- The paper introduces a dual-path framework that decouples identity and block attention residuals, efficiently preserving gradient flow and enabling soft forgetting.
- Experimental results on an industrial dataset show a +0.32% AUC and +0.53% GAUC improvement over state-of-the-art baselines with minimal compute overhead.
- The study provides both theoretical and empirical insights on scaling behavior and layer-wise fusion, emphasizing the role of SiLU-based pointwise attention in CTR prediction.
DeRes: Decoupling Residual Stability and Adaptivity for Scalable CTR Prediction
Introduction and Motivation
The paper "DeRes: Decoupling Residual Stability and Adaptivity for Scalable CTR Prediction" (2606.07980) targets a fundamental limitation in contemporary Transformer-based CTR models: the inadequacy of standard residual connections for information propagation and selective forgetting as networks scale in depth. Current Pre-Norm residuals preserve gradient flow but suffer from three critical drawbacks in the CTR setting: progressive dilution of early signals, indiscriminate preservation of outdated information, and limited inter-layer context. Previous proposals for LLMs such as AttnRes, DenseFormer, and mHC offer partial solutions but neglect identity path protection and are untested on CTR data with its heterogeneity and shallow depth.
The DeRes framework advances this space by introducing a dual-path inter-layer connector. It integrates a stable identity residual path for low-order feature reuse and gradient preservation with a block-wise attention residual path for dynamic high-order recall over earlier layers, synthesized via a vector-wise gate. The novel Pointwise AttnRes replaces Softmax normalization with SiLU activation to mitigate the limitations of competitive layer selection, enhancing multi-interest encoding and introducing architectural mechanisms for soft forgetting.
DeRes Architecture
DeRes instantiates an explicit dual-path connector for each layer, depicted schematically in the system architecture and single-layer diagrams.
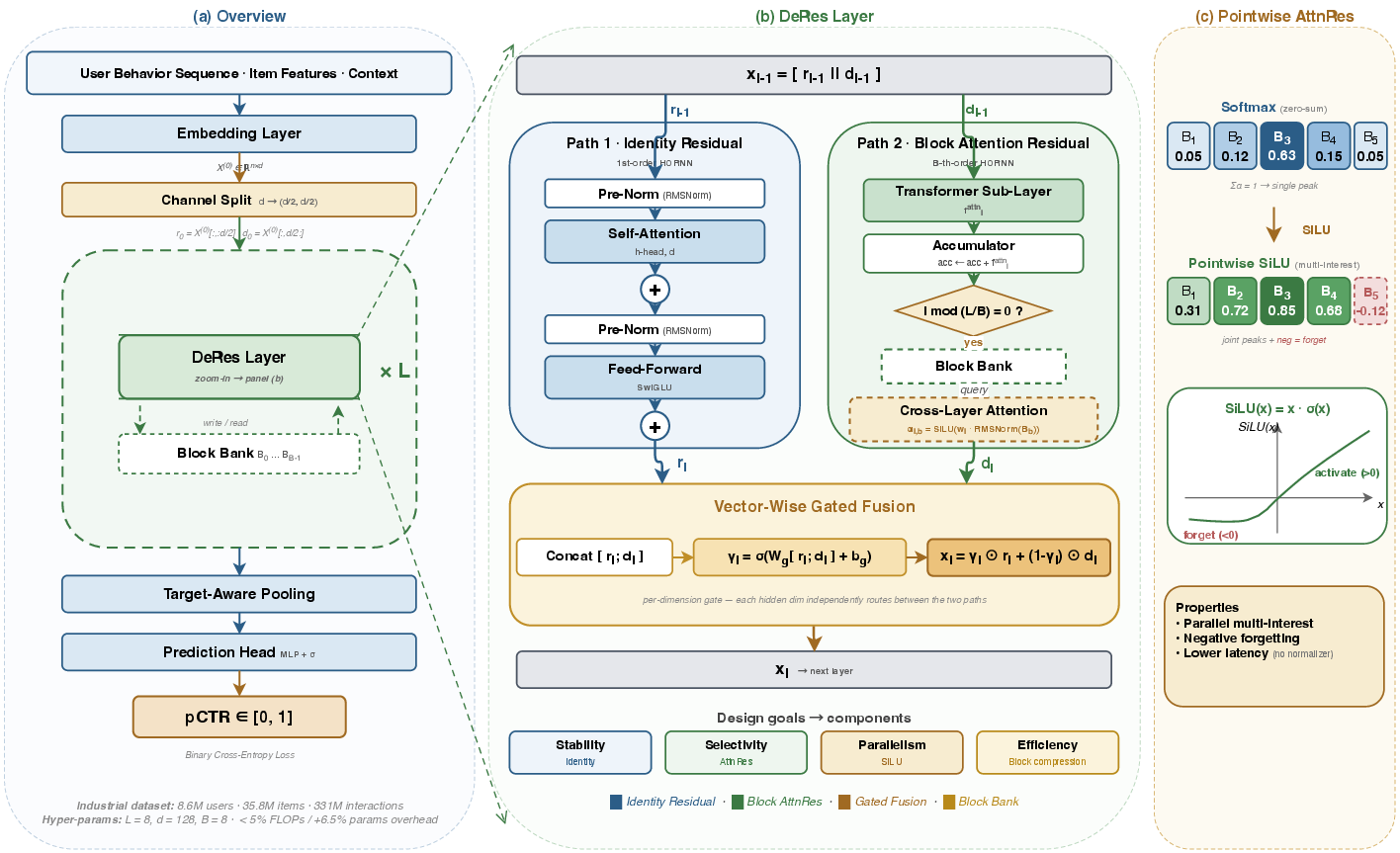
Figure 1: DeRes architecture: (a) CTR pipeline integrating DeRes; (b) dual-path residual mechanism with identity and block-attention paths fused by a vector-wise gate; (c) SiLU-based pointwise attention vs. Softmax.
The Identity path (Path 1) maintains fixed skip weights, enforcing direct propagation akin to HORNN's first-order recurrence and ensuring non-attenuating gradient flow through depth. This analytically circumvents the exponential decay in signal observed with learned residual matrices (as formalized in the cumulative singular value analysis and substantiated by empirical path ablations).
The Block Attention path (Path 2) divides the L network layers into B blocks. Each block accumulates compressed states from its constituent layers. At each forward pass, a static, trainable query vector produces similarity scores against all previous block summaries, normalized via SiLU rather than Softmax. This block-wise structure is computationally efficient (scaling as O(Bd) per layer) and empirically optimal at intermediate granularity (B=8).
Gated fusion is performed per hidden dimension via parameterized sigmoidal gating, enabling dynamic and sparse selection between stability (Path 1) and high-order adaptivity (Path 2) on a feature-wise basis. Theoretical and empirical evidence shows strict representational superiority for this dual-path gating over either single-path architecture, as well as over shallow fusions (e.g., addition).
Pointwise AttnRes: SiLU-based Cross-layer Attention and Its Implications
AttnRes originally employed Softmax normalization, but Pointwise AttnRes replaces this with SiLU to better match the CTR scenario. SiLU allows multiple blocks to be simultaneously salient and supports negative attention weights, enabling explicit suppression of irrelevant historical states (soft forgetting). The ablation studies confirm that SiLU substantially improves over Softmax and alternatives (e.g., Sigmoid, ReLU) for CTR, with gains compounding in the presence of multi-interest user behavior. This design decisively addresses the parallel encoding requirement—the primary inductive mismatch in transferring LLM residual techniques to CTR.
Numerical Results and Comparative Evaluation
On an industrial recommendation dataset (330M+ interactions), DeRes-P (Pointwise) achieves a notable +0.32% AUC and +0.53% GAUC improvement over TokenMixer-Large, the strongest baseline, with a marginal compute cost (< 5% extra FLOPs and +6.5% parameters). These deltas are highly significant in industrial ranking systems, translating to actionable online effect sizes.
Further, DeRes exhibits a steeper compute–AUC scaling law than alternatives. The fitted exponent γ=0.118 for DeRes far exceeds OneTrans (γ=0.071), conferring 1.66× greater efficiency and allowing an 8-layer DeRes to match the AUC of a 16-layer OneTrans (~2× compute savings at iso-quality).
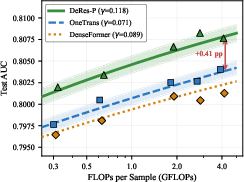
Figure 3: Scaling law on the Industrial dataset: DeRes achieves both higher ceiling and dramatically improved scaling efficiency across compute budgets.
In analysis by data slice, the advantage of DeRes systematically increases:
- With sequence length: as cap increases from 200 to 2000, DeRes outpaces OneTrans by +0.49% AUC.
- With model depth: scaling from 4 to 16 layers, the relative gain rises steadily and DeRes avoids the saturation observable in fixed-residual baselines.
- With user behavior/activity: longer-history users benefit disproportionately, a trend matched for cold-start and tail items.
Ablations demonstrate that (i) dual-path is superior to single-path, (ii) identity skip outperforms learnable alternatives, (iii) SiLU attention dominates Softmax, and (iv) vector-wise gating is essential for effective specialization.
Interpretability and Mechanistic Insights
DeRes's interpretability analysis exposes:
- Cross-layer attention heatmaps reveal a pronounced diagonal, indicating dominant local recall, yet with persistent high attention on early blocks from later layers (highlighted region).
- SiLU activation enables functional forgetting: the distribution of negative attention weights is concentrated at obsolete blocks in deeper layers, supporting robust suppression of outdated signals.
- The gating mechanism learns layer-wise specialization: importance shifts from identity in shallow layers (initial γ≈0.68) to attention in deep layers (B0) with feature-level heterogeneity.
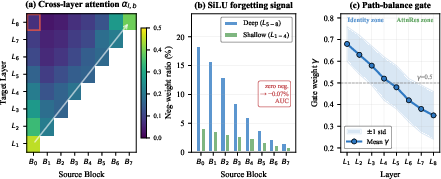
Figure 4: (a) Heatmap of cross-layer attention; (b) negative-valued SiLU weights indicate active suppression by deep layers; (c) learned gate coefficients diminish with depth, evidencing informed fusion.
Theoretical Implications and Broader Consequences
The dual-path design is rigorously underpinned by the HORNN framework, and its contribution to representational capacity and stability is formalized through propositions on functional set strict containment and singular value decay (bypassed by fixed identity paths). The scaling law improvement is consistent with recent learning-theoretic analyses (e.g., Rademacher bounds indicating feature field explosion as the dominant complexity axis in CTR).
Practically, DeRes is architecturally modular: it can be integrated into any backbone supporting residual connections, with hyperparameters (block granularity, gating dimensionality) controllable for deployment–efficiency tradeoff. As it does not require changes to candidate generation or feature specification, migration cost is minimal. The observed scaling behavior suggests robust generalization across feature-rich domains where high-capacity inter-layer routing is essential.
The theoretical separation in representational power (gated sum of identity and block-attention) is likely to inspire future hybrid topologies for other data modalities struggling with similar propagation/forgetting tradeoffs, such as session-based recommendation, context-aware ranking, or temporal relational modeling.
Limitations and Future Directions
Potential limitations include optimal block granularity selection (data- and depth-dependent), partial reliance on pre-fused multimodal embeddings (not explicitly end-to-end), exclusive focus on pointwise CTR (not multi-task/multistage), and anchoring to Pre-Norm architecture (not verified for Post-Norm). While SiLU is empirically optimal among common activations, no constructive proof exists for its uniqueness.
Future work may extend dual-path principles to multi-task ranking, dynamic block aggregation, or adaptive path reparameterization, as well as formal universality results for pointwise attention activations under multi-interest data distributions.
Conclusion
DeRes advances the state of the art in Transformer-based CTR prediction by decoupling residual stability and adaptivity. Its dual-path architecture, block-wise attention with SiLU activation, and vector-wise gated fusion all contribute to robust, scalable, and more expressive inter-layer information processing. This enables significant improvements in AUC at industrial scale and unlocks favorable scaling laws, all within tight budget constraints. The architectural prescriptions and mechanistic findings presented are poised for immediate adoption in real-world CTR systems and for extension to related high-cardinality, multi-interest domains.

