- The paper introduces a weight-space meta-learning method that generates task-specific LoRA weights in a single forward pass without gradient-based fine-tuning.
- It employs a structured meta-network to map multimodal embeddings from language and video into LoRA parameters, achieving up to 2x task success improvements on benchmarks.
- Real-world tests on a Franka Emika Panda arm demonstrate the method’s efficiency and robustness in zero-shot adaptation while reducing the need for labeled data.
Methodological Foundations
This work introduces a weight-space meta-learning paradigm for robotic policy adaptation, addressing the limitations of current Vision-Language-Action (VLA) models that require per-task fine-tuning and action-labeled data for generalization to unseen tasks. The central strategy is to completely decouple test-time adaptation from gradient-based optimization, by generating task-specific Low-Rank Adaptation (LoRA) weights for a frozen, high-capacity VLA policy in a single forward pass. The only inputs required are a natural language instruction and a short demonstration video; action labels and further fine-tuning are not needed.
The core pipeline proceeds as follows (Figure 1):
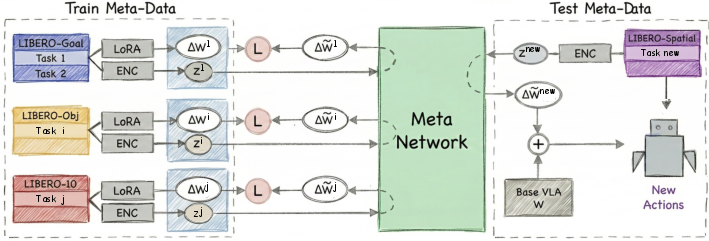
Figure 1: The WIZARD pipeline learns from a repository of LoRA-trained experts, mapping multimodal task embeddings to LoRA parameters via a meta-network; zero-shot inference is achieved by generating LoRA weights for new tasks from demonstration and language only.
- Meta-Training Phase: Expert LoRA adapters are fine-tuned per task using labeled data. For each such expert, a task embedding is formed via encoding both the language instruction and visual demonstration. The meta-network learns a mapping from these multimodal task embeddings to the LoRA parameter space, optimizing for both reconstruction in weight space and alignment-oriented (cosine) structural similarity.
- Meta-Inference (Deployment): When presented with a previously unseen task, a single demonstration and instruction are converted into a task embedding, from which the meta-network predicts the adaptation weights. These LoRA weights are then injected into the frozen VLA to yield a specialized policy.
This formulation leverages and extends prior works on meta-imitation (e.g., VIMA [jiang2023vima]) and parameter generation (e.g., HyperNetworks [ha2016hypernetworks], recent LoRA weight generators [wang2025rpg, liang2025draganddropllmszeroshotprompttoweights]). However, it departs from prior LLM/robotics methods by not requiring privileged data (e.g., goal images [zhou2025hypergoalnetgoalconditionedmanipulationpolicy]), or the computational burden of full-parameter generation; it instead exploits LoRA adapters, which are efficient to generate and inject even for large backbones.
Structural and Objective Innovations
To bridge the architectural heterogeneity and parameter scale differences in VLA models, the authors introduce several mechanisms:
- Structured, Multimodal Weight Representation: LoRA parameters are grouped and tensorized over perception (vision), reasoning (language), and control heads, ensuring architectural distinctions are maintained and facilitating multi-modal modeling.
- Scale-Aware Generation: Per-layer statistics (mean and standard deviation) of LoRA weights are explicitly modeled and predicted, yielding stable convergence during generation; weight normalization is necessary as magnitude variation is substantial across modules.
- Alignment-Oriented Supervision: Beyond classic reconstruction (MSE), the training objective includes cosine loss for directionality in weight space, enforcing that generated weights are functionally aligned with task expert weights.
Empirical Evaluation
LIBERO Benchmark Results
Zero-shot adaptation capability is rigorously assessed using the LIBERO suite, isolating generalization under severe distribution shift by holding out one entire dataset (e.g., LIBERO-Spatial) for testing.
Key findings:
- On unseen distributions, average zero-shot task success is substantially improved compared to multi-task VLA baselines and nearest-neighbor retrieval: up to 2× in dataset average (e.g., 0.19 → 0.40 success rate in LIBERO-Spatial), and up to 14× improvement on certain task/dataset configurations.
- Unlike action-space baselines, the adaptation preserves task specificity and high-fidelity policy recovery, manifesting in strong per-task results for challenging spatial and object-centric tasks; e.g., task-level results in LIBERO-Spatial exhibit up to 0.90 success rate for select tasks.
- The approach outperforms dataset-level embedding adaptation (akin to [liang2025draganddropllmszeroshotprompttoweights]), underscoring that task-level conditioning is critical for robust functional adaptation.
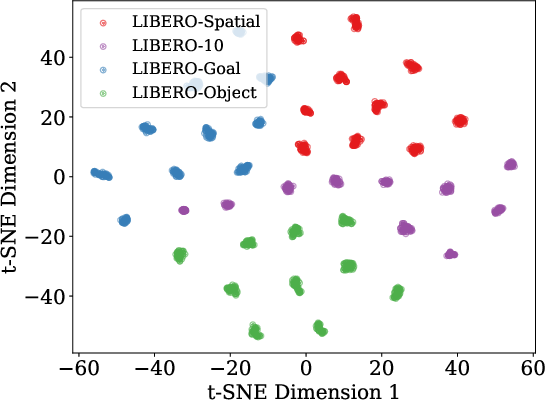
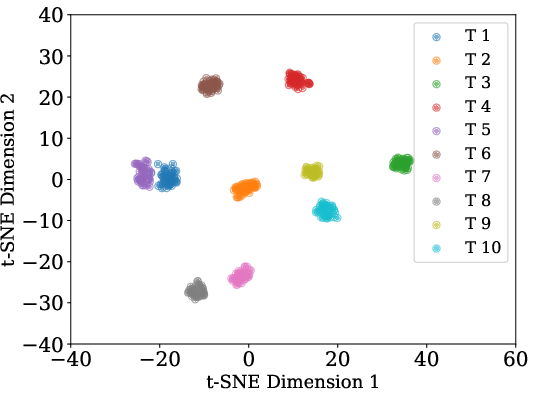
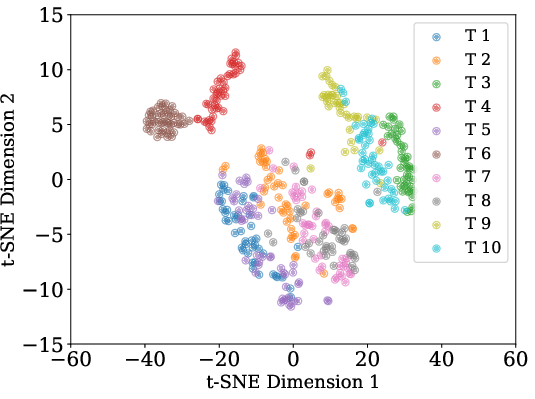
Figure 2: t-SNE visualization demonstrates that learned task embeddings are highly structured, forming discrete clusters by task and dataset, and maintain alignment between the conditioning and weight-generative manifolds.
The framework is deployed on a 7-DoF Franka Emika Panda arm for five manipulation tasks, with both the baseline (domain-adapted π0.5) and the proposed method evaluated after sim-to-real calibration. Success rates averaged over multiple trials demonstrate consistent, often dramatic, gains: for example, the "pick the banana" task improves from 0.27 to 0.53, while "pick the cup" achieves 0.63 versus the baseline 0.30.

Figure 3: Qualitative rollout—framed sequence of the Franka Panda arm successfully completing a manipulation task ("pick the banana") using the LoRA adapter generated in a zero-shot fashion.
Adaptation Efficiency
Notably, generated adapters match or exceed the performance of supervised MT-VLA policies trained with up to 25 demonstrations, but require no labeled data for task inference. Generated weights also serve as excellent initializations ("warm starts"), reducing the number of gradient steps to attain expert-level performance during further fine-tuning.
Qualitative Result Spectrum
The manuscript provides a comprehensive battery of qualitative evaluations spanning atomic manipulations, object-centric tasks, goal-oriented behaviors, and compositional, long-horizon objectives. In each, the zero-shot generated policy aligns motion and action semantics with the provided demonstration and textual instruction, often synthesizing correct trajectories even in novel configurations and with significant distractors.
Theoretical and Practical Implications
This study demonstrates that the weight manifold of LoRA parameterizations for large VLA policies is structured and traversable via multimodal task evidence—a result that has both practical and theoretical ramifications:
- Practical Deployment: Robotic policy adaptation can be performed at deployment time without task-specific optimization, further reducing annotation and compute requirements.
- Lifetime Generalization: Policies can potentially acquire new skills and adapt in-the-wild from minimal human demonstrations, aligning with the long-term goal of scalable, foundation-model–based embodied intelligence.
- Composable Generative Foundations: The approach is extensible to richer forms of policy composition, as the learned manifolds potentially admit algebraic manipulation (e.g., interpolations, extrapolations) presaging more general forms of task generalization.
Limitations and Future Directions
- The method is contingent on the informativeness and unambiguity of task evidence; ambiguous demonstrations lead to unreliable adapters.
- The framework is presently limited to single-task expert generation; performance degrades for long-horizon, composition-intensive tasks (e.g., multi-stage tasks in LIBERO-10).
- Future research could focus on multi-task/adaptive meta-generation, stronger cross-task compositional operators, and scaling to even broader domains and policy classes.
Conclusion
This work establishes that meta-learning in the weight space of adapter-based VLA models is a viable and scalable solution to zero-shot robotic policy adaptation. By leveraging only language and demonstration video, it sidesteps the need for costly supervised adaptation, yielding robust task generalization in both simulation and real-world settings. The results clarify the structure and learnability of the LoRA manifold in large VLA architectures, paving the way for parameter-efficient, demonstration-driven policy generation in general-purpose robotics.
References:
- (2606.07217) Bianchi et al., "Robotic Policy Adaptation via Weight-Space Meta-Learning"
- [jiang2023vima], [wang2025rpg], [liang2025draganddropllmszeroshotprompttoweights], [ha2016hypernetworks], [zhou2025hypergoalnetgoalconditionedmanipulationpolicy], [liu2023liberobenchmarkingknowledgetransfer]