- The paper introduces an MDP-based taxonomy that decomposes sim-to-real gaps in FM agents into observation, action, transition, and reward discrepancies.
- It details practical stress-test strategies by adapting RL techniques like domain randomization and action shielding, evidenced by a 9x increase in error rates under multilingual conditions.
- The work advocates for standardized benchmarks and community adoption of robustness techniques to enhance the reliable deployment of FM agents in real-world environments.
Introduction
The deployment of foundation model agents (FM agents) in real-world decision-making has catalyzed rapid adoption across diverse domains, from tool-augmented LLM assistants to robotics and autonomous systems. Despite their impressive performance on academic benchmarks, these agents face substantial generalization failure when transitioned from simulation (i.e., curated training environments) to dynamic real-world environments—a phenomenon known as the sim-to-real gap. This essay summarizes and critically reviews "The Sim-to-Real Gap of Foundation Model Agents: A Unified MDP Perspective" (2606.07017), which advocates for a unification of sim-to-real analysis under the Markov Decision Process (MDP) formalism, leveraging decades of insights from RL and classical control to systematize and benchmark FM agent robustness failures.
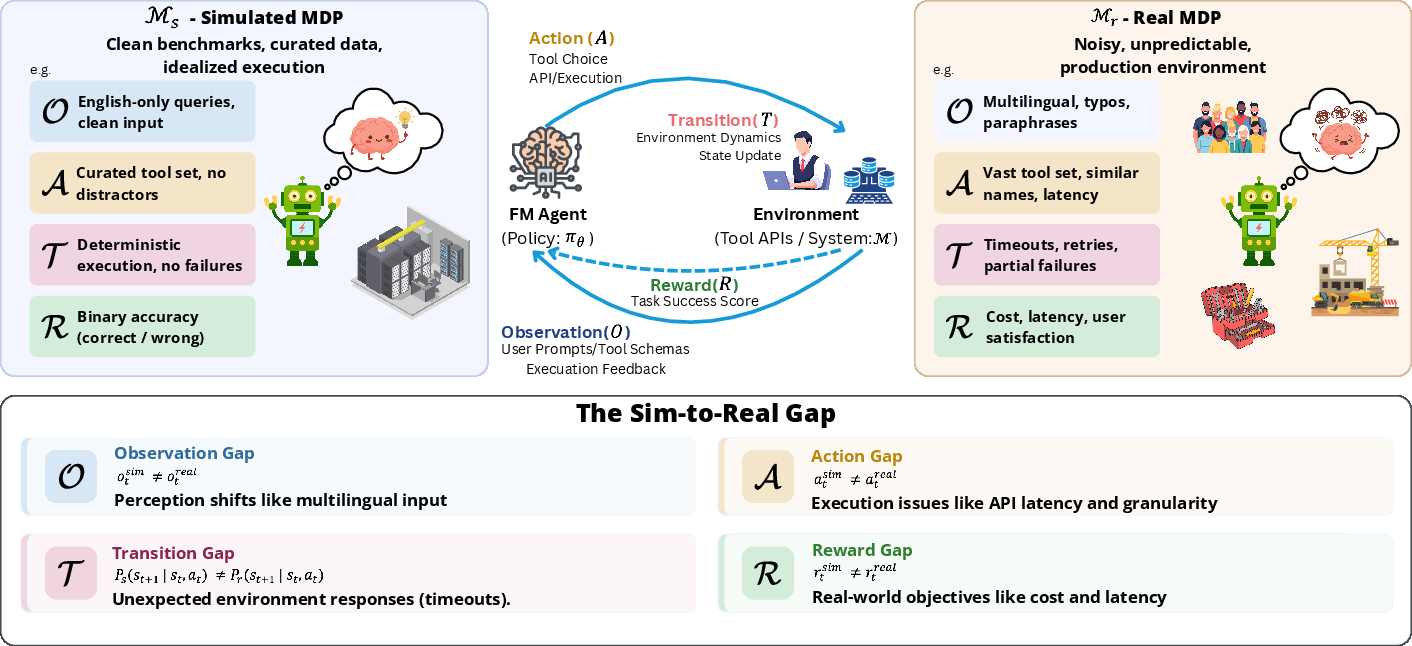
Figure 1: High-level depiction of sim-to-real transfer for FM agent systems, decomposing the total gap into observation, action, transition, and reward discrepancies.
The paper posits that the reliability failures observed in FM agents parallel well-studied discrepancies in RL, which manifest in the four canonical MDP elements: Observation (O), Action (A), Transition (T), and Reward (R). The core thesis is that each dimension experiences its own form of distribution shift or perturbation as agents are deployed, and these can be stress-tested and mitigated through principled adaptations of RL sim-to-real methodologies.
The observation gap originates from the distributional dissimilarity in what agents perceive during training versus deployment, often due to noise, partial observability, or semantic mismatches. Action gaps arise when simulated actions are not aligned with those required or allowed in real world due to discretization, delays, or ambiguous choices in tool-rich environments. Transition gaps encapsulate imperfect modeling of environment responses, including stochastic API errors and nondeterministic effects absent in simulators. Finally, reward gaps result from discrepancies between simulated reward proxies (often oversimplified or idealized) and real-world objectives, which may embed operational efficiency, latency, or hidden costs.
Mapping RL Sim-to-Real Methods to FM Agents
The paper systematically maps classical RL sim-to-real mitigation strategies to FM agent contexts:
- Observation: Domain randomization and adaptation, long used to improve vision policy transfer [tobin2017domain, bousmalis2017unsupervised], are applicable to FM agents by injecting linguistic noise, typos, or multilingual paraphrases into training inputs. Sensor fusion analogues involve annotating and combining multiple modalities (e.g., vision, speech, text).
- Action: Action shielding and delay-aware control are recast as mechanisms for filtering out-of-distribution tool calls and handling long-latency or ambiguous tool APIs. Adversarial action space perturbations (e.g., distractor tools) stress-test semantic understanding as opposed to naive lexical matching.
- Transition: Grounded action transformation and dynamics randomization are reframed as augmenting FM agent environments with stochastic API failures, incomplete payloads, and transient errors, forcing agents to develop robust fallback and error-handling strategies.
- Reward: Reward shaping and augmentation migrate to FM agent settings as scenarios that prioritize operational metrics (e.g., financial cost, completion time) over task completion alone, requiring agents to resolve trade-offs and optimize for deployment-level efficiency.
Canonical Failure: Multilingual Observation Gap
A central concrete example addressed is the multilingual observation gap for tool-calling LLMs. In real deployment, agents are queried in diverse natural languages, but underlying APIs expect strict parameter value conventions (often English). The paper shows that major models (e.g., GPT-5, Qwen3-Next-80B) exhibit dramatically increased execution errors when exposed to user instructions in languages unseen during training, even if intent, tool selection, and high-level planning are correct. For instance, error rates for Qwen3-Next-80B ascend from 5.5% on English to 46.5% on Chinese instructions—a nearly 9x increase.
This gap is not semantic but structural: parameter value "language mismatch" leads to API failures despite correct intent. These results establish the necessity for observation-space randomization, cross-lingual alignment, and format-invariant interface training in the FM agent pipeline.
Benchmarking and Evaluation Protocols
The paper calls for standardized stress-test benchmarks targeting each MDP component. For observations, this includes noise injection, multilingual perturbations, and cross-modal corruption protocols. For actions, construction of cluttered and ambiguous tool sets tests semantic grounding. For transitions, systematic introduction of delays, timeouts, and partial successes measures real-environment robustness. For rewards, multi-objective evaluations introduce shifting optimization criteria (e.g., cost, time, resource usage) that go beyond task accuracy.
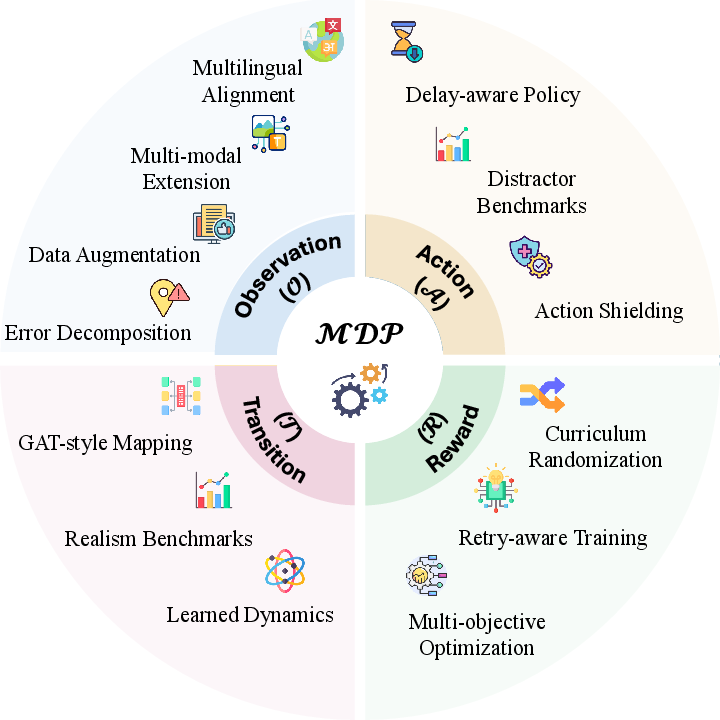
Figure 2: Overview of research directions aligned with the MDP loop, delineating prioritized open challenges and concrete methodologies for each gap dimension.
The paper specifically advocates for leaderboards and shared libraries that report gap-specific as well as aggregated robustness metrics, to facilitate reproducible benchmarking and fair comparison across models and interventions.
Implications and Future Research
Adopting the unified MDP-driven perspective has immediate theoretical and practical consequences:
- Theory: It enables rigorous attribution of suboptimality to specific sources, thus clarifying when failures are inherent to language reasoning vs. interface fragility vs. modeling misspecification. This formalization advances the science of reliability in complex agentic systems.
- Practice: Developers and deployers benefit from stress-test protocols reflecting real-world complexity, enabling reliable system hardening before deployment. The active integration of RL robustness mechanisms (e.g., curriculum randomization, domain adaptation) into LLM agent pipelines is expected to yield quantifiably more trustworthy systems.
- Open Challenges: The paper makes explicit that the joint interaction of multiple gap types (e.g., simultaneous observation and transition perturbations) remains unsolved, as do protocol design questions for multi-agent and multi-modality integration. There is little evidence that sheer model scaling naturally closes these gaps without targeted interventions.
The outlined research agenda points toward the need for error decomposition, robustness scaling analyses, and new stress-test corpora that systematically expose FM agent vulnerabilities in realistic scenarios, grounded in operational efficiency as well as correctness.
Conclusion
This work reframes FM agent robustness as a classical sim-to-real challenge, proposing an MDP-based taxonomy and evaluation framework that standardizes vocabulary and benchmarking for observation, action, transition, and reward gaps. Through quantitative and qualitative evidence, the authors demonstrate that systemic vulnerabilities persist across major SOTA models, particularly in cross-lingual and complex tool-use settings. The paper's proposed roadmap—porting RL robustness techniques, expanding stress-test corpora, and driving community adoption of universal protocols—charts a clear path for elevating FM agent reliability to meet real-world operational demands while opening significant new avenues for fundamental research in trustworthy, generalizable AI systems.

