- The paper introduces AdaGRPO which adapts curriculum filtering to match the model's evolving capability in flow-based generative tasks.
- It integrates cross-level advantage fusion to combine local and global signals, yielding unbiased policy updates without relying on value networks.
- Extensive experiments confirm improvements in training stability, visual fidelity, and alignment with human feedback over existing GRPO methods.
AdaGRPO: Capability-Aware Adaptive Enhancement for Flow-Based GRPO
Motivation and Problem Identification
The alignment of text-to-image (T2I) generative models with human preferences remains a pivotal challenge in controllable generation. Flow-based models have become state-of-the-art for high-fidelity content synthesis; however, their generative process, even after extensive pretraining, exhibits persistent misalignment with user intents, especially for complex or nuanced prompts. Reinforcement Learning from Human Feedback (RLHF) has become a preferred alignment mechanism, with Group Relative Policy Optimization (GRPO) offering a value-network-free approach that uses intra-group sample comparisons for policy updates.
Despite the recent adaptation of GRPO for flow models, such as Flow-GRPO and DanceGRPO, critical limitations persist. Existing pipelines sample prompts randomly without regard to the learner's evolving capabilities, leading to exposure to either too-easy or too-hard tasks and introducing high variance or under-informative updates. Furthermore, advantage estimation is performed using only intra-group statistics, lacking a global reference and resulting in myopic, locally biased credit assignments that do not capture genuine policy progression. This structural decoupling yields instability and hinders the optimal alignment efficacy of flow-based models.

Figure 1: AdaGRPO consistently improves generation quality, especially for intricate textures and compositional fidelity, over baseline Flow-GRPO implementations.
AdaGRPO: Methodological Advancements
AdaGRPO introduces two orthogonal, lightweight components that remedy both prompt selection and advantage estimation:
Online Curriculum Filtering Strategy
Rather than random prompt selection, AdaGRPO incorporates a curriculum-inspired, capability-aware filtering mechanism. At each iteration, a batch of candidate prompts is scored via deterministic ODE rollouts, and the model's proficiency is dynamically anchored by an exponential moving average (EMA) of historical rewards. The prompt whose reward most closely matches this global capability anchor is selected, ensuring that the task presented is at the model's evolving learning boundary. This approach stabilizes reward variance and mitigates the inefficiency of local median heuristics, which can be biased by the candidate batch distribution.
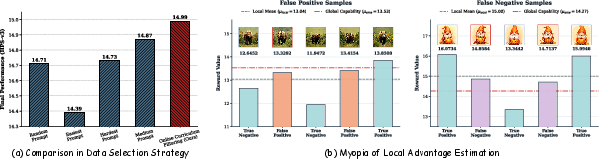
Figure 2: Online Curriculum Filtering dynamically identifies tasks matched to the global capability anchor, avoiding the pitfalls of local-only or extreme sampling.
Cross-Level Advantage Fusion
To resolve the myopia of intra-group comparison, AdaGRPO introduces a dual-stage estimation process. The local advantage is computed within the group, while the global advantage leverages the EMA baseline to gauge absolute progression. To reconcile these signals, AdaGRPO performs a conditional, sign-preserving normalization ensuring a zero-mean global advantage while preserving progression directionality. The fused advantage aggregates both local and global signals before policy update, yielding unbiased and robust gradient estimation aligned with true model enhancements.
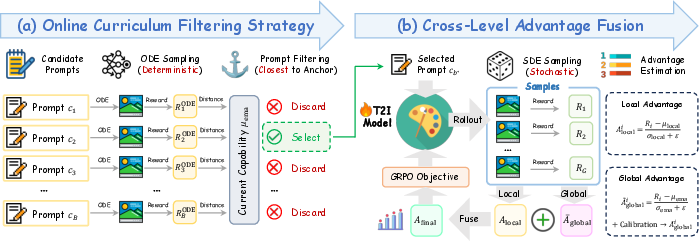
Figure 3: AdaGRPO’s pipeline: curriculum filtering evaluates candidate prompts against the EMA anchor; Cross-Level Advantage Fusion integrates unbiased global and local advantages for robust policy optimization.
Experimental Validation
Extensive experimentation demonstrates the architecture-agnostic applicability and efficacy of AdaGRPO:
- Quantitative benchmarks on Flux.1-dev and three flow-based GRPO frameworks (Flow-GRPO, DanceGRPO, Flow-CPS) consistently show substantial performance improvements. AdaGRPO yields the best or near-best results on HPS-v2/v3, Coherence, Style, and ImageReward metrics under both single- and multi-reward configurations.
- Training reward curves indicate smoother learning dynamics and higher performance ceilings, with AdaGRPO improving stability and convergence speed (see Figure 4).
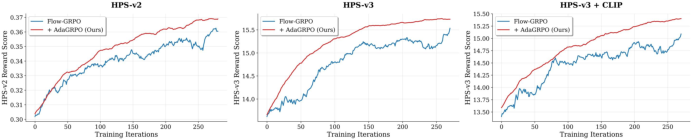
Figure 4: AdaGRPO stabilizes and accelerates training reward dynamics across paradigms.
- Qualitative comparison (Figures 5–6) further corroborates that AdaGRPO achieves superior visual fidelity, semantic adherence, and compositional alignment compared to GRPO baselines. Improvements manifest in natural texture rendering, complex compositional understanding (e.g., accurate spatial relations with mirrors, action scenes), and intricate detailing (e.g., material reflections, fine lighting gradients).

Figure 5: AdaGRPO delivers improved image quality and prompt adherence versus strong baselines (HPS-v2).

Figure 6: On challenging HPS-v3 prompts, AdaGRPO produces richer details and robust alignment.
- Ablation studies confirm that both the adaptive curriculum filter and cross-level fusion are critical for optimal performance. The curriculum filter's batch size and momentum coefficient control the trade-off between responsiveness and historical stability, while cross-level advantage fusion is necessary to avoid local-optimum traps.
Theoretical and Practical Implications
AdaGRPO is the first work to systematically introduce dynamic data selection, based on curriculum learning principles, to flow-based GRPO alignment. The explicit modeling of current learner capability allows for optimally challenging tasks, drawing from pedagogical concepts such as the "zone of proximal development." This context-sensitive data selection can be extended to other RL-aligned vision or multimodal tasks, especially where training resource constraints and stability are essential.
Integrating cross-level advantage calibration addresses underexplored issues in policy gradient estimation for value-network-free RL frameworks, indicating broader applicability in alignment protocols beyond vision or T2I. The practical implication is that AdaGRPO can be plugged into any GRPO-capable framework with minimal code changes, immediately improving preference alignment, sample quality, and robustness of training.
Future Directions
The work indicates two promising research threads:
- Efficient and scalable curriculum filtering, for example by leveraging quantized lightweight models during prompt selection phase to further reduce overhead.
- Extending the cross-level advantage approach to RL frameworks with more complex, multidimensional reward landscapes or multi-modal context, where local and global reward statistics vary on separate factors.
The main limitation is the added computational cost of performing ODE-based profiling for each candidate batch, though empirical evidence suggests that with moderate batch sizes and parallelization, the overhead is manageable.
Conclusion
AdaGRPO delivers a principled, capability-aware RL enhancement for flow-based GRPO, resolving both prompt selection and advantage estimation deficiencies inherent in earlier frameworks. Its curriculum-inspired filter and unbiased cross-level fusion yield consistent improvements in alignment stability, sample quality, and applicability across GRPO architectures. AdaGRPO establishes new standards for data-aware RL alignment in visual generation and motivates broader exploration of curriculum-based adaptive data selection and multi-level policy evaluation for RL with human feedback (2606.06828).

