- The paper presents a ProRL framework that uses Stepwise Reward Centering and Position-Specific Advantage Estimation to eliminate path length shortcut and reduce gradient variance.
- It addresses the issues of amplified path rewards and unstable gradients by aligning policy updates with targeted multi-step recommendation quality.
- Empirical validations on multiple datasets confirm ProRL’s significant improvements in engagement metrics and guidance effectiveness over traditional methods.
ProRL: Rectified Policy Gradient Estimation for Proactive Recommendation
Proactive Recommendation Systems (PRSs) extend traditional recommender paradigms by focusing not merely on passive reflection of user preferences, but on the strategic guidance of users toward platform-specified target items. Instead of abrupt, unfamiliar item injection, PRS constructs multi-step recommendation paths that transition user interests, maximizing both intermediate engagement (feasibility) and eventual target acceptance (effectiveness). This necessitates joint optimization over (1) path feasibility—the acceptance probability for each intermediate item—and (2) guidance effectiveness—the likelihood of target acceptance after traversing the path.
The system is formalized as follows: given a user’s interaction history Su and a target item iT, generate an ordered path Lu=(i1,...,iL), where L≤Lmax. Path rewards are quantified via Increment of Interest (IoI), Increment of Rank (IoR), and Click-Through Rate (CTR). The objective is to learn a policy πθ that maximizes a weighted sum of these metrics:
Rpath=α⋅IoI+β⋅IoR+γ⋅CTR

Figure 1: A toy example of proactive recommendation, demonstrating gradual genre blending (Sci-Fi → Comedy) across intermediate steps to maintain user engagement.
Deficiencies of Standard Policy Gradient in PRS
Direct application of classic policy gradient (e.g., REINFORCE) to PRS leads to systematic path degeneracy. Empirical analysis reveals two critical deficiencies:
Length Shortcut: Path-level rewards in PRS decompose into step-level rewards with positive mean (E[rt]>0). As a consequence, longer paths yield higher expected cumulative rewards irrespective of actual guidance quality. During optimization, this drives policy to repeatedly extend paths, saturating at Lmax, and converging to globally suboptimal, homogeneous recommendations.
High Gradient Variance: Each step’s gradient is weighted by the total path reward. Given reward decomposition, this uniform treatment introduces irrelevant noise—early steps’ gradients are driven by rewards unaffected by their corresponding actions, inflating variance and destabilizing learning.
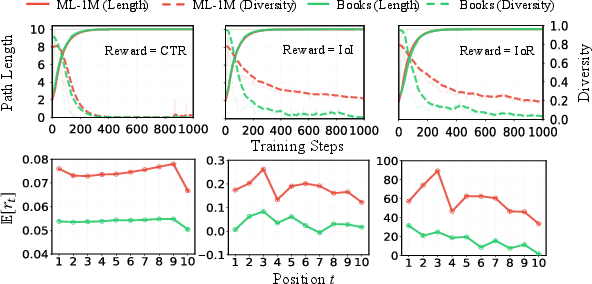
Figure 2: Standard policy gradient estimation dynamics showing rapid path length inflation and diversity collapse (top), driven by consistently positive expected step-level reward (bottom).
These phenomena are rooted in the reward structure—not tuning artifacts—and are proven to yield monotonic collapse of stopping probability under gradient flow, with path length converging to Lmax at rate O(1/s).
ProRL Framework: Rectified Policy Gradient Estimation
ProRL introduces two task-specialized mechanisms:
Stepwise Reward Centering (SRC): Subtracts a global expected step reward iT0 from each iT1, producing iT2. This rectification ensures that path extension yields zero expected gain, eliminating the length shortcut and forcing optimization to focus exclusively on path quality.
Position-Specific Advantage Estimation (PSAE): Computes reward-to-go iT3 for each step and adapts baselines to position-specific expectations (iT4). The resulting advantage estimator iT5 delivers unbiased, low-variance gradient signals, tightly tracking the relevant future rewards per position.
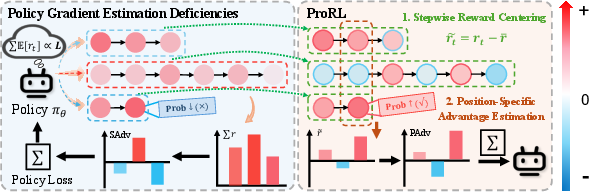
Figure 3: ProRL architecture. Left: Standard policy gradients suffer from length shortcut and high variance. Right: ProRL applies SRC and PSAE for robust optimization of path quality.
Empirical Validation and Ablation
Comprehensive experiments on MovieLens-1M, Steam, and Amazon-Book corroborate the superiority of ProRL. Across all metrics—IoI, IoR, CTR, and Coherence—ProRL outperforms both classical sequential recommenders and state-of-the-art proactive strategies (including LLM-based agents), achieving statistically significant improvements.
Notably, ProRL maintains high Coherence despite it not being directly rewarded, indicating robust semantic generalization rather than reward overfitting.
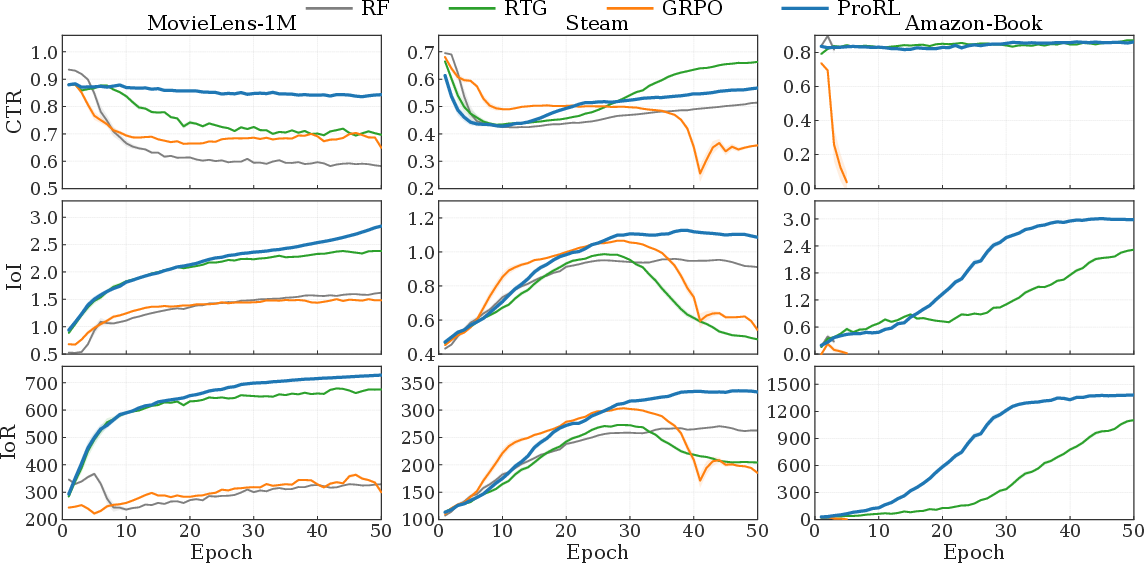
Figure 4: Training dynamics of gradient estimators on multiple datasets highlighting ProRL's superior stability and metric convergence compared to baselines.
Ablations confirm the individual necessity of SRC (removal leads to pathological path extension and feasibility bias) and PSAE (removal increases variance and destabilizes path length evolution). Multi-objective reward design proves essential, with each component synergistically improving both feasibility and guidance quality. Comparisons with alternative estimators (RF, RTG, GRPO, A2C) show that ProRL's analytic baseline and per-step reward structuring uniquely prevent collapse and maximize guidance efficacy.
Analysis of Training Stages and Robustness
Rollout analysis reveals that strong supervised pretraining is a prerequisite; RL acts as a probability rectifier, redistributing policy mass from low-probability, high-quality tail paths discovered during exploration. Robustness tests across varying target accessibility (random versus filtered selection) demonstrate that ProRL consistently dominates baselines, preserving engagement and maximizing guidance regardless of intervention difficulty.
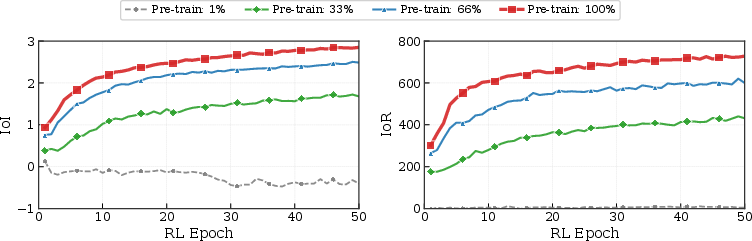
Figure 5: The effect of pretraining maturity on RL efficiency, confirming the necessity of a sufficiently converged semantic prior for effective reward optimization.
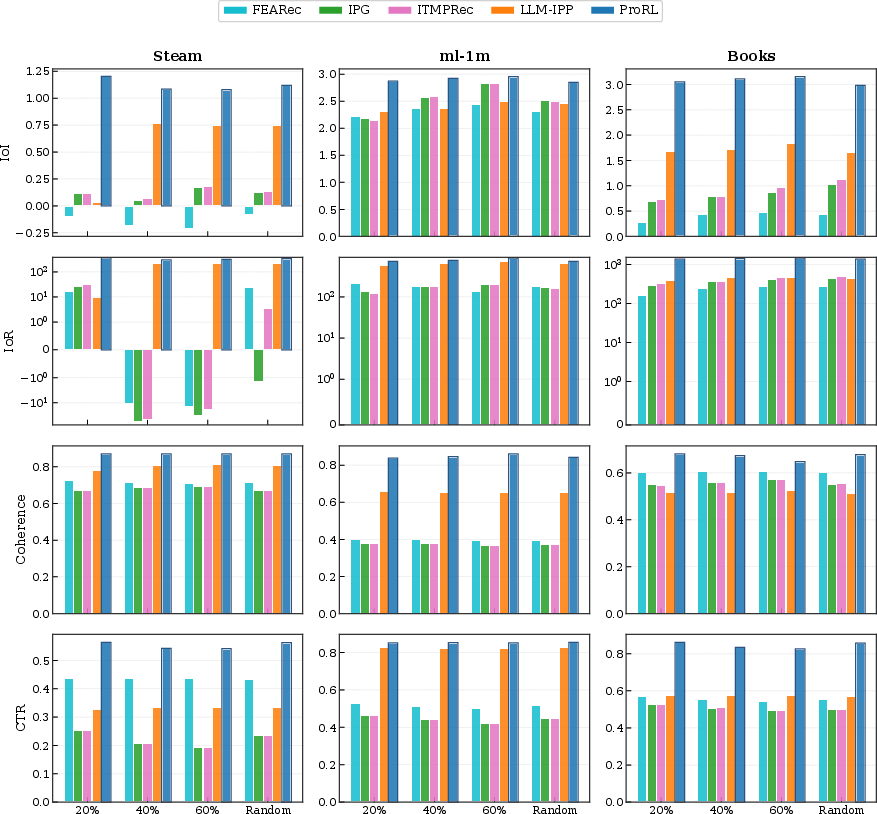
Figure 6: Robustness analysis across varying target selection schemes and guidance difficulties, with ProRL maintaining dominance across CTR, Coherence, IoI, and IoR.
Sensitivity analysis further establishes that manual offset tuning for reward centering is highly unstable, with narrow effective regions leading to either overlong or collapsed paths—whereas ProRL’s data-driven SRC achieves robust length moderation without manual tuning.
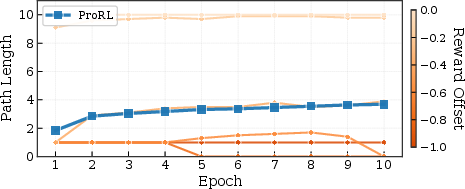
Figure 7: Offset sensitivity analysis showing path length instability under manual offset tuning; ProRL’s SRC stabilizes learning automatically.
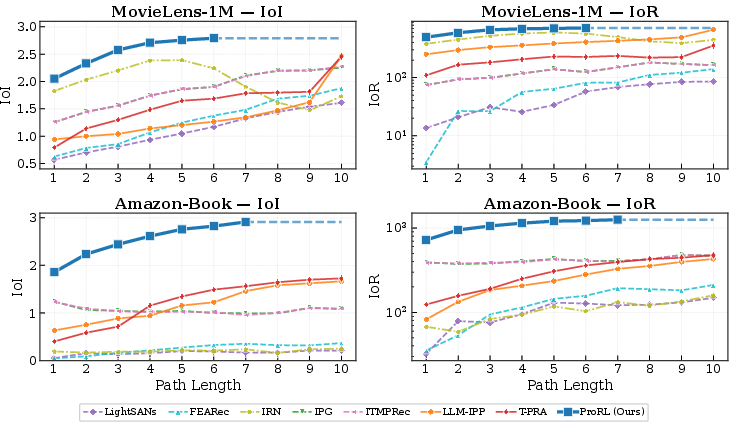
Figure 8: Performance comparison across varying path lengths, demonstrating ProRL's superiority in decision quality per step.
Theoretical and Practical Implications
Theoretically, ProRL’s rectifications provide unbiased gradient targeting precisely the path quality, with analytic variance reduction achieved through position-specific advantage estimation, obviating the need for learned critics prone to drift. This aligns RL optimization with PRS’s structural reward decomposition, and avoids global policy collapse.
Practically, ProRL empowers deployment of lightweight transformer-based models for industrial-scale proactive recommendation, circumventing the prohibitive cost and impracticality of LLM-based planners. The learned strategy generalizes across unseen evaluative models, indicating genuine discovery of transferable guiding principles.
Future Directions
ProRL’s methodology opens several avenues for future research:
- Extension to multimodal recommendation paths with heterogeneous item representations.
- Integration of real-time online user feedback for dynamic reward adaptation.
- Fine-grained control and explanation of guidance strategies via explicit attribute-level constraints.
- Application to long-term interest shaping and mitigation of filter bubble effects in recommender platforms.
Conclusion
ProRL establishes an effective RL framework for proactive recommendation by addressing critical deficiencies in policy gradient estimation: length shortcut and gradient variance. With Stepwise Reward Centering and Position-Specific Advantage Estimation, ProRL achieves robust, transferable optimization of path feasibility and guidance effectiveness. Empirical and theoretical analyses confirm its superiority and stability, setting a strong foundation for future proactive guidance architectures in recommender systems.