- The paper proposes a unified multimodal autoregressive framework that integrates text-to-2D and text-to-3D generation using an interleaved X-to-X training paradigm.
- It leverages large-scale, heterogeneous datasets and custom tokenizers to compress text, images, and 3D meshes into shared token sequences for efficient cross-modal fusion.
- Experimental results demonstrate superior shape-text alignment and geometric fidelity compared to cascaded and diffusion-based methods, highlighting parameter efficiency.
Omni123: Unified Text-to-2D and 3D Generation with Limited 3D Data
Introduction
Omni123 proposes a unified, multimodal autoregressive framework for joint text-to-2D and text-to-3D generation, explicitly targeting the challenge of severe 3D data scarcity relative to abundant 2D web-scale data. The paper critically examines pipeline approaches that use 2D generation as a proxy and iterative optimization for 3D synthesis, noting their frequent failures in maintaining geometric consistency and native multimodal reasoning. Instead, Omni123 introduces an interleaved X-to-X training paradigm—treating text, 2D images, and 3D geometry as discrete tokens in a shared sequence space—to maximize cross-modal knowledge transfer and exploit the implicit 3D priors in image data, without requiring fully aligned text-image-3D triplets.
This unified approach aims to coordinate potentially interfering statistical priors from different modalities, enforce semantic-visual-geometric consistency, and enable practical downstream workflows of generation and editing.

Figure 1: Comparison of methodological paradigms for text-to-3D generation, highlighting contrasts between classical cascaded, optimization-based, and native unified methods.
Data Design and Processing
Omni123 leverages large-scale, heterogeneous paired datasets with strongly curated quality control. The training corpus covers text, images, and 3D assets, parsed into text-image (63.7M), image-3D (120M), and text-3D (9M) pairings, and interleaved SFT (22M) triplets. To align the training with practical 3D-aware tasks, pipeline stages include rendering/canonicalization, synthetic data augmentation, multi-view rendering for explicit viewpoint control, chain-of-thought multi-granularity captioning, and robust filtering for geometric/textural fidelity and alignment.
The resulting text and 3D assets are optimized to bridge the modality gap both with diverse semantic detail and explicit pose information. Viewpoint control is operationalized in subsequent stages by attaching learnable view tokens.
Architecture and Tokenization Framework
Omni123's architecture innovates on the autoregressive transformer paradigm by compressing all modalities (text, image, 3D mesh) into short 1D token sequences. This is achieved via self-developed image tokenizers (with a two-stage VAE and 1D Q-Former extraction) and the Cube3D tokenizer for mesh geometry. Both achieve low reconstruction error and high semantic fidelity for their respective inputs, supporting efficient context lengths and avoiding modality-specific position encoding.
Dual text encoders (CLIP, Qwen3) provide complementary alignment for vision-language and enriched semantic features. The backbone is a dual-stream transformer with joint-attention for cross-modal fusion and subsequent single-stream layers for token prediction, facilitating maximal parameter sharing.
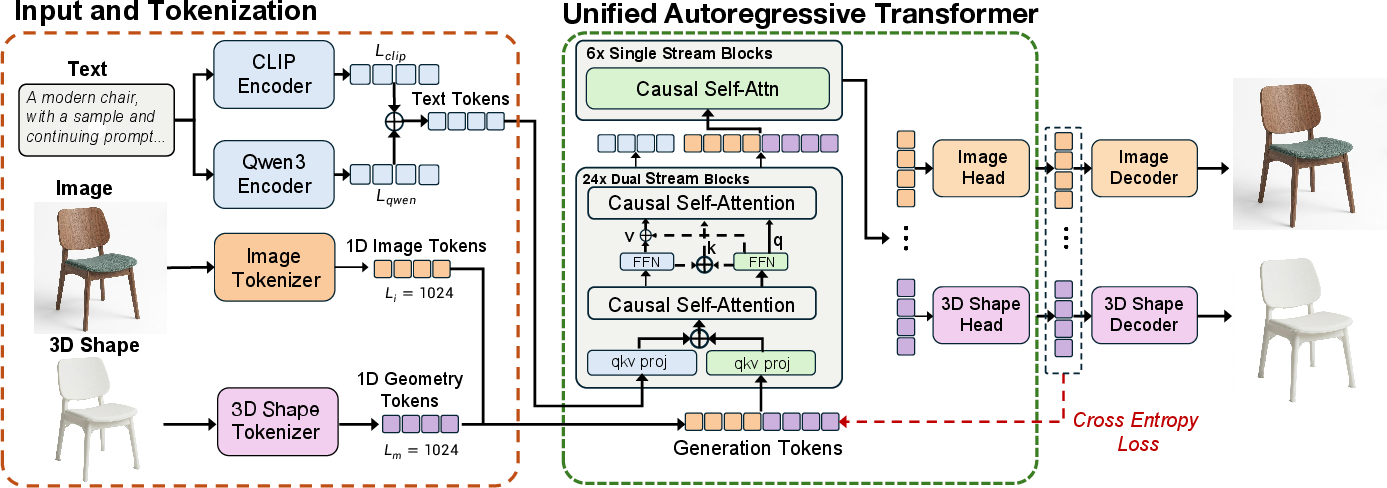
Figure 2: The Omni123 architecture enables concatenated token sequences for text, image, and 3D, processed with shared self-attention to promote strong cross-modal coupling.
Training Curriculum: Cross-Modal Consistency and Viewpoint Awareness
Training proceeds in three interdependent stages:
- Cross-modal Pre-training: Tasks cover text-to-image, text-to-3D, image-to-3D, and 3D-to-image, formulated as next-token prediction. Pool temperature rebalancing and priority weighting address natural imbalances in the data for each direction. Cross-modal generative cycles enforce that the representations satisfy requirements for high-level semantics, image appearance, and explicit geometric consistency.
- Continued Training (CT): Introduces learnable view tokens to accomplish explicit viewpoint-controllable generation. Rendering canonical views for each 3D shape expands the model's native understanding of view-conditioned image synthesis, a critical step for robust projection and 3D-aware downstream tasks.
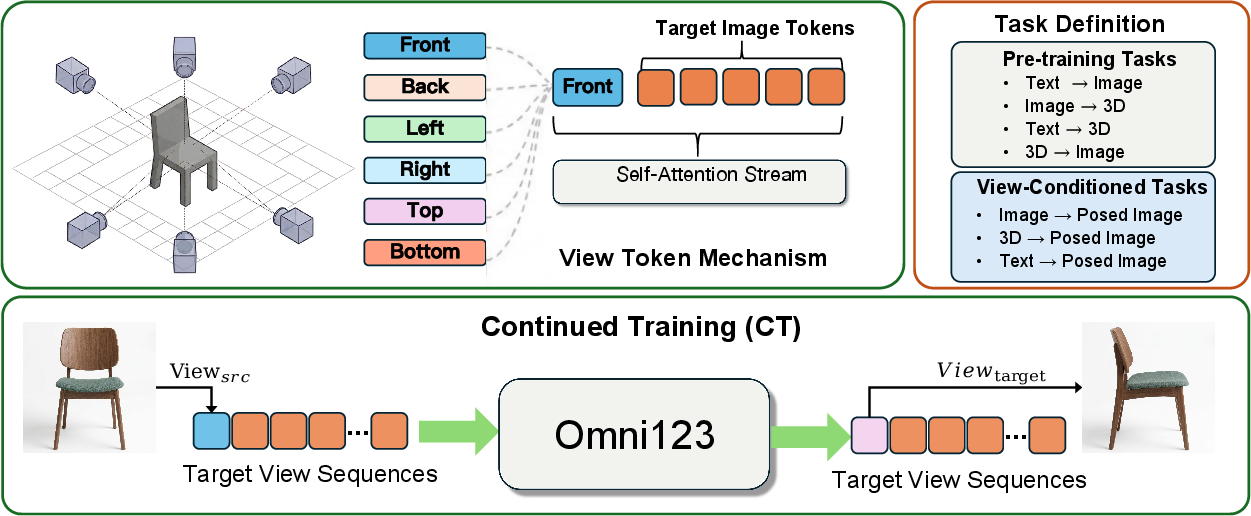
Figure 3: Continued training imbues the model with camera pose conditioning via view tokens, establishing explicit geometric correspondences across modalities.
- Supervised Fine-Tuning (SFT): Implements interleaved, multi-modal generation chains (e.g., text→image→3D→multi-view-image), closing the semantic-visual-geometric loop at the sequence level. This ensures that 3D outputs are not only informed by preceding image generations but are also directly evaluated by their capacity to render consistent multi-view images.
Instruction-Based 3D Editing
Omni123 natively supports language-driven 3D editing by treating source mesh tokens as prefixes and feeding edit instructions as conditioning, yielding autoregressively generated edited mesh tokens. Leveraging 3DEditVerse (the largest high-quality 3D edit dataset), Omni123 aligns structural and appearance modifications with user directives while enforcing minimal disruption to unedited regions and maintaining cross-view consistency through its sequential context.

Figure 4: Omni123's framework naturally enables diverse, iterative 3D generation and editing tasks with high geometric fidelity and semantic control.
Experimental Results
Text-to-3D Generation
Quantitative and qualitative benchmarks against both cascaded (text→image→3D) and native text-3D generation baselines demonstrate that Omni123's cross-modal interleaving achieves superior shape-text alignment. Notably, a 2.2B parameter Omni123 surpasses larger (7B) autoregressive and diffusion-based alternatives (2604.02289). Numerical results indicate improved ULIP-T and Uni3D-T scores compared to both two-stage and native methods, establishing that interleaved X-to-X training is fundamentally more parameter-efficient.

Figure 5: Omni123 generates more consistent, compositionally accurate 3D assets compared to both two-stage and native baseline models.
Instruction-Based Editing
On Edit3D-Bench, Omni123 achieves the lowest Chamfer Distance (CD), indicating superior global geometric fidelity; its F1 scores are competitive despite certain benchmarks being tilted in favor of pipeline-specific training distributions. The ability to propagate cross-modal priors from pre-training enables data-efficient adaptation to fine-grained editing.
Image Tokenizer Analysis
The bespoke 1D image tokenizer demonstrates state-of-the-art FID/PSNR/SSIM on ImageNet-1K, minimizing tokenization-induced degradation. Qualitative results show superior preservation of object structure, textural details, and text rendering over competing methods—crucial for guiding accurate 3D synthesis within the joint sequence.

Figure 6: Comparative reconstructions reveal the tokenizer’s advantage in high-frequency detail and structural preservation across image classes.
Implications and Future Directions
Omni123’s unified framework represents a shift towards native, sequence-level multimodal 3D generation and editing. By recasting diverse synthesis pipelines as interleaved autoregressive sequences, Omni123 exploits implicit geometric priors from 2D data, enabling parameter-scalable 3D world modeling and practical workflows for 3D content creation. Its approach to viewpoint control, explicit cross-modal consistency, and editability closely aligns with emergent needs in embodied AI, robotics, simulation, and interactive design.
However, constraints remain: fixed mesh resolution and predetermined set of canonical views limit its expressiveness for high-complexity or scene-level content. Further work is needed in adaptive-resolution tokenization, generalization to arbitrary camera/viewpoint distributions, and integration of physical/material properties for simulation-ready assets.
Conclusion
Omni123 provides substantive evidence that unifying 2D and 3D generative pipelines within a shared autoregressive token space, with explicit cross-modal and view-conditioned training, dramatically enhances semantic and geometric fidelity in 3D generation and editing, especially under practical 3D data scarcity constraints. This framework establishes a robust foundation for future multimodal, world-centric AI systems that require seamless traversal and manipulation of visual, geometric, and linguistic information (2604.02289).