- The paper introduces an end-to-end 3D-native framework that directly generates and edits scenes using a unified mesh-texture representation, bypassing 2D projection artifacts.
- It employs a Diffusion Transformer with text conditioning and a novel 3D REPA loss to achieve explicit semantic alignment and improved multi-view consistency.
- Quantitative evaluations demonstrate state-of-the-art performance in semantic fidelity and editing quality across various benchmarks, reinforcing its potential in AR/VR and design applications.
Native3D: End-to-End 3D Scene Generation via Unified Mesh-Texture Modeling and Semantic Alignment
Introduction
Native3D introduces a fully 3D-native framework for text-driven scene generation and editing that circumvents the limitations associated with 2D projection and hybrid mapping strategies. Existing 3D scene generation approaches either rely on extending robust 2D diffusion models to 3D through multi-view image synthesis or hybrid 2D-3D optimization, resulting in domain adaptation artifacts, geometric inconsistency, and degraded texture detail. Native3D eliminates the 2D-3D domain gap by operating directly in a unified mesh-texture representation space and architecting all generative, editing, and alignment modules natively in the 3D domain. The unified mesh-texture modeling and a novel semantic feature alignment loss—3D REPA—establish a continuous latent space with explicit structure-appearance alignment across object collections, supporting fine-grained, consistent, and semantically controllable indoor scene generation and editing.
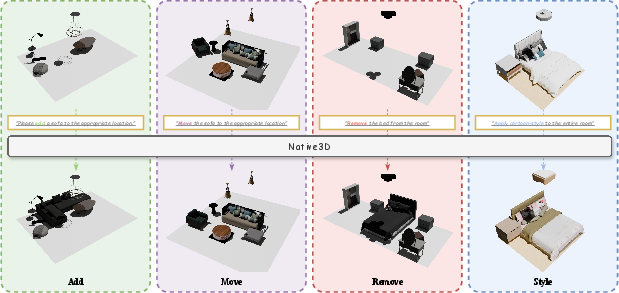
Figure 1: Native3D supports multiple scene editing tasks: object addition, spatial rearrangement, object removal, and appearance style transfer.
Unified Mesh-Texture Scene Representation
Native3D leverages a scene representation that aggregates mesh vertices and per-object texture features across all constituent objects. Each scene is encoded as a union of object meshes and textures, yielding a high-dimensional, information-dense input that preserves spatial topology and semantic interrelations. This representation is processed through a hierarchical Transformer-based encoder initialized from HunYuan3dShapeVAE. Local shape-appearance fusion for each object is handled in the encoder's initial layers, but the critical innovation is the self-attention-based adapter, which aggregates and globally contextualizes inter-object relationships in feature space.
Qualitative results, as shown in the following figure, demonstrate Native3D's robustness in removing and moving objects, as well as performing style transfer, all while preserving geometric and textural consistency:

Figure 2: Qualitative editing results across two bedroom and two dining room scenes. Each row corresponds to one scene, with the first column showing the input scenes, the second demonstrating object removal, the third illustrating object movement, and the fourth showcasing style transfer.
The result is a global latent code encapsulating the scene's structure and style at multiple semantic scales, facilitating subsequent robust diffusion-based editing without the cross-view inconsistencies and geometric hallucinations intrinsic to 2D-driven methods.
Native3D deploys a Diffusion Transformer (DiT) backbone in the 3D feature domain, guided by text conditioning via unified mesh-texture latents and natural language prompt embeddings. Unlike hybrid or projection-based methods, this architecture directly synthesizes and modifies 3D meshes and textures, resulting in improved multi-view consistency and semantic fidelity.
A further critical advancement is the 3D REPA Loss—a multi-level contrastive alignment regularizer enforcing congruence between diffusion latents and 3D semantic features, computed by a frozen Direct3D encoder. This REPA variant operates simultaneously at the global scene and per-object level, using a modified InfoNCE objective to maximize semantic correspondence. The study further integrates an ℓ2 norm latent regularization to enhance training stability under the alignment constraint.
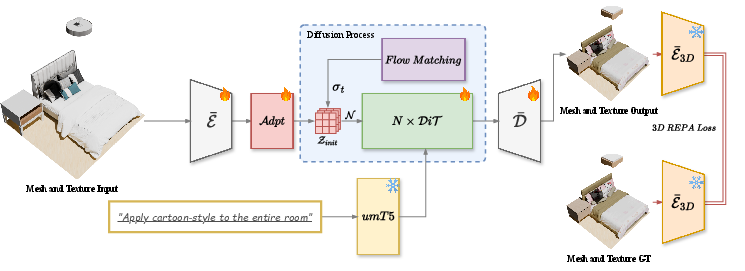
Figure 3: Native3D Overview. Input mesh is encoded through a joint mesh-texture encoder, adapted to target dimension, passed through a diffusion process with text conditioning, and finally decoded to mesh and texture. The frozen Direct3D encoder computes the 3D REPA loss for alignment.
Quantitative and Qualitative Evaluation
Native3D's performance was validated using a large-scale, instruction-driven indoor scene editing dataset with comprehensive evaluation metrics: CLIP Score (CS), Aesthetic Score (AS), BRISQUE (BQ), Inception Score (IS), Fréchet Inception Distance (FID), and a multi-task editing benchmark (ImgEdit-Bench). Compared to baselines such as Text2Tex, SceneTex, RoomTex, and RoomPainter, Native3D achieved the highest CS (32.1) and ranked best on all core structural scene editing operations—Add (4.01), Remove (4.14), Move (2.61)—according to LLM-based evaluation, though it was modestly behind in photorealistic style editing.
The ablation analysis demonstrates that Direct3D-based 3D feature alignment and the full 3D REPA loss significantly impact both semantic alignment and editing quality. Removal of these modules led to degraded control fidelity and increased artifact rates, especially in move/remove operations where topological consistency is crucial.

Figure 4: Ablation study on 3D feature alignment and 3D REPA loss. Lacking 3D alignment modules degrades compliance with instructions and introduces artifacts, confirming their necessity.
Implications and Future Directions
Practically, Native3D provides a scalable and robust foundation for text-driven, multi-object, physically accurate 3D scene synthesis and editing—enabling content creation pipelines in AR/VR, gaming, architecture, and professional design that demand structural integrity and editing flexibility absent from prior frameworks. Theoretically, Native3D establishes the efficacy of direct mesh-texture-latent manipulation with scene-level and object-level feature alignment, setting a precedent for future work in 3D diffusion modeling where explicit geometric and semantic preservation is essential.
Possible extensions include integration of realistic illumination, viewpoint, and neural material models for higher fidelity rendering, as well as expansion into open-world and outdoor scene domains. Joint optimization across perceptual and physical constraints could further enhance the system's generalization and quality.
Conclusion
Native3D constitutes a fully 3D-native, end-to-end generative modeling pipeline—using a hierarchical mesh-texture representation, 3D diffusion-based generation, and multi-level semantic alignment for consistent, controllable scene synthesis and editing. The system achieves state-of-the-art performance in semantic alignment and editing capabilities while paving the way for further convergence between text, structure, and appearance priors in large-scale 3D content creation frameworks (2606.07117).

