A Very Big Video Reasoning Suite
Abstract: Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces VBVR, a Very Big Video Reasoning suite. Think of it as a giant collection of video-based puzzles for AI, plus a fair way to grade how well AIs solve them. The goal is to help AI systems not just make pretty videos, but actually think and reason about what’s happening over time—like tracking objects, understanding cause and effect, and following instructions step by step.
What the researchers wanted to find out
They focused on three big questions:
- Can we build a huge, diverse set of video reasoning tasks so AIs can learn real problem-solving, not just video style?
- Can we create a grading system that checks answers reliably and fairly (without relying on another AI’s opinion)?
- If we train AI models with lots of these reasoning tasks, do they get better at solving new, unseen video puzzles?
How they did it (in simple terms)
They built two main things:
1) A massive dataset of video puzzles (VBVR-Dataset)
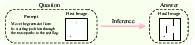
Imagine a puzzle factory. It creates many different kinds of short video tasks that test thinking skills. Each task includes:
- A starting picture (the first frame)
- Instructions (the prompt)
- A goal picture (what success looks like)
- A full example of the correct solution as a video (the ground truth)
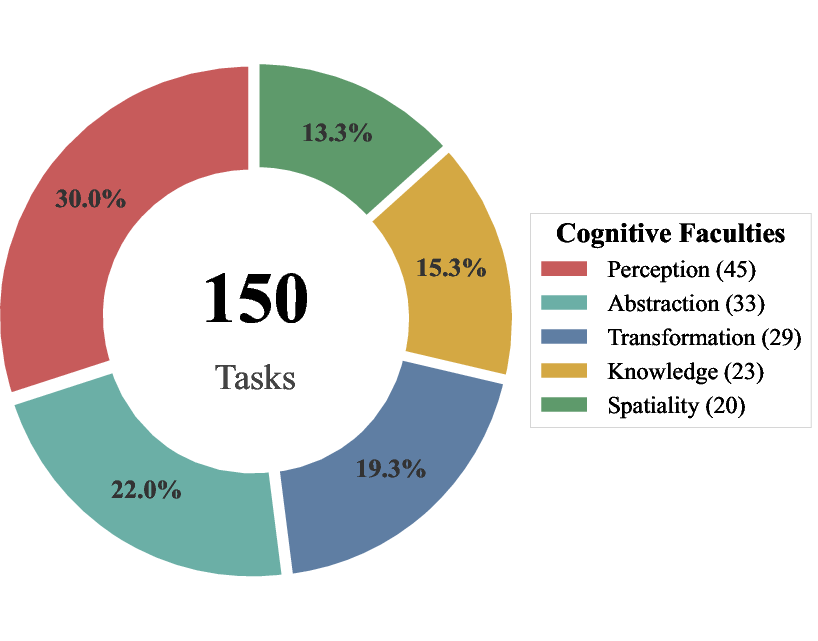
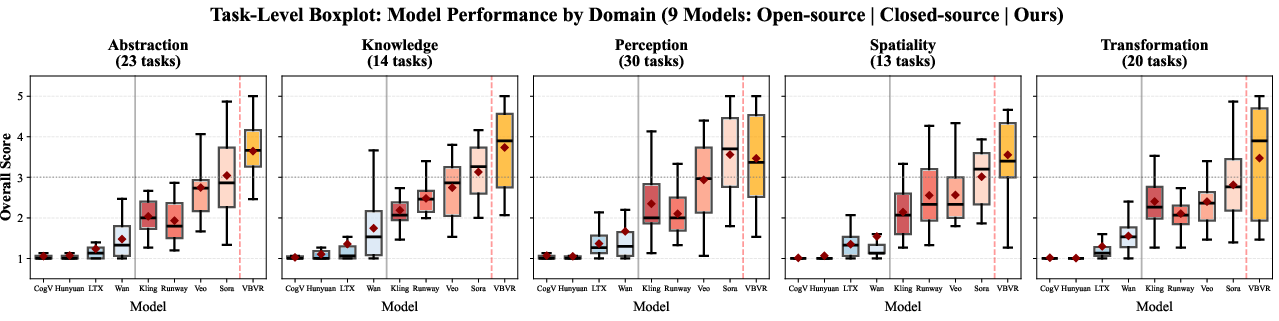
These tasks cover five “thinking skills,” inspired by how humans think:
- Perception: Noticing what’s in the scene (colors, shapes, objects).
- Spatiality: Understanding where things are and how they relate in space (like maps or mazes).
- Transformation: Predicting what happens if things move, rotate, or change over time.
- Abstraction: Spotting patterns and rules to solve puzzles (like Raven’s Matrices).
- Knowledge: Using basic facts or learned rules to make decisions.
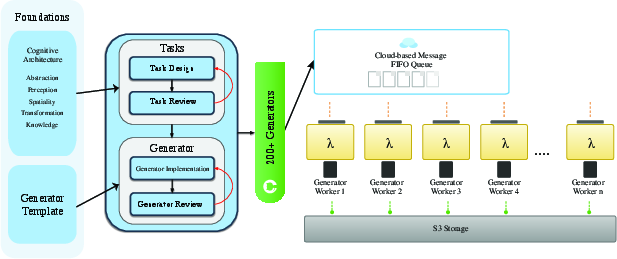
The dataset is huge: over 1 million videos across 200 types of tasks. It’s about 1,000 times bigger than previous video reasoning datasets. A cloud system generates and checks these puzzles automatically, so new tasks can be added and scaled easily.
2) A fair, rule-based grading system (VBVR-Bench)
Instead of asking another AI to judge the answers, they use clear rules—like a checklist with exact measurements. For example, in a maze task, the grader checks:
- Did the agent pick the right key and door?
- Did it follow a valid path without hitting walls?
- Was the path efficient?
- Was the animation smooth and accurate?
They tested this grading system against human opinions and found a very strong match (high correlation), meaning the automatic scores reflect what people think is “better.”
They also split evaluation into:
- In-Domain (ID): Puzzles similar to what the model saw during training, but with new details.
- Out-of-Domain (OOD): Totally new puzzle types the model hasn’t seen—this tests real generalization.
What they found and why it matters
- Bigger, smarter doesn’t mean “good at reasoning”: Many famous video models (like Sora, Veo, Runway, etc.) make nice videos but still struggle with precise multi-step reasoning. All of them are far from human-level on these tasks.
- Training on VBVR helps a lot: When they fine-tuned an open model (Wan 2.2) on VBVR, the new model (VBVR-Wan2.2) improved a ton on reasoning tasks—beating both open and closed models on their benchmark. It still didn’t reach human performance, but it got much closer.
- More data helps, but only up to a point: As they trained on more VBVR data, performance increased on both ID and OOD tasks, showing early signs of true generalization. But after a while, improvements started to plateau. There’s still a gap, especially on unseen tasks.
- Control before reasoning: Models that can keep the scene stable (same objects, same layout) do much better at reasoning tasks like “rotate this object only” or “remove just this symbol and change nothing else.” If the scene drifts or changes randomly, reasoning falls apart.
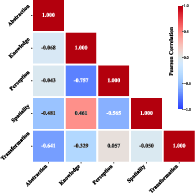
- Skills develop differently: Some abilities tend to grow together (like knowledge and spatial understanding), while others can trade off (like perception vs. knowledge in their results). This gives clues about how to balance training for different skills.
Why this is important
This work gives the research community:
- A giant, growing “gym” of video reasoning puzzles to train on.
- A fair, transparent way to grade results that matches human judgment.
- Evidence that training on reasoning-focused video data can produce meaningful gains—even on new tasks.
In the long run, stronger video reasoning could help:
- Robots plan and act safely in the real world.
- Video editors make precise, smart edits based on instructions.
- Educational tools teach problem-solving with interactive visuals.
- Scientific and engineering tools simulate and reason about complex processes over time.
Bottom line
VBVR is a big step toward AIs that don’t just make videos, but understand and reason within them. The dataset and benchmark are public, and the results show that with the right training, models can get better at real video reasoning—though there’s still a long way to go to match humans.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper establishes a large synthetic suite and a rule-based evaluation for video reasoning, but leaves several concrete issues unresolved that future work could address:
- Synthetic-to-real gap: The dataset is entirely generator-produced with simplified visuals; transfer to photorealistic, in-the-wild videos and complex cinematography remains unmeasured and likely non-trivial.
- Limited physics and causality coverage: Despite motivation around continuity and causality, the paper does not detail tasks with rich physical dynamics (e.g., contact, friction, mass, occlusion, soft-body interactions); it is unclear whether models learn or generalize intuitive physics.
- 3D reasoning and camera motion: Tasks appear largely 2D and static-camera; there is no explicit evaluation of 3D spatial reasoning, moving cameras, depth, or multi-view consistency.
- Temporal horizon and memory: Video lengths and temporal dependencies are not reported; no analysis of performance vs. horizon length or memory window is provided.
- Narrow OOD definition: “Out-of-domain” tasks come from the same generator ecosystem and visual style, risking shared low-level biases; transfer to independently created tasks or external datasets is not tested.
- Information sufficiency constraint: Requiring all cues in the first frame biases the suite toward planning/execution rather than active perception; tasks needing mid-video evidence gathering or disambiguation are underexplored.
- Evaluation sample size: Only 5 test samples per task may be underpowered; no confidence intervals, variance estimates, or power analyses are provided.
- Scorer sensitivity and Goodhart effects: Task-specific, weighted rule-based metrics may be gamed; no sensitivity analyses of weights, tolerance to benign visual/style deviations, or robustness to adversarial strategies.
- Human alignment details: The reported correlation lacks information on annotator count, inter-annotator agreement, task coverage, and sampling; alignment across all faculties and difficulty levels is not broken down.
- Aggregation choices: Overall scores average across heterogeneous task weights without justification; effect of alternative aggregation (e.g., per-faculty normalization) is not explored.
- General video quality trade-offs: The impact of reasoning fine-tuning on photorealism, style diversity, and standard video-generation benchmarks is promised but not reported; potential degradation (catastrophic forgetting) is unknown.
- Architecture constraints: Scaling experiments fix architecture and training recipe; whether architectural changes (explicit state tracking, object-centric models, memory modules, planners) alleviate the performance plateau is untested.
- Scaling laws: Only data scaling up to 500K and one-epoch LoRA is studied; no scaling laws across parameters, context length, training duration, or compute are reported.
- Training regimen ablations: LoRA rank/placement, learning rate, number of epochs, curriculum, and optimizer choices are not ablated; their influence on ID/OOD gaps is unknown.
- Supervision signals: Ground-truth trajectories exist but only paired with diffusion training; reinforcement or direct optimization against verifiable scorers is not explored.
- Task difficulty calibration: There is no difficulty taxonomy or calibration within tasks; how performance varies with controlled difficulty (e.g., grid size, clutter, distractors) is not analyzed.
- Compositionality across faculties: Tasks and analysis per faculty are presented, but systematic tests where multiple faculties must be composed within a single task are not evaluated.
- Language grounding scope: Prompts seem simple and single-shot; robustness to naturalistic language (ambiguity, coreference, multi-step instructions, dialogues) and multi-turn interaction is not examined.
- Interactive, closed-loop evaluation: All evaluations are open-loop generation; interactive settings where the model observes, acts, and adapts to feedback are not included.
- Multi-agent and social reasoning: Tasks involving multiple agents, coordination, or social cues are absent; transfer to such scenarios is unknown.
- OOD generalization gap: A persistent ~15% ID–OOD gap remains; the paper does not identify which task attributes drive this gap or propose targeted remedies beyond “more data.”
- Correlation analysis power: Capability correlations are computed over only 9 models; statistical significance, confidence intervals, and robustness to confounders are not reported.
- Generator bias and leakage: Even with disjoint seeds, shared rendering pipelines and assets may leak stylistic cues; no tests using independently developed generators to validate generalization.
- Robustness and stability: Effects of noise, compression, occlusions, viewpoint shifts, and distractors on performance and scorer reliability are not studied.
- Fairness and ethics: Societal impacts, misuse risks, and dataset licensing/asset provenance are not discussed; contributor governance and QC for community-submitted tasks lack detailed protocols.
- Reproducibility of proprietary comparisons: Inference settings (seeds, temperatures, guidance) for closed models are not standardized or disclosed; fairness of cross-model comparisons is uncertain.
- Resource reporting: Compute, energy, and wall-clock costs for generation, evaluation, and training are not provided, limiting practical reproducibility and sustainability assessment.
- Release integrity: With 50 hidden tasks for leaderboards, the risk of leaderboard overfitting and strategies to mitigate it (e.g., periodic refresh, anti-cheat checks) are not specified.
- Bridging I2V and T2V: Experiments focus on image-to-video; generality to pure text-to-video reasoning tasks, and cross-modality transfer, is not examined.
Practical Applications
Immediate Applications
The following applications can be deployed now using the VBVR-Dataset, VBVR-Bench, and the demonstrated training and evaluation workflows.
- Reproducible QA and model selection for video generation (software, media, enterprise AI)
- Use VBVR-Bench’s rule-based, human-aligned scorers to rank and compare video models under deterministic, interpretable criteria (spatial accuracy, trajectory correctness, temporal consistency, logical validity).
- Integrate VBVR-Bench into CI/CD for A/B testing, gating releases with minimum capability thresholds, and generating transparent model cards.
- Potential tools/workflows: “VBVR-Bench CI plugin,” procurement/RFP scoring templates, dashboarding for capability-by-category.
- Assumptions/Dependencies: Access to the benchmark tasks and scorer implementations; sufficient compute for evaluation runs; organizational buy-in for reproducible, non-LLM judging.
- Fine-tuning open-source video models for controllable, constraint-following editing (software, creative tools, consumer apps)
- Replicate the VBVR-Wan2.2 workflow to improve object removal with minimal unintended changes, pivot-based rotations, and constrained relocations, then ship these as product features.
- Potential tools/workflows: “Minimal-edit object deletion,” “Pivot rotation around cue,” “Constraint-guided move-to-slot,” model-as-a-tool modes in NLEs and mobile editors.
- Assumptions/Dependencies: Licensing that permits training and deployment; GPU resources; domain alignment between VBVR tasks and application content; quality and latency targets acceptable for production.
- Benchmark-driven responsible AI audits and documentation (policy, compliance, standards)
- Replace opaque LLM-as-a-judge processes with VBVR’s verifiable scorers to substantiate product claims (e.g., “maintains spatial consistency,” “follows constraints”).
- Potential tools/workflows: Conformance testing suites, audit reports aligned to VBVR categories, capability thresholds embedded in risk registers.
- Assumptions/Dependencies: Regulator or standards-body acceptance; mapping between benchmark tasks and declared claims; reproducibility policies.
- Reasoning curriculum and lab assignments (academia, education)
- Adopt VBVR tasks for coursework in video reasoning, cognitive architectures, and generative model evaluation; run scaling studies in class and publish results.
- Potential tools/workflows: Assignment kits for task design, generator coding, scorer writing; reproducible ablations; category-wise analysis (e.g., residualized capability correlations).
- Assumptions/Dependencies: Course integration and licensing; students’ access to cloud compute; lightweight subsets for teaching.
- Internal “reasoning dataset factory” for organizations (software/ML ops)
- Reuse VBVR’s parameterized generator templates to build proprietary task families aligned to business needs while preserving verifiability and scalability.
- Potential tools/workflows: Template libraries, stratified parameter sampling, automated validation and retry pipelines (Lambda/S3 or equivalents), dual ID–OOD split management.
- Assumptions/Dependencies: Cloud infrastructure and monitoring; domain experts to author task semantics; quality gates for generator code.
- Video feature QA beyond models (media product engineering)
- Apply VBVR-Bench criteria (path validity, temporal smoothness, alignment) to regression-test new editing features (tracking, rotoscoping, stabilizing).
- Potential tools/workflows: Automated pixel/object-level scoring for feature performance; test-set expansions tied to product roadmaps.
- Assumptions/Dependencies: Access to product outputs in formats compatible with scorers; mapping features to appropriate task families.
- Capability dependency mapping across model portfolios (academia, enterprise AI)
- Use VBVR’s residualized correlation analysis to diagnose structural co-development and trade-offs (e.g., Knowledge–Spatiality coupling, Perception–Spatiality trade-off) across multiple models.
- Potential tools/workflows: Cross-model capability dashboards; targeted data or training interventions guided by dependency insights.
- Assumptions/Dependencies: Comparable score vectors across models; stable evaluation protocols; statistical expertise for residualization.
- Smart-edit consumer applications (daily life, consumer software)
- Deliver cloud-backed mobile apps that perform “do exactly what is asked” edits: delete a marked object, rotate around a specified pivot, move items into designated slots, preserving layout and identity.
- Potential tools/workflows: Prompt-to-edit pipelines; constraint validators; lightweight inference endpoints; UX for visual cues (arrows, markers).
- Assumptions/Dependencies: Robust inference servers; content safety filters; latency budgets suited to consumer UX.
Long-Term Applications
The following opportunities require further research, scaling, architectural advances, or broader ecosystem adoption before widespread deployment.
- Embodied AI and household robotics with reliable spatiotemporal reasoning (robotics)
- Pretrain robot world models with VBVR-like tasks (navigation, key–door matching, obstacle-aware pathing), then adapt to real-world perception and control.
- Potential tools/workflows: Video-to-policy pretraining, explicit state tracking and memory modules, rule-verification of planned trajectories.
- Assumptions/Dependencies: Bridging sim-to-real; robust OOD generalization; integration with sensors and actuation; safety validation.
- AR guidance assistants delivering step-wise video instructions (software, education, retail)
- Generate and verify multi-step procedural videos (e.g., furniture assembly, repair tasks) with controllable execution and temporal consistency.
- Potential tools/workflows: Instruction-following video planners; constraint checkers; overlay systems for cues; user-in-the-loop corrections.
- Assumptions/Dependencies: Architecture improvements for long-horizon temporal reasoning; task libraries for diverse real-world workflows; reliable OOD transfer.
- Autonomous driving and operations training via verifiable video reasoning (mobility, industrial training)
- Evaluate and train planning modules with pixel/object-level scoring of path validity, efficiency, and temporal consistency in complex scenes.
- Potential tools/workflows: Synthetic-to-real curriculum; BFS/optimality comparators; policy distillation from scored trajectories.
- Assumptions/Dependencies: Domain gap closure; multi-sensor fusion; safety and regulatory approvals.
- Standardization and certification for generative video systems (policy, standards bodies)
- Evolve VBVR-Bench into a recognized standard for reproducible claims, capability thresholds, and model disclosures in synthetic media.
- Potential tools/workflows: ISO-like spec for rule-based scorers; public leaderboards with hidden test sets; certification programs.
- Assumptions/Dependencies: Multi-stakeholder governance; task coverage sufficiency; anti-gaming procedures; periodic updates of hidden sets.
- Detection and attribution of synthetic video manipulation via consistency checks (security, media integrity)
- Use spatiotemporal and logical consistency rubrics to flag manipulations that violate physical or geometric constraints.
- Potential tools/workflows: Forensic scoring pipelines; anomaly detectors trained on rule violations; provenance metadata.
- Assumptions/Dependencies: Robustness to natural video variability; access to reference signals or priors; legal and policy frameworks.
- Surgical and clinical video training with constraint-following verification (healthcare)
- Score instrument paths, spatial precision, and temporal consistency in training videos; provide feedback against optimal trajectories.
- Potential tools/workflows: “Procedure path validators,” skill dashboards, curriculum generation tailored to specialties.
- Assumptions/Dependencies: Medical data access and privacy; clinical validation; domain-specific task design and approval.
- Reasoning-aware video IDEs and toolchains (software)
- Build development environments that enforce constraints and verify outputs during generation (e.g., object identity preservation, permissible paths).
- Potential tools/workflows: Constraint compilers; interactive rule authoring; step-by-step generation with self-correction hooks.
- Assumptions/Dependencies: Architectural support for explicit state and self-correction; developer adoption; integration with existing content pipelines.
- Adaptive tutoring systems leveraging cognitive faculty taxonomy (education)
- Assess and train abstraction, spatiality, perception, transformation, and knowledge through personalized video tasks and rubrics.
- Potential tools/workflows: Student capability profiles; targeted curricula by faculty; real-time feedback loops.
- Assumptions/Dependencies: Pedagogical validation; age-appropriate task design; accessibility and equity considerations.
- Architectural advances inspired by saturation insights (academia, software)
- Develop models with explicit state tracking, structured reasoning modules, memory, and self-correction to close ID–OOD gaps and long-horizon failures.
- Potential tools/workflows: Hybrid generative–planner systems; differentiable constraint satisfaction; error detection and rollback mechanisms.
- Assumptions/Dependencies: Research breakthroughs beyond scaling alone; community benchmarks for longitudinal evaluation; compute and data resources.
- Living benchmark ecosystems and broader task compositionality (academia, open-source)
- Continuously expand task families, compositional regimes, and hidden sets to reflect evolving real-world reasoning demands.
- Potential tools/workflows: Community task submission pipelines; automated quality control; periodic releases with dual ID–OOD splits.
- Assumptions/Dependencies: Sustained community participation; governance to prevent leakage and gaming; funding and infrastructure.
Cross-cutting assumptions and dependencies
- Synthetic, parameterized tasks may not fully capture in-the-wild complexity; translating gains to natural videos requires domain adaptation.
- Rule-based scorers depend on tasks with unique, verifiable success criteria; general-purpose creative outputs will still need qualitative review.
- Models exhibit a persistent gap to human performance and plateauing with scale; architectural changes (explicit state, memory, self-correction) are likely required.
- Compute availability, licensing clarity (dataset, models), and cloud infrastructure (e.g., Lambda/S3-like pipelines) affect feasibility.
- OOD generalization remains a core challenge; broader compositionality and diverse task families will help but require ongoing curation.
Glossary
- a priori: Refers to knowledge or intuitions that are independent of experience. "Kant further argued the mind structures experience through a priori intuitions and categories, aggregating by Einbildungskraft~\cite{kant1998cpr}."
- Chain-of-Frame: A multi-step diagnostic paradigm that analyzes reasoning or generation across sequential frames. "multi-step Chain-of-Frame diagnosis~\cite{guo2025mmecof,liu2025genvire}"
- cognitive architecture: A principled organization of mental faculties used to structure tasks and capabilities. "grounding our task taxonomy in well-established theories of human cognitive architecture~\cite{newell1972human, anderson2007human}."
- compositional regimes: Structured combinations of components or factors designed to test generalization and composition in models. "introduce new task families and richer compositional regimes in future releases, enabling broader coverage of reasoning patterns and better closing the IDâOOD gap."
- configural associations: Learned associations about configurations of elements rather than simple pairings, often studied in neuroscience. "impaired at learning both spatial and non-spatial configural associations in a deterministic feedback task"
- data factory: An automated, scalable pipeline for producing large volumes of data and new task families. "With our data factory, we plan to continuously introduce new task families and richer compositional regimes in future releases"
- data leakage: Undesired overlap between training and test data that invalidates evaluation. "Training and test splits are constructed using disjoint random seed ranges to prevent data leakage."
- deterministic generator: A generator that produces the same output given the same inputs and seeds. "Tasks are implemented as deterministic generators supporting scalable instance variation while preserving visual clarity and video dependency."
- deterministic solvability: A task property ensuring a unique, verifiable solution. "Deterministic solvability, ensuring a unique and verifiable success criterion;"
- Diffusion models: Generative models that iteratively denoise samples to produce images or videos. "Since the inauguration of diffusion models and transformer-based scaling~\cite{ho2020denois, peebles2023scala}, video generation models are rapidly proliferating"
- DiT backbone: The Diffusion Transformer backbone architecture underlying the video model. "We employ LoRA adaptation on the DiT backbone"
- disjoint random seed ranges: Non-overlapping random seeds used to segregate training and test data. "Training and test splits are constructed using disjoint random seed ranges to prevent data leakage."
- dual-split evaluation strategy: An evaluation setup with two splits to separately measure in-domain and out-of-domain performance. "VBVR-Bench employs a dual-split evaluation strategy across 100 diverse tasks."
- Einbildungskraft: Kant’s term for the imagination faculty that synthesizes mental representations. "Kant further argued the mind structures experience through a priori intuitions and categories, aggregating by Einbildungskraft~\cite{kant1998cpr}."
- grid cells: Neurons implicated in spatial representation and navigation, forming a grid-like encoding of space. "human brains use hippocampal place cells and grid cells to support concept learning."
- ground-truth outputs: Correct, verifiable outputs provided as supervision signals for training and evaluation. "it algorithmically computes the solution and generates both the task and ground-truth outputs."
- human-aligned: Designed or validated to agree with human preferences or judgments. "a verifiable, human-aligned evaluation toolkit, VBVR-Bench."
- ID (in-domain): Evaluation or data drawn from distributions similar to those seen during training. "we observe concurrent performance improvements on both in-domain~(ID) and out-of-domain~(OOD) tasks"
- in-distribution robustness: Stability and reliability of performance on data drawn from the same distribution as training. "assess both in-distribution robustness and out-of-distribution generalization"
- Information sufficiency: A task design criterion requiring all necessary cues to be present for successful reasoning. "Information sufficiency, requiring all necessary reasoning cues to be present in the first frame and the prompt;"
- instruction following: The capability to execute tasks precisely as described by given instructions. "emergent behaviors in instruction following, controlled editing, and semantic understanding"
- Lambda (AWS Lambda): A serverless compute service used here for distributed data generation. "distributed Lambda workers writing to centralized S3 storage."
- LoRA adaptation: Low-Rank Adaptation; a parameter-efficient fine-tuning technique applied to large models. "We employ LoRA adaptation on the DiT backbone"
- model-based judging: Evaluation where a model (e.g., an LLM/VLM) acts as the judge of outputs. "moves beyond model-based judging by incorporating rule-based, human-aligned scorers"
- OOD (out-of-domain): Evaluation or data from distributions or tasks not seen during training. "we observe concurrent performance improvements on both in-domain~(ID) and out-of-domain~(OOD) tasks"
- out-of-distribution generalization: The ability to perform well on tasks or data outside the training distribution. "assess both in-distribution robustness and out-of-distribution generalization"
- parameterized task generators: Programmatic task creators with tunable parameters to produce diverse instances. "VBVR implements each category as a family of parameterized task generators."
- parametric diversity: Diversity achieved by varying parameters within generators to create many non-trivial instances. "Parametric diversity, supporting the generation of at least 10,000 non-trivial instances;"
- Pearson ρ: The Pearson correlation coefficient, measuring linear correlation between variables. "Residualized capability correlation among five faculties across 9 models (Pearson )."
- place cells: Hippocampal neurons that become active when an animal is in a specific location, linked here to concept learning. "human brains use hippocampal place cells and grid cells to support concept learning."
- residualized capability correlation: Correlation analysis after removing (regressing out) overall model strength to reveal structural dependencies. "Residualized capability correlation among five faculties across 9 models (Pearson )."
- rule-based scorers: Deterministic evaluators using explicit rules rather than learned judgments. "by incorporating rule-based, human-aligned scorers"
- S3 (Amazon S3) storage: Object storage service used here as centralized storage for generated data. "distributed Lambda workers writing to centralized S3 storage."
- scoring rubrics: Structured, weighted criteria used to score performance on tasks. "geometric, physical, or deductive constraints are also considered in the scoring rubrics."
- semantic understanding: The capability to capture and manipulate meaningfully structured content. "emergent behaviors in instruction following, controlled editing, and semantic understanding"
- Spearman’s correlation coefficient: A rank-based correlation measure used to assess monotonic relationships. "observing strong agreement between automated scores and human judgments, with a Spearmanâs correlation coefficient of ."
- stratified sampling: Sampling method ensuring balanced coverage across defined parameter strata. "Generators employ stratified sampling to ensure balanced coverage within each task's parameter space."
- Technical feasibility: A criterion to avoid unsolvable or pathological configurations in rendering and task design. "Technical feasibility, avoiding unsolvable or pathological configurations under standard rendering pipelines."
- temporal consistency: Maintaining coherent states and dynamics across frames in generated videos. "these tasks require the simultaneous satisfaction of logical constraints and long-term temporal consistency"
- TI2V: Text-and-Image-to-Video; a setting where both text and image inputs are used to generate video. "TI2V answer suites~\cite{luo2025vreasonbench,chen2025tivibench}"
- transformer-based scaling: Expanding Transformer model capacity and data to improve performance. "Since the inauguration of diffusion models and transformer-based scaling~\cite{ho2020denois, peebles2023scala}"
- verifiable supervision: Supervision that includes explicit, checkable solution traces for learning and evaluation. "provide verifiable supervision---complete reasoning paths that enable learning
how'' to reason, not justwhat'' the answer is." - video dependency: A requirement that tasks rely on temporal video information rather than static images. "Video dependency, such that the task cannot be solved from a single static image but through a process;"
- Visual clarity: A design standard ensuring unambiguous and distinguishable visual elements. "Visual clarity, ensuring all visual elements are distinguishable with unambiguous layouts;"
- VLM-as-a-judge: Using a Vision-LLM to automatically evaluate outputs. "VLM-as-a-judge paradigms have been widely adopted for evaluating video generation models~\cite{peng2025svbench}"
- zero-shot: Performing tasks correctly without task-specific training examples. "nontrivial zero-shot perceptual and manipulation behaviors"
Collections
Sign up for free to add this paper to one or more collections.

