopt the Joint Embedding Predictive Architecture (JEPA) \citep{assran2025v} paradigm, representing states as latent embeddings of image encoders"
- Latent action embedding: A compact vector representation of a sequence of actions used to condition a dynamics model. "The action sequence ... is compressed into a latent action embedding "
- Model Predictive Control (MPC): Receding-horizon planning that optimizes action sequences using a predictive model at each step. "the world model works as a transition function inside a Model Predictive Control (MPC) loop to plan trajectories by optimizing action sequences."
- Multi-modal optimization: Optimization that accounts for multiple distinct solution modes (e.g., multiple valid action sequences) rather than a single unimodal solution. "we find that multi-modal optimization via a Particle Filter is superior"
- Object-aware planning: Planning that explicitly reasons over individual objects’ representations and interactions. "We present the first world model approach to employ object-aware planning, incorporating a contact predictor and particle filter optimization to enhance subgoal generation."
- Object-centric representation: A scene representation decomposed into embeddings (“slots”) for individual entities (objects, robot, background). "we incorporate object-centric representations that decouple environmental entities"
- Open-loop rollout: Predicting a trajectory forward without using feedback from actual observed future states to correct errors. "Finally, we present an open-loop rollout example on the Cube-Triple dataset"
- Operational space: The task-space (Cartesian) space in which end-effector motions are commanded and controlled. "these predicted actions operate within the end-effector's operational space"
- Particle Filter (PF): A sequential Monte Carlo method that maintains a set of particles (hypotheses) to approximate complex, multi-modal distributions. "we find that a Particle Filter (PF) better accommodates the inherent multi-modality of robotic action spaces"
- Patch-level features: Visual embeddings computed per image patch (token) rather than per pixel or whole image. "utilize patch-level features from large-scale encoders like DINOv2"
- SAM2: A segmentation model (Segment Anything, second version) used here to provide supervision for object masks. "using a SAM2~\citep{ravi2025sam} model to provide guidance during training."
- Slot attention: An iterative attention mechanism that extracts a fixed set of object “slots” from input features. "Following the slot attention framework~\citep{locatello2020object}, we initialize slots"
- Teacher forcing: A training technique where the model is fed ground-truth previous outputs to stabilize sequence learning. "we predict the next state $\hat{s}_{k_{i+1}$ conditioned on all previous ground-truth states ... via teacher forcing"
- Tversky loss: A segmentation loss that generalizes Dice/IoU by weighting false positives and false negatives. "We then employ a Tversky loss~\citep{salehi2017tversky}, , (described in the appendix) to supervise the predicted masks ."
- Vision-Language-Action models: Models that integrate visual inputs, natural language, and action generation for control tasks. "or Vision-Language-Action models \citep{kim2024openvla, intelligence2025pi, bjorck2025gr00t}"
- World model: A learned predictive model of environment dynamics that maps current state and actions to future states. "World models, in recent times, have emerged as a powerful class of functions for learning complex system dynamics from observations"
Collections
Sign up for free to add this paper to one or more collections.

