Evidence Markets
Abstract: Modern prediction markets face two limitations that restrict their applicability in a range of settings:~(i)~they reveal what the crowd believes but not the evidence or reasoning behind those beliefs, and~(ii)~they require an event with an external ground truth that resolves at a known future date. We address these twin challenges by introducing evidence markets, a generalization of prediction markets that incentivizes the submission of evidence alongside beliefs and can be endogenously resolved using the crowd-sourced evidence if external resolution is not possible. At its core, the market uses a logarithmic market scoring rule whose liquidity parameter changes dynamically with the accumulated evidence quality. We prove that platform loss is bounded, evidence is rewarded proportional to the current market uncertainty, and can be equivalently implemented through an automated market maker. In the case where the marker resolves endogenously based on submitted evidence, we characterize how withholding evidence shifts a trader's belief about resolution and use it to prove truthful belief and evidence reporting is a always an $\varepsilon$-dominant strategy incentive compatible (DSIC) strategy. To address operational considerations, we propose evidence verification via an LLM-as-a-Judge framework with staking and give an asynchronous execution algorithm that is not bottle-necked by verification. Throughout the work, we use LLM evaluations -- determining which model is best for a given task -- as a salient and representative running example for our proposed market.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language explanation of “Evidence Markets”
1) What is this paper about?
This paper introduces a new kind of prediction market called an evidence market. Regular prediction markets tell you what people think will happen (like “there’s a 70% chance Team A wins”), but they don’t tell you why people think that. Also, they only work well for events that will definitely be resolved in the future (like an election result).
Evidence markets fix both problems at once:
- They encourage people not only to share their predictions, but also to share the evidence behind those predictions.
- When there’s no clear future “true answer” (like “Which AI model is better at creative writing?”), the market can resolve itself using the evidence people submit.
The authors use evaluating LLMs as their main example: people can bet on which model is better and submit test questions and answers as evidence to decide the winner.
2) What questions are the authors trying to answer?
In simple terms, the paper asks:
- How can we build a market that shows both what people believe and why they believe it?
- How can we resolve questions that don’t have a fixed, future, real‑world answer by using the crowd’s evidence instead?
- Can we design rewards so that people:
- tell the truth about their beliefs,
- submit all the useful evidence they have, and
- don’t cause the platform (the market host) to lose unbounded amounts of money?
3) How do they approach the problem?
To explain the approach, think of a classroom debate with a scoreboard:
- In a normal prediction market, students raise their hands to vote on which side they think will win. The scoreboard shows the current odds, but nobody sees the sources or reasons.
- In an evidence market, students can still vote—but they can also submit their sources (evidence). The scoreboard updates both based on votes and on how strong the submitted evidence is.
Key ideas, explained with everyday language:
- Dynamic scoring (LMSR): The market uses a well-known “scoring rule” (like a fair point system) that encourages honest predictions. The twist is that the “sensitivity” of the scoreboard changes depending on how much good evidence the market has collected. More good evidence means the system becomes more stable and less easy to sway by a single bet.
- Evidence quality: The market measures the total quality of all the evidence submitted so far (think: how relevant, non-duplicative, and well-verified the evidence is). The better the evidence pool, the more confident the market becomes.
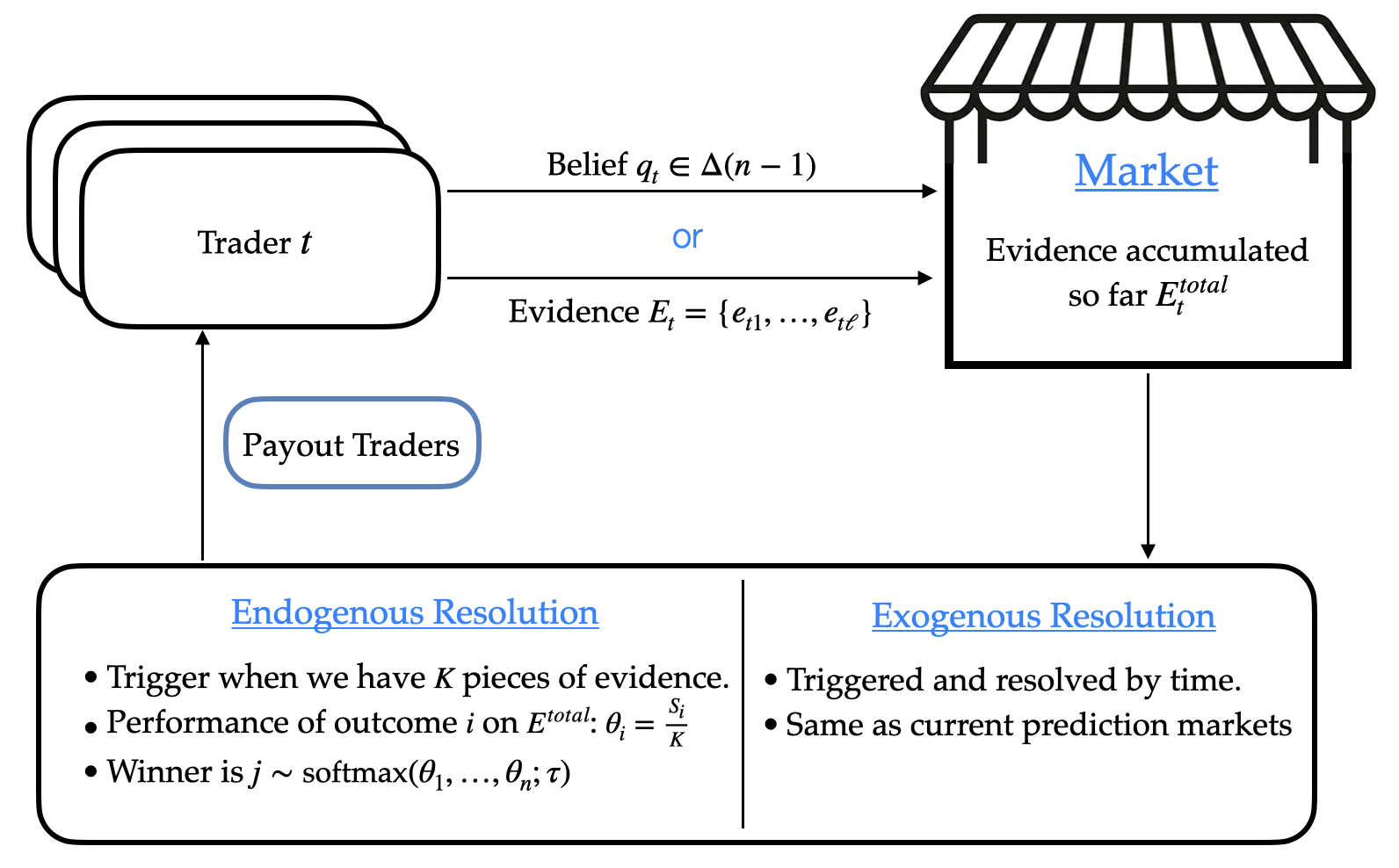
- Endogenous resolution (resolving from within): If there’s no clear real-world outcome (like “best LLM”), the market waits until it collects K pieces of evidence, then uses those to decide a winner. Imagine tallying how much each pile of evidence supports each option, then rolling a weighted die where better-supported options are more likely to be picked. A temperature setting controls how sharply that weighted die favors the leading option—higher temperature makes the roll “softer,” reducing the benefit of gaming the system.
- Limiting manipulation: What if someone hides part of their evidence to boost their payoff? The authors show that by choosing the right temperature and requiring enough total evidence (big K), the benefit of hiding evidence becomes very small.
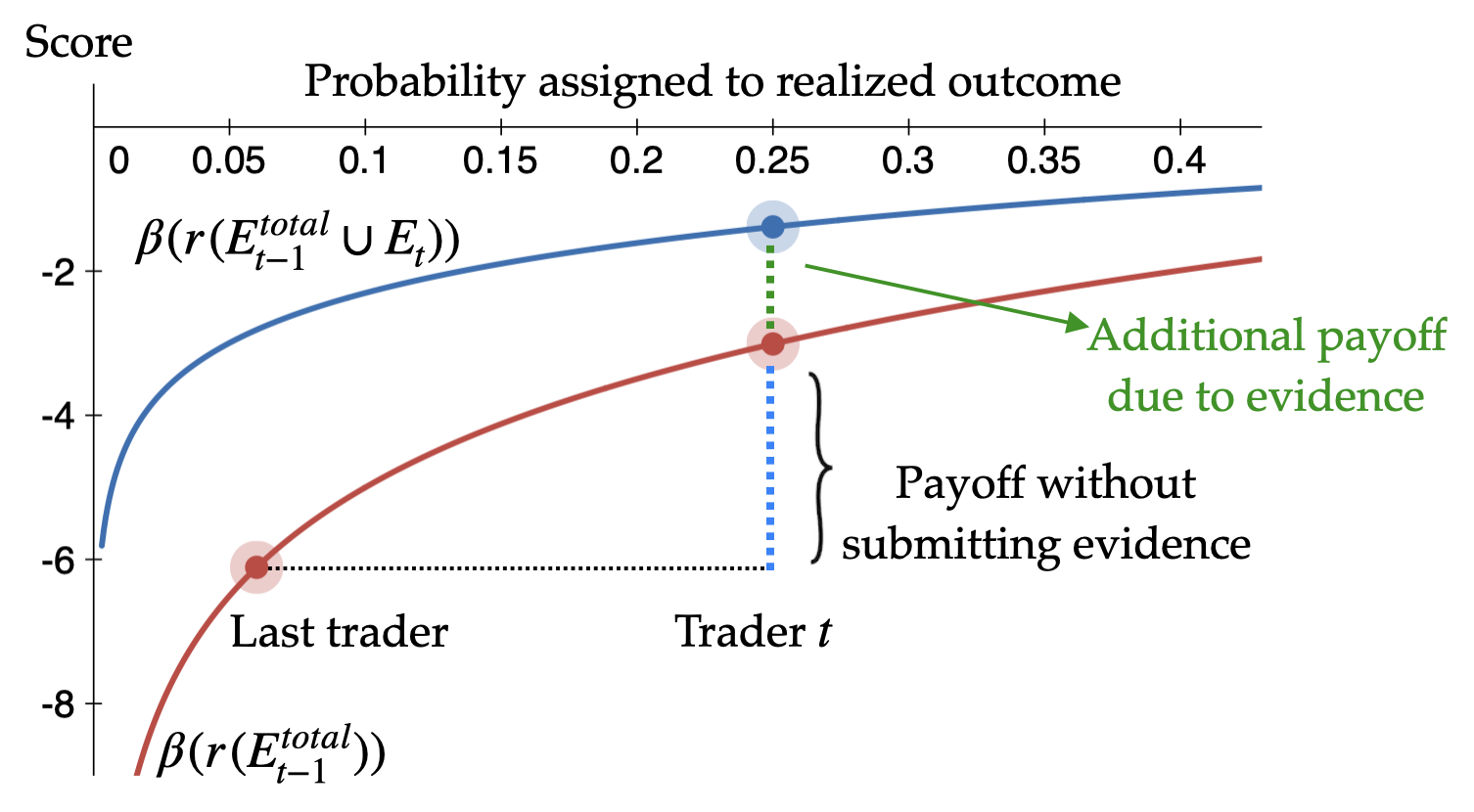
- Rewards for evidence and beliefs: The payoff breaks into two parts:
- belief payoff—reward for moving the market toward the truth (like in standard prediction markets),
- evidence payoff—extra reward when you add valuable evidence, especially when the market is still uncertain.
- AMM implementation: You can run this system in the familiar “automated market maker” style (a robot cashier that always offers to buy or sell shares at a fair price), so users can just trade “shares” instead of submitting raw probability numbers.
- Evidence verification via LLM-as-a-Judge + staking: Since people might submit low‑quality or fake evidence, the authors propose using a strong LLM to judge evidence by default. Others can dispute a judgment by staking money; if the dispute is valid, the staker can be rewarded. This setup leans on the idea that checking evidence is often easier than creating it.
- Asynchronous execution: Trades don’t get stuck waiting for evidence verification. The system can verify evidence in the background and adjust rewards appropriately.
4) What did they find, and why is it important?
Main results (in simple terms):
- Bounded platform loss: The total money the platform could lose is capped (and depends on a “liquidity” setting). This makes the system financially manageable.
- Truthful beliefs are optimal:
- When the event is resolved externally (like an election), telling the truth about your belief is strictly the best strategy.
- When the event is resolved using the market’s own evidence, telling the truth is still best “up to a tiny wiggle room” (called ε-dominant). The system settings can make that wiggle room as small as you want.
- Full evidence submission is incentivized:
- For external resolution, sharing all your evidence strictly helps you (or at least never hurts), because it earns an evidence payoff.
- For internal (endogenous) resolution, hiding evidence doesn’t help much—the benefit can be made very small by choosing the right temperature and evidence target K.
- Evidence is paid more when uncertainty is high: If the market is unsure, your evidence is more valuable. This encourages people to contribute when it matters most.
- Market beliefs become interpretable: Because evidence is part of the market record, you can see why the price moved—not just that it moved.
- Flexible participation: People can submit only beliefs (like a normal market), only evidence (as contributors), or both—lowering the barrier to participation.
Why this matters:
- It opens markets to questions that don’t naturally “resolve themselves,” like: Which scientific method works better? Does a policy change actually help? Which AI model is better for a specific task? Instead of waiting for a future outcome, the market’s collected evidence can decide.
- It turns prediction markets from “black box” odds into “explainable” forecasts that include the reasons behind the odds.
- It creates practical incentives to build high-quality evaluation datasets—especially useful for rapidly evolving fields like LLMs.
5) What are the implications?
This research could change how we evaluate complex or subjective questions:
- AI model evaluations: Communities could quickly build, verify, and use targeted tests to judge which model is better at a given task, with the market providing both the verdict and the supporting evidence.
- Science and policy: For questions that require judgment and interpretation, evidence markets could help gather competing evidence and reach a reasoned conclusion, making the process more transparent.
- Better decision-making: Because evidence is collected and visible, decision‑makers can trust not just the final number, but also the reasoning behind it.
In short, evidence markets aim to make predictions explainable and make unexplained questions answerable—by paying people to bring both their beliefs and their best evidence to the table.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide future research:
- Evidence quality function r(E): precise design, properties (e.g., submodularity/diminishing returns), deduplication, and robustness to correlated/near-duplicate or low-novelty evidence are unspecified beyond monotonicity.
- Calibration of r(E) to prevent gaming: how to prevent incremental sybil-splitting of evidence, spam, or adversarial “padding” that marginally increases r(E) to harvest evidence payoffs.
- LLM-as-a-Judge verification: empirical reliability, bias, variance, adversarial robustness (prompt injection, targeted failures), and calibration across domains are not quantified.
- Dispute/staking mechanism: no formal model of disputes, equilibria, or guarantees (e.g., truthfulness, collusion resistance, sybil resistance, and budget balance) when verifiers and traders are the same agents.
- Collusion and coalition attacks: analysis is missing for groups coordinating to manipulate r(E), β(R), or the resolution outcome by crafting targeted evidence.
- Evidence attribution and duplication: unresolved policy for credit assignment when multiple traders submit similar or identical evidence (racing dynamics, plagiarism, and timestamping).
- Order-independence (Axiom 5): dynamic β(R) implies order-dependent payoffs unless carefully designed; a formal proof or mechanism ensuring order irrelevance is absent.
- AMM implementation with dynamic liquidity: exact cost function, price updates, and arbitrage/no-regret guarantees under β that changes with R are not fully derived.
- Path independence and no free-lunch: when β changes over time, conditions ensuring no cyclic arbitrage and consistent pricing are not established.
- Strategic timing: incentives to delay evidence submission (e.g., right before K) or to split evidence across time/accounts to maximize payout require analysis and mitigation.
- Parameter selection: principled methods to set K (resolution threshold), β(R) schedule, and τ (temperature) balancing incentive compatibility, market sharpness, and error risk are not provided.
- Sensitivity bound practicality: the ε-DSIC guarantee depends on correctly estimating the largest “evidence whale” to set τ; how to estimate this robustly (and respond to misestimation) is open.
- Resolution quality vs τ trade-off: quantitative analysis of how τ affects sharpness, resolution error probability, and market informativeness is missing.
- Sample complexity: no bounds relating K, evidence quality distribution, and the probability of selecting the correct alternative (ex-post accuracy or regret).
- Evidence model realism: binary X_ie (support/refute) is restrictive; graded, noisy, or multi-faceted evidence and partial credit are not modeled.
- Correlated evidence: no formal treatment of dependence among evidence items (e.g., multiple questions probing the same capability), which can distort resolution and incentives.
- Endogenous vs exogenous beliefs: in endogenous resolution, evidence submission changes beliefs; conditions on β(R) and τ that make full evidence submission strictly optimal (not just ε-optimal) are not characterized.
- Entropy-based evidence payoff: the x·H(q) term may encourage higher-entropy beliefs; formal analysis of whether belief truthfulness fully dominates entropy incentives (especially with endogenous resolution) is lacking.
- Trader risk preferences and budgets: incentive claims assume risk-neutral expected payoff maximization; robustness under risk aversion, budget constraints, or limited liability is unaddressed.
- Platform economics: bounded loss β(R0)·log n is nonzero; sustainable funding, fee design, and cross-subsidization (especially in repeated markets) are not explored.
- Payment timing: whether to compensate evidence contributors immediately vs at resolution (and implications for participation and gaming) is unclear.
- Hybrid or rolling resolution: beyond fixed K, adaptive stopping rules (e.g., confidence thresholds), early stopping, or multi-phase resolution are not developed.
- Cross-market evidence reuse: policies and incentives for reusing evidence across related markets, and impacts on r(E) and β(R), are unexamined.
- LLM evaluation application specifics: safeguards against adversarial question design targeting specific models, contamination controls, and fairness across model families are not specified.
- Governance and parameter transparency: who sets/updates K, β(R), τ, r(·), and verifier models; change-management, auditability, and community oversight are open design questions.
- Security and spam resistance: throughput, computational costs of verification, DoS risks, and throttling/ratelimiting mechanisms for submissions are not analyzed.
- Legal/regulatory considerations: classification of endogenous-resolution markets, use of LLMs as adjudicators, and compliance in real-money contexts remain to be addressed.
- Privacy/IP of evidence: policies and mechanisms for ownership, licensing, and sharing of submitted evidence (datasets, prompts/answers), including takedown/dispute processes, are unspecified.
- Empirical validation: absence of simulations or field experiments to test manipulation resistance, parameter choices, verifier accuracy, and market efficiency under realistic adversarial conditions.
Practical Applications
Immediate Applications
Below are applications that can be piloted with today’s tooling (especially in domains where LLM-as-a-Judge is reliable, evidence is digital/verifiable, and resolution can be exogenous or via crowd-sourced artifacts).
- LLM evaluation and dynamic benchmarking (AI/Software, Education)
- Use case: Run continuous markets on “Which model is best for task X?” where traders both place probabilistic bets and submit evaluation items (prompts/answers) as evidence. Resolution is endogenous via the submitted tests; leaderboards update in real time with confidence.
- Tools/products/workflows: Evidence-augmented LMSR AMM; LLM-as-a-Judge with staking/dispute; de-duplication and relevance filter for questions (r(E)); leaderboard API; plug-in for platforms like Chatbot Arena/HELM dashboards.
- Assumptions/dependencies: Judge accuracy for pairwise/model scoring; safety filters for harmful prompts; IP/licensing for submitted items; anti-gaming (sybil resistance, similarity filtering); temperature τ tuned to limit belief-shift by evidence withholding.
- AI red teaming and safety stress-testing (AI Safety, Software)
- Use case: Markets to surface high-value jailbreaks or failure cases. Traders stake on which model/policy fails and submit prompts/outputs as evidence; endogenous resolution by judge models and human-on-the-loop arbitration for disputed cases.
- Tools/products/workflows: Red-team portal with evidence staking; automatic clustering and deduplication; severity-weighted r(E); workflow to triage/repair models informed by the evidence record.
- Assumptions/dependencies: Robust harm classifiers/verifiers; strong moderation; liability policies; sealed handling of sensitive content; dispute budget and expert adjudication for edge cases.
- Evidence-augmented earnings and macro markets (Finance)
- Use case: Extend exogenous prediction markets (earnings beats, CPI surprises) to reward contributed evidence (channel checks, filings, alternative data analyses) that improves market liquidity/accuracy even before resolution.
- Tools/products/workflows: Evidence submission UI with source links; plagiarism detection; dynamic liquidity tied to r(E); analyst leaderboard for evidence quality; APIs for fund dashboards.
- Assumptions/dependencies: Compliance/KYC; IP and fair-use policies; guardrails against market manipulation; clear evidence-quality function r(E) (e.g., source credibility, novelty).
- Product/model A/B testing marketplace (Software/SaaS)
- Use case: “Which assistant/translation/summarization tool is better for my use case?” Traders submit tasks and results as evidence; judge evaluates outputs; endogenous resolution enables rapid, targeted benchmarking for buyers.
- Tools/products/workflows: Vendor integration for task execution; judge orchestration; per-segment leaderboards; procurement-ready reports.
- Assumptions/dependencies: Vendor permission to test; privacy-safe task data; domain-tuned judges; normalization across versions.
- Fact-checking and claim verification markets (Media/Information integrity)
- Use case: Markets on whether a statement is accurate; traders submit citations/excerpts as evidence; judge assesses support/refutation; outputs a confidence and evidence pack for editors/readers.
- Tools/products/workflows: “Evidence pack” generator; source credibility scoring in r(E); newsroom CMS integration; dispute and corrections workflow.
- Assumptions/dependencies: Judge reliability for citation grounding; defamation/legal risk management; provenance checks for media.
- Bug triage and root-cause forecasting (Software Engineering)
- Use case: Predict severity/root cause/ETA for issues; evidence includes minimal repro, logs, failing tests. Exogenous resolution occurs when the fix merges; evidence accelerates diagnosis and is rewarded.
- Tools/products/workflows: Issue-tracker integration (Jira/GitHub); test-artifact verifier; r(E) tied to reproducibility and failure isolation; on-call dashboards.
- Assumptions/dependencies: Access to logs/tests; sensitive data handling; automated test execution sandbox; spam controls.
- Evidence-augmented DAO and community governance (Web3/Governance)
- Use case: Attach staked analyses to proposals (treasury actions, parameter changes); exogenous resolution after vote or KPI-based milestones; evidence rewarded for improving market certainty.
- Tools/products/workflows: Governance portal plugin; identity/stake-based sybil resistance; on-chain AMM with dynamic liquidity; audit trail of rationales.
- Assumptions/dependencies: On-chain identity; dispute resolution; jurisdictional compliance for tokens/stakes.
- Dataset and evaluation-set marketplaces (AI/ML)
- Use case: Incentivize creation of high-quality evaluation items for targeted capabilities (reasoning, retrieval, multilingual); evidence items both resolve markets and are packaged as curated eval sets/products.
- Tools/products/workflows: Evidence curation pipelines; duplication/contamination checks; versioned “eval packs”; revenue sharing with contributors.
- Assumptions/dependencies: Strong r(E) for novelty, difficulty, and balance; leakage detection; licensing models (open vs. commercial).
- Enterprise decision markets with evidence (Operations/Strategy)
- Use case: Internal markets (e.g., “Will project X hit Q3 goals?”) with evidence like dashboards, customer interviews, and risk logs; exogenous resolution by KPI realization; evidence improves shared situational awareness.
- Tools/products/workflows: SSO-integrated market tool; connectors to BI/wikis; r(E) aligned to data freshness/relevance; retention-safe storage.
- Assumptions/dependencies: Governance for sensitive info; cultural buy-in; clear policy on conflicts of interest; privacy/compliance.
Long-Term Applications
These require further research, domain integration, or institutional buy-in (e.g., high-stakes verification, physical-world evidence, complex causality).
- Scientific replication and robustness markets (Academia/Science)
- Use case: Markets on “Does result R replicate?” with evidence as replications, preregistrations, code/data reanalyses; endogenous resolution via accumulated replications and expert arbitration.
- Tools/products/workflows: Registry integration (OSF); code execution sandboxes; r(E) weighting by sample size, prereg status, methods quality; funder dashboards to prioritize replications.
- Assumptions/dependencies: Incentives for labs; IRB/ethics; cost of experiments; human panels to complement judges; field-specific standards.
- Comparative effectiveness and treatment policy markets (Healthcare/Policy)
- Use case: Markets on treatment/program effectiveness using real-world evidence (registries, EHR analyses) as evidence; multi-study aggregation informs resolution.
- Tools/products/workflows: Privacy-preserving analytics; causal inference checks in r(E); health system partnerships; payer/regulator viewers.
- Assumptions/dependencies: HIPAA/GDPR compliance; causal validity; long timelines; oversight and equity considerations.
- Public policy impact markets (Government/NGOs)
- Use case: Markets on policy outcomes (e.g., “Did program P reduce homelessness by ≥X%?”); evidence as studies/administrative data analyses; resolution via pre-specified evaluation protocols.
- Tools/products/workflows: Evaluation registries; data-sharing MOUs; r(E) aligned to design rigor and data quality; independent audit boards.
- Assumptions/dependencies: Political neutrality; data access; time horizons; legitimacy of adjudication.
- Legal outcome forecasting with brief-based evidence (Legal)
- Use case: Predict appellate outcomes with evidence as briefs, precedents, and oral-argument signals; exogenous resolution by verdict; evidence submission clarifies reasoning for practitioners.
- Tools/products/workflows: Legal-judge models with human review; r(E) for precedent strength and jurisdiction fit; firm knowledge-base integration.
- Assumptions/dependencies: Ethics/confidentiality; model reliability; potential chilling effects; bar/regulatory guidance.
- Robotics and embodied AI benchmarking (Robotics/Autonomy)
- Use case: Markets on “Which policy/controller succeeds on task T?” with evidence as videos, logs, and eval runs; endogenous resolution via standardized testbeds.
- Tools/products/workflows: Simulator integration; tamper-evident logging; r(E) for task difficulty and domain coverage; physical test facilities.
- Assumptions/dependencies: Standardized protocols; sensor spoofing defenses; sim-to-real gap; cost to run trials.
- Carbon accounting and ESG claims markets (Energy/Climate/Finance)
- Use case: Markets on emissions reductions or project additionality; evidence includes sensor data, audits, satellite imagery; resolution via verified MRV pipelines.
- Tools/products/workflows: Data-oracle connectors; provenance-attested uploads; r(E) weighted by source integrity and coverage; auditor panels.
- Assumptions/dependencies: Data authenticity; audit capacity; jurisdictional standards; anti-greenwashing enforcement.
- Vulnerability discovery and triage markets (Cybersecurity)
- Use case: Markets on exploitability/impact of components; evidence as PoCs, fuzzing traces; exogenous resolution via CVE assignment/severity; structured incentives for high-signal findings.
- Tools/products/workflows: Safe-disclosure workflows; sandbox verification; r(E) for reproducibility and severity; vendor coordination.
- Assumptions/dependencies: Legal safe harbor; preventing real-world harm; export controls; secure storage.
- Code correctness/proof markets (Programming languages/Formal Methods)
- Use case: Markets on correctness of critical code paths; evidence as proofs, model-checker traces; endogenous resolution via proof checker verifiers.
- Tools/products/workflows: Checker orchestration; r(E) for proof completeness/strength; IDE integrations; assurance reports.
- Assumptions/dependencies: Maturity of provers/checkers; developer workflow fit; proof maintenance costs.
- Education efficacy markets (Education/EdTech)
- Use case: Markets on “Does curriculum/intervention improve outcome Y?” with evidence as RCTs/quasi-experiments and learning analytics; resolution by pre-registered evaluation plans.
- Tools/products/workflows: Data pipelines from LMS; r(E) for study design quality and cohort balance; district dashboards.
- Assumptions/dependencies: Student privacy; causal validity; multi-year horizons; ethical review.
- Supply-chain compliance and provenance markets (Manufacturing/Logistics)
- Use case: Markets on supplier compliance (labor, materials); evidence as audits, IoT telemetry, document chains; resolution via independent verification.
- Tools/products/workflows: Provenance ledgers; multi-source corroboration in r(E); auditor staking; escalation workflows.
- Assumptions/dependencies: Document fraud risk; physical audits; geopolitical constraints; standards alignment.
Cross-cutting enablers (from the paper’s methods)
- Evidence-augmented LMSR with dynamic liquidity
- Productization: AMM module where β decreases as r(E) increases; SDK for existing market platforms to turn on “evidence rewards.”
- Dependencies: Well-defined, monotone r(E); bounded platform loss; clear interpretation of market prices.
- Endogenous resolution via softmax over evidence-supported scores
- Productization: Configurable K (evidence quota) and temperature τ; dashboards showing both scores and resolution probabilities.
- Dependencies: τ calibrated to bound belief shifts (ε-DSIC); whale-detection to set τ; clear scoring schema Xie per evidence.
- LLM-as-a-Judge with staking and disputes
- Productization: Judge orchestrator; staking/dispute layer; evidence similarity/novelty filters; asynchronous execution so trading isn’t blocked by verification.
- Dependencies: Domain-tuned judges, human arbitration budget, abuse prevention, transparent adjudication logs.
- Evidence quality function r(E)
- Productization: Pluggable scoring services (novelty, difficulty, source credibility, reproducibility); deduplication and semantic clustering.
- Dependencies: Domain data, ground rules per market, anti-collusion monitoring.
These applications assume careful market governance (sybil resistance, anti-collusion), legal/compliance review (especially for finance, health, and security), and transparent policies for verification and disputes to maintain trust and reduce gaming.
Glossary
- Automated market maker (AMM): An algorithmic trading mechanism that sets prices via a cost function and provides continuous liquidity without matching counterparties. Example: "can be equivalently implemented through an automated market maker."
- Correlated Agreement: A peer-prediction mechanism that rewards reports based on their correlation structure to elicit truthful information across tasks. Example: "Multi-task extensions including Correlated Agreement~\citep{shnayder2016informed}..."
- Determinant-based Mutual Information: A peer-prediction scoring method that uses a determinant-based estimator of mutual information to incentivize truthful reporting. Example: "...and Determinant-based Mutual Information~\citep{kong2020dominantly} strengthen these results under weaker assumptions."
- Dominant strategy incentive compatible (DSIC): A mechanism property where telling the truth maximizes a participant’s payoff regardless of others’ actions. Example: "an -dominant strategy incentive compatible (DSIC) strategy."
- Endogenous resolution: Determining the market outcome using evidence collected within the market rather than an external ground truth. Example: "Endogenous resolution is triggered when pieces of evidence has accumulated."
- Evidence verification: The process of checking that submitted evidence is valid, relevant, and not tampered with. Example: "we propose evidence verification via an LLM-as-a-Judge framework with staking"
- Exogenous resolution: Determining the market outcome using an externally verifiable ground truth at a known time. Example: "strict DSIC for exogenous resolution"
- Generative reward models: Reward models that generate evaluations or feedback to score model outputs or reasoning. Example: "generative reward models~\citep{zhang2024genrm}"
- KL divergence: A measure of how one probability distribution diverges from another reference distribution. Example: "the KL divergence:"
- Liquidity curve: The function mapping accumulated evidence quality to the liquidity parameter, shaping how payoffs scale. Example: "depends crucially on the shape of this liquidity curve ."
- Liquidity parameter: A scalar controlling the sensitivity of prices/payoffs in market scoring rules; higher values imply larger payoffs for the same probability change. Example: "liquidity parameter changes dynamically with the accumulated evidence quality."
- LLM-as-a-Judge: A framework where a LLM serves as the default verifier or adjudicator of evidence quality. Example: "LLM-as-a-Judge"
- Logarithmic Market Scoring Rule (LMSR): A market scoring rule using log scores that ensures truthful probability reports and bounds platform loss. Example: "Logarithmic Market Scoring Rule (LMSR)"
- Negative cross-entropy: A scoring/payoff based on the negative of cross-entropy, equivalent to log-likelihood rewards for correct predictions. Example: "pays earlier participants based on the final reporter's prediction via negative cross-entropy"
- Peer prediction: Mechanisms that elicit truthful reports without ground truth by rewarding agreement with peers in statistically informed ways. Example: "Peer prediction."
- Perfect Bayesian equilibrium: An equilibrium in dynamic games where strategies and beliefs are mutually consistent and updated via Bayes’ rule. Example: "achieving truthful reporting as a perfect Bayesian equilibrium"
- Process reward models: Reward models that evaluate intermediate reasoning steps (process) rather than only final answers. Example: "process reward models~\citep{lightman2023verify}"
- Self-resolving prediction market: A market that resolves outcomes via its own internal reporting process rather than observing an external outcome. Example: "The self-resolving prediction market of ~\citet{srinivasan2023self}"
- Shannon entropy: A measure of uncertainty in a probability distribution, defined as the expected negative log-probability. Example: "Shannon Entropy function"
- Simplex: The set of all probability vectors over n outcomes; each component is nonnegative and sums to one. Example: "the dimensional simplex."
- Softmax: A function converting scores into probabilities by exponentiating and normalizing, often with a temperature parameter. Example: "the market resolves by sampling alternative "
- Staking: Putting collateral at risk to back claims or disputes in verification/adjudication. Example: "with staking"
- Telescoping series: A sum where consecutive terms cancel out, leaving only initial and final terms. Example: "sum of the payoffs form a telescoping series"
- Temperature (softmax): A parameter controlling how peaked or flat the softmax distribution is; higher temperature makes the distribution flatter. Example: "where is the temperature of the softmax."
- Verifier-augmented thinking models: Systems that augment generation with verification steps to improve reasoning reliability. Example: "verifier-augmented thinking models~\citep{khalifa2025thinkprm}"
- WOMAC mechanism: A mechanism for adjudication in prediction competitions that structures disputes and resolution. Example: "the recent WOMAC mechanism~\citep{srinivasan2025womac}"
Collections
Sign up for free to add this paper to one or more collections.