- The paper introduces HumDial-EIBench, a benchmark leveraging authentic, human-recorded multi-turn dialogues to evaluate emotional intelligence in audio language models.
- The paper devises four core tasks—emotional trajectory detection, implicit causal reasoning, empathetic response, and acoustic-semantic conflict—to diagnose multimodal alignment and reasoning capabilities.
- The paper presents experimental results showing closed-source models achieve up to 88% accuracy in tracking emotions while all models exhibit text-dominance bias under cross-modal conflict.
HumDial-EIBench: Systematic Evaluation of Emotional Intelligence in Audio LLMs
Motivation and Limitations of Existing Benchmarks
Recent advances in end-to-end audio LLMs (ALMs) enable simultaneous processing of semantic and paralinguistic (intonational, emotional) components, theoretically supporting more native and robust emotional intelligence (EI) capabilities than cascaded ASR→LLM→TTS architectures. However, benchmarking these emergent EI competencies has been fundamentally limited by reliance on single-turn, TTS-synthesized benchmarks and subjective LLM-based scoring protocols. Existing resources either lack multi-turn context, omit cross-modal conflict scenarios, or introduce considerable subjectivity into evaluation, thus masking core deficiencies in multimodal alignment and emotional inference abilities of ALMs.
HumDial-EIBench: Design and Benchmark Construction
To systematically evaluate and diagnose the EI of ALMs, the paper introduces HumDial-EIBench, leveraging authentic human-recorded multi-turn dialogues from the ICASSP 2026 HumDial Challenge. The benchmark's data annotation and evaluation pipeline is illustrated below.
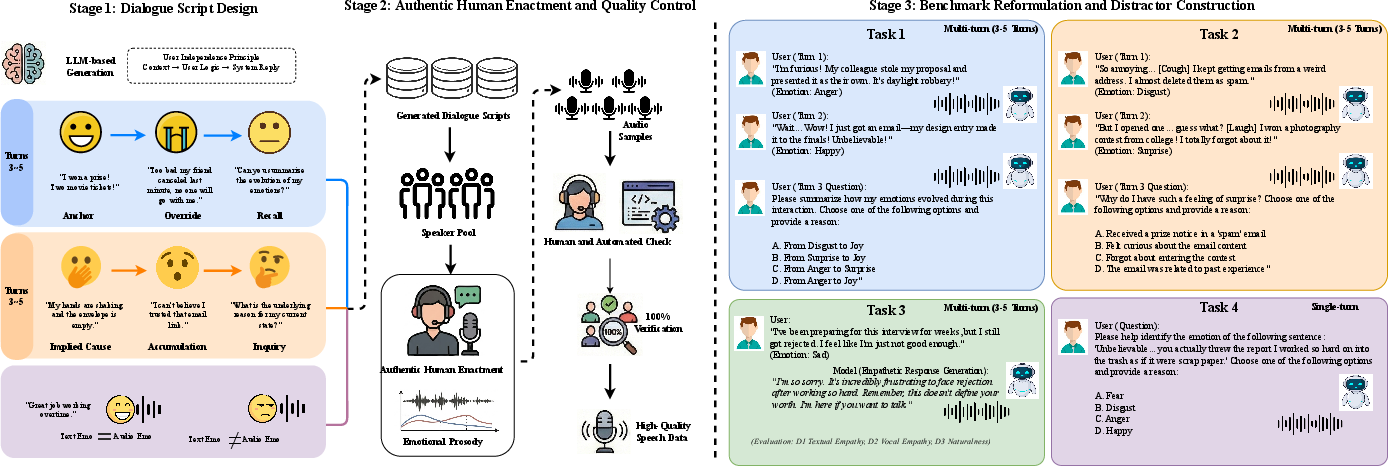
Figure 1: The three-stage data construction pipeline and overview of the four core EI tasks covered in HumDial-EIBench.
The pipeline encompasses: (1) dialogue script design using LLM-assisted scenario creation with explicit control over emotion and context; (2) high-fidelity human enactment preserving naturalistic prosody and variability; and (3) objective multiple-choice reformulation for comprehension-oriented tasks, fortified by adversarial distractors designed to expose both superficial and reasoning-related errors. Task 4 injects cross-modal conflicts designed to dissect and expose text-dominance bias inherent in current multimodal inference systems.
Evaluation Tasks
HumDial-EIBench incorporates four distinct tasks, each targeting a critical EI subdomain:
- Task 1 (Emotional Trajectory Detection): Requires accurate multi-turn emotional memory and selection of the correct emotional sequence over several conversational turns via MCQ.
- Task 2 (Implicit Causal Reasoning): Probes the model's ability to identify unstated emotional triggers from distributed contextual cues, formulated as objective MCQ to limit scorer subjectivity.
- Task 3 (Empathetic Response Generation): Evaluates both textual empathy and acoustic prosodic congruence in generated responses, scored along distinct dimensions for semantic and vocal appropriateness using both LLM judges and expert humans.
- Task 4 (Acoustic-Semantic Conflict): Examines model robustness and modality integration under conditions where textual sentiment is explicitly incongruent with vocal emotional tone, exposing reliance on either text or acoustic cues.
The diversity of tasks and authentic data enables discrimination between superficial generation fluency, underlying reasoning capacities, and true multimodal understanding—a separation not afforded by prior benchmarks.
Experimental Results and Analysis
Eight contemporary ALMs (five open-source, three closed-source) were systematically benchmarked to provide a comprehensive mapping of current capability and limitations. Strong results were reported for closed-source models (e.g., Gemini-2.5-flash, GPT-4o-audio) in trajectory tracking (up to 88%) and causal reasoning (up to 79.67%), substantially outperforming most open-source competitors. However, cross-model performance trends reveal structural weaknesses:
- Trade-Offs in Contextual Modeling: Closed-source ALMs show strong sequential memory (emotional tracking), while select open-source alternatives (e.g., Step-Audio-2-mini) perform better at local causal extraction, at the cost of poor multi-step tracking.
- Textual vs. Acoustic Empathy Decoupling: There is a persistent gap between semantic empathy (as perceived by LLMs) and acoustic empathy (human-rated vocal congruence), underscoring that proficiency in one facet does not guarantee strength in the other. Notably, models such as Doubao-realtime exhibit high acoustic empathy scores even when textual empathy is mainstream, indicating modality-specific strengths that are not always aligned.
- Text-Dominance Bias in Conflict Settings: In Task 4, all models—including high-performing closed-source solutions—show pronounced degradation in conflict samples. For example, Qwen2.5-Omni's accuracy drops from 88% (consistent) to 22% (conflict) for Chinese, illustrating that even end-to-end models overfit to text modality, defaulting to superficial semantic cues. No evaluated ALM demonstrated robust prioritization of vocal affect over text-derived distractors in adversarially designed contradiction scenarios.
Implications for Multimodal Learning and EI Modeling
The evidence establishes two critical theoretical implications:
- End-to-End Not Yet Sufficient for EI: Despite improved architecture, current ALMs are not natively emotionally intelligent; they still predominantly use audio as a transcription signal rather than as a full-fledged emotional channel. The decoupling of empathy dimensions and susceptibility to cross-modal conflict accentuate the persistence of 'transcribe-then-understand' bias.
- Need for Explicit Multimodal Alignment: Achieving robust EI in ALMs—especially under adversarial cross-modal conditions—requires more than architectural changes; dedicated consistency training, structured conflict scenarios during learning, and objective, modality-sensitive supervision frameworks will be essential for future progress.
Toward More Rigorous and Robust EI Benchmarks
HumDial-EIBench sets a new standard for objective, fine-grained, and diagnosis-oriented evaluation of ALMs by (i) using authentic, humanized multi-turn dialogue, (ii) employing domain-specific adversarial distractors to expose brittle reasoning and modality reliance, and (iii) explicit separation and evaluation of textual and prosodic empathy. Nevertheless, the paper recognizes two ongoing challenges: (a) LLM-based empathy scoring remains unstable with high inter-model variance; (b) acoustic-semantic conflict evaluation is limited to single-turn pairs, whereas natural human emotional tension often unfolds over multiple interleaved conversational turns.
Conclusion
HumDial-EIBench provides a comprehensive and objective framework for diagnosing nuanced emotional intelligence capabilities in ALMs, revealing that contemporary models remain susceptible to text-dominance bias and modality decoupling even under advanced end-to-end architectures. These results call for targeted research in cross-modal context integration, robust conflict supervision, and development of more stable evaluation protocols for genuine empathy and EI in large-scale audio LLMs.