VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
Abstract: We introduce VideoKR, the first large-scale training corpus specifically designed to strengthen knowledge- and reasoning-intensive video understanding. It comprises 315K video reasoning examples over 145K newly collected, CC-licensed, expert-domain videos. We develop a human-in-the-loop, skill-oriented example generation pipeline that targets progressively deeper video reasoning capabilities while ensuring the difficulty, diversity, and reliability of both the examples and their CoT rationales. We also curate VideoKR-Eval, a new expert-annotated benchmark where questions require genuine video understanding and knowledge-intensive reasoning rather than textual shortcuts. Our experiments show that, under a standard SFT$\rightarrow$GRPO pipeline, models post-trained on VideoKR outperform prior post-training approaches on knowledge-intensive video reasoning while remaining competitive on general video reasoning, highlighting data design as a key driver of progress in video reasoning. We further conduct comprehensive ablations to isolate the contributions of VideoKR, providing actionable insights for future work.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces VideoKR, a giant, carefully built collection of videos and questions that teach AI systems to truly “think” about videos, not just describe what they see. Instead of focusing on simple actions like “a person is running,” VideoKR pushes models to use real-world knowledge (like physics, biology, or engineering) and multi-step reasoning to figure out what’s happening and why it matters.
What questions does the paper try to answer?
- Can we build a video dataset that trains AI to combine what it sees with what it knows, so it can handle harder, real-world problems?
- How do we make sure the questions really need video understanding (not just reading the caption or guessing from a single image)?
- Will models trained on this new data actually get better at knowledge-heavy video tasks?
How did the researchers do it?
The team designed a multi-step, human-checked process to create high-quality training and testing materials.
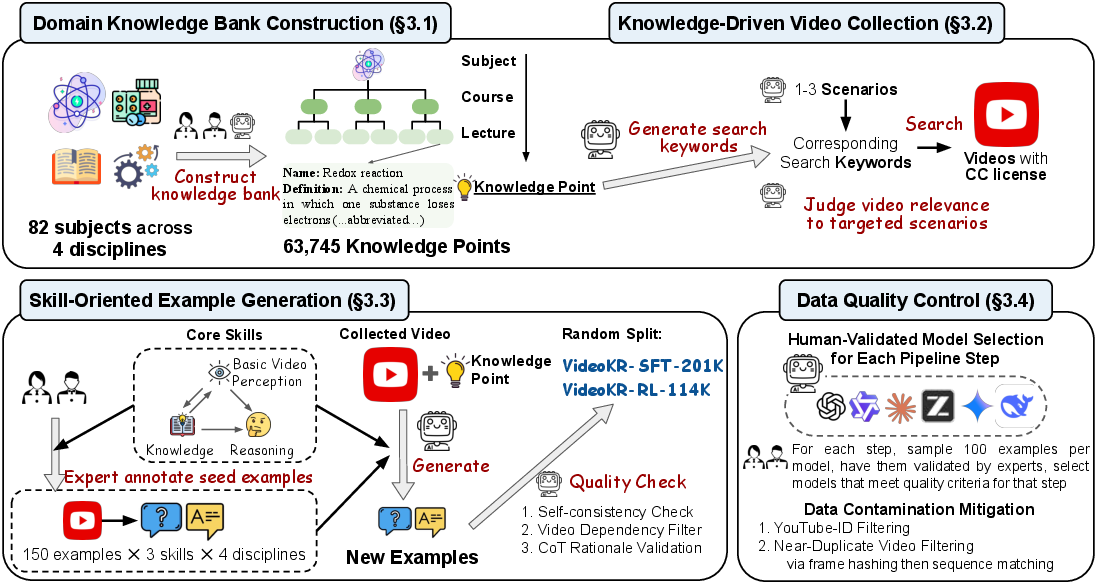
Step 1: Build a “knowledge bank”
- They listed 82 university-level subjects (like physics, medicine, or history), then organized them into subjects → courses → lectures → specific “knowledge points.”
- A “knowledge point” is a key idea with a clear definition (for example, “Newton’s Second Law” and what it means).
- They collected 63,745 knowledge points to guide what kinds of videos and questions to create.
Step 2: Collect the right videos
- For each knowledge point, they asked AI to suggest real-world situations that show that idea (e.g., “a rocket launching” to show Newton’s Second Law).
- They searched for Creative Commons (CC) licensed videos on YouTube so they could use them legally.
- They filtered out videos that were too long, unsafe, or not actually about the idea.
- Result: 145,000+ new, CC-licensed videos across professional domains, with an average length of about 5–6 minutes each.
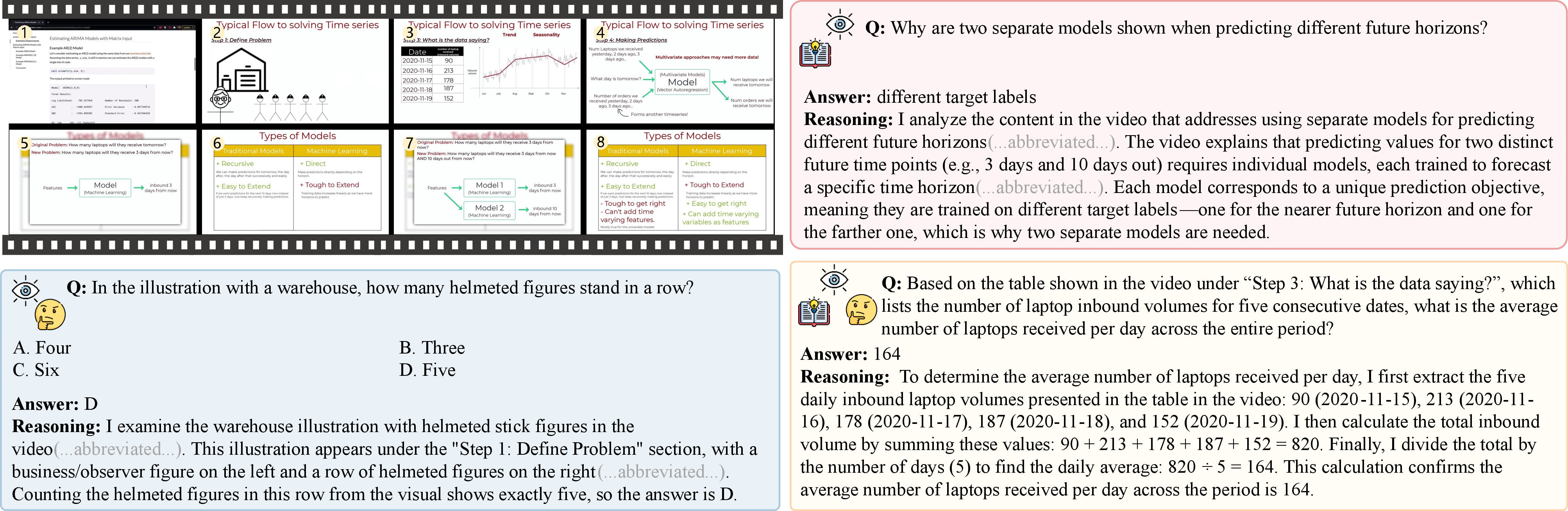
Step 3: Create questions that build three core skills
To help models grow from simple understanding to deep reasoning, they created questions in three categories:
- Basic Video Reasoning (VidR): understanding what’s visibly happening and in what order (who did what, where, and when).
- Knowledge-Enhanced Video Perception (KnowVid): recognizing specialized objects or processes and linking them to concepts (e.g., identifying lab equipment and its purpose).
- Knowledge-Intensive Video Reasoning (KnowVidR): using both the video and domain knowledge to reason through multi-step problems (e.g., inferring a diagnosis from symptoms shown over time).
To make this work:
- Human experts wrote high-quality example questions with step-by-step explanations for each skill.
- AI systems then generated many more questions using those expert examples as “seeds.”
- In total, they created 315,000 question–answer pairs, many with high-quality step-by-step “reasoning traces” that show how to get the answer.
Step 4: Quality control with humans in the loop
Because AI can make mistakes, the team:
- Checked for self-consistency (the model must solve its own question the same way twice).
- Removed questions answerable by looking at text or just one frame of the video (they tested this using strong models and strict rules).
- Verified that the step-by-step explanations were supported by the video and standard knowledge.
- Used a pool of strong AI models plus 34 human experts to avoid bias and ensure reliability.
- Split the data into two training sets:
- VideoKR-SFT-201K (for “Supervised Fine-Tuning,” where the model learns from answers and step-by-step solutions).
- VideoKR-RL-114K (for reinforcement learning, where the model practices and gets reward-like feedback for correct answers).
Step 5: Build a fair test: VideoKR-Eval
The team noticed that many existing “hard” video benchmarks can be answered by just looking at one frame (like a single photo). So they made a better evaluation set:
- They tested existing questions with multiple strong models using only one frame. If a question didn’t truly need the video, they filtered it out.
- For filtered videos, domain experts wrote new questions that really require watching the sequence.
- Final result: VideoKR-Eval with 2,000 carefully checked questions that demand real, continuous video understanding.
Step 6: Train and test models fairly
- They trained models in two stages: first SFT (learning from examples), then a simple reinforcement learning step (called GRPO) that rewards correct answers.
- They used standard training settings to keep the focus on the data design.
- They evaluated models on both general video tasks (broad understanding) and knowledge-heavy tasks (domain reasoning).
- They also standardized prompts and settings for fair comparisons.
What did they find?
- Models trained on VideoKR got clearly better at knowledge-intensive video reasoning while staying competitive on general tasks.
- For example, a 7B-parameter base model improved its average score on knowledge-heavy tests by about +4.7 points after being trained on VideoKR; an 8B model improved by about +3.0 points.
- The biggest gains appeared on tests that require domain knowledge and multi-step thinking (like medical or scientific reasoning).
- More input frames at test time helped: giving the model more of the video (e.g., 128 frames vs 16) improved performance, especially on reasoning tasks.
- Ablation studies (careful “what-if” tests) showed:
- Using all three skill types (VidR + KnowVid + KnowVidR) works best for tough reasoning.
- Including step-by-step explanations (often called “chain-of-thought”) during training gave notable improvements over just providing final answers.
- Compared to other open datasets of similar size, VideoKR data led to stronger gains in knowledge-intensive tasks.
Why is this important?
- Real-world video problems—like understanding a medical procedure, diagnosing engine faults, or analyzing a physics demo—don’t just ask “what is happening?” They ask “why, how, and what follows?” That needs both vision and knowledge.
- VideoKR shows that better data design can make AI genuinely smarter at these tasks, not just better at describing scenes.
- The new test set (VideoKR-Eval) raises the bar for evaluation by removing shortcuts, nudging the field toward models that truly watch and reason, rather than guess.
- This work gives researchers a strong, open-source foundation (new videos, high-quality questions, and a fair benchmark) for building the next generation of video reasoning systems that are more trustworthy and useful in expert domains.
Key takeaways (in simple terms)
- The team built a giant, well-checked library of educational videos and tough questions that force AI to think, not just look.
- They trained models with a two-step process: first “study with examples,” then “practice with feedback.”
- The models got better at solving real, knowledge-heavy video problems.
- A new test makes sure models can’t cheat by using just one frame.
- Bottom line: smarter training data leads to smarter video understanding.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research:
- Domain coverage scope: The Domain Knowledge Bank is built from undergraduate curricula; it is unclear how well VideoKR covers advanced professional/clinical content, vocational skills, or niche expert domains underrepresented on YouTube CC content.
- Language and regional bias: Videos and curricula appear primarily English-centric; the impact on multilingual and cross-cultural generalization is untested, and no multilingual variants of VideoKR(-Eval) are provided.
- Video length limitation: Videos longer than 30 minutes are excluded; long-context, multi-hour reasoning (lectures, surgeries, procedures) remains unaddressed, including memory and hierarchical planning over very long horizons.
- Audio modality omission: The pipeline ignores audio/dialogue/ASR; how leveraging audio (without enabling textual shortcutting) affects knowledge-intensive reasoning is unexplored.
- Frame sampling bias: QA generation uses uniformly sampled frames at 0.2 fps; the effect of this coarse temporal sampling on fine-grained or fast events, and on the kinds of reasoning the dataset favors, is not analyzed.
- Generation–inference mismatch: Examples are generated from sparse frames, but training/evaluation uses up to 128 frames; the consequences of this mismatch on learning signals and generalization are not studied.
- Single-frame filtering robustness: Training filters use two models and four random frames; evaluation filters use three models with one random frame. Whether these checks miss spurious cues (e.g., answer-bearing on-screen text, stable scene priors) or overfit to today’s model capabilities is not analyzed.
- Evolving benchmark validity: VideoKR-Eval depends on current models’ single-frame solvability; as models improve, re-annotation/refresh schedules and automatic re-filtering criteria are not specified.
- Reliance on proprietary models: Multiple pipeline stages depend on closed-source M(L)LMs (e.g., GPT-5.x); reproducibility, cost, and bias introduced by these models vs fully open pipelines are not quantified.
- CoT verification reliability: Reasoning traces are validated by another MLLM; residual verifier bias, false accept/reject rates, and disagreement with human experts are not systematically measured (e.g., inter-annotator agreement, adjudication studies).
- Error analysis granularity: Manual audit reports aggregate error counts, but lacks breakdown by skill type, domain, video length, or content characteristics to target future data cleaning and synthesis improvements.
- Distractor quality in MCQs: There is no quantitative assessment of distractor hardness, diversity, or adversarial near-miss design, nor analyses of model shortcutting through superficial lexical cues in options.
- Reward design limitations: RL uses EM/ROUGE accuracy rewards; the lack of process-level or evidence-grounding rewards means models can game final answers; exploring verifiable stepwise/process rewards is left open.
- Faithfulness and grounding: No measurement of whether generated rationales reflect actual internal reasoning (vs post-hoc); no spatiotemporal grounding supervision/evaluation (e.g., citing frames/regions for each reasoning step).
- Robustness and security: Model robustness to temporal perturbations (shuffling, speed change), adversarial edits, occlusion, compression artifacts, or synthetic distractor segments is not tested.
- On-screen text confounders: The dataset may allow answering via reading prominent on-screen text; no analyses disentangle text-reading from visual reasoning, nor controlled variants that mask text for diagnostic evaluation.
- External knowledge use: Tasks require domain knowledge but training does not assess retrieval/tool-augmented approaches (e.g., calculators, symbolic solvers, medical guidelines); how explicit retrieval affects performance and faithfulness is open.
- Data scaling laws: The relationship between dataset size/composition (per skill/domain) and performance is not characterized; optimal skill mixtures, diminishing returns, and cost-effectiveness remain unknown.
- Model scaling effects: Results focus on 7B–8B bases; how gains translate across larger/smaller models, and interactions with pretraining quality, are not examined.
- Training efficiency: Compute/data efficiency and ablation of training schedules (epochs, RL steps, curricula over skills) are not explored; practical recipes for low-resource labs are missing.
- Generalization/OOD: Transfer to domains absent or underrepresented in VideoKR, cross-dataset generalization stress tests, and calibration/abstention behavior under uncertainty are not evaluated.
- Safety, ethics, and bias: Safety filtering uses four random frames and image moderation only; audio/text safety, domain-specific harms (e.g., medical), demographic bias, and hallucination risks are not systematically audited.
- Decontamination scope: Decontamination targets benchmarks in LMMs-Eval; potential leakage from pretraining corpora (videos or transcripts) is not assessed, and VideoKR-Eval itself may include videos already seen by base models.
- Task diversity: The corpus centers on QA; other verifiable task formats (counterfactual reasoning, temporal localization with rationales, procedural planning, numerical/scientific estimation with tools) are not included.
- Temporal reasoning depth: Causal, counterfactual, and physics-consistent temporal reasoning over extended intervals is not separately benchmarked, limiting diagnosis of true temporal inference capabilities.
- Licensing constraints: Exclusive reliance on CC YouTube may skew content toward certain subjects and production styles; coverage of industrial, clinical, or safety-critical scenarios with limited CC availability remains sparse.
- Human oversight throughput: Only 1,800 seed examples are expert-authored; the fraction of large-scale synthetic data receiving human review, and strategies to prioritize human time for maximum quality impact, are not detailed.
- Maintenance and versioning: Policies for updating VideoKR and VideoKR-Eval (e.g., periodic re-filtering, adding domains, tracking breaking changes) are not specified, limiting longitudinal comparability.
Practical Applications
Overview
The paper introduces VideoKR: an open, large-scale corpus and evaluation suite purpose-built for knowledge- and reasoning-intensive video understanding. The contributions include: (a) a domain knowledge–driven, CC-licensed video collection across 82 subjects; (b) a skill-oriented QA generation pipeline with validated chain-of-thought (CoT) rationales; (c) rigorous human-in-the-loop quality control and multi-model single-frame filtering to ensure genuine video dependency; (d) split datasets for SFT and RLVR; and (e) VideoKR-Eval, an expert-annotated benchmark that resists single-frame shortcuts. Empirically, VideoKR improves knowledge-intensive video reasoning under a standard SFT→GRPO pipeline, and ablations provide actionable data-design guidance.
Below are practical, real-world applications derived from the dataset, methods, and findings, grouped by deployment horizon. Each item notes relevant sectors, potential tools/workflows/products, and feasibility assumptions or dependencies.
Immediate Applications
These applications can be deployed now using the open-sourced corpus, pipeline designs, and evaluation methods described in the paper.
- CC-licensed, domain-targeted video data sourcing for AI training
- Sectors: software tooling, media platforms, AI labs
- What: Adopt the knowledge-driven collection protocol (knowledge bank → scenario generation → CC-filtered YouTube search → visual relevance check) to assemble legally reusable, domain-rich video datasets.
- Tools/workflows/products: “CC-safe Video Harvester” that builds domain-specific corpora; integration with YouTube API; content-safety filters (e.g., Azure image moderation).
- Assumptions/dependencies: Continued availability of CC content; API access and rate limits; internal content-governance and legal review.
- Skill-oriented QA synthesis with validated CoT for video models
- Sectors: software/AI, EdTech, enterprise training
- What: Use the three-skill template (VidR, KnowVid, KnowVidR) to generate balanced training data and explanations for video assistants.
- Tools/workflows/products: “Video QA Generator” service that ingests videos and outputs MCQ/open-ended items with CoT; seeds curated by SMEs; self-consistency and verifier checks.
- Assumptions/dependencies: Access to frontier MLLMs (or strong open models) and SMEs for seed examples and spot-checks; compute for generation and verification.
- Multi-model single-frame probing to harden benchmarks and vendor evaluations
- Sectors: procurement, standards, AI governance, academia
- What: Apply the paper’s multi-model, multi-trial single-frame filter to ensure benchmark items require continuous video understanding (reduce shortcutting).
- Tools/workflows/products: “Video Benchmark Auditor” that flags likely single-frame-solvable items and prompts re-annotation.
- Assumptions/dependencies: Access to multiple strong MLLMs; acceptance of a stricter filtering criterion; human re-annotation capacity.
- Reproducible evaluation pipelines for video reasoning
- Sectors: AI labs, model hubs, MLOps
- What: Standardize prompts, frame budgets, and inference settings (e.g., via LMMs-Eval) to reduce cross-paper mismatch and ensure apples-to-apples comparisons.
- Tools/workflows/products: Evaluation harnesses with model-specific prompt templates; CI/CD for model eval.
- Assumptions/dependencies: Community alignment on reference prompts and frame caps; access to benchmarks (including VideoKR-Eval).
- Post-train compact video models for domain tasks
- Sectors: manufacturing, energy, lab operations, healthcare education
- What: Fine-tune 7B–8B MLLMs on VideoKR to power knowledge-aware video QA, procedure understanding, and incident explanation without massive closed models.
- Tools/workflows/products: Task-tuned assistants deployed behind APIs; on-prem options for sensitive video.
- Assumptions/dependencies: Adequate GPUs; domain adaptation with small finetunes; data privacy compliance.
- Lecture and lab-video tutors with rigorous Q&A and explanations
- Sectors: education, corporate L&D
- What: Generate quizzes and stepwise explanations for lecture or lab videos, aligned with curricula via a Knowledge Bank.
- Tools/workflows/products: Tutor plugins for LMS; automated assessment item generation; study-mode with CoT.
- Assumptions/dependencies: Institutional approval; content licenses; oversight to prevent hallucinated knowledge.
- Knowledge-aware video search and indexing
- Sectors: search/media, knowledge management
- What: Use knowledge-point → scenario mapping to tag videos with domain concepts and procedural roles (apparatus, steps, outcomes).
- Tools/workflows/products: “Concept Indexer” that enriches metadata; semantic retrieval for “videos demonstrating X principle in Y context.”
- Assumptions/dependencies: Robust concept extractors; ontology alignment across subjects; periodic re-indexing.
- Safety and compliance review of specialized procedures
- Sectors: laboratories, manufacturing, chemical processing
- What: Analyze process videos to check for required apparatus use and procedure ordering (KnowVid/KnowVidR) and flag deviations.
- Tools/workflows/products: Compliance dashboards; rule templates per SOP; exception reports with grounded evidence.
- Assumptions/dependencies: High-quality, appropriately placed cameras; SOP digitization; human-in-the-loop triage.
- Sports and skill coaching with concept-grounded feedback
- Sectors: sports tech, creator tools
- What: Provide step-by-step feedback that ties movement patterns to domain concepts (biomechanics, rules).
- Tools/workflows/products: Consumer coaching apps; interactive overlays with rationale snippets.
- Assumptions/dependencies: Sufficient video quality; liability disclaimers; calibration for camera angles.
- Inference-time frame budgeting best practices
- Sectors: MLOps, product teams
- What: Apply the paper’s finding that more frames consistently help; auto-tune frame budgets by task to balance latency vs. accuracy.
- Tools/workflows/products: “Frame Budget Controller” that adapts N-frames per query; quality-of-service policies.
- Assumptions/dependencies: Model supports variable frame inputs; downstream SLAs and cost constraints.
- Human-validated model-pool orchestration for data synthesis
- Sectors: data engineering, AI labs
- What: Replace single-model pipelines with stage-eligible model pools validated on held-out samples, reducing generator bias.
- Tools/workflows/products: Orchestrators that route steps (e.g., metadata screening vs. CoT generation) to vetted models.
- Assumptions/dependencies: Contract or API access to multiple models; SME bandwidth for periodic audits.
- Contamination mitigation playbooks for video datasets
- Sectors: dataset providers, benchmark owners
- What: Use ID- and perceptual-hash–based de-dup to avoid eval leakage and benchmark contamination.
- Tools/workflows/products: Decontamination scripts; continuous dataset hygiene jobs.
- Assumptions/dependencies: Access to eval video IDs; careful threshold selection for near-duplicate detection.
Long-Term Applications
These applications require further research, scaling, domain integration, regulatory approvals, or technical advances (e.g., longer context, real-time inference).
- Clinical video reasoning assistants
- Sectors: healthcare
- What: Interpret surgical, endoscopy, ultrasound, and rehab videos to provide evidence-grounded checklists, risk alerts, or rationale-backed summaries.
- Tools/workflows/products: “Procedure Companion” with validated CoT; EMR integration; multimodal RL with verifiable rewards beyond QA.
- Assumptions/dependencies: IRB approvals, HIPAA/GDPR compliance; domain datasets with PHI-safe pipelines; rigorous validation and FDA clearance.
- Real-time industrial inspection and causal diagnosis
- Sectors: manufacturing, energy, aviation
- What: Detect procedural anomalies and infer likely root causes (e.g., equipment misuse, unsafe sequencing) from live video streams.
- Tools/workflows/products: Edge-deployed reasoning models; sensor fusion; incident simulators for RLVR.
- Assumptions/dependencies: Long-context video handling; low-latency inference; robust rewards for non-QA tasks; operator acceptance.
- Autonomous laboratory monitoring and lab-notebook generation
- Sectors: R&D, pharmaceuticals, chemistry
- What: Track apparatus, reagent states, and quantities from experiment videos; auto-generate structured logs and inferred outcomes.
- Tools/workflows/products: “Video-to-ELN” pipeline; digital twin validation; uncertainty-aware claims with evidence links.
- Assumptions/dependencies: Fine-grained visual recognition accuracy; calibrated quantity estimations; lab integration and QA.
- Disaster response and infrastructure assessment from aerial video
- Sectors: public safety, civil engineering
- What: Reason over drone footage to assess structural integrity, identify hazards, and prioritize triage with knowledge-grounded rationale.
- Tools/workflows/products: Field-ready inference kits; incident triage dashboards; policy playbooks for deployment.
- Assumptions/dependencies: Domain-labeled training data for post-disaster conditions; coordination with agencies; robustness to adverse visuals.
- Knowledge-intensive driver assistance and fleet safety analytics
- Sectors: automotive, logistics, insurance
- What: Interpret driver actions and road events with rule-based knowledge (traffic laws, defensive driving principles) to explain risky behaviors.
- Tools/workflows/products: In-cabin/external video analyzers; explainable safety scoring; claims adjudication support.
- Assumptions/dependencies: Privacy safeguards for cabin video; regional legal knowledge integration; high recall with low false positives.
- Legal forensics and compliance review from surveillance video
- Sectors: legal, compliance, security
- What: Evidence triage and chain-of-reasoning reports distinguishing plausible alternatives, grounded in observable video facts.
- Tools/workflows/products: Audit-ready “Reasoning Dossiers” with timestamped evidence; provenance-tracking of CoT.
- Assumptions/dependencies: Chain-of-custody standards; explainability requirements; adversarial robustness.
- Standardized benchmarks and procurement criteria for video AI
- Sectors: policy, standards bodies, enterprise IT
- What: Institutionalize multi-model single-frame filtering and VideoKR-like criteria as minimums for “claims of video reasoning.”
- Tools/workflows/products: Public benchmark suites; procurement checklists; conformity assessments.
- Assumptions/dependencies: Multi-stakeholder consensus; periodic refresh to prevent overfitting; open governance.
- Multilingual, cross-cultural knowledge banks for global video reasoning
- Sectors: global education, international media
- What: Extend the knowledge-bank and scenario generation to multilingual, culturally specific practices (e.g., regional lab standards, local sports).
- Tools/workflows/products: Cross-lingual ontologies; translation-aware QA generation; localized VideoKR-Eval variants.
- Assumptions/dependencies: SME availability across languages; bias and fairness audits; data availability in non-English CC content.
- AR-guided, step-by-step assistants for hands-on tasks
- Sectors: consumer electronics, field service, maker communities
- What: Wearable guidance that watches user actions and provides knowledge-grounded, context-aware feedback in real time.
- Tools/workflows/products: On-device video reasoning with CoT snippets; “next best action” prompts; safety-check overlays.
- Assumptions/dependencies: Efficient, privacy-preserving on-device models; low-latency; robust tracking in uncontrolled environments.
- Sports analytics with tactical/biomechanical reasoning
- Sectors: pro/college sports, broadcasting
- What: Multi-hop analysis connecting biomechanics to tactics and rules; generate coach-level explanations and counterfactuals.
- Tools/workflows/products: Team analytics platforms; broadcaster explainers; player development tools.
- Assumptions/dependencies: High-frame, multi-angle feeds; calibrated models per sport; acceptance by coaching staff.
- Extended-context, hours-long video understanding
- Sectors: surveillance, entertainment, MOOCs
- What: Sustain reasoning over long-form content (lectures, multi-shift operations), tracking entities and evolving states.
- Tools/workflows/products: Hierarchical memory; episodic summarization with verifiable anchors; long-horizon RLVR.
- Assumptions/dependencies: Scalable context handling and memory; stable evaluation metrics for long video; compute cost control.
- Safer content moderation with reasoning-aware decisions
- Sectors: social platforms, UGC marketplaces
- What: Move beyond single-frame classifiers to evidence-grounded, policy-linked decisions (e.g., context determines safety).
- Tools/workflows/products: “Policy-COT Moderation” with video-grounded justifications; reviewer tooling with evidence highlights.
- Assumptions/dependencies: Platform policy mapping to model prompts; adjudication pipelines; transparency/audit requirements.
Notes on feasibility across applications:
- Compute and latency: Most long-term use cases require efficient, long-context models or edge acceleration.
- Data privacy and legal: Many verticals (healthcare, automotive, legal) need strict privacy, security, and compliance controls.
- Domain coverage: Performance depends on how well the domain knowledge bank and training data match target tasks; additional finetuning may be needed.
- Reliability and verification: RL with verifiable rewards works well for QA; broader tasks need new, reliable reward signals and human verification.
- Human-in-the-loop: Critical for high-stakes deployments to validate CoT, resolve ambiguity, and manage liability.
Glossary
- Ablation: A controlled study where specific components are removed or varied to assess their impact on performance. "We further conduct comprehensive ablations to isolate the contributions of VideoKR"
- Azure AI's image moderation APIs: Microsoft’s content safety service used to detect and filter unsafe imagery. "Azure AI's image moderation APIs"
- Chain-of-Thought (CoT): Explicit, step-by-step reasoning traces that explain how an answer is derived. "Chain-of-Thought"
- Creative Commons (CC): A family of licenses that allow reuse of creative works under specified conditions. "Creative Commons (CC) licensed"
- Decontamination protocol: Procedures to remove overlap between training and evaluation data to prevent leakage. "two-stage decontamination protocol"
- Domain Knowledge Bank: A structured repository of domain-specific “knowledge points” (terms and definitions) organized for coverage. "Domain Knowledge Bank"
- Evaluation leakage: When evaluation content inadvertently appears in training data, compromising test validity. "To prevent evaluation leakage"
- Exact Match: A metric that rewards correctness only if the model output exactly matches the target answer. "Exact Match for multiple-choice QAs"
- Frame budgets: The number of video frames provided to a model during inference, affecting available temporal context. "frame budgets"
- GRPO: A reinforcement learning optimization method used in post-training to improve policy performance. "run GRPO on VideoKR-RL-114K"
- Hierarchical knowledge organization framework: A multi-level structure (Subject → Course → Lecture → Knowledge Point) for organizing domain content. "a hierarchical knowledge organization framework"
- Human-in-the-loop: A synthesis or evaluation process where human experts audit and guide automated model steps. "human-in-the-loop, skill-oriented example generation pipeline"
- Knowledge-enhanced Video Perception (KnowVid): Perception tasks where visual cues are interpreted with explicit domain knowledge. "Knowledge-enhanced Video Perception"
- Knowledge-Intensive Video Reasoning (KnowVidR): Reasoning that integrates visual evidence with domain knowledge to perform multi-step inference. "Knowledge-Intensive Video Reasoning (KnowVidR)"
- LMMs-Eval: A standardized evaluation framework for large multimodal models. "LMMs-Eval framework"
- MLLMs: Multimodal LLMs that process and reason over text and visual inputs. "we prompt MLLMs to perform a secondary relevance assessment"
- Multi-hop inference: Reasoning that requires chaining multiple information steps to reach a conclusion. "multi-hop inference"
- Multi-model single-frame probing: A diagnostic that checks if multiple strong models can answer using only one video frame, indicating low video dependence. "multi-model single-frame probing"
- Near-Duplicate Video Filtering: Removing videos that are highly similar to evaluation items to avoid contamination. "Near-Duplicate Video Filtering"
- Perceptual hashing: A technique that maps visual content to similarity-preserving hashes for duplicate detection. "frame level perceptual hashing"
- Policy model: In RL, the model that generates actions (e.g., reasoning and answers) according to a learned policy. "the policy model generates its own reasoning during training"
- Prompt misalignment: Using prompts that are inconsistent with a model’s intended inference mode, leading to unfair or misleading evaluations. "prompt misalignment"
- Reinforcement learning with verifiable rewards (RLVR): RL where rewards are derived from outcomes that can be automatically checked for correctness. "reinforcement learning with verifiable rewards (RLVR)"
- Reward engineering: Designing and refining reward signals to shape model behavior during RL. "reward engineering"
- ROUGE: A set of text-overlap metrics used to score generative outputs against references. "use ROUGE for open-ended QAs"
- Self-Consistency Verification: Re-solving generated questions to ensure the reasoning leads to the same answer. "Self-Consistency Verification"
- SFT→GRPO pipeline: A two-stage post-training process of supervised fine-tuning followed by reinforcement learning optimization. "SFTGRPO"
- Single-frame answerability: The fraction of questions solvable using only one frame, indicating potential lack of true video reasoning. "Single-frame answerability rates across existing benchmarks"
- Spatiotemporal relationships: Joint spatial and temporal dependencies within video content. "integrated spatiotemporal relationships"
- Temporal dynamics: Time-varying aspects and sequences of events in video. "temporal dynamics"
- Verifiable supervision: Training with signals (e.g., multiple-choice answers) that can be automatically validated. "verifiable supervision"
- Video Dependency Filtering: Removing questions that can be answered without genuine video understanding. "Video Dependency Filtering"
- Windowed sequence matching: Comparing sequences using sliding windows to detect near-duplicates across time. "windowed sequence matching"
- YouTube Data API: Google’s API for retrieving YouTube video metadata and content. "YouTube Data API"
- Zero-RL training: Applying reinforcement learning directly without a preceding supervised fine-tuning stage. "Zero-RL training"
Collections
Sign up for free to add this paper to one or more collections.

