- The paper introduces a novel Cogito-Pipe pipeline that systematically curates high-quality audio reasoning data for LALM training.
- It employs self-distillation with chain-of-thought tracing to enhance interpretability and accuracy, outperforming existing models on the MMAR benchmark.
- The open-source framework bridges the performance gap with proprietary systems, enabling advanced and explainable audio reasoning in varied scenarios.
Audio-Cogito: An Open-Source Framework for Deep Audio Reasoning
Introduction
Audio-Cogito introduces a systematic methodology for constructing and training Large Audio LLMs (LALMs) with enhanced deep reasoning capabilities over audio input. Existing LALMs underperform in complex reasoning, mainly due to the absence of well-annotated reasoning datasets and methodologies closely integrated with model architectures. Audio-Cogito addresses these limitations by proposing a comprehensive data curation pipeline—Cogito-Pipe—and a training regimen leveraging self-distillation with large-scale, high-quality audio reasoning tasks. Results on the MMAR benchmark and Interspeech 2026 Audio Reasoning Challenge confirm this framework as a state-of-the-art open-source system for deep audio reasoning, demonstrating robust performance across diverse domains and superior logical interpretability in Chain-of-Thought (CoT) settings.
Cogito-Pipe: Systematic Data Pipeline for Audio Reasoning
The core of the Audio-Cogito approach is Cogito-Pipe, a four-stage pipeline designed for scalable generation of high-fidelity audio reasoning datasets, which is critical for advancing model reasoning depth and stability.
Cogito-Pipe comprises:
- Data Collection: Amasses large-scale, multi-domain audio data (sound events, speech, and music), with a focus on mixed/interleaved acoustic scenes. Metadata enrichment ensures contextual richness for downstream QA tasks.
- QA Construction: Utilizes Qwen3-Omni-Instruct for instructive QA generation, guided by a curated seed pool of ~500 diverse, expert-refined questions. The process integrates confusing distractors for robust negative sampling and supports one-to-many QA associations per audio segment.
- CoT Generation: Implements a self-distillation strategy via Qwen3-Omni-Thinking to generate free-form reasoning traces. Ground-truth answers are withheld to enforce answer derivation strictly from acoustic evidence, fostering intrinsic logical grounding.
- Quality Verification: Enforces quality through dual-stage auditing: a QA-consistency check and LLM-based logic judgment (LLM-as-a-Judge), effectively filtering out hallucinations and inconsistencies.
The interchangeability of pipeline components enables extensibility and compatibility with evolving LALM architectures.
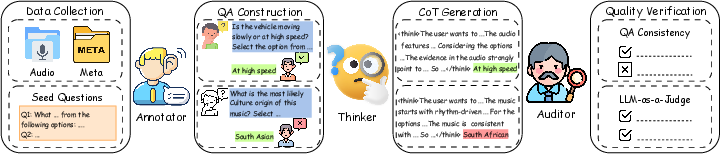
Figure 1: Cogito-Pipe overview, detailing the staged process for generating multimodal, high-quality audio reasoning datasets.
Model Architecture and Training
Audio-Cogito leverages Qwen3-Omni-Thinking (30B parameters) as its backbone, with LoRA-based supervised fine-tuning on the Cogito-Pipe dataset. Each training sample integrates audio input, text query, structured reasoning trace (CoT), and ground truth answer. The training objective maximizes the joint log-likelihood of reasoning trace and answer, explicitly aligning model behavior with human-like problem-solving protocols. This structuring ensures both answer accuracy and transparent, logically coherent intermediate reasoning steps.
Evaluation Protocols
A key innovation in this study is the focus on explainable audio reasoning rather than mere outcome accuracy. The MMAR benchmark is employed, prioritizing evaluation of the intermediate CoT process. Metrics include:
- Avg (Average Accuracy): Proportion of QA pairs with correctly predicted answers.
- Rubrics Score: Assessment of stepwise CoT validity, based on LLM judge evaluation of rubric criteria derived from ground-truth reasoning.
- CRS (Correct Reasoning Score): Average rubric score conditioned on correct answers, quantifying logical rigor in successful predictions.
This framework reveals not just task performance but the validity and reliability of the model’s reasoning chain.
Experimental Results
Audio-Cogito outperforms all open-source models across LALM, OLM, and LARM classes on MMAR, demonstrating robust generalization to single and mixed-domain audio reasoning tasks.
Notably:
- Superior accuracy: Audio-Cogito exceeds Qwen3-Omni-Thinking by 5.44% (relative) in average accuracy and delivers especially strong gains in mixed-domain inference.
- Narrowing the proprietary gap: Performance matches or exceeds leading closed-source systems (e.g., Gemini 2.0 Flash, Gemini 2.5 Flash, Omni-R1, GPT-4o Audio) in several metrics and domains, and nearly matches Gemini 2.5 Pro in complex scenarios.
- Robust logical quality: Achieves SOTA Rubrics and CRS among LARMs, underscoring holistic, logically sound CoT reasoning.
Ablation studies confirm that all Cogito-Pipe components—seed question pool, meta-information enrichment, and stringent quality verification—are indispensable, with the removal of any stage resulting in a quantifiable performance and reasoning degradation.
Implications and Future Directions
Audio-Cogito’s open-source, modular design catalyzes further research by providing a reproducible, extensible pipeline for deep audio reasoning. The demonstrable improvements in reasoning trace quality, particularly with self-distillation, underscore the necessity of closely aligned data construction and training strategies for robust LALM development.
Practically, Audio-Cogito can underpin advanced audio agents requiring interpretable and reliable decision-making—such as clinical audio diagnostics, intelligent assistant systems, and audio scene interpretation. Theoretically, the findings support the centrality of CoT and rigorous data curation in transferring LLM-style reasoning to complex, high-variance acoustic environments.
Moving forward, further scaling of dataset diversity, domain coverage, and model parameterization—combined with improved rubric construction protocols and adversarial QA augmentation—can be expected to enhance LALM robustness and generalizability in unconstrained, real-world audio reasoning tasks.
Conclusion
Audio-Cogito establishes a new state-of-the-art in open-source audio reasoning, showcasing the criticality of systematic, high-quality data pipelines and self-consistent CoT learning frameworks. The approach bridges the gap between proprietary and open models in deep audio understanding, validating the transferability of CoT paradigms to the audio modality. Its practical and theoretical contributions set the foundation for the next generation of explainable, multimodal reasoning systems in speech and audio AI.

