- The paper quantifies how AI agents, using LLMs in LMSR prediction markets, experience sharp aggregation degradation as information complexity increases.
- It shows that higher agent intelligence reduces catastrophic aggregation failures by lowering tail risks, yet fails in highly complex environments.
- The study finds that public communications, initial pricing, and feedback interventions do not improve aggregation, highlighting limits in recursive reasoning.
Experimental Setting and Market Design
The paper "Information Aggregation with AI Agents" (2604.20050) presents a controlled experimental investigation into the ability of LLM-based AI agents to aggregate dispersed private information via trading in multi-agent prediction markets. The market uses the Logarithmic Market Scoring Rule (LMSR) for trading a binary security, where the asset's terminal value depends on the conjunction of private signals held by three AI agents. The experiment manipulates six key variables: the information structure complexity, trading horizon, communication channel (cheap talk), trading objective (myopic vs. strategic), market initial price, and an information provision intervention.
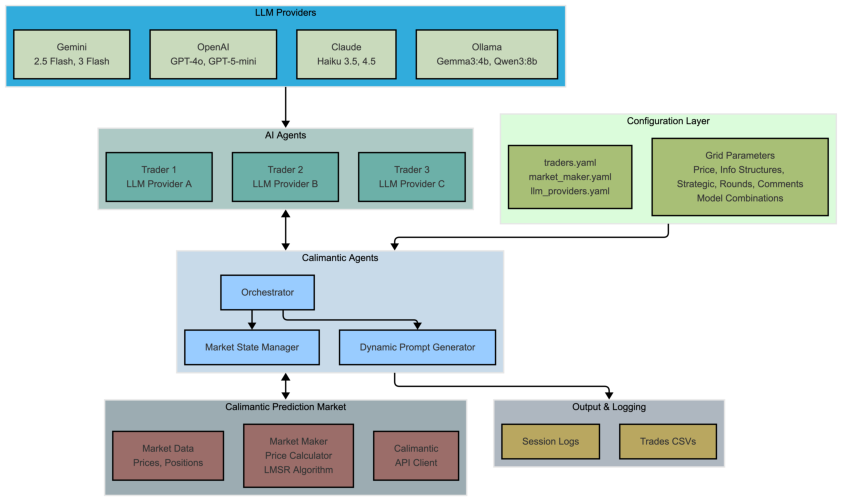
Figure 1: Prediction market platform.
The market structure involves repeated rounds, with each agent trading at fixed positions. Private signals are randomly assigned and determine, in conjunction, the true security value. The design ensures that—in theory—information aggregation should occur when agents are perfectly rational and capable of higher-order belief updating, in accordance with the separability condition outlined in Ostrovsky (2012).
Core Empirical Results: Complexity, Aggregation, and Intelligence
A central contribution is the rigorous quantification of information aggregation effectiveness across market conditions. Aggregation performance is measured by the log error of the market's closing price relative to the true asset value.
A critical finding is the sharp and monotonic degradation of information aggregation as the complexity of the information structure increases. While the median market achieves nearly perfect aggregation in the easiest settings, performance collapses to randomness in the most complex structure, which formalizes a multi-agent "muddy children" puzzle. Even state-of-the-art April 2026 LLMs (Gemini 3.1 Pro, GPT-5.4, Claude 4.6 Opus) fail to aggregate information in this regime, indicating a persistent upper bound on LLM-based agents’ recursive reasoning capabilities—even with only three traders.
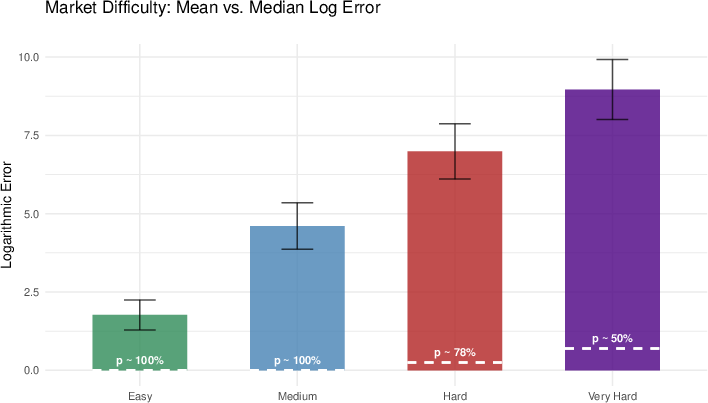
Figure 2: The Complexity Effect. As the structure becomes more complex, the information aggregation deteriorates. The dashed line, p(True), indicates the median price of the security that paid 1.
Provision of public messages ("cheap talk"), manipulation of the initial price, extending the trading period, or strategic prompting had no statistically significant impact on aggregation—demonstrating robustness of LMSR prediction markets to these factors.
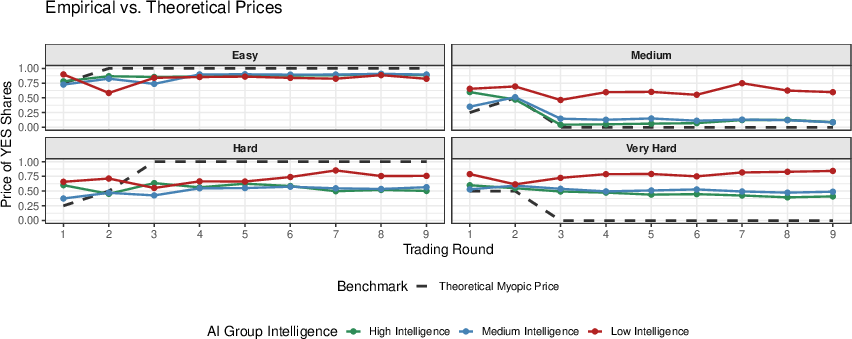
Figure 3: Myopically Optimal and Actual Prices Across Structures. Smarter markets tightly track the myopically optimal prices in the Easy and Medium structures, but revert to 0.5 in the Hard and Very Hard. The low intelligence markets do better in the Hard structure but this seems more an artifact of noisy trading rather than sophisticated interactive reasoning.
Agent Intelligence, Strategic Behavior, and Communication
Market performance is partially rescued by the cognitive abilities of the agents: higher average intelligence within teams reduces catastrophic aggregation failures, primarily by lowering the lower tail risk (i.e., reducing crash frequency, rather than raising median accuracy). However, even high-intelligence teams fail in the hardest structures.
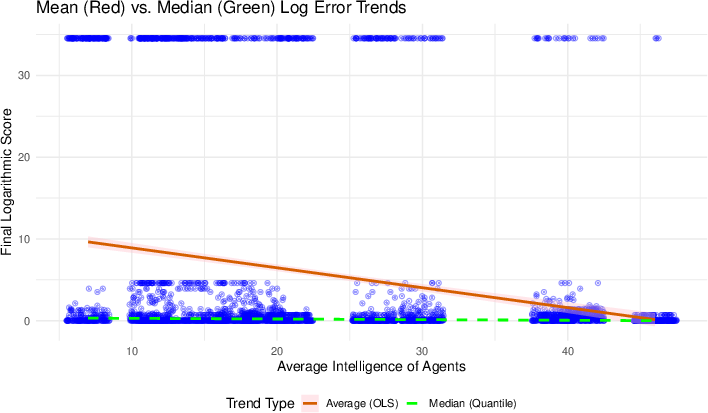
Figure 4: The Intelligence Effect. As the AI agents become smarter, information aggregation (mean log error) improves, but the median log error is unaffected. Points are jittered horizontally to show density of markets with the same intelligence.
Agent-level profit analysis reveals that individual intelligence increases profitability, but this advantage is offset as average team intelligence rises—mirroring competitive rent dissipation. This supports prior findings from human-subject markets, indicating parallel strategic arbitrage dynamics.
Communication analysis exposes systematically adversarial behavior: in >90% of markets, public messages are shorter and less informative than private ones (information hoarding). Strategic prompting does not induce substantive deception or information revelation, with only minor shifts in message similarity and length. Analysis of the temporal dynamics shows a “sawtooth” pattern: agents withhold information and mislead in early rounds to protect rents but spike in truthful revelation at terminal rounds—demonstrating some awareness of end-game incentives but incomplete dynamic market reasoning.
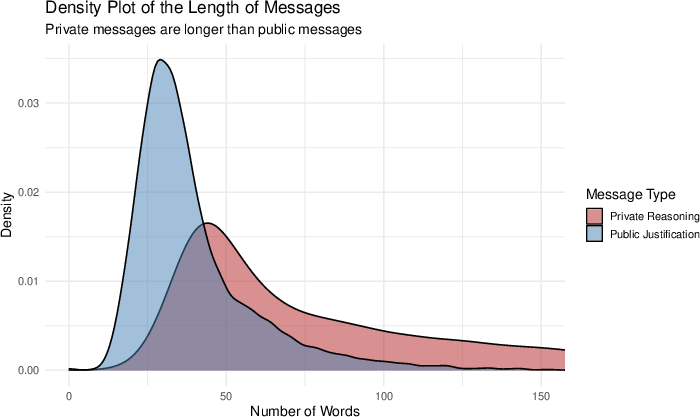
Figure 5: Length of Private and Public Messages
Negative Impact of Feedback and Learning from Experiments
Notably, the experiment tested whether exogenous feedback (summary statistics of past market outcomes) would enable agent learning. Contrary to self-improvement results in recent LLM optimization literature, information provision significantly increased the average market log error and had no effect or even negative effect on individual profitability—suggesting that qualitative disclosures can disrupt multi-agent aggregation by confusing the agents’ reasoning chains in this environment.
Frontier Model Robustness and Theoretical Limits
A third experimental wave in April 2026 validates the robustness and persistence of the aggregation ceiling. Even with major architecture advancements and higher intelligence scores, no model or model ensemble successfully aggregates information in the complex structures—the median market consistently outputs the uninformative price p=0.5 in the "muddy children" regime, with error distributions statistically bounded away from rational benchmarks.
Mean performance in the hardest conditions deteriorates relative to the best January 2026 models, suggesting possible RLHF-induced miscalibration or alignment tax in advanced LLMs. Only direct, interpreted communication helped slightly, possibly reflecting improved comprehension of text logs rather than superior belief updating.
Implications and Theoretical Consequences
This study demonstrates structural limits on the depth of recursive reasoning and higher-order belief modeling achievable by current and near-term LLM-based AI agents in multi-agent markets, despite state-of-the-art prompting and communication scaffolding. The LMSR market mechanism performs robustly to many parameterizations, but aggregation fails as soon as multi-level interactive inference is required.
Theoretically, this challenges the use of LM-augmented agent collectives in settings requiring sophisticated common-knowledge inference—reminding us that even in AI-only markets, the “no-trade” and “agreeing-to-disagree” theorems are only operational with agents capable of true high-order epistemic modeling.
Practically, deploying LLM agents for collective decision-making, forecasting, or market-based aggregation cannot presume optimal collective epistemics simply due to large context windows, high IQ benchmarks, or human parity on standard NLP tasks. Instead, recursive market-based architectures depending on interactive higher-order belief updating may be fundamentally bottlenecked by the architectures’ depth of reasoning.
Future developments may see progress via architectural advances that provide explicit memory, recursive belief modeling, or agent simulations that allow deep ToM (theory-of-mind). Joint neuro-symbolic approaches, iterative elicitation protocols, or specialized RL training directly targeting interactive reasoning might push these boundaries. Until then, markets requiring the aggregation of fully distributed, high-order epistemic information should assume critical limitations for contemporary LLM-agent platforms.
Conclusion
This paper provides a rigorous benchmark for the epistemic limits of current AI agents in market-based information aggregation. While median performance in simple settings is strong, interactive complexity rapidly yields aggregation failure even in small markets. Robustness to market conditions is high, intelligence heterogeneity partially mitigates failures, but recursive belief collapse persists for all tested models. The negative impact of exogenous qualitative feedback further highlights the fragility of AI-ensemble learning in multi-agent economic environments. These results signal the need for explicit advances in interactive reasoning for AI-market design and call for new theoretical frameworks when modeling cognitive architectures in strategic economic systems.

