Hierarchical Planning with Latent World Models
Abstract: Model predictive control (MPC) with learned world models has emerged as a promising paradigm for embodied control, particularly for its ability to generalize zero-shot when deployed in new environments. However, learned world models often struggle with long-horizon control due to the accumulation of prediction errors and the exponentially growing search space. In this work, we address these challenges by learning latent world models at multiple temporal scales and performing hierarchical planning across these scales, enabling long-horizon reasoning while substantially reducing inference-time planning complexity. Our approach serves as a modular planning abstraction that applies across diverse latent world-model architectures and domains. We demonstrate that this hierarchical approach enables zero-shot control on real-world non-greedy robotic tasks, achieving a 70% success rate on pick-&-place using only a final goal specification, compared to 0% for a single-level world model. In addition, across physics-based simulated environments including push manipulation and maze navigation, hierarchical planning achieves higher success while requiring up to 4x less planning-time compute.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Hierarchical Planning with Latent World Models — Explained Simply
What is this paper about?
This paper is about teaching robots and agents to plan and act over long periods of time by “imagining” the future. The authors show a way to break big, multi-step tasks into smaller chunks using two “brains”:
- a high-level planner that picks good waypoints or subgoals, and
- a low-level planner that figures out the exact moves to reach the next subgoal.
They do this using learned “world models” that predict what will happen next from camera images, without needing task-specific labels or rewards.
What questions did the researchers ask?
In simple terms, they asked:
- How can a robot plan far ahead without getting confused or taking forever to think?
- Can we make robots handle tricky tasks where you must first move away from the goal (non-greedy behavior), like opening a drawer before grabbing something inside?
- Can this work “zero-shot,” meaning without retraining for each new task, and still be efficient and reliable?
How did they do it? (Methods in everyday language)
Think of planning a road trip:
- The high-level planner picks cities you’ll stop at (subgoals).
- The low-level planner figures out the exact turns to get from one city to the next.
Here’s how that maps to the robot’s brain:
- World model: Like a mental simulator. Given what the robot sees now and a possible action, it predicts what it will see next.
- Latent space: A compact “secret code” version of images and states. Instead of working with big pictures, the robot works with smaller, meaningful numbers.
- Model Predictive Control (MPC): The robot repeatedly “imagines” a few steps into the future, chooses the best next move, acts, and repeats.
The new idea in this paper is to use hierarchy in that mental simulation:
- High-level world model: Predicts the future in bigger steps. It works with “macro-actions” (summaries of many small moves) and proposes a subgoal, a helpful checkpoint on the way to the final goal.
- Low-level world model: Predicts shorter, fine-grained steps to actually reach that subgoal.
- Action encoder: A tool that compresses a long sequence of tiny movements into one “macro-action,” making high-level planning much simpler and faster.
Importantly, both levels speak the same “latent language,” so the high-level subgoal can be directly understood by the low-level planner. This avoids training special skills or needing hand-written rules.
Zero-shot setup: The models are trained on lots of unlabeled videos or robot data (just “what happened when I did this”), not on specific tasks. At test time, you give a goal image (what you want the scene to look like), and the planner figures out how to get there.
Why this helps:
- It reduces “error piling up.” Predicting many tiny steps can add small mistakes that grow big. Predicting in bigger steps at the top helps avoid that.
- It shrinks the search space. Choosing among a few macro-actions is easier than picking among thousands of tiny actions.
What did they find, and why does it matter?
The most important findings are:
- Real robot success on tricky, non-greedy tasks:
- On a Franka arm (a real robot) doing pick-and-place and drawer tasks from a single goal image, the hierarchical system succeeded much more often. For example, pick-and-place went from 0% success (single-level planner) to about 70% success with hierarchy.
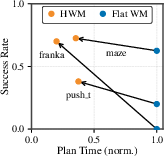
- Better long-horizon control in simulation:
- In a pushing task with a T-shaped block (Push-T), success at long distances jumped from 17% to 61% using hierarchy.
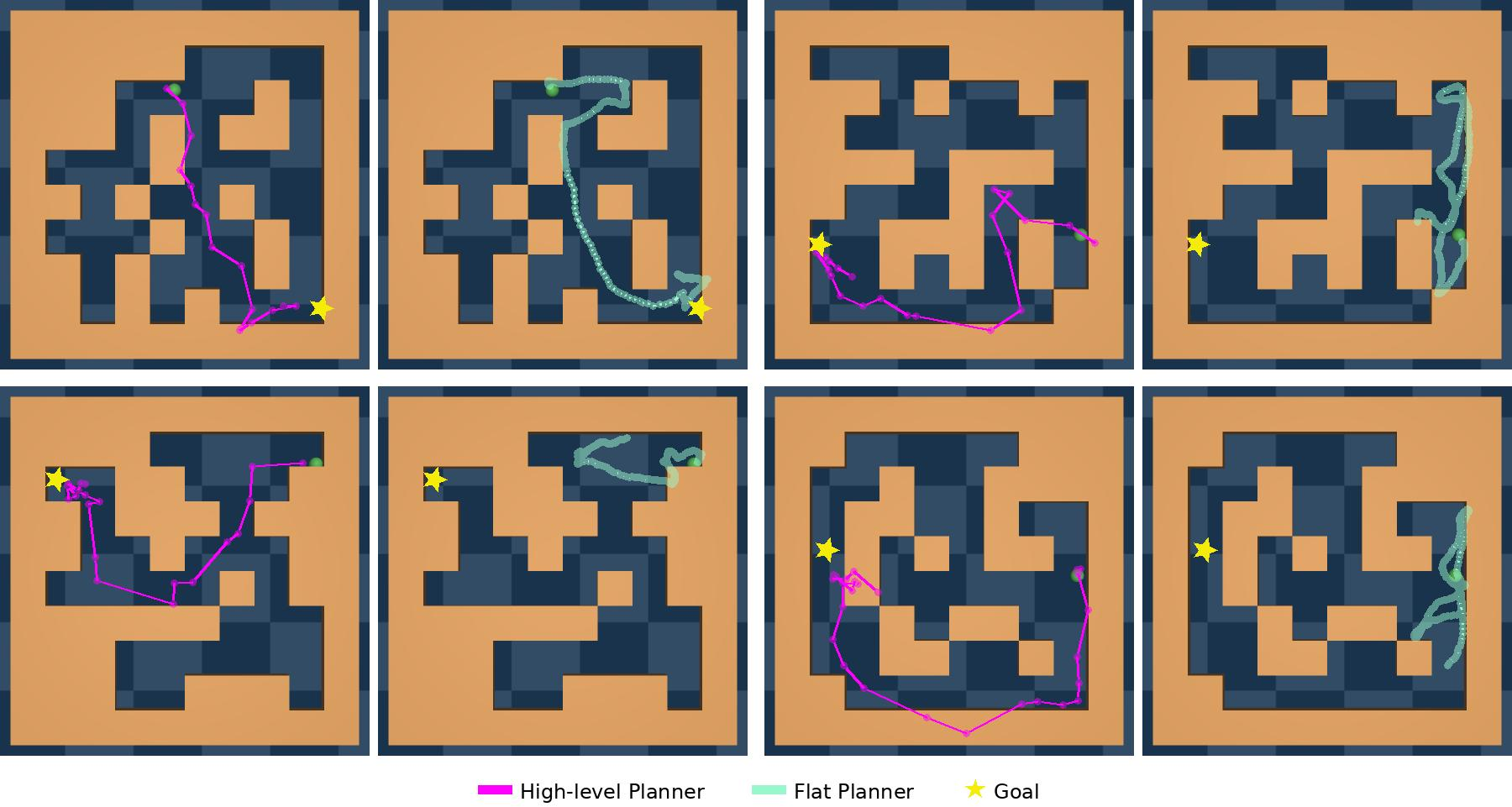
- In maze navigation with bigger, unseen mazes, success improved dramatically, especially on the hardest cases.
- Faster planning with less compute:
- For the same or better success, the hierarchical approach used up to 3–4× less planning time than the single-level version.
Why this matters:
- It shows robots can solve multi-step tasks that need detours (like moving away from the goal before approaching it), using only a final goal image and no extra training.
- It’s a general method: the same hierarchical planning layer improved different world model types and different tasks.
What could this change in the future? (Implications)
- More capable robots, sooner: Robots could handle longer, more complex tasks in homes, warehouses, and labs without needing hand-designed steps or task-specific training.
- Efficient and modular planning: The “hierarchy” is a plug-in on top of existing world models. That means you can reuse many different learned models and still get the benefits.
- Better generalization: Because it’s trained from broad, unlabeled data and plans at test time, it can adapt to new goals and environments more easily.
Caveats and next steps:
- Very long or very complicated tasks are still hard. The authors suggest improvements like:
- Better high-level representations (even more abstract “mental maps”),
- Handling uncertainty in predictions,
- Tighter feedback between high and low levels so they coordinate even more smoothly.
In short, this work shows a practical way to make “thinking ahead” both smarter and faster by combining big-picture planning with precise control—much like how you plan a trip with waypoints and then navigate turn by turn.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain after this work. These points focus on what is missing, uncertain, or left unexplored, and are phrased to guide follow-up research.
- Feasibility-aware subgoal generation: The high-level planner can propose valid-but-unreachable subgoals; there is no mechanism to predict low-level reachability or to filter subgoals with a learned viability/value model.
- Lack of cross-level feedback: The hierarchy is strictly top-down with separate optimizations; there is no joint or bi-directional coordination (e.g., low-level feasibility signals shaping high-level plans, joint training, or alternating optimizations).
- Uncertainty handling: Planning is deterministic and does not quantify or propagate model uncertainty (e.g., ensembles, Bayesian heads, risk-sensitive costs) to avoid overconfident long-horizon subgoals or infeasible macro-actions.
- Latent distance as a progress metric: The L1 distance in latent space is assumed to measure goal progress, but there is no calibration or validation that latent distances reflect task-relevant success; learned costs/contrastive distances or success classifiers are not explored.
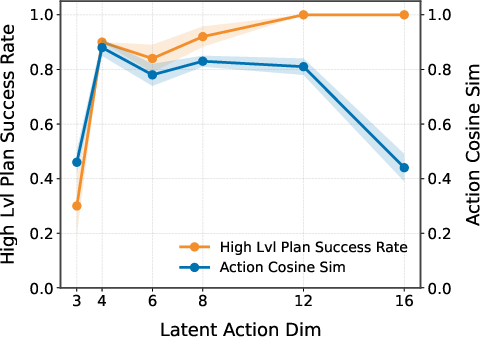
- Action-encoder priors and OOD latent actions: The high-level planner samples latent actions via CEM without priors or support constraints; how to regularize macro-actions to stay on-policy/in-distribution remains open (e.g., diffusion priors, normalizing flows, KL to dataset).
- Variable macro-action timing at inference: Although variable-length segments are used in training, the inference procedure fixes horizons (e.g., H=2 high-level steps) and uses the first predicted latent as subgoal; adaptive subgoal timing/termination criteria are not addressed.
- Automatic selection of hierarchical hyperparameters: There is no principled way to choose the number of levels, high-/low-level horizons, replanning interval k, and latent action dimensionality; sensitivity and auto-tuning are not studied.
- Beyond two levels: The framework is demonstrated with two levels only; how many levels are beneficial, how to place temporal boundaries, and how to train multi-level stacks remains open.
- Subgoal choice beyond “first step”: Only the first predicted high-level latent is executed as the subgoal; alternatives (e.g., selecting among later waypoints based on reachability or progress-to-goal) are not evaluated.
- Planning algorithm dependence: CEM is the sole optimizer; comparisons with alternative planners (e.g., MPPI variants, gradient-based shooting, MCTS over learned dynamics, hybrid trajectory optimization) and their compute-performance trade-offs are missing.
- Compute and deployment constraints: Test-time planning uses thousands of samples on GPUs; the feasibility under tight real-time or on-robot edge compute budgets (CPU/NPU) and energy constraints is not evaluated.
- Robustness to stochastic, dynamic, or adversarial environments: All tasks are quasi-static and single-agent; performance under moving obstacles, human interaction, stochastic dynamics, or sensor latency/noise remains unknown.
- Partial observability and memory: The approach does not include explicit memory or belief tracking; handling occlusions, long-term dependencies, or latent-state uncertainty (e.g., via filters or recurrent inference) is not studied.
- Goal specification generality: Goals are images (plus proprioception); extension to language, sets of acceptable goals, constraints (e.g., “avoidance” conditions), or multi-objective preferences is unexplored.
- Safety and constraint satisfaction: There is no explicit handling of collision avoidance, joint/velocity limits, or safety regions; integrating constraints or safe-MPC into latent planning is an open direction.
- Sensor modality limitations: Reported failures cite perceptual issues (e.g., depth/geometry); the benefits of adding depth, segmentation, tactile/force, or 3D scene representations are not quantified.
- Data requirements and scaling laws: The method is trained on ~130 hours of real-robot data; there is no study of data efficiency, scaling behavior, or how dataset composition/coverage affects hierarchical performance.
- Distribution shift in action subsequences: High-level macro-actions may induce action patterns underrepresented in training; how the high-level model extrapolates to OOD latent actions is untested.
- Shared vs. separate latent spaces: Both levels share one encoder and latent space; potential benefits of level-specific representations or learned cross-level mappings are not analyzed.
- Model mismatch and compounding error analysis: While qualitative benefits are shown, there is no formal analysis of error accumulation reduction, stability of hierarchical MPC, or bounds on planning error vs. horizon.
- Generalization breadth: Evaluations cover three domains; transfer to more complex, contact-rich manipulation (deformables, tool use), locomotion, and multi-object tasks is not demonstrated.
- Learning reachability/value models: There is no learned predictor for “distance-to-goal” in latent space grounded in success likelihood; training such models to guide subgoal selection is an open avenue.
- Integration with skills/options: The approach avoids skill learning; whether combining latent-world-model planning with learned options/skills improves performance and compute is untested.
- Termination and success detection: Execution relies on latent L1 minimization and decoded visuals for interpretability; robust stopping conditions and goal-detection mechanisms for noisy sensors are absent.
- Hyperparameter sensitivity: The method involves many planning hyperparameters (sample counts, iterations, horizons); systematic sensitivity analyses and auto-configuration strategies are missing.
- Multi-agent and interactive settings: The framework’s applicability to collaborative or competitive tasks (requiring anticipation of other agents) is unexplored.
- Interpretability of latent subgoals: Decoded subgoals are visualization-only; methods to verify, inspect, and debug latent subgoals for safety and reliability are not provided.
Practical Applications
Immediate Applications
- Robotics (manufacturing/lab automation) — Zero-shot pick-and-place and non-greedy manipulation from a goal image
- What: Retrofit existing arms (e.g., Franka, UR, FANUC) to execute multi-stage tasks like pick–place, open/close drawers, tool handoffs using a single goal photo/state instead of hand-authored subgoals or task-specific rewards.
- Tools/workflows: HWM Planner ROS node; “Goal-to-Plan” pipeline (encode current/goal → high-level latent plan → decoded subgoal visualization → low-level MPC via IK); use the released codebase to add a high-level model and action-encoder on top of an existing latent world model.
- Dependencies/assumptions: Availability of domain trajectories (e.g., DROID/RoboSet-style logs) to train both levels; calibrated RGB(+proprioception) sensing; safe motion controllers and IK; on-robot GPU or edge compute; task geometry similar to data distribution; careful tuning of latent-action dimension (e.g., 4-D).
- Robotics (warehousing/logistics) — Layout-robust indoor navigation with lower compute
- What: Point-to-point mobile robot navigation through frequently changing aisles/corridors using images/top-down renderings, with 3–4× lower planning compute than flat planners.
- Tools/workflows: High-level planner proposes waypoint latents; low-level controller tracks with short-horizon MPC (CEM/MPPI); subgoal overlays for monitoring.
- Dependencies/assumptions: Reliable visual state estimation; offline navigation logs for training (including OOD layouts); real-time re-planning; safety envelopes (geofencing, stop conditions).
- Robotics (assembly/handling) — Contact-rich pushing and reorientation policies
- What: Use HWM to plan non-greedy pushes/reorientations (e.g., “Push-T” analogs) in feeders and fixtures where objects must be maneuvered away from the target before aligning.
- Tools/workflows: Train task-agnostic latent world models on push/contact datasets; deploy HWM for macro-planning + primitive execution.
- Dependencies/assumptions: Coverage of relevant contact dynamics in offline data; stable low-level compliance control; appropriate sensing (force/vision) if needed.
- Software/ML engineering — Drop-in hierarchical MPC for latent world models
- What: Productize HWM as a model-agnostic planning layer on top of VJEPA2-AC, DINO-WM, PLDM or similar, to reduce search complexity and improve long-horizon success.
- Tools/workflows: SDK with (i) action-encoder trainer, (ii) high-level WM trainer with variable waypoint spacing, (iii) dual-scale CEM planner, (iv) SubgoalViz for decoding/interpreting latent plans; CI benchmarks on manipulation/navigation suites.
- Dependencies/assumptions: Access to pretrained latent world models or training recipes; GPU budget for training high-level model; standardized observation/action specs.
- Academia (research/teaching) — Benchmarking and course modules on hierarchical planning
- What: Use HWM to teach/model long-horizon planning, error accumulation analyses, and compute–performance trade-offs; reproduce results on Franka/Push-T/Diverse Maze.
- Tools/workflows: Classroom labs with the released GitHub repo and datasets; ablation exercises (latent action dimension, horizon, CEM budget).
- Dependencies/assumptions: Compute resources; simplified robot/testbeds or high-fidelity simulators; dataset licenses.
- Product QA and test rigs — Multi-stage fixture manipulation without custom scripting
- What: Replace brittle task scripts with goal-image-driven sequences for toggles, drawers, covers, or staged placements in QA lines.
- Tools/workflows: Library of goal images per SKU/state; HWM planning wrapper around existing robot controllers; subgoal logs for traceability.
- Dependencies/assumptions: Consistent lighting/placement; safety interlocks; dataset curation per SKU variant; guardrails against rare OOD cases.
- Daily life prototypes (makerspaces/labs) — Goal-photo commands for household-ish tasks
- What: Prototype “put cup here”/“open drawer” behaviors for tabletop assistive robots using only a final goal photo.
- Tools/workflows: Minimal prompt UI that captures the goal image; HWM planning loop; on-device subgoal visualization for debugging.
- Dependencies/assumptions: Constrained, uncluttered scenes similar to training; user supervision and safety stops; compute on-board or tethered.
- Ops and safety — Subgoal-based explainability and monitoring
- What: Decode and log high-level subgoals to give operators visibility into “why” a robot moves away from a goal (non-greedy steps), aiding incident review and compliance.
- Tools/workflows: Subgoal dashboards with reconstructions, cosine-similarity/goal-distance metrics; alerts when subgoals become unreachable.
- Dependencies/assumptions: Reliable decoders for interpretability (not used in control); thresholds calibrated to environment risk.
Long-Term Applications
- General-purpose home and service robots — Multi-room, multi-task execution from images or high-level goals
- What: Combine HWM with larger, more abstract world models to handle cleaning/tidying, object fetching, and appliance interaction via long-horizon subgoal chains.
- Potential products: “Goal-photo-to-action” assistant; routine planners that schedule macro-actions across rooms.
- Dependencies/assumptions: Internet-scale embodied video datasets; robust 3D perception; safety-certified low-level control; uncertainty-aware planning for open worlds.
- Healthcare logistics and assistive care
- What: Ward delivery/fetching, supply drawer operations, room prep with non-greedy paths in dynamic spaces; assistive robots performing safe, staged manipulations.
- Workflows: Hospital-specific offline data collection; HWM for goal-driven routines; human-in-the-loop subgoal vetting.
- Dependencies/assumptions: Strong safety, sterilization, and regulatory compliance; OOD robustness; clear fail-safes.
- Autonomous driving and ADAS planning
- What: Hierarchical latent planning for route-level macro decisions (e.g., merges, detours) and micro maneuvers under a shared latent model of traffic dynamics.
- Products: Planner modules that reduce online compute while improving long-horizon foresight.
- Dependencies/assumptions: High-fidelity multi-agent world models; rigorous safety envelopes; real-time guarantees; regulatory approval.
- Industrial process control (energy/chemicals) with high-dimensional sensors
- What: Extend hierarchical MPC to learned latent dynamics from multimodal plant logs, enabling macro setpoint planning with micro actuation refinement.
- Tools: Latent world models over time-series + vision; high-level macro-action encoders over actuator sequences.
- Dependencies/assumptions: Safe simulation-to-plant transfer, observability of critical states, strong uncertainty quantification and failover policies.
- Multi-robot fleet coordination (warehouses, agriculture)
- What: High-level macro-plans distribute waypoints/subgoals across robots; low-level planners execute safely and efficiently under local dynamics.
- Products: Fleet coordinator that emits latent subgoals; per-robot HWM execution.
- Dependencies/assumptions: Communications latency bounds; collision avoidance; shared or aligned latent spaces across agents.
- Foundation models for embodied control (language × HWM)
- What: Use language/VLA models to specify goals/constraints, while HWM handles hierarchical control and feasibility; language “decomposes” tasks into latent subgoals.
- Workflows: Natural-language-to-goal-image/state generation; joint planning with symbolic constraints.
- Dependencies/assumptions: Reliable grounding from language to goal states; constraint-satisfying planning; calibrated uncertainty.
- Edge-first, energy-efficient planning
- What: Leverage 3–4× planning compute reductions to run on embedded GPUs/accelerators in battery-powered platforms (AMRs, drones, service bots).
- Products: Onboard HWM runtime with adaptive compute budgets.
- Dependencies/assumptions: Further model compression; real-time schedulers; thermal and power budgets.
- Policy and standards — Explainability, data governance, and validation protocols for learned planners
- What: Subgoal logging and plan traceability as audit artifacts; benchmarks for zero-shot, long-horizon safety; guidance on large-scale trajectory data governance.
- Outputs: Certification checklists (subgoal reachability metrics, OOD tests), dataset documentation standards.
- Dependencies/assumptions: Cross-industry consensus; shared evaluation suites; acceptance of learned-model evidence in certification processes.
Glossary
- Action encoder: A learned module that compresses a sequence of low-level actions into a compact representation for high-level planning. "we further introduce a learned action encoder that compresses sequences of primitive actions between waypoint states into latent macro-actions."
- Autoregressive: Refers to predicting future states by repeatedly feeding previous predictions back into the model step-by-step. "including teacher-forcing and multi-step autoregressive rollout losses"
- CEM: The Cross-Entropy Method, a sampling-based optimizer used for planning by iteratively refining action distributions. "using 3000 CEM samples"
- Compounding prediction errors: The phenomenon where small model errors accumulate over multi-step rollouts, degrading long-horizon predictions. "Learned world models remain brittle when used for long-horizon planning due to compounding prediction errors"
- Cost-based optimization: Selecting actions by minimizing a defined cost (or energy) over predicted outcomes rather than learning a policy directly. "select actions through cost-based optimization, without requiring task-specific policy training"
- Curse of horizon: The exponential growth of the planning search space with increasing horizon length, making long-term planning computationally difficult. "the search tree grows exponentially with the branching factor and horizon (a manifestation of the curse of horizon)"
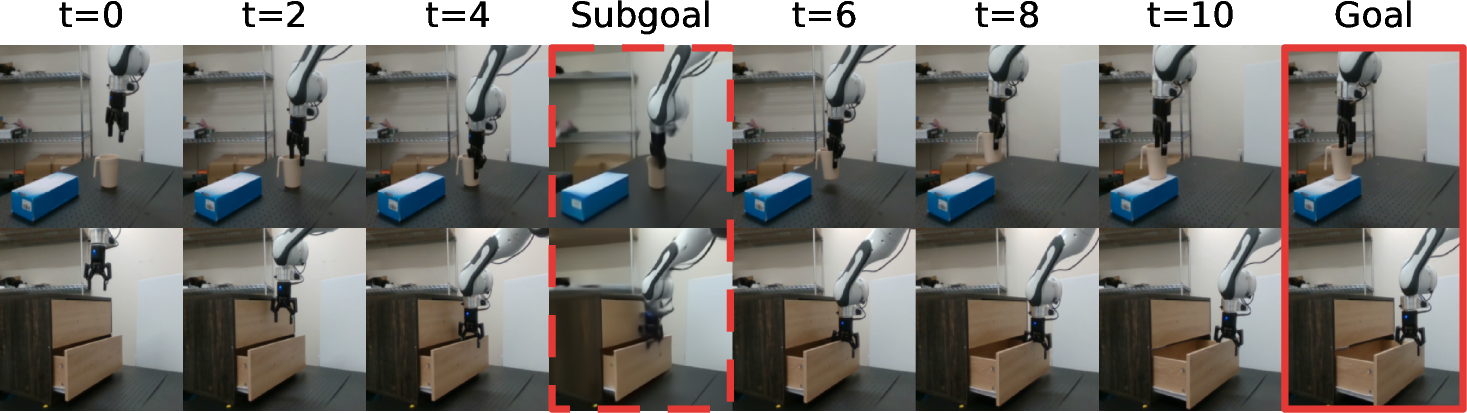
- Decoder reconstructions: Images decoded from latent representations to visualize or interpret predicted states. "others are decoder reconstructions shown for interpretability only."
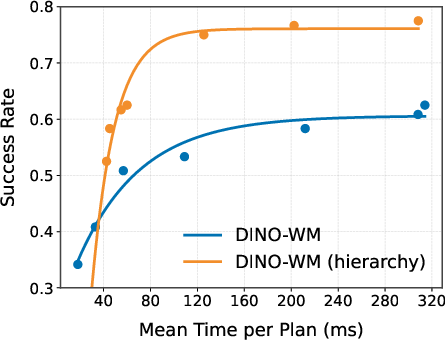
- DINO-WM: A specific latent world-model architecture used for vision-based control and planning. "We instantiate HWM on top of DINO-WM"
- End-effector: The robot’s terminal tool (e.g., gripper) whose pose or motion is commanded during manipulation. "end-effector delta poses"
- Energy function (goal-conditioned): A scalar objective measuring the discrepancy between predicted and goal states, minimized during planning. "goal-conditioned energy function in latent space:"
- GCIQL: A goal-conditioned offline RL algorithm baseline used for comparison in experiments. "offline goal-conditioned RL methods GCIQL and HIQL"
- Goal embedding: A latent representation of the goal observation used to guide high-level planning. "to reach the final goal embedding."
- Goal-conditioned policy: A policy that conditions on a specified goal to produce actions aimed at reaching it. "which induces a goal-conditioned policy."
- Hierarchical model predictive control (MPC): A control paradigm that plans at multiple temporal scales, coordinating high-level and low-level MPC. "the optimal control literature has explored hierarchical model predictive control (MPC) for multi-task settings"
- HILP: A zero-shot, unsupervised RL method used as a baseline in evaluations. "HILP \citep{park2024foundation}, a zero-shot unsupervised RL method."
- HIQL: A hierarchical offline RL algorithm baseline for goal-conditioned tasks. "offline goal-conditioned RL methods GCIQL and HIQL"
- Inverse kinematics: Computing joint-space commands that realize desired end-effector motions. "mapped to joints delta poses via inverse kinematics."
- Inverse models: Models that infer actions needed to transition between states (often inverse dynamics); avoided by the proposed approach. "This removes the need for inverse models, skill learning, or goal-conditioned policies"
- JEPA: Joint-Embedding Predictive Architecture; a style of predictive modeling used to train latent world models. "following prior work on JEPA-style predictive models"
- Latent actions: Compact, abstract action variables optimized by the high-level planner instead of raw primitives. "plan over a sequence of latent actions"
- Latent macro-actions: Latent representations summarizing variable-length sequences of low-level actions for long-horizon transitions. "latent macro-actions "
- Latent prediction loss: A training loss that encourages accurate prediction of future latent states. "trained with a latent prediction loss"
- Latent state: A compact feature representation of an observation used for dynamics modeling and planning. "An encoder maps observations to latent states "
- Latent world models: Predictive models operating in a learned latent space to forecast future states given actions. "latent world models learned from reward-free, task-agnostic offline data"
- Latent-state matching: Using similarity in latent space to align low-level plans with high-level subgoals. "via latent-state matching."
- Markov decision process (MDP): A formal framework for sequential decision making with states, actions, and transition dynamics. "We consider a Markov decision process (MDP)"
- Model predictive control (MPC): A planning approach that optimizes action sequences by repeatedly predicting and re-optimizing over a finite horizon. "Model predictive control (MPC) with learned world models has emerged as a promising paradigm"
- MPPI: Model Predictive Path Integral, a sampling-based planning method akin to CEM. "CEM/MPPI samples and iterations"
- MuJoCo: A physics engine used for simulating continuous-control tasks such as PointMaze navigation. "MuJoCo PointMaze environment"
- Non-greedy: Behaviors requiring intermediate moves that temporarily increase distance to the final goal. "These tasks require non-greedy behavior"
- Options: Temporally extended actions or skills in hierarchical RL that abstract low-level control. "including options, skills, and hierarchical policies"
- Oracle subgoals: Externally provided intermediate goal images used to simplify long-horizon tasks. "Oracle subgoals use externally provided subgoal images"
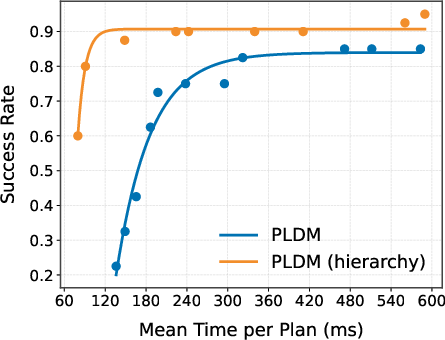
- Out-of-distribution (OOD) generalization: Performance on environments or tasks that differ from the training distribution. "OOD generalization: HWM improves PLDM performance on navigation in larger, unseen mazes."
- Proprioception: Internal sensory measurements (e.g., joint positions, velocities) used as observations for control. "end-effector proprioception"
- Receding-horizon: An MPC strategy that repeatedly optimizes over a moving finite window as new observations arrive. "repeating this process in a receding-horizon MPC manner."
- Teacher-forcing: A training technique that feeds ground-truth inputs to the model during sequence prediction. "including teacher-forcing and multi-step autoregressive rollout losses"
- Temporal abstraction: Structuring decision making at multiple time scales to simplify long-horizon control. "a large body of work on temporal abstraction in reinforcement learning"
- VJEPA2-AC: A specific latent world-model and planner used as a baseline for robotic manipulation tasks. "compared to 0\% for VJEPA2-AC"
- Vision–language–action (VLA) models: Multimodal models that map visual and language inputs to robot actions. "We additionally evaluate three vision–language-action models (VLA) baselines"
- Waypoint: An intermediate state along a trajectory used to structure high-level transitions. "Then the waypoint states are $(s_{t_1}, s_{t_2}, \dots, s_{t_{N-1}, s_{t_N})$."
- Zero-shot: Deploying a model on new tasks without task-specific training or fine-tuning. "allowing zero-shot deployment in downstream robotic control"
Collections
Sign up for free to add this paper to one or more collections.

