- The paper introduces RobustBench-TC, a sim-to-real benchmark that simulates 22 realistic perturbation types across POMDP components for tool-use agents.
- It benchmarks 21 model variants, revealing that scaling fails to mitigate reward and transition robustness gaps, with degradations up to 40%.
- The proposed ToolRL-DR approach reduces transition errors by 27% and improves retry strategies, demonstrating effective behavioral transfer.
Tool-Use Agents Under Realistic Perturbations: Sim-to-Real Gaps and Domain-Randomized RL
Introduction and Motivation
Tool-use language agents, typically evaluated on benchmarks with pristine conditions, face a marked sim-to-real gap when deployed in production. The assumptions of clean user queries, unambiguous tool registries, and deterministic tool APIs are routinely violated in practical scenarios, resulting in brittle agent behavior. Production failures—ranging from typographical errors in user queries to ambiguous tool metadata or transient API failures—highlight the necessity for more realistic evaluation frameworks and robust training strategies. The paper "When Simulation Lies: A Sim-to-Real Benchmark and Domain-Randomized RL Recipe for Tool-Use Agents" (2605.11928) addresses these issues comprehensively by introducing RobustBench-TC, a sim-to-real perturbation benchmark, and ToolRL-DR, a domain-randomized RL training approach targeting these perturbations.
The core insight of the work is the formulation of tool use as a partially observable Markov decision process (POMDP) where noise and disruptions can corrupt the agent's performance at multiple loci:
- Observation perturbations: e.g., typos, paraphrasing in queries or tool descriptions.
- Action space perturbations: injected distractor tools, ambiguous argument mappings.
- Reward metadata perturbations: misleading or abbreviated tool names and descriptions.
- Transition perturbations: runtime errors in tool execution, requiring retries.
These axes are systematically instantiated in RobustBench-TC, with 22 perturbation types, each grounded in documented incidents from open-source agent frameworks and peer-reviewed robustness studies. The POMDP decomposition provides a principled taxonomy (Figure 1), greatly extending prior robustness studies that consider only isolated failure modes.
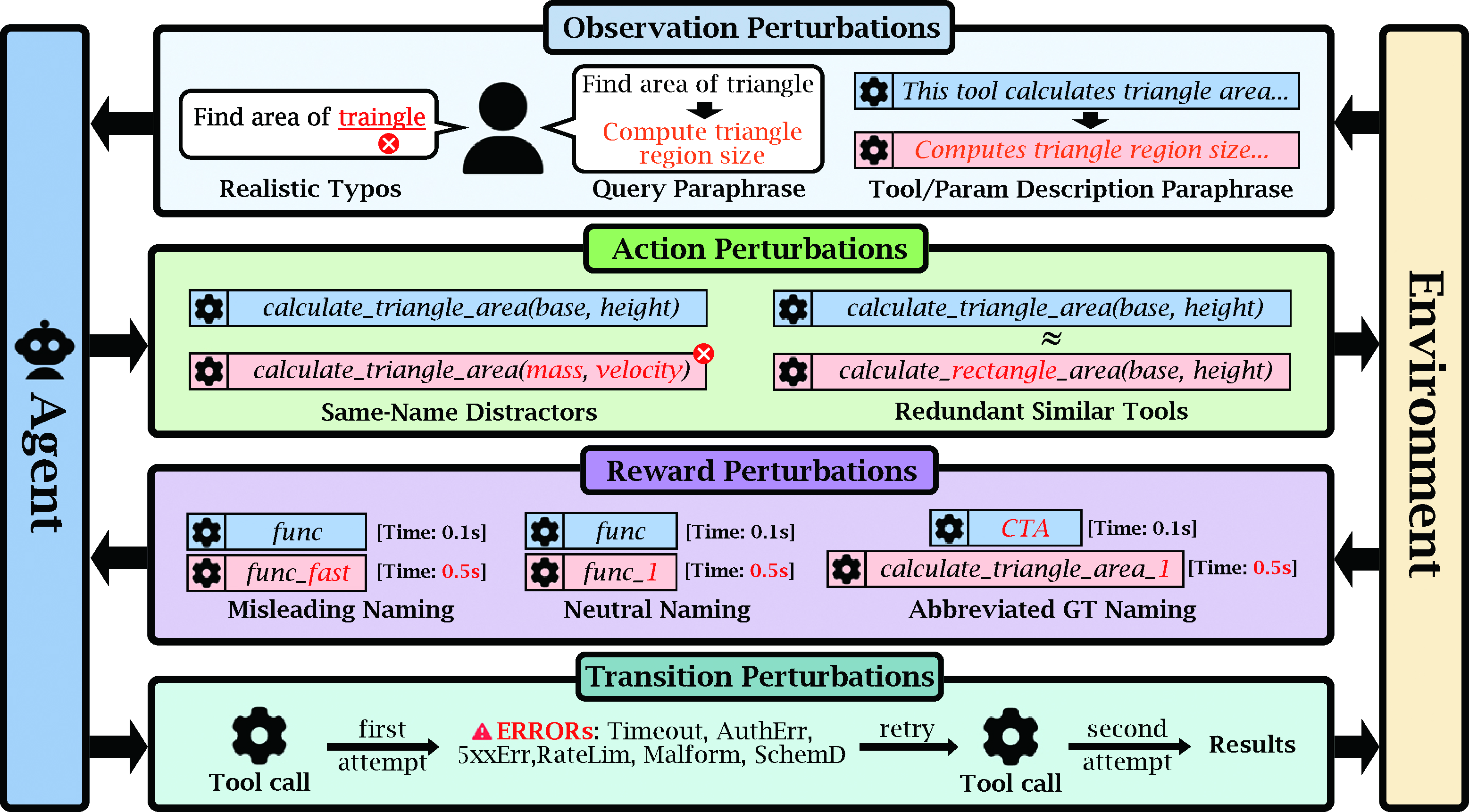
Figure 1: The POMDP structure underlying tool-use agents, with four principal perturbation categories: Observation, Action, Reward, and Transition.
RobustBench-TC: Benchmark Construction and Production Grounding
RobustBench-TC overlays realistic error models on five widely-used tool-use datasets, producing 3,721 evaluation samples that span the full perturbation taxonomy. Perturbation methods range from LLM-assisted paraphrasing to deterministic rule-based modifications or explicit injection of canonical error strings at runtime. Each perturbation type is tightly linked to production failures, with source code available, facilitating transparent external validation and continuous benchmarking.
The construction methodology ensures that each perturbation emulates actual deployment failures rather than contrived adversarial attacks. For action and reward perturbations, modifications include duplicate tools with ambiguous parameterizations and intentionally misleading descriptions; for transition errors, the evaluation environment reliably injects transient API-level faults.
Experimental Findings: Failure Modes and Scaling Laws
Twenty-one agent variants, spanning parameter counts from 1.5B to 32B, including both RL-trained and instruction-tuned models, are systematically benchmarked.
Key empirical findings:
- Sim-to-real gaps are severe and uneven:
- Observation perturbations yield negligible performance loss (less than 5% accuracy drop).
- Reward and transition perturbations induce substantial degradations—mean gaps of ~40% and ~30% respectively, invariant to model scale.
- Action perturbations have intermediate impact, primarily caused by ambiguous distractor tools.
- Scaling LLMs does not resolve production fragility:
- In all evaluated model families, including leading 32B RL-trained models, increased parameter count fails to ameliorate performance deficits on reward and transition perturbations (Figure 2, Figure 3).
- The absence of robustness gains from scaling underscores limitations inherent in data and training distribution rather than model capacity alone.
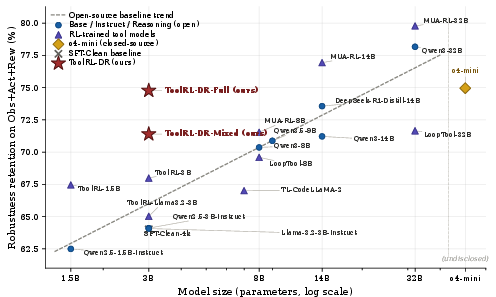
Figure 2: Robustness retention with respect to observation, action, and reward perturbations as a function of model size; larger models do not close the gap in reward and transition robustness.
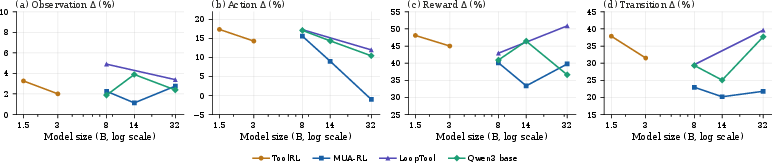
Figure 3: Per-POMDP-component accuracy drop versus model size for multiple model families; only minor improvements in robustness are observed as models scale from 8B to 32B.
- Error mode analysis confirms that under transition perturbations, RL-trained baselines predominantly either retry incorrect tool calls with minor argument changes or prematurely omit retries, demonstrating a lack of persistent and adaptive recovery strategies.
Domain-Randomized RL: ToolRL-DR and Behavioral Transfer
To address these robustness failures, ToolRL-DR replaces clean fine-tuning trajectories with perturbation-augmented ones, sampled from all statically encodable POMDP components except transition perturbations (which require runtime-in-the-loop rollouts). This RL schema is based on GRPO and evaluated with fully-controlled ablations (DR-Full, DR-Mixed).
Salient results:
- ToolRL-DR-Full achieves a 27% reduction of the transition gap and similar closure on reward perturbations relative to ToolRL-Clean—even without explicit exposure to transition errors during training.
- The perturbed RL agent exhibits a more persistent retry policy: omitted-call rate under transition errors drops from 47.0% (ToolRL-Clean) to 34.2% (ToolRL-DR-Full), converting premature giveups into successful or at least persistent retries.
- Aggregate perturbed accuracy for the 3B ToolRL-DR-Full checkpoint becomes competitive with 14B and 32B open-source function-calling models, despite being orders of magnitude smaller.
These results (Figure 4) substantiate that domain-randomized RL on static perturbations induces non-trivial behavioral transfer to unseen runtime failures.
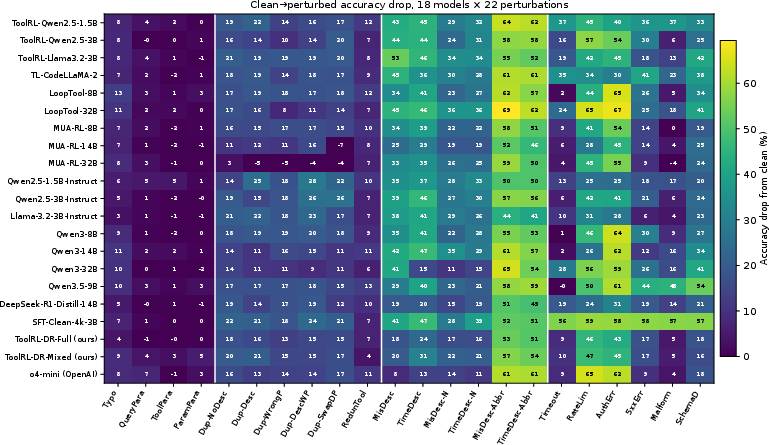
Figure 4: Per-model, per-perturbation accuracy drop heatmap for all 21 models and 22 types, visually confirming that ToolRL-DR models exhibit smaller drops in the Reward and Transition blocks compared to other 3B baselines.
To institutionalize ongoing progress measurement, the authors provide a public-facing RobustBench-TC leaderboard. It computes per-component robustness, supports community submissions, and catalyzes transparent comparison and continuous improvement (Figure 5, Figure 6). The platform aligns with established evaluation practice (e.g., BFCL), but extends it with fine-grained perturbation axes reflecting real-world deployment risk.
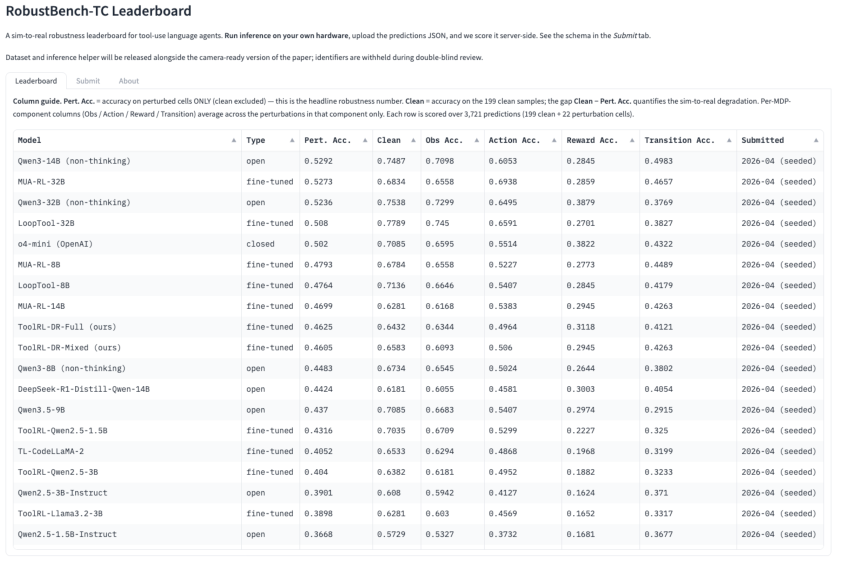
Figure 5: Interactive leaderboard view summarizing per-component accuracy and aggregate perturbation scores across all submissions.
Figure 6: Leaderboard submission interface, streamlining reproducible evaluation and fair comparison using a deterministic server-side scorer.
Implications, Limitations, and Future Directions
Practical Implications:
- Evaluation of tool-use agents must systematically incorporate realistic perturbation scenarios across all POMDP components. Clean-benchmarked accuracy is not predictive of production reliability.
- Domain-randomized RL offers a viable path for closing much of the robustness gap with modest backbone scale and tractable training costs.
Theoretical Implications:
- Transfer of retry policies from static to dynamic perturbations suggests a generalization benefit from adversarially broadened rollouts, echoing findings in sim-to-real robotics.
- Failure of scale to improve transition or reward robustness, absent appropriate data augmentations, reinforces the need for task-specific environment randomization.
Limitations & Open Problems:
- The experiments are restricted to single-turn tool-use settings; evaluation and RL support for multi-turn agent dialogues, long-horizon dependencies, and compositional tool use remain open.
- Further transition robustness likely requires RL with online error responses and custom retry-aware objectives, or curated test-time strategies.
- The scalability of ToolRL-DR to larger backbones and broader data remains to be established.
Conclusion
This work reframes tool-use robustness as a sim-to-real challenge, operationalizing a POMDP-based taxonomy of real-world perturbations and demonstrating both the magnitude of current model fragility and the efficacy of domain-randomized RL in bridging the gap—particularly for reward- and transition-driven errors. The partial behavioral transfer to untrained transition errors highlights the value of adversarial training even in the absence of online error-rollouts. The benchmark, training recipe, and leaderboard together constitute a foundation for systematic robustness measurement and progress in tool-use agent reliability (2605.11928).