- The paper presents AdaGRPO which introduces a conditional RL loss gating mechanism to selectively apply reward updates based on reward model reliability.
- It demonstrates that stratified reward application improves HR@10 and controls hallucination, outperforming uniform GRPO methods in e-commerce recommendations.
- Empirical evaluations in both offline and online settings validate its robustness in balancing retrieval accuracy with effective reward maximization.
Adaptive Loss Balancing for Noise-Robust GRPO in Generative Recommendation
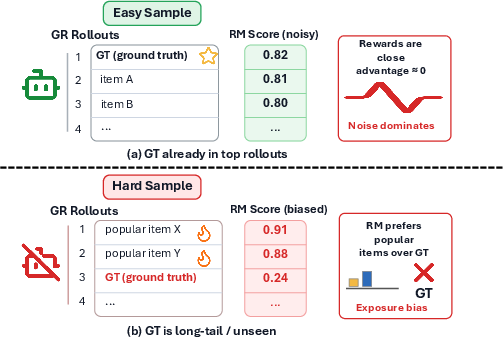
Generative Retrieval (GR) via autoregressive LLMs has emerged as a scalable alternative to embedding-based recall in industrial recommender systems, providing enhanced coverage for semantically similar and long-tail catalog items. However, the primary challenge for GR models is fine-grained discrimination, as these models lack dedicated per-item parameters and dense cross-feature input, making them inferior to the ranking stage in precision. Reinforcement learning (RL) using reward models (RM) has thus been proposed to align GR policies with high-value targets as scored by production rankers. Yet, RMs are trained on exposure-biased logs, rendering their reliability sample-dependent, especially for rarely exposed or fresh catalog items.
The central issue addressed in this paper is the mismatch between uniform application of reward-guided RL fine-tuning (particularly using the Group Relative Policy Optimization, GRPO, method) and the heterogeneity in RM trustworthiness across samples. Uniform RL pressure can lead to performance degradation by amplifying reward model noise or incentivizing the policy to move toward popular distractors when the RM is unreliable for certain regions of the item space.
Systematic analysis reveals two major pathological behaviors resulting from unselective reward propagation:
Conditional Utility of Reward Models
The paper presents a stratified analysis using beam search to rank tokens by LLM and RM order, measuring the influence of RM on ground-truth rank. Key findings:
- Aggregate RM influence is nearly zero or negative as beam width increases. As candidate set size grows, more out-of-distribution tokens are surfaced, reinforcing RM unreliability.
- RM helps only conditionally: On hard samples—where the policy is uncertain and the RM exhibits clean discriminability—the RM's influence becomes substantial (e.g., +11.41 ranks at K=50 hard instances), but this effect is diluted in aggregate metrics.
- Further conditioning on RM discriminability sharply increases per-sample RM influence but reduces coverage: Only the intersection of policy uncertainty and RM reliability justifies RL updates (e.g., nearly 60 rank improvement on K=128 samples, but coverage drops to approx. 13%).
AdaGRPO: Methodology
AdaGRPO reframes reward-guided optimization as selective admission rather than uniform pressure. Each training instance is anchored by supervised negative log-likelihood (NLL), but the GRPO term is gated via a binary clip determined by:
- Policy-side difficulty (f1): The instance is hard if the ground truth falls outside the top τ percentile of model rollouts.
- Reward-side discriminability (f2): RM reliably separates the ground truth (top τ) from in-batch distractors (bottom ρ).
The GRPO loss is admitted only if both diagnostics are satisfied. The resulting sample-level clip ensures RL updates occur only where the reward signal is locally informative.
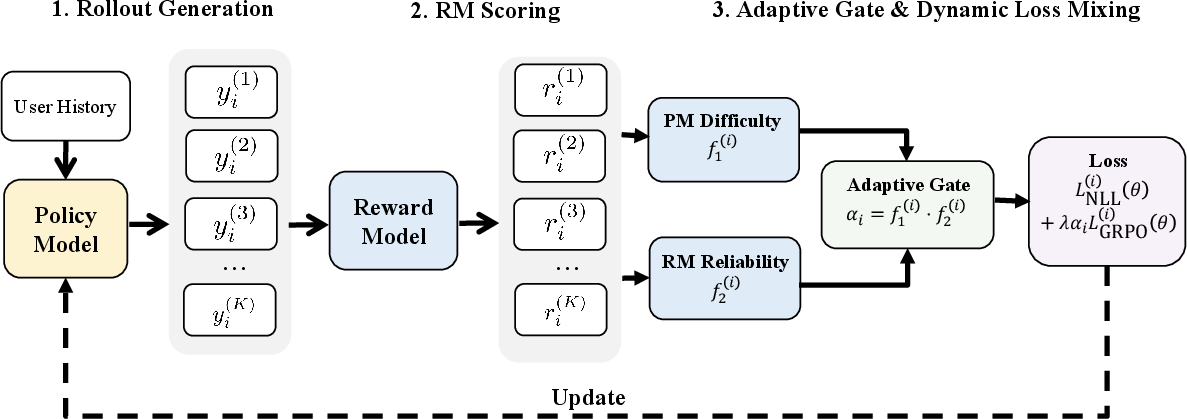
Figure 2: Overview of AdaGRPO: two rank-based diagnostics gate the GRPO objective per instance; only trusted samples contribute RL updates.
Design properties include interpretable, binary per-instance admission, scalability in rollout group size, and robustness to reward model quality. The scheme leverages rollout statistics directly, requiring no auxiliary models or external heuristics.
Empirical Evaluation
Offline Results
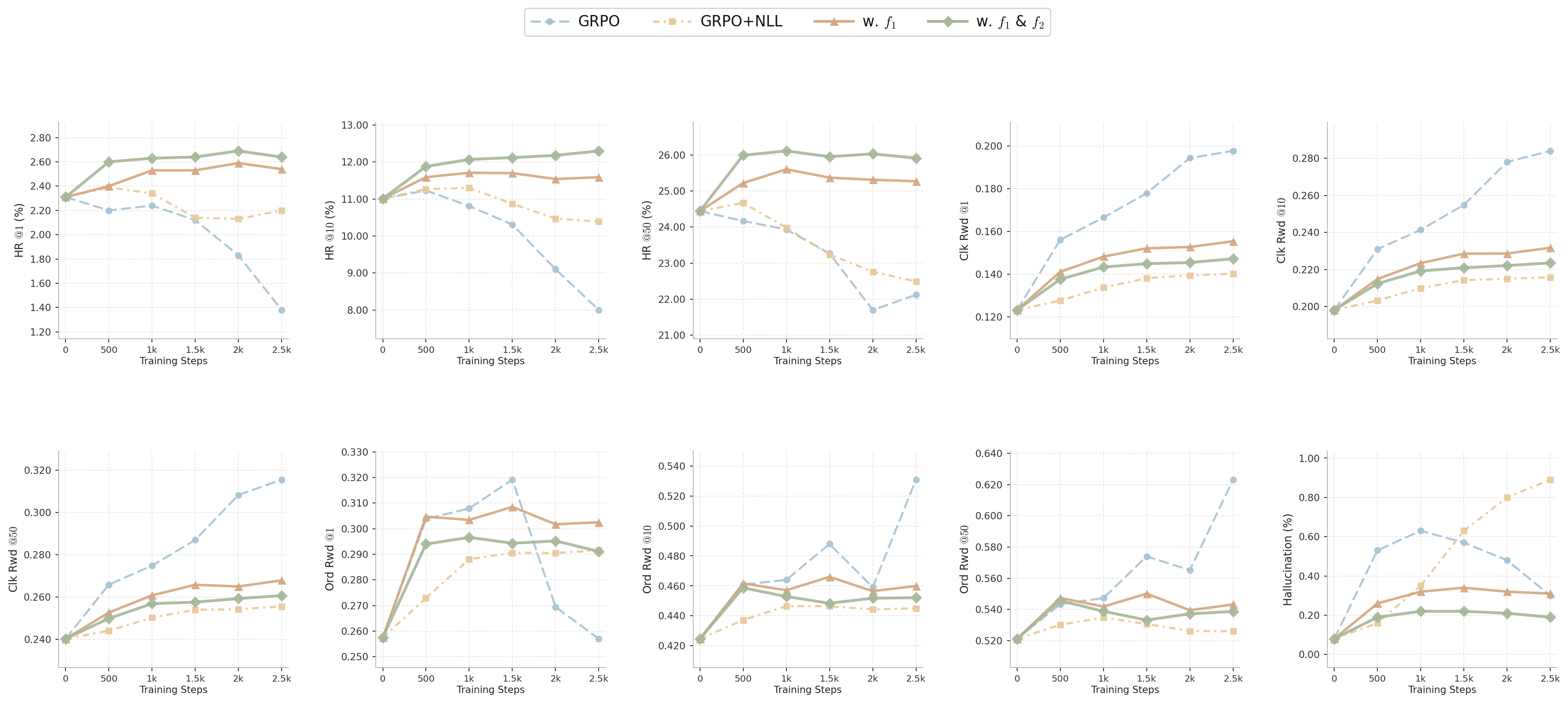
AdaGRPO was evaluated on a 175K e-commerce user-item sequence dataset (one-week window). Baseline GRPO and hybrid GRPO+NLL models suffer increasing hallucination and retrieval degradation at late training checkpoints due to reward overoptimization. AdaGRPO, by contrast, achieves:
Difficulty-stratified analysis confirms AdaGRPO’s gain is concentrated in intermediate-difficulty samples, with negligible or negative change for easiest (already confident) and hardest (reward model unreliable) cases.
Online A/B Testing
Production A/B deployment validates AdaGRPO’s practical utility:
- Statistically significant gains in effective Item Page Views (IPV), click-through rate (UCTR), and dwell time compared to control and GRPO+NLL baselines.
- AdaGRPO expands exposed and clicked category diversity, indicating robust coverage rather than collapse to reward-favored items.
- Demonstrates sample-level clipping yields improvements not merely in offline metrics but in real user engagement.
Implications and Future Directions
AdaGRPO’s contributions lie in operationalizing conditional trust for reward models in generative recommendation RL alignment. Results suggest:
- The main challenge in RL tuning of GR models is not reward design, but detection of local RM reliability.
- Sample-wise adaptivity can substantially improve trade-offs between retrieval accuracy, validity, and reward maximization, preventing reward hacking and mode collapse observed in uniform RL protocols.
- Methodology is robust and hyperparameter-lean, relying on rollout statistics and interpretable rank-based diagnostics.
Theoretical implications extend to RL alignment in sparse-feedback, exposure-biased domains beyond recommendation. Practically, scalable deployment requires further validation under long-term concept drift, larger/longer training windows, and more varied catalog freshness regimes. Future research should address dynamic tuning of clipping thresholds, generalize diagnostics for domains with less clear ground-truth structure, and explore the effect of batch composition on reward-side reliability checks.
Conclusion
AdaGRPO introduces a principled, sample-level trust-region mechanism for RL fine-tuning of generative recommenders, anchored on supervised NLL and gated GRPO reward admission. Empirical results demonstrate significant improvements in retrieval, minimized hallucination, and enhanced user engagement, thereby affirming that selective recognition of reward model reliability is key to robust RL-based alignment in generative recommendation systems (2606.08480).