- The paper introduces an aligned audio-text dataset with multimodal logical triplets, chain-of-thought explanations, and structured reasoning annotations.
- It leverages a reinforcement learning framework with reward modules for answer accuracy, format correctness, and reasoning length to enhance multimodal output.
- Empirical evaluations show significant accuracy gains across audio-to-text, text-to-audio, and audio-to-audio scenarios, with ablation studies highlighting each reward's impact.
SoundMind: Reinforcement Learning-Incentivized Logic Reasoning for Audio-LLMs
Introduction and Motivation
Recent progress in LLMs has enabled complex logical reasoning in textual and, more recently, visual modalities. However, the extension of these capabilities to audio-LLMs (LALMs) remains fundamentally inadequate, primarily due to limited reasoning-focused audio benchmarks and the challenge of generating consistent, stepwise audio explanations. The "SoundMind: RL-Incentivized Logic Reasoning for Audio-LLMs" (2506.12935) paper systematically addresses these deficits by introducing both an aligned, reasoning-centric audio-text dataset (SoundMind) and a task-specific reinforcement learning (RL) optimization method (SoundMind-RL). This dual contribution establishes a practical foundation for advancing audio-based stepwise reasoning and lays out a clear empirical methodology for multimodal logic task evaluation.
The SoundMind Dataset: Design, Structure, and Motivation
SoundMind is constructed to specifically enable audio logical reasoning (ALR) tasks. It comprises 6,446 samples, each with carefully aligned multimodal annotations: user prompts, structured logical triplets, chain-of-thought (CoT) reasoning, and final entailment decisions, all provided in both text and speech audio. Unlike predecessors, SoundMind ensures that CoT rationales and answers accompany each sample for both input and output in the respective modalities, thus enabling fine-grained supervision of both textual and spoken inference.
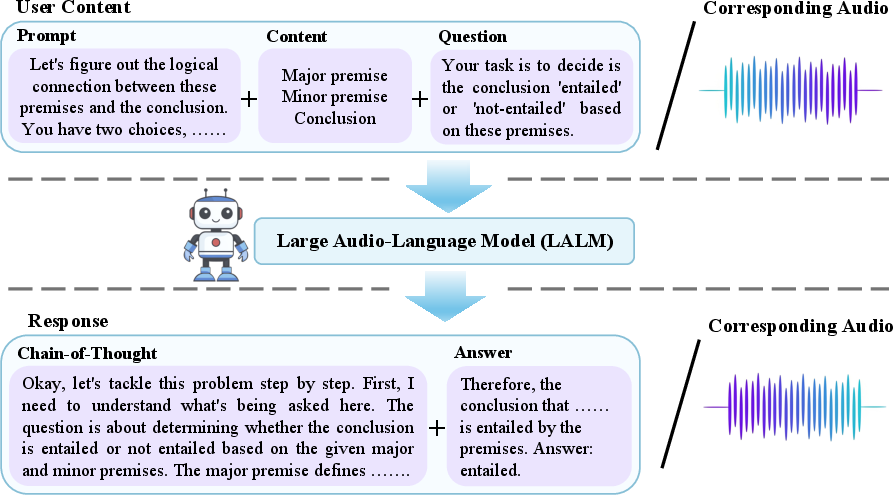
Figure 1: A SoundMind sample for ALR, with prompt, logical structure, question, detailed reasoning, and final answer—each in text and speech audio—enabling rigorous multimodal evaluation.
Data construction employs a three-stage pipeline:
- Colloquialization rewrites logical triplets into natural conversational prompts using LLMs.
- Chain-of-thought explanations and answers are automatically generated.
- Sequentially, both sides are synthesized into speech, yielding tightly paired audio segments.
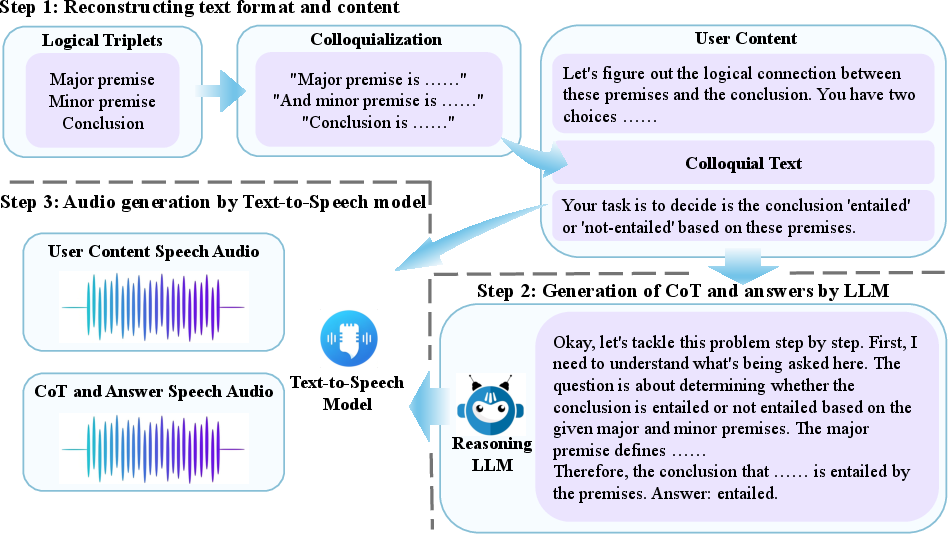
Figure 2: The pipeline for SoundMind instance construction, spanning triplet colloquialization, automatic CoT and answer generation, and high-fidelity TTS synthesis for both prompt and response.
Each ALR sample is thus structured for both auditory and textual input-output mappings, precisely aligned at the utterance and reasoning level. This explicitly facilitates the training and evaluation of LALMs not only for their ability to map audio to text or vice versa, but also for end-to-end reasoning and explanation directly within the audio domain.

Figure 3: SoundMind sample breakdown: natural-language prompt with logical triplet, stepwise CoT trace, and final answer—all accessible as both text and synthesized audio.
Dataset analysis reveals its substantial focus on long-form reasoning: average prompt duration is ~1 minute, while CoT reasoning audios average ~10 minutes. This distinguishes SoundMind from prior benchmarks, where either modality alignment or extended reasoning annotation is typically absent. A diverse and near-balanced class distribution of "entailed" and "not-entail" instances across splits ensures robust generalization and reliable model benchmarking.
The SoundMind-RL Framework: Rule-Based Multimodal RL for Audio Reasoning
SoundMind-RL builds on advances in rule-based RL for reasoning tasks (e.g., DeepSeek-R1, Logic-RL) with modifications for the audio modality. It enhances reasoning performance through several reward modules:
- Format correctness (text/audio): Rewards strict adherence to required logical output structure in both modalities.
- Answer accuracy: Explicitly incentivizes factual correctness—model answer must match ground truth.
- Reasoning length (text/audio): Supervises that model reasoning aligns length-wise (in tokens or audio duration) with annotated standards, deterring shortcut or surface-level explanations.
These composite rewards are integrated under the REINFORCE++ algorithm, which provides stable, critic-free Monte Carlo gradient updates while employing PPO-style clipped objectives and token-level KL penalties for divergence regularization. Policy optimization is conducted on Qwen2.5-Omni-7B, a large-scale LALM with full multi-modal support.
Empirical Evaluation and Ablation
Audio-to-text (a2t), text-to-audio (t2a), and audio-to-audio (a2a) settings are each robustly evaluated, with the SoundMind-RL policy consistently outperforming baselines (MiniCPM-o, Gemini-Pro-V1.5, Baichuan-Omni-1.5, Qwen2-Audio, Qwen2.5-Omni-7B):
- Audio-to-Text: Fine-tuned Qwen2.5-Omni-7B (SoundMind-RL) achieves 81.40% accuracy, a substantial absolute gain over direct SFT (77.59%) and other MLLMs.
- Text-to-Audio: 3% accuracy improvement is realized over SFT, with a modest rise in WER—a result of generating longer, more elaborate CoT traces.
- Audio-to-Audio: The most challenging configuration still yields 81.40% accuracy (+3.81% over base), albeit with increased WER, evidencing a trade-off between semantic completeness and speech fluency.
Distributional analysis demonstrates dataset diversity in reasoning durations and class labels, ensuring fair challenge and minimization of modality-specific shortcuts.
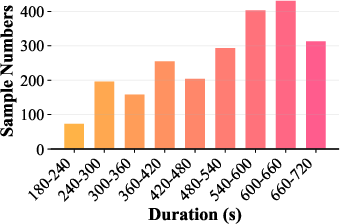
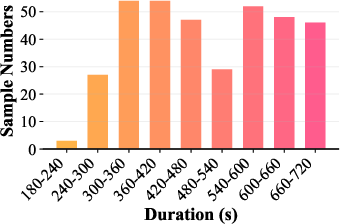
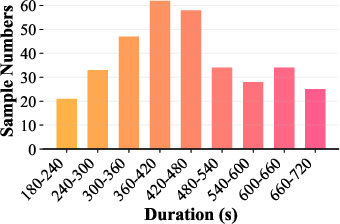
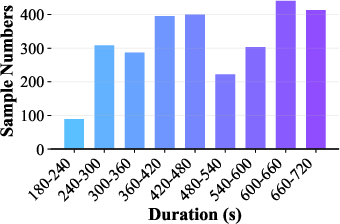
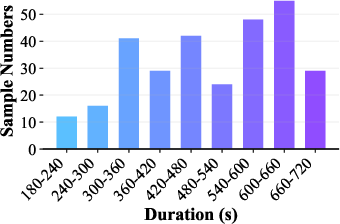
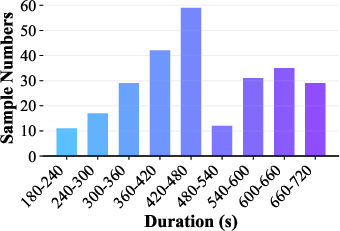
Figure 4: Distribution of audio durations across splits and entailment labels, validating class balance and coverage across reasoning contexts.
Ablation highlights the quantitative impact of each reward component:
- Removal of text format/length rewards causes catastrophic collapse in accuracy (to 48.8%), underlining the necessity of structural guidance.
- Answer-correctness is also critical, with its ablation dropping accuracy by 21.2 percentage points.
- Audio format/length rewards, while less dominant, provide meaningful regularization (+10% gain when included).
Implications, Limitations, and Future Directions
The SoundMind approach provides clear empirical evidence for the role of multimodal RL-based training when extending stepwise reasoning to the audio modality. The framework demonstrates that nuanced, compositional reward design can enforce correct output structure and factuality in both text and audio outputs, and that these constraints are synergistic rather than redundant. The moderate increase in WER highlights an inherent trade-off between reasoning verbosity and speech transcription fidelity, especially as sequence length increases—a dimension ripe for further study via fluency or prosody-aware reward augmentations.
Practically, these advancements have implications for explainable voice-based agents, accessibility technologies, spoken tutoring systems, and the development of robust, transparent conversational AI for screen-free or hands-busy environments. Theoretically, SoundMind sets a precedent for resource construction and evaluation in multimodal step-by-step reasoning, encouraging systematic study of representation, alignment, and reward design in next-generation audio-LLMs.
The framework’s limitations include its reliance on synthetic TTS-generated audio and LLM-annotated CoT rationales, possible rigidity introduced by fixed reward schemas, and the observed fluency-reasoning trade-off. Robustness to open-ended reasoning, speaker variability, and prosodic diversity remains unproven. Future research can explore real human-recorded datasets, reinforcement learning objectives incorporating fluency and expressivity, and transfer learning to more complex, noisy, or diverse audio-logic tasks.
Conclusion
The "SoundMind" framework establishes a rigorous, RL-incentivized methodology for multimodal logic reasoning in audio-LLMs, providing a dual contribution of high-quality aligned data and task-specific RL policy optimization. Extensive empirical results across multiple reasoning scenarios validate significant, consistent improvements in logical entailment and CoT reasoning, marking a substantial step toward intelligent, explainable, and context-aware spoken AI systems. The open release of data and code further catalyzes progress in systematic multimodal reasoning research.