- The paper introduces an auditable, modular multi-agent system that decouples reasoning from retrieval to ensure transparent, evidence-based research.
- It employs a dynamic, graph-based planning approach with recursive search agents that robustly mitigate retrieval noise and agent failures.
- Rubric-based guidance at both planning and synthesis stages significantly improves insight and comprehensiveness, validated on public benchmarks.
DuMate-DeepResearch: Auditable Multi-Agent Deep Research with Recursive Search and Rubric-Grounded Reasoning
System Architecture and Design Rationale
DuMate-DeepResearch introduces a multi-agent architecture for deep research, built atop the Qianfan Agent Foundry, with a marked focus on auditability, resilience to retrieval noise, and evidence-grounded synthesis. The architecture exposes every planning decision and tool invocation, facilitating full process transparency.
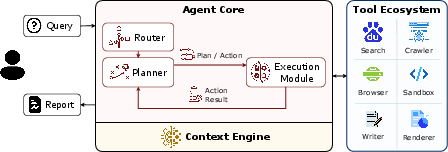
Figure 1: High-level illustration of the Qianfan Agent Foundry, highlighting the separation of the Agent Core from the extensible Tool Ecosystem.
The core architectural innovation is the full decoupling between the Agent Core (reasoning, planning, scheduling) and the Tool Ecosystem (retrieval, analysis, rendering). This separation enables independent scaling, modular evolution, and fine-grained inspection of all agentic operations. The system loop is formalized as a state transition across iterations, where each state captures: the fixed task context, the evolving plan, the accumulated evidence, and the current guidance signal (instantiated as rubrics). Every intermediate artifact—queries, tool outputs, planning DAG updates—is logged for thorough traceability, meeting stringent requirements for high-stakes, evidence-sensitive domains.
Graph-Based Dynamic Planning and Hierarchical Execution
Central to addressing the long-horizon, underspecified nature of deep research, DuMate-DeepResearch employs a dynamic, graph-based planning strategy. Rather than ReAct-style stepwise progression—which is inherently myopic and brittle in high-noise situations—the roadmap is maintained as a directed acyclic graph (DAG) expanded in a coarse-to-fine fashion. Nodes encode sub-tasks, edges capture dependencies, and recursive expansion/refinement occurs as new evidence accrues.
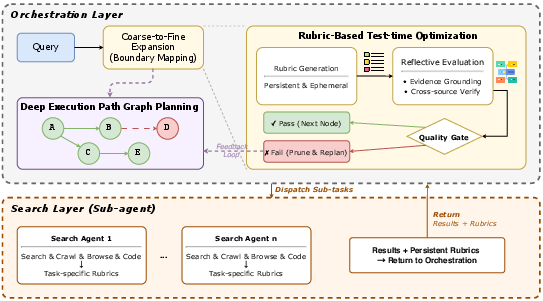
Figure 2: Depiction of dynamic planning, rubric-guided optimization, and the nested execution structure.
This enables far-sighted re-planning: when retrievals fail, or new information contradicts prior assumptions, the planner prunes, backtracks, or branches as appropriate. Only nodes on the ready frontier—those with all dependencies resolved—are dispatched, with parallelism exploited as sub-task independence permits.
When an action corresponds to a complex search (open-ended, multi-step retrieval), the outer Execution Module spawns a new, fully-fledged inner Search Agent—a recursive instantiation of the Agent Core—thus strictly separating global research strategy from noisy, local evidence gathering. These Search Agents themselves follow the understand-plan-execute loop with localized sub-goals and evidence bases, preventing failures on one sub-task from cascading globally. This two-level nesting achieves execution stability and enables robust recovery from web stochasticity, dead ends, and retrieval errors.
Rubric-Based Test-Time Optimization
A distinctive feature is the rubric-based reasoning scaffold operational at both planning and synthesis phases. Rubrics, structured as sets of actionable, fine-grained criteria, are generated and updated dynamically throughout execution. This guides not just synthesis (as in most prior work) but also drives all stages of planning—informing the planner and Search Agents about factual sufficiency, evidence gaps, and synthesis requirements at a sub-task granularity.
The rubric implementation is dual-layered: persistent rubrics (fixed for the topic/session) provide stable, global dimensions of report quality (comprehensiveness, internal consistency, source calibration, etc.), while ephemeral rubrics (regenerated after each planning-execution cycle) reflect the evolving information state, highlighting newly discovered gaps or contradictions. These are injected into agent contexts as explicit operational scaffolds, conditioning query formulation, evidence selection, and adaptive stopping (the main loop halts only when the rubric signals no outstanding evidence gaps).
Empirical Results and Ablation Analysis
DuMate-DeepResearch demonstrates strong numerical improvements across two public, challenging deep research benchmarks, DeepResearch Bench and DeepResearch Bench II.
- DeepResearch Bench: Achieves an overall score of 58.03%, outperforming all contemporary baselines. The system leads on Comprehensiveness (+0.9% over the next-best), Insight (+1.34%), and remains highly competitive on Instruction Following and Readability.
- DeepResearch Bench II: Secures an overall score of 61.95%, also ranking first on Information Recall and Analysis, the benchmarks’ most critical axes reflecting evidence acquisition and synthesis quality.
Ablation studies confirm that rubric-based guidance, especially at the report synthesis stage, contributes meaningfully to the Insight and Comprehensiveness dimensions. Model replacement at the report stage has an even stronger effect, underscoring the paramount significance of high-capacity, evidence-grounded sequence generators for final output fidelity.
Qualitative Analysis
Several case studies highlight the practical behaviors induced by the proposed architecture.
- Coarse-to-Fine Expansion: Initial planning phases conduct macroscopic, exploratory searches to delineate problem space boundaries, followed by data-driven fine-grained task decomposition. This strategy excels on queries with ambiguous scope, adaptively allocating retrieval and synthesis effort.
- Dynamic Re-Planning: The graph planner evaluates intermediate outcomes after each cycle, injecting validation, refinement, and supplemental queries in the presence of information gaps or source inconsistencies.
- Recursive Search Loops: Within each search sub-task, multi-turn retrieval strategies—query diversification, progressive specificity, and multi-tool fusion—maximize evidence recall and mitigate retrieval noise.
- Rubric-Grounded Reasoning: Rubrics propagate through all agent layers, enforcing explicit calibration against multi-source evidence, directly operationalizing criteria such as coverage, contradiction resolution, and scenario-specific quantification.
The system produces outputs featuring multi-source citation, scenario-bounded conclusions, quantitative modeling (e.g., AHP-entropy weighted frameworks), and full citation trails—demonstrably aligned with the evaluation axes for deep research agentic quality.
Implications and Future Directions
DuMate-DeepResearch makes several important strides in agentic research systems:
- Auditability: Full process transparency is operationalized; underlying trajectories are inspectable at arbitrary granularity, a strict necessity for research, policy, and legal use-cases.
- Long-horizon Resilience: Recursive planning/execution decouples global trajectory control from local retrieval, stabilizing execution in noisy, high-variance web environments.
- Rubric-Guided Adaptivity: Rubric scaffolding provides a generalized, formal interface between expert criteria (as in human evaluation) and live agentic reasoning, suggesting a blueprint for both test-time and (with further work) train-time rubrics-in-the-loop RL systems.
Looking ahead, extending this framework to richer Tool Ecosystems (e.g., domain-specific APIs, multi-modal retrieval), integrating live user feedback, and formalizing rubric-centric training objectives open clear research frontiers. Furthermore, such infrastructure can underpin benchmarking standards for future agentic reasoning systems.
Conclusion
DuMate-DeepResearch presents a comprehensive, auditable, and empirically validated framework for high-quality multi-agent deep research. By combining far-sighted, graph-based planning, recursive two-level execution, and rubric-based reasoning scaffolds, the system advances both the theoretical and practical state-of-the-art in complex, evidence-intensive research automation. The demonstrated performance across diverse domains and open benchmarks underscores the potential of transparent, adaptive, and rubric-driven agent architectures for the next generation of AI-augmented research.

