- The paper introduces DP-OPD, which privatizes only student updates via DP-SGD while leveraging a frozen teacher to provide dense feedback on on-policy rollouts, reducing exposure bias and computational overhead.
- It achieves lower perplexity (e.g., 30.63 on BigPatent) compared to standard DP-SGD and synthesis-based methods, demonstrating an improved privacy-utility tradeoff under strict DP budgets.
- The single-stage, synthesis-free DP-OPD pipeline simplifies training by eliminating multi-step synthetic data generation, thereby lowering engineering complexity and runtime costs.
Differentially Private On-Policy Distillation for LLMs
Motivation and Problem Setting
Deployment of LLMs on domain-specific corpora containing sensitive information poses significant privacy risks, necessitating formal guarantees such as differential privacy (DP). Conventional approaches rely predominantly on DP-SGD, which, although effective for privacy, induces substantial utility degradation in autoregressive generation tasks due to optimization noise amplifying exposure bias and error compounding. Model compression via knowledge distillation (KD) is employed to address resource constraints (e.g., latency and memory), yet standard KD is typically off-policy, exacerbating train-test mismatch—particularly problematic when DP noise is present.
Existing solutions involving DP-compressed models manifest undesirable tradeoffs. Methods applying DP-SGD on both teacher and student models double the privacy burden and computational overhead, with marked utility loss. Synthesis-based approaches, such as DistilDP, offload privacy expense to the teacher and utilize DP-synthetic text, but necessitate complex multi-stage pipelines and expensive generation by large teacher models.
DP-OPD: Core Methodology
The paper introduces DP-OPD—Differentially Private On-Policy Distillation—which strictly privatizes only student updates via DP-SGD while leveraging a frozen, non-private teacher for dense, token-level feedback on states encountered via student rollouts. This approach eliminates both DP training of the teacher and synthesis of offline synthetic corpora, resulting in a single-stage, synthesis-free DP compression pipeline.
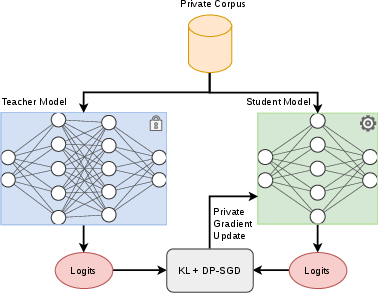
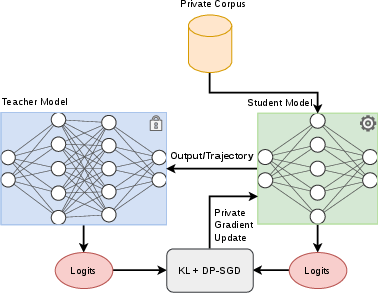
Figure 1: Off-policy KD uses fixed, teacher-forced trajectories; DP-OPD uses student rollouts, with the teacher providing supervision on visited states.
The training procedure is based on a generalized knowledge distillation (GKD) objective, parameterized by β, interpolating between forward/reverse KL and JSD divergences. For on-policy steps (probability λ), trajectories are sampled according to the current student policy; otherwise, teacher-forced trajectories are used. Only continuation tokens are considered for the KD loss, avoiding leakage or DP-accounting on prompts/control codes. Teacher and student distributions are softmax outputs at a tunable temperature τd.
DP-SGD updates clip per-example gradients, add Gaussian noise, and are tracked by a standard privacy accountant, ensuring end-to-end (ε,δ)-DP for the released student model. Teacher inference is regarded as internal and does not consume privacy budget.
Experimental Results
DP-OPD is benchmarked against three alternatives:
- Strong DP-SGD fine-tuning of the student.
- Dual-DP off-policy distillation (DP-SGD on both teacher and student).
- Synthesis-based KD using synthetic DP text (DistilDP).
Evaluations are performed on the Yelp (short-form) and BigPatent (long-form) datasets. DP-OPD demonstrates the lowest student model perplexity across both datasets under ε=2.0, outperforming student-only (DP-SGD), dual-DP off-policy KD, and synthesis-based DP-KD. For example, on BigPatent, DP-OPD achieves a perplexity of 30.63 versus 32.43 for DistilDP and 41.80 for naive DP-SGD.
Practical and Computational Cost
DP-OPD executes all training (both rollout and gradient steps) in a single pipeline. In contrast, DistilDP requires full DP-SGD for a large teacher (e.g., GPT-2 Large), offline synthetic data generation, and student training on that corpus. Despite introducing rollout/teacher-inference overhead (especially for high values of λ), DP-OPD is empirically shown to be competitive with, or even favorable to, synthesis-based approaches in terms of hardware and runtime demands due to its algorithmic simplicity.
Ablation: Influence of GKD Divergence Parameter
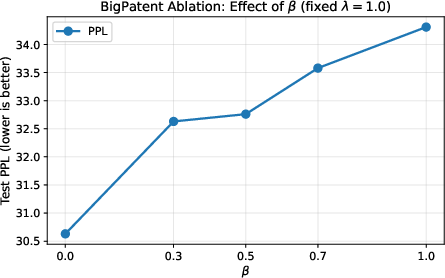
Figure 2: Test perplexity on BigPatent as a function of the GKD divergence parameter β with fully on-policy distillation (λ=1.0).
Ablations on β illustrate a monotonic rise in perplexity as β increases, with optimal performance at λ0 (forward-KL regime), indicating that the task-derived next-token likelihood is best optimized by encouraging the student to cover the teacher's predictive distribution on visited states. This underscores the importance of objective selection for robust transfer under DP noise.
Theoretical and Practical Implications
The principal theoretical contribution is the integration of on-policy distillation—prioritizing student-aligned state distributions—with DP accounting for privacy, closing the gap induced by exposure bias under privacy noise. The result is a more stable and performant small student under strict privacy budgets in practical deployments. Empirically, DP-OPD outperforms synthesis-based and dual-DP baselines on real-world datasets.
Practically, by collapsing the pipeline to a single stage, DP-OPD significantly lowers engineering and computational barriers for privacy-preserving LM deployment. It does so without compromising the privacy formalism and while remaining compatible with advanced KD and distillation objectives.
Limitations and Future Directions
DP-OPD's online rollout/teacher-inference cost can become the bottleneck for long continuations or high rollout frequency. The method also requires full (frozen) teacher access during all student updates, which may limit applicability in scenarios with teacher model constraints or API chargeability. If control codes or other conditional metadata are sensitive, additional privatization strategies and formal threat modeling are necessary.
Future research directions include:
- Precise characterization of compute-utility tradeoffs as a function of rollout parameters (frequency, length, batch size).
- Extension to teacher-student pairs with mismatched tokenizers (e.g., via GOLD logit alignment).
- Adapting DP-OPD to settings with restricted teacher access or non-negligible sensitivity of conditioning inputs.
Conclusion
DP-OPD provides an efficient, synthesis-free solution for differentially private LM compression by leveraging on-policy distillation and advanced KD objectives solely under DP-SGD on the student. It achieves lower perplexity under strict privacy budgets compared to both synthesis-based distillation and strong DP fine-tuning, while incurring significant practical and computational simplifications. The framework directly addresses exposure bias—further exacerbated by DP optimization—by aligning the student with teacher outputs on the true student trajectory distribution, and presents a structurally robust alternative to existing DP model compression pipelines.
Future advances could improve the practical deployment profile and broaden applicability, especially for scenarios with tokenizer heterogeneity, expensive teacher access, or sensitive control metadata.