Trust-Region Behavior Blending for On-Policy Distillation
Abstract: On-policy distillation (OPD) trains a student on prefixes sampled from its own policy while matching a stronger teacher. This addresses the prefix mismatch of offline distillation, but early student rollouts can still be poor, placing teacher supervision on weak or low-quality prefixes. We propose Trust-Region behavior Blending (TRB), a warmup method that replaces the early rollout policy with the closest-to-teacher behavior policy inside a student-centered KL trust region, while keeping the per-prefix reverse-KL OPD loss unchanged. The KL budget is annealed to zero, so training returns to pure student rollouts after warmup. Across two math-reasoning distillation settings, TRB attains the strongest average among the compared methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a smaller AI model (“the student”) to behave like a bigger, stronger AI model (“the teacher”) when solving problems, especially math word problems. The authors show a new way to guide the student during the early part of training so it doesn’t wander into bad habits. Their method, called Trust-Region behavior Blending (TRB), gives the student gentle, temporary “training wheels” that keep it close to the teacher’s behavior at first, and then gradually takes those training wheels off.
What questions were the researchers asking?
- Can we improve how a smaller model learns from a bigger one by gently guiding the smaller model’s early steps, without permanently taking over its decisions?
- Is there a way to let the student explore on its own (which is important for learning), while still nudging it toward better choices when it’s weakest—right at the start?
- Will this careful early guidance lead to better final performance than existing approaches?
How did they try to solve it?
First, some simple ideas to understand their approach:
- Student and teacher: Think of a student learning to write essays from a teacher. The student should practice writing on their own (so they learn to deal with their own mistakes), but if their early drafts are really off-track, a bit of teacher guidance can help.
- Prefix: When an AI writes an answer, it does it word by word. The “prefix” is the text written so far at any point.
- Behavior policy: This is the model’s “plan” for what word to pick next.
- Trust region: A trust region is like a “stay-close zone.” It’s a rule that says, “You can adjust your choices toward the teacher’s, but don’t drift too far from your current student style.”
What TRB does:
- During the early part of training only, TRB replaces the student’s next-word choices with a carefully blended mix of the student’s and teacher’s suggestions. This blend stays within a small “distance budget” from the student’s original choices. You can imagine it like mixing two playlists: mostly the student’s songs, but with some of the teacher’s top picks added in—just not too many at once.
- That “distance budget” is measured by a standard way of comparing two choice patterns (called KL divergence). You don’t need the math; just think “how far did we move from the student’s usual way of choosing words?”
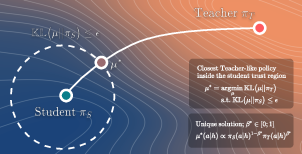
- The blend is chosen so it’s the closest possible to the teacher while still staying inside the student’s “stay-close zone.” This has a neat, exact solution: it’s like turning a knob that mixes teacher and student suggestions until you hit the allowed limit.
- Annealing (gradually turning off): The “distance budget” starts bigger and then is shrunk to zero over a short warmup period. That means the training wheels slowly come off, and, after warmup, the student goes back to fully choosing its own words. Importantly, the training goal (match the teacher on the visited prefixes) stays the same the whole time—the only thing that changes is how we collect those early prefixes.
Why this matters: Early on, a weak student often wanders into low-quality beginnings. TRB keeps those beginnings more sensible and teacher-like—without taking over completely—so the student learns from better situations right away.
What did they find?
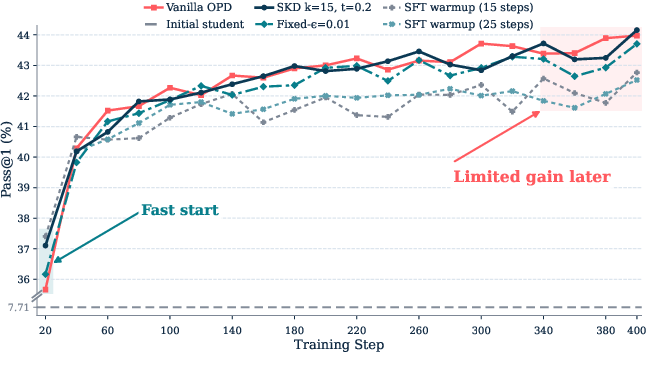
Across two setups where smaller “Qwen3” models learned from larger Qwen3 teachers on math reasoning tasks, TRB did best on average compared with several alternatives.
Here is what stood out:
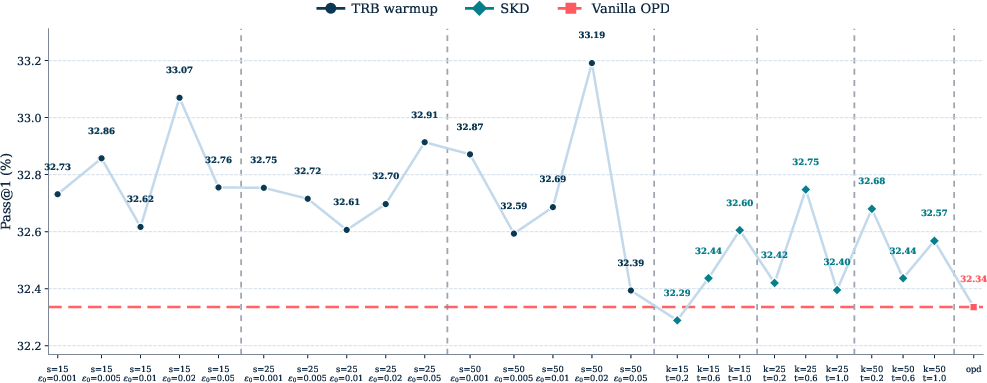
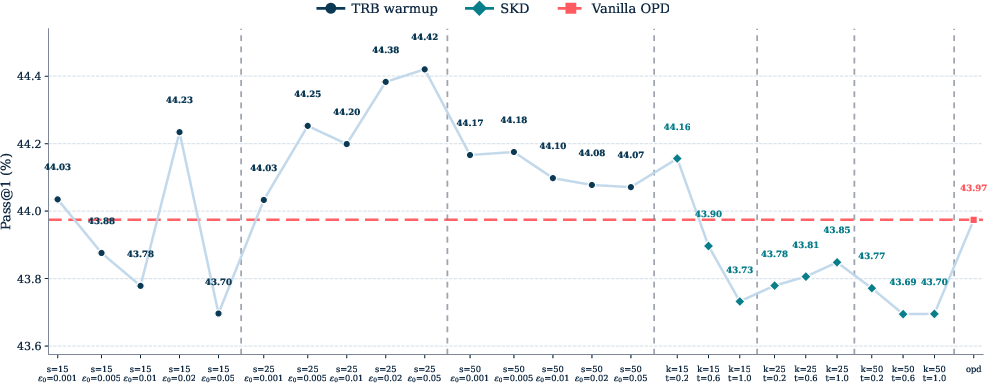
- Stronger overall results: TRB achieved the best average pass rates (pass@1) across multiple math benchmarks (like MATH500, AIME, AMC, and Olympiad) in both tested student–teacher pairs.
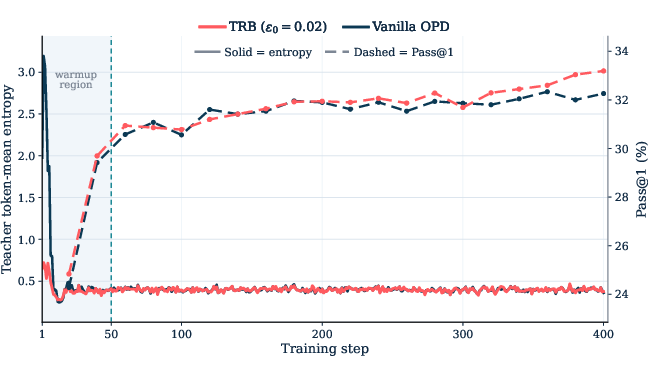
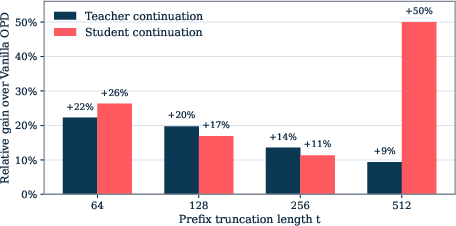
- Better early training states: In the very first steps, the prefixes collected with TRB were more promising: both the teacher and the student were more likely to finish those prefixes correctly than prefixes collected by the plain student.
- Temporary guidance works best: Using the same blending permanently (fixed budget) helped less. TRB’s “warmup only” approach led to better final outcomes, suggesting that guidance is most useful when the student is weakest, and then should be removed.
- Competitive against other ideas: TRB beat or matched alternatives like:
- Vanilla on-policy distillation (no guidance),
- Injecting teacher tokens directly into the student’s text,
- Changing the learning target at each step,
- Lowering the student’s sampling temperature early on,
- Doing a short supervised-teacher phase before switching to self-generated training.
- TRB had the strongest average across the board.
Why does this matter?
- Faster, steadier learning: By gently steering the student toward better early paths, TRB helps the student learn from more useful examples without losing the habit of thinking for itself.
- Keeps the right goal: TRB doesn’t change what the student is trying to learn (matching the teacher on the prefixes it visits). It only improves which early prefixes the student visits, leading to better practice.
- Practical recipe: If you’re training a small model from a bigger one, using TRB as a short warmup can unlock better results than treating the entire training like a fixed, teacher-heavy process.
A quick note on limits and costs
- Tested scope: The experiments focused on math reasoning and on specific model sizes. While the idea is general, settings in other domains may need different schedules.
- Extra compute during warmup: TRB needs the teacher to help during generation in the warmup, which can add memory and time costs. This overhead ends when the warmup ends.
In short, TRB is like giving a student temporary training wheels that keep them near the teacher’s style while still letting them practice on their own. Those wheels gradually come off, and by then the student has learned to start in better directions—leading to stronger overall performance.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored in the paper and could guide future research.
- Generalization beyond math reasoning and Qwen3 pairs:
- Effectiveness on other domains (code, multilingual text, open-ended dialogue, safety-critical tasks), modalities, and data regimes remains untested.
- Behavior under different teacher–student gaps (e.g., much larger/smaller gaps, near-parity models, or teacher worse than student in some regions) is not characterized.
- Sensitivity and automation of warmup scheduling:
- How to choose the initial trust-region budget ε₀ and warmup horizon K robustly across tasks and model pairs is not established.
- No comparison across alternative schedules (e.g., exponential/cosine/stepwise, or early stopping based on a diagnostic like teacher–student divergence or teacher entropy).
- Lack of adaptive, state-aware budgeting (e.g., per-prefix/per-token ε driven by teacher entropy, disagreement, reward signals, or variance).
- Off-policy bias and learning dynamics:
- Theoretical and empirical impact of sampling prefixes from μ (not πS) during warmup on the reverse-KL OPD objective (defined under P{π_S}) is not analyzed; the bias introduced and its decay when annealing back to on-policy are unclear.
- No study of how TRB affects gradient variance, stability, or sample efficiency of the reverse-KL estimator.
- Scope of divergences and constraint choices:
- The method minimizes D_KL(μ‖π_T) with a D_KL(μ‖π_S) constraint, but alternatives (e.g., forward KL, JS, α/Rényi divergences, χ², Wasserstein) and their trade-offs are not evaluated.
- Sequence-level trust regions (e.g., trajectory KL, return-aware constraints) versus token-level constraints are not explored, despite the objective being sequence-level in effect.
- No analysis of incorporating teacher entropy or risk-sensitive objectives directly into the solver (e.g., entropy-aware constraints or multi-objective formulations).
- Approximation effects from top-k KL estimation:
- Reverse-KL is estimated on a truncated student top-k support; the bias this introduces—and its interaction with TRB’s behavior policy—has not been quantified.
- Sensitivity to k and to support selection procedures is not studied.
- Robustness, diversity, and calibration:
- Potential diversity loss or mode-collapse risks from steering behavior toward the teacher are not measured (e.g., n-gram diversity, self-BLEU, entropy analyses).
- Impact on calibration (e.g., probability calibration, confidence alignment) is not assessed.
- Robustness to adversarial prompts, distribution shift, or long-context settings remains unexplored.
- Baseline coverage and fairness:
- SFT and SKD baselines may not be exhaustively tuned (e.g., SFT learning-rate schedules, KL/temperature schedules, acceptance rules), making relative ranking potentially sensitive to hyperparameters.
- No compute-/FLOP-normalized comparison across methods; improvements could partly reflect different teacher compute placement and latency profiles during warmup.
- Best-checkpoint selection protocol (evaluating every 20 steps and picking the top) may inflate reported gains; last-epoch, fixed-step, or early-stopping criteria comparisons are missing.
- Statistical rigor and reproducibility:
- Absence of multiple seeds, error bars, or statistical significance tests leaves uncertainty about variance and stability of gains.
- Sensitivity to data subsampling, prompt order, and the fixed system prompt is not examined.
- Interaction with existing OPD stabilizers:
- Compositions with Veto, TIP, Entropy-Aware OPD, or curriculum/assistant data (MiCoTA-style) are not studied; potential synergies or conflicts remain open.
- Whether TRB can replace or complement temperature warmup, token-importance filtering, or logit-bridge targets has not been systematically explored.
- Adaptivity and diagnostics:
- No mechanism to adapt ε on-the-fly using real-time signals (e.g., teacher–student KL, teacher entropy, verifier reward, or success prediction) is provided.
- Diagnostics used (teacher entropy, continuation success gain) suggest early benefits, but actionable stop/continue criteria for TRB are not formalized.
- Teacher quality, trust, and safety:
- The method assumes the teacher is a reliable guide locally; behavior when the teacher is noisy, biased, or domain-mismatched is not analyzed.
- Safety and bias propagation risks from aligning early behavior more closely to the teacher are not measured (e.g., toxicity, bias audits).
- Numerical and support mismatch concerns:
- Practical handling of near-zero probabilities and support mismatches beyond EOS canonicalization is under-specified; stability of β bisection with extreme logits or sparse supports is untested.
- Edge cases where π_T assigns negligible mass to tokens favored by π_S (or vice versa) and their effect on feasibility, β*, and rollout quality are not examined.
- Efficiency and systems questions:
- While an efficiency analysis is sketched, there are no empirical throughput/latency measurements or memory profiles across hardware setups; wall-clock impact and scalability with larger teachers/students remain unclear.
- No exploration of caching/approximation strategies (e.g., teacher distillation of shallow adapters, KV-sharing tricks, speculative teacher queries) to reduce online teacher cost.
- Evaluation metrics and breadth:
- Reliance on pass@1 for math; no analysis of training loss curves, perplexity, reward-model scores, or downstream utility.
- Generalization to held-out or private benchmarks, or cross-benchmark transfer, is not assessed.
- Theoretical guarantees and convergence:
- Although the trust-region path has favorable local properties (e.g., √ε improvement in teacher KL), there is no theory connecting TRB warmup to improved asymptotic performance, convergence speed, or generalization in OPD.
- Conditions under which TRB could be detrimental (e.g., over-anchoring to teacher modes that conflict with the student’s future reachable states) are not characterized.
- Design space extensions:
- Multi-teacher or ensemble-guided TRB (e.g., log-linear pooling with trust regions) is not explored.
- Token- or span-level selective blending (e.g., apply TRB only when disagreement/entropy is high) and structured constraints (e.g., per-Category or per-Reasoning-Step budgets) are left open.
- Data and verifier dependencies:
- Reliance on Math-Verify and a specific system prompt may shape behavior; sensitivity to verifier type/thresholds and prompting style is not tested.
- Effects of training-set size, prompt diversity, and curriculum pacing on TRB’s benefits are unknown.
Practical Applications
Immediate Applications
Below are practical ways to deploy the paper’s Trust-Region behavior Blending (TRB) warmup for on-policy distillation (OPD) today, along with sectors, concrete outputs, and feasibility notes.
- Drop-in warmup for existing LLM distillation pipelines (software/AI platforms, academia)
- What to build: Add a “TRB Warmup” stage that computes the geometric-mean behavior policy μβ∝πS1−β·πTβ with per-prefix bisection to satisfy DKL(μ‖πS)≤ε, and linearly anneal ε→0 over 15–50 steps before reverting to pure student rollouts. Integrate EOS canonicalization and top‑k reverse‑KL as in the paper.
- Tools/workflow: Implement as a module for Hugging Face TRL/DeepSpeed/Verl/SGLang pipelines; expose ε0 and K as knobs; dashboard for teacher entropy, KL budget, and pass@1.
- Assumptions/dependencies: Access to a stronger teacher model; GPU memory to co-reside teacher+student during warmup; licensing to run the teacher; tasks where reverse‑KL OPD is already used.
- Production of smaller, domain‑specialized assistants with better math/logical reasoning (industry: SaaS, education; daily life: tutoring apps)
- What to build: Distill an 8–13B teacher into a 1–3B student for math help, STEM Q&A, or structured reasoning, using TRB for only the first ~15–50 training steps.
- Tools/products: Offline-capable math tutors, lightweight reasoning copilots in IDEs/calculators.
- Assumptions/dependencies: Gains demonstrated on math benchmarks; domain transfer likely but should be validated with domain-specific evals; require high-quality prompts and verifier(s) if used.
- Stabilized pre-RLHF preparation (industry: AI labs; academia)
- What to build: Insert TRB as a short warmup before PPO/DPO/RLAIF to reduce brittle early on-policy data and improve the starting point for reinforcement stages.
- Workflow: “SFT → TRB‑OPD short warmup → PPO/DPO”; track teacher-token entropy and early reward quality.
- Assumptions/dependencies: RLHF stack already in place; teacher and student tokenizers aligned or canonicalized; additional warmup compute acceptable.
- Distillation for code and tool-use models (software/devtools)
- What to build: Apply TRB‑OPD to code LLMs or tool-augmented agents (e.g., function calling), using teacher guidance within a KL trust region to avoid early off-task rollouts.
- Products: Smaller code copilots, CI assistants that run on developer laptops/edge servers.
- Assumptions/dependencies: Strong code/tool teacher available; ensure API/tool-calling tokens are included in the behavior policy and KL support.
- On-device/edge model enablement (mobile, robotics, IoT)
- What to build: Distill a stronger cloud teacher into a small on-device student, using TRB only during training to improve early trajectories without needing the teacher at inference.
- Products: On-device reasoning assistants, robotic planners that fit memory/compute budgets.
- Assumptions/dependencies: Sufficient training-time compute to host both models; final inference remains student-only; safety/latency constraints validated for the edge setting.
- Safer early-stage training data collection (policy/compliance teams; industry)
- What to build: Use TRB to keep early rollouts closer to the teacher (assumed audited/safe) while bounding deviation from the student, reducing exposure to degenerate prefixes that can propagate unsafe patterns.
- Workflow: Couple TRB with content filters; log KL budgets and intervene if teacher–student gaps spike.
- Assumptions/dependencies: Teacher audited for safety; logging and monitoring in place; TRB only restricts behavior distribution, it does not replace safety reviews.
- Research instrumentation for on‑policy learning dynamics (academia)
- What to build: Use TRB as a controlled knob on prefix quality to study how early trajectory distributions affect OPD outcomes; replicate the paper’s entropy and continuation-gain diagnostics.
- Tools: Analysis scripts to track teacher log-probabilities, AUROC separability of correct vs. incorrect rollouts, and pass@1 during warmup.
- Assumptions/dependencies: Access to evaluation suites (e.g., MATH500, GSM8K) and verifiers; ability to run frequent evaluations.
- Training-framework extensions (MLOps/software)
- What to build: A reusable “TRB Warmup Kit” with: per-prefix bisection solver, geometric-mean sampler, EOS alignment utility, top‑k reverse‑KL estimator, and annealing schedules.
- Tools: Plugins for SGLang/Verl; CUDA kernels or fused ops for dual-policy scoring to minimize overhead.
- Assumptions/dependencies: Engineering to manage teacher KV caches and memory; guidance for users on ε0, K defaults and monitoring.
- Cost/energy reduction via smaller students with maintained quality (industry; policy/sustainability)
- What to build: Replace larger inference endpoints with students distilled using TRB to improve math/logical tasks at the same parameter count, or maintain quality at reduced size.
- Workflow: A/B test endpoints on target benchmarks; track energy per inference and total compute.
- Assumptions/dependencies: Quality retention validated on your workloads; telemetry for energy/latency; teacher availability for training only.
- Regulated-domain pilots with careful oversight (healthcare, finance, legal)
- What to build: Pilot TRB‑OPD to produce compact assistants (e.g., medical math, actuarial calculations, legal clause counting) where correctness is verifiable.
- Workflow: Couple with verifiers and auditing datasets; restrict warmup to verified prompts.
- Assumptions/dependencies: Domain-appropriate teacher; data governance and PHI/PII controls; legal rights to use the teacher and data.
Long-Term Applications
These require further research, scaling, or engineering to generalize beyond the paper’s math-focused scope or to fit more complex settings.
- Multimodal and multilingual TRB‑OPD (healthcare imaging, autonomous driving, education)
- What to build: Extend trust‑region behavior blending to vision‑language and speech models, guiding early rollouts with stronger multimodal teachers under KL constraints.
- Dependencies: Multimodal teacher availability; per-modality alignment of token/splice spaces; efficient dual‑model decoding for large context windows.
- Learned or adaptive KL budgeting (software/AI research)
- What to build: Replace hand‑tuned linear ε schedules with learned controllers (e.g., based on teacher entropy, reward, or predicted teacher‑student gain).
- Dependencies: Reliable on‑the‑fly signals and stability guarantees; safeguards against oscillations.
- Teacher‑free or proxy‑teacher warmups (cost/safety sensitive sectors)
- What to build: Use verifier models, ensembles, or preference models as proxies to steer behavior within a trust region when a full teacher is unavailable or too costly.
- Dependencies: Proxy quality must correlate with downstream success; calibration of proxy signals; risk of proxy bias.
- Integration with RL and control beyond LLMs (robotics, operations research)
- What to build: Apply per‑state TRB to stabilize early online learning in sequential decision‑making, blending a baseline policy with an expert under a KL trust region (akin to TRPO but for behavior collection).
- Dependencies: Well-defined expert or planner; exploration–exploitation balance; handling continuous action spaces.
- Safety‑aware TRB with constrained token classes (policy, safety engineering)
- What to build: Constrain TRB to only shift probability mass toward teacher tokens that pass safety policies (e.g., content filters or red‑team lists).
- Dependencies: High-precision safety classifiers; conservative thresholds to avoid masking useful supervision.
- Systems support for dual‑model decoding (hardware/software co‑design)
- What to build: GPU/accelerator kernels and schedulers optimized for concurrent teacher+student KV cache management and step‑synchronous decoding during warmup.
- Dependencies: Framework and kernel support; memory-planning APIs; incentives to standardize across stacks.
- Hierarchical or multi‑teacher blending (enterprise AI)
- What to build: Blend multiple specialized teachers (e.g., math, code, legal) under per‑prefix trust regions chosen by a router, to train a single versatile student.
- Dependencies: Teacher selection/routing accuracy; conflict resolution among teacher distributions; additional compute.
- Curriculum and data selection powered by TRB signals (academia/industry)
- What to build: Use early teacher‑support metrics and DKL gaps to prioritize prompts or generate curricula where on‑policy learning is most transferable.
- Dependencies: Robust metrics across domains; avoidance of overfitting to “easy” prefixes.
- Standards and governance for warmup reporting (policy/governance)
- What to build: Documentation norms requiring disclosure of warmup schedules, teacher usage, and extra compute for on‑policy methods to support reproducibility and sustainability reporting.
- Dependencies: Community consensus; tooling for automatic logging of KL budgets, teacher calls, and energy.
- Cross‑task generalization studies of OPD warmups (academia)
- What to build: Large‑scale experiments to test TRB on dialogue safety, code synthesis, chain‑of‑thought in non‑math domains, and multilingual tasks, establishing when and why it helps.
- Dependencies: Benchmarks with reliable automatic verifiers; funding/compute for extensive sweeps.
Notes on Feasibility and Transfer
- Evidence base: The paper demonstrates gains on math reasoning with Qwen teacher–student pairs and reverse‑KL OPD; benefits are likely but not guaranteed to transfer unchanged to other domains or divergence objectives.
- Compute/memory: TRB requires online teacher decoding and co‑residency during warmup; peak memory and wall‑clock overheads must be budgeted.
- Teacher quality: TRB presumes a stronger teacher with aligned tokenizer and safe behavior; poor or misaligned teachers will degrade outcomes.
- Objective specifics: The method assumes reverse‑KL OPD with top‑k support estimation; different divergences or supports may require re‑tuning.
- Governance: Ensure licensing for teacher weights, data privacy compliance, and safety monitoring during warmup data collection.
Glossary
- Annealed warmup: A training schedule that gradually reduces an intervention parameter over time until it reaches zero. Example: "The KL budget is annealed to zero, so training returns to pure student rollouts after warmup."
- AUROC: Area Under the Receiver Operating Characteristic curve; a threshold-independent measure of ranking quality. Example: "The vertical axis shows AUROC for ranking verifier-correct rollouts above verifier-incorrect ones using the sequence-level teacher-support score obtained by averaging over the response."
- Behavior policy: The policy used to generate data (prefixes) during training, which can differ from the student policy. Example: "We denote that behavior policy by ."
- Chain-of-Thought (CoT): A prompting/learning style that trains models to produce step-by-step intermediate reasoning. Example: "addresses a related learnability gap in offline CoT distillation through intermediate assistants and intermediate-length reasoning traces."
- EOS canonicalization: Harmonizing different end-of-sequence token IDs across models to compare or sample consistently. Example: "we canonicalize EOS before behavior construction and KL evaluation; Appendix~\ref{app:eos} gives the exact procedure."
- Exposure bias: The discrepancy caused by training on teacher-forced prefixes while inference uses the model’s own outputs. Example: "For autoregressive models, this creates exposure bias because training conditions on fixed or teacher-provided prefixes, whereas inference conditions on the student's own rollouts."
- Exponential tilt: Reweighting a base distribution by an exponential factor to form a new distribution. Example: "The trust-region path can be written as the exponential tilt"
- Forward KL divergence: The KL divergence measured as D_KL(p || q); in this paper, used to encourage diversity by moving toward high-entropy teacher distributions. Example: "adding forward-KL pressure at high-entropy teacher states to preserve diversity."
- KL budget: A limit on how far the behavior policy may deviate from the student in KL divergence. Example: "TRB therefore introduces two method hyperparameters: the initial KL budget and the warmup horizon ."
- KL divergence: Kullback–Leibler divergence; a measure of how one probability distribution differs from another. Example: "defines a KL trust region $D_{\mathrm{KL}(\mu \,\|\, \pi_S) \le \varepsilon$."
- KV cache: Key–Value cache used during transformer decoding to avoid recomputation across time steps. Example: "and KV caches and ."
- Log-normalizer: The log of the normalization constant ensuring a distribution sums to one after exponential reweighting. Example: "where is the log-normalizer."
- Logits: Pre-softmax scores output by a model for each token. Example: "constructing a bridge between student and teacher logits."
- Off-policy: Data collection or training using trajectories not generated by the current policy. Example: "while stronger teacher intervention can improve local prefix quality only by moving collection off-policy"
- On-Policy Distillation (OPD): Distillation where the student is trained on prefixes sampled from its own current policy, supervised by the teacher. Example: "On-policy distillation (OPD) trains a student on prefixes sampled from its own policy while matching a stronger teacher."
- Pass@1: The fraction of problems solved correctly by the model’s first attempt. Example: "Table~\ref{tab:main-results-skeleton} reports pass@1 under the common checkpoint-selection protocol."
- Reverse KL divergence: The KL divergence measured as D_KL(q || p); here, used as the per-prefix loss pushing the student toward the teacher. Example: "MiniLLM further argues that reverse KL is a good fit for generative LLM distillation and derives an on-policy optimization procedure for that objective."
- Rollout: A generated trajectory or sequence produced by a policy during decoding. Example: "Pure student rollouts preserve the target training distribution"
- SFT (Supervised Fine-Tuning): Fine-tuning a model directly on labeled or teacher-generated outputs via supervised learning. Example: "SFT warmup is a two-stage baseline that replaces the first part of online rollout collection with a supervised teacher-generated warmup."
- Teacher token-mean entropy: The average token-level entropy of the teacher distribution over visited prefixes, indicating teacher uncertainty. Example: "Teacher token-mean entropy (left axis) and benchmark Pass@1 (right axis) for vanilla OPD and TRB on the Qwen3-1.7B-Base Qwen3-8B setup."
- Top-k support: Restricting computations (e.g., KL) to the top-k most probable tokens under a model’s distribution. Example: "the reverse-KL term is estimated on a truncated student top- support."
- Top-p sampling: Nucleus sampling; sampling from the smallest set of tokens whose cumulative probability exceeds p. Example: "top-p & 1.0"
- Trust region: A constraint that limits how far a policy update or behavior can move from a reference policy, typically measured by KL divergence. Example: "This objective chooses the most teacher-like sampling distribution inside a student-centered trust region."
- Trust-Region behavior Blending (TRB): The proposed method that blends teacher and student behaviors within a KL-bounded region during warmup. Example: "We propose Trust-Region behavior Blending (TRB), a warmup method that replaces the early rollout policy with the closest-to-teacher behavior policy inside a student-centered KL trust region"
- Verifier: An external checker that judges correctness of generated solutions, providing a reward signal. Example: "ranking verifier-correct rollouts above verifier-incorrect ones"
- Warmup horizon: The number of steps over which a warmup schedule (e.g., KL budget) is applied before reverting to standard training. Example: "For a warmup horizon , we set"
- Veto: A baseline method that reformulates the target distribution at visited prefixes to stabilize training. Example: "Veto changes the target distribution at a visited prefix by constructing a bridge between student and teacher logits."
Collections
Sign up for free to add this paper to one or more collections.