- The paper introduces a plan-execute paradigm that integrates planning tokens into the action space, significantly improving long-horizon task performance.
- It employs a dual-mode residual vector quantization tokenizer to jointly represent planning and execution tokens, ensuring better temporal alignment and action fidelity.
- Empirical evaluations demonstrate robust enhancements, achieving up to 97.9% success in simulation and near 100% in multi-stage robotic manipulation tasks.
Action-Token Planning for Vision-Language-Action Models: A Technical Analysis of Coarse-to-Control
Motivation and Context
The Coarse-to-Control framework directly addresses core limitations in vision-language-action (VLA) models arising from end-to-end paradigms that map visual observations and language instructions to robot actions without explicit intermediate planning. While progress has been made with architectures such as RT-1, RT-2, and π0 [brohan2022rt1, brohan2023rt2, black2024pi0], direct-generation VLA models commonly struggle with long-horizon manipulation: errors compound due to their inability to explicitly model task-level motor intent, and reasoning burden is concentrated into a single step. Prior attempts to bridge semantic and motor inference have focused on introducing textual [zawalski2024ecot, black2025pi05, huang2025thinkact] or visual CoT [zhao2025cotvla, zhang2025dreamvla], but these intermediates represent intent at a semantic or perceptual level, insufficiently constrained for motor execution.
Coarse-to-Control realigns the intermediate reasoning layer by moving CoT into the action space. By operating in the action-token domain, the framework tackles both the abstraction mismatch and information bottleneck inherent in VLA policies, leveraging a more control-aligned planning medium while maintaining the sample efficiency and deployment advantages of action tokenization.
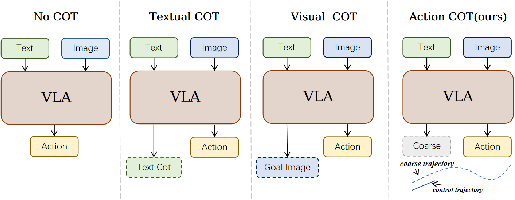
Figure 1: A comparison of reasoning paradigms for VLA control, highlighting textual, visual, and action-token (proposed) chain-of-thought approaches.
Method: Coarse Action-Token Planning with Joint Tokenization
The primary innovation in Coarse-to-Control is the explicit separation of planning and execution within a shared discrete action-token space. Given visual observations, language instructions, and proprioceptive state, the policy autoregressively predicts a sequence of planning tokens representing coarse, motoric intent over an extended horizon, followed by fine-grained executable tokens for immediate control. This plan-execute paradigm is enabled by a dual-mode residual vector quantization (VQ) tokenizer trained to represent both granularities with a unified codebook.
Planning tokens (ztplan) are obtained by summarizing long future action segments into compact representations that encode stage-level robot motion and gripper state transitions, discarding high-frequency details but retaining task-relevant phases. These planning tokens are then provided as prefix context for the executable action token prediction (ztexec), which decodes into continuous robot actions.
This formulation allows chain-of-thought to be realized natively in action space, substantially mitigating the interface mismatch between semantic intent and motor execution.
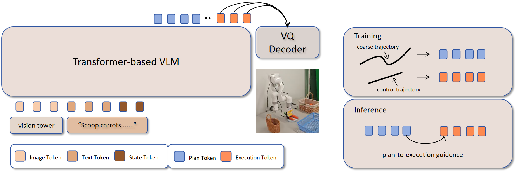
Figure 2: The Coarse-to-Control plan-execute schema; the policy conditions on multimodal context and generates planning tokens before executable tokens, which are mapped to actions.
One core architectural principle is the joint tokenizer design, wherein planning and execution utilize the same discrete vocabulary. This shared latent space ensures alignment: executable actions become conditionally dependent on directly actionable planning prefixes, with improved continuity compared to representations relying on textual or visual abstractions.
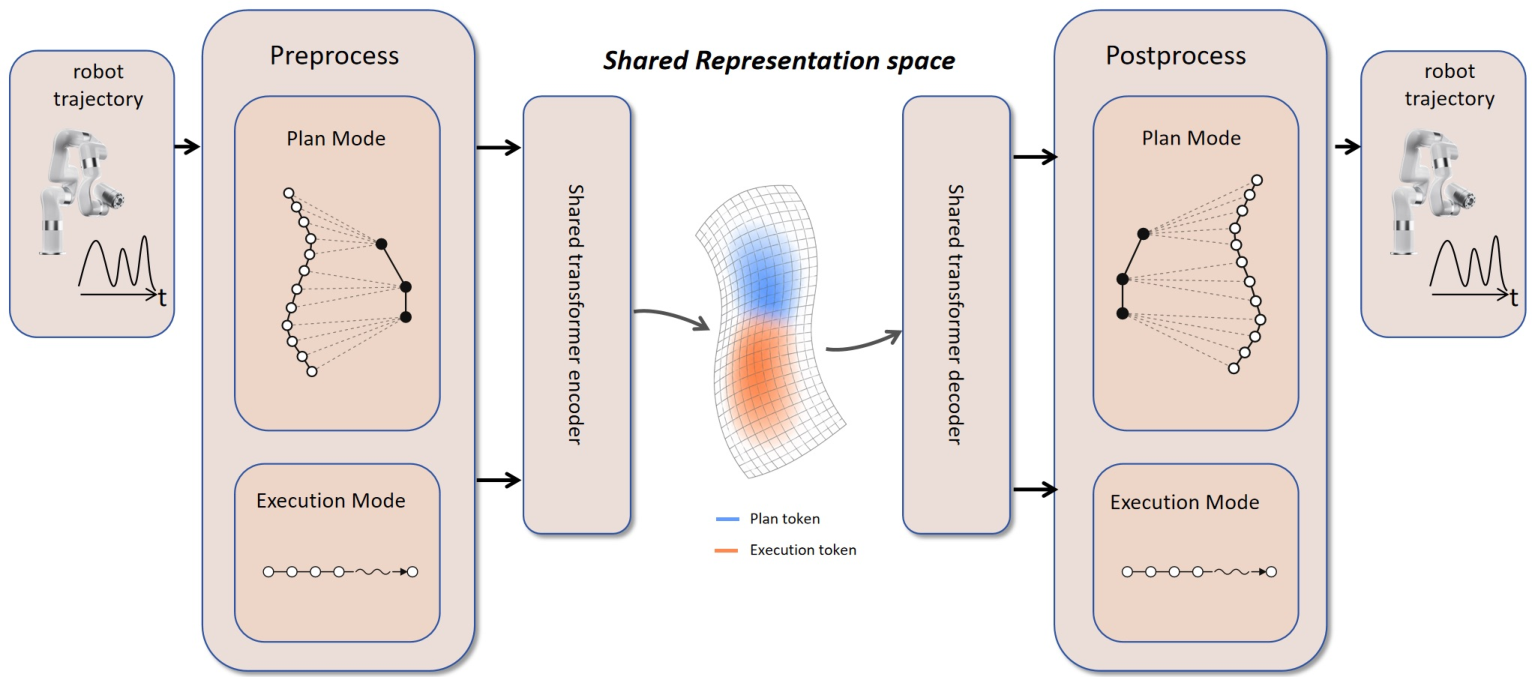
Figure 3: The joint plan-execute action tokenizer: both planning and execution modes are represented in the same discrete token space, supporting information flow and reducing modality mismatch.
Empirical Evaluation
Coarse-to-Control is validated on multiple fronts: comprehensive simulation experiments (LIBERO, SimplerEnv-WidowX) and real-world robotic manipulation tasks explicitly benchmarking long-horizon, multi-stage skill acquisition.
Simulation Benchmarks
LIBERO: On the LIBERO benchmark, Coarse-to-Control achieves an overall success rate of 97.9%, outperforming all evaluated baselines. This includes action CoT approaches such as MolmoAct-7B-D and state-of-the-art action-tokenization models like OpenVLA-OFT and F1. Notably, the gains are most pronounced in the long-horizon (95.0%) and multi-stage (Goal/Object) tasks, supporting the hypothesis that action-space CoT delivers superior temporal credit assignment and intent preservation at scale.
SimplerEnv-WidowX: On real-to-sim tasks, Coarse-to-Control attains an average task success of 83.3%, with several tasks (e.g., PutSpoon, PutCarrot) consistently solved at near 100%—substantially ahead of visual or textual CoT baselines.
Real-World Manipulation Tasks
In physical robotic evaluations, Coarse-to-Control exhibits a 62.5% average success across four manipulation tasks. The improvements are especially salient in multi-stage settings: plan-based policies outperform direct action generation baselines by a wide margin on Plate→Basket and Cleanup, where maintaining intermediate progress and mitigating error accumulation is critical.
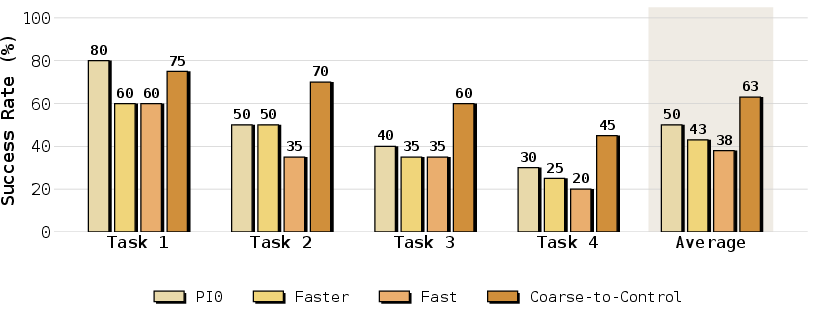
Figure 4: Real-world task success rates for four benchmark tasks, illustrating robustness gains from action-token planning.

Figure 5: The physical hardware setup and representative task frames, covering diverse long-horizon manipulation scenarios.
Mechanistic Analysis and Ablations
A series of ablations further clarify the efficacy and design of the action-token planning approach:
- Planning Horizon: Increasing planning horizon directly enhances task performance. On LIBERO, expanding the planning context from 0 to 160 steps improves overall success from 96.45% to 97.90%, with the greatest boost observed in the most temporally extended (Long) suite. This demonstrates that temporally extended intent encoding reduces error accumulation and increases subgoal satisfaction.


Figure 6: Qualitative and quantitative analysis of planning horizon impacts and planning-token attention; joint-mode action-token planning aids downstream execution focus and spatial intent.
- Token Sharing: Using a joint tokenizer (versus separate codebooks for planning and execution) further increases overall and long-horizon success, highlighting the importance of maintaining a shared token geometry and minimizing representational translation overhead.
- Qualitative Diagnostics: Attention head analysis reveals that presence of planning tokens anchors policy focus to task-relevant objects and contact points—unlike no-plan settings, where attention is diffused. Decoded coarse plans already indicate correct object-goal trajectories even in early plan phases.
Theoretical and Practical Implications
Action-token chain-of-thought instantiates a new paradigm for intermediate representation in embodied policy learning, departing from natural language and visual reasoning toward control-aligned, discrete-guidance signals directly exploitable by downstream execution. By embedding hierarchical intent in the action vocabulary, Coarse-to-Control enhances the compositionality and robustness of VLA models while retaining sample efficiency, tractable inference, and model simplicity.
Practically, the approach demonstrates tangible improvements in both simulation and real-world settings, robustly transferring long-horizon planning benefits. Its modularity—requiring no external planner or interface—further facilitates integration with current VLA backbones.
The main limitations stem from the expressiveness of fixed, discrete planning tokenization: future work should explore adaptive, dynamically scoped planning and more flexible action reasoning formats, as well as further scaling analyses.
Conclusion
Coarse-to-Control advances the state of vision-language-action policy learning by internalizing chain-of-thought in the action-token space. Empirical results substantiate consistent improvements over direct and semantic reasoning baselines, especially for long-horizon, multi-stage manipulation. The plan-execute methodology, centered on a shared action-token vocabulary, provides a succinct, control-centric intermediary—paving the way for further research in motor-level reasoning, hierarchical control, and autonomous multi-step decision-making in VLA systems (2606.07107).