- The paper introduces SWE-InfraBench as a benchmark for evaluating LLMs on complex AWS CDK modifications in real-world cloud infrastructure settings.
- It details a three-stage pipeline combining LLM-driven generation, sequential critique-and-refinement, and expert oversight to ensure robust task creation.
- Results highlight low single-shot success rates (up to 34%) with significant improvements via multi-turn feedback, underscoring current LLM limitations in industrial IaC tasks.
SWE-InfraBench: A Comprehensive Evaluation of LLMs on Cloud Infrastructure Code
Motivation and Position within LLM Benchmarks
SWE-InfraBench is introduced as a specialized benchmark to evaluate the efficacy of LLMs in Infrastructure-as-Code (IaC) generation, focusing on the imperative paradigm via the AWS Cloud Development Kit (CDK). Unlike existing benchmarks which typically address declarative IaC systems (notably Terraform) and prioritize codebase generation from scratch, SWE-InfraBench is engineered to capture the industrial reality: LLMs must reason over and incrementally modify substantial, stateful CDK repositories in response to nuanced natural language instructions reflective of real-world development. This yields a substantially elevated bar for context retention, codebase understanding, and domain-specific reasoning.

Figure 1: Each SWE-InfraBench task includes an IaC repository, natural language modification instructions, and automated tests verifying the correctness and integration of the generated solution.
Dataset Composition and Pipeline
The dataset encompasses 100 hand-curated tasks diversified across 34 repositories (open-source and custom), each offering a non-trivial CDK codebase, a modification prompt, and a comprehensive suite of unit tests. A three-stage hybrid pipeline—LLM-driven initial generation, sequential critique-and-refinement using distinct LLMs, and human expert finalization—ensures high-quality, robust, and generalizable tasks. This integration of LLM augmentation and expert oversight is critical given the acute paucity of pre-existing test coverage and the subtlety of infrastructure semantics.
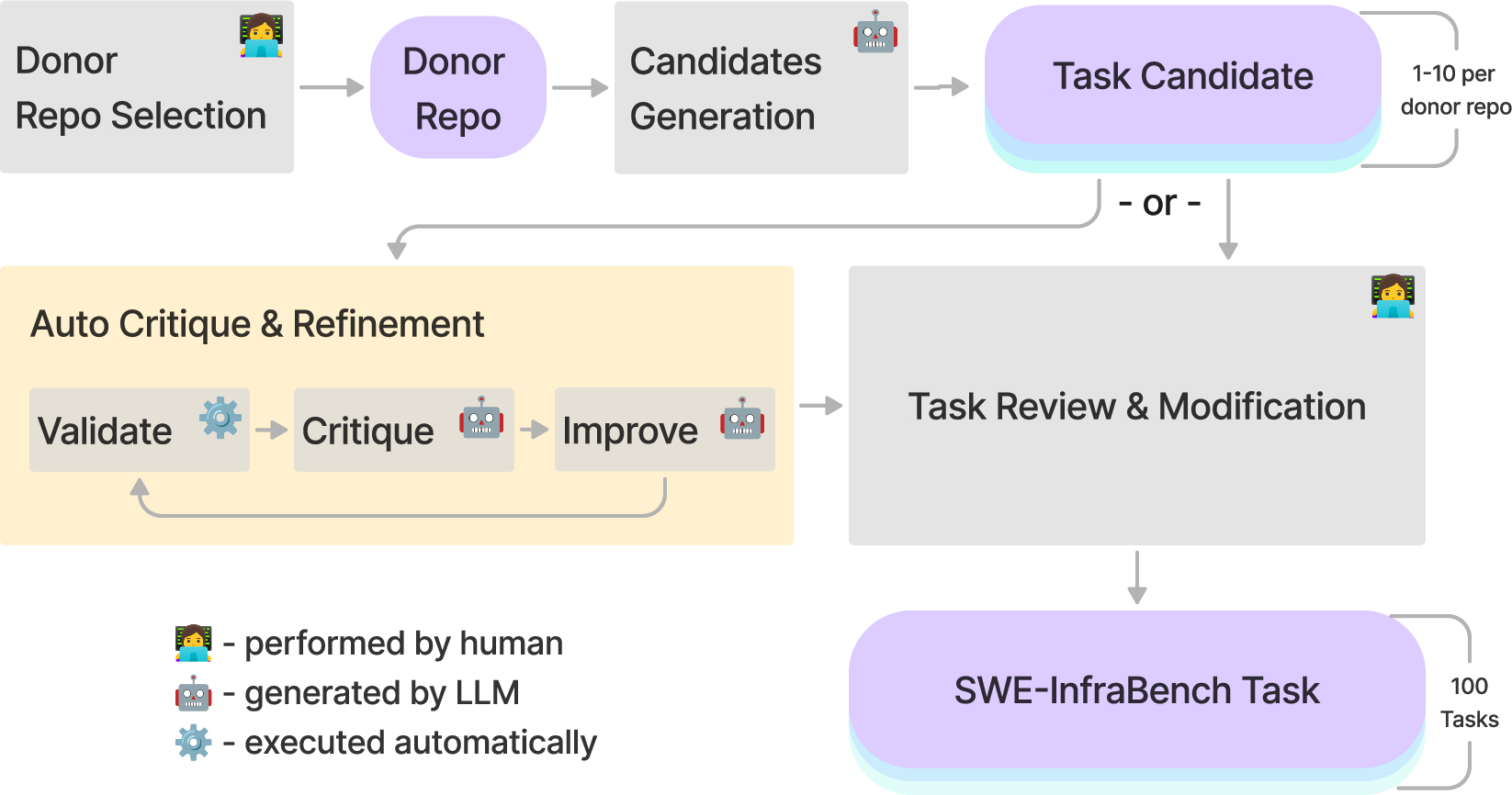
Figure 2: SWE-InfraBench task instances are created from open-source and custom developed IaC repositories in a semi-automated manner with a rigorous human engineers oversight.
The context size for tasks is non-trivial, with codebases typically comprising around 10 files and up to 30k characters, capturing realistic development scale and complexity.
Evaluation Protocol and Metrics
The evaluation scheme is grounded on execution-based validation: LLMs are required to return minimal, additive, git-style diffs, which are then integrated and verified against a canonical battery of tests; correctness is strictly pass-all-or-nothing. Metrics are pass@k (for up to 5 attempts), generation success (format adherence), and “passed tests share” for fine-grained functional coverage analysis.
Baseline Results and Analysis
A multi-model, multi-vendor experimental sweep (20 LLMs, including Claude 3.7, Gemini 2.5, DeepSeek R1, GPT-4.1, and leading open weights models) demonstrates that SWE-InfraBench is a significantly challenging benchmark. The highest single-shot pass rate—achieved by Claude 3.7 Sonnet—is only 34%. This constitutes a stringent diagnostic: contemporary foundation models, despite excelling on canonical code benchmarks, fail decisively to reach robust industrial automation for iterative IaC modification. Specialized reasoning-augmented LLMs such as DeepSeek R1 or OpenAI o3 reach, at best, 24% and 23% correctness rates, respectively.
A common weak point is observed in syntax errors, especially incorrect property usage in CDK constructs (comprising 40–85% of total errors), highlighting persistent gaps in syntactic and semantic grounding in these domain-specific frameworks. Logical errors (up to 30%) are prevalent when models generate syntactically correct yet contextually invalid solutions.
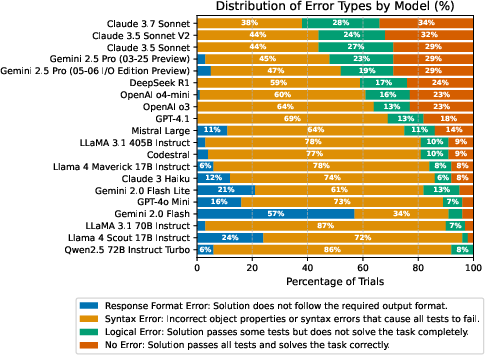
Figure 3: Distribution of error types across trials. Syntax errors are the dominant failure type (40–85%), primarily stemming from incorrect property usage in CDK constructs. Logical errors (5–30%) occur when models produce syntactically valid code that fails to meet task requirements or capture context. Response format errors are relatively rare, with Claude and OpenAI models demonstrating particular strength in format adherence.
Task Characteristics and Domain Diversity
SWE-InfraBench tasks encompass a distribution of context sizes, solution lengths, and utilize a broad spectrum of AWS CDK versions (from 2.0.0 to 2.189.1), reinforcing coverage across recent and legacy infrastructure patterns.
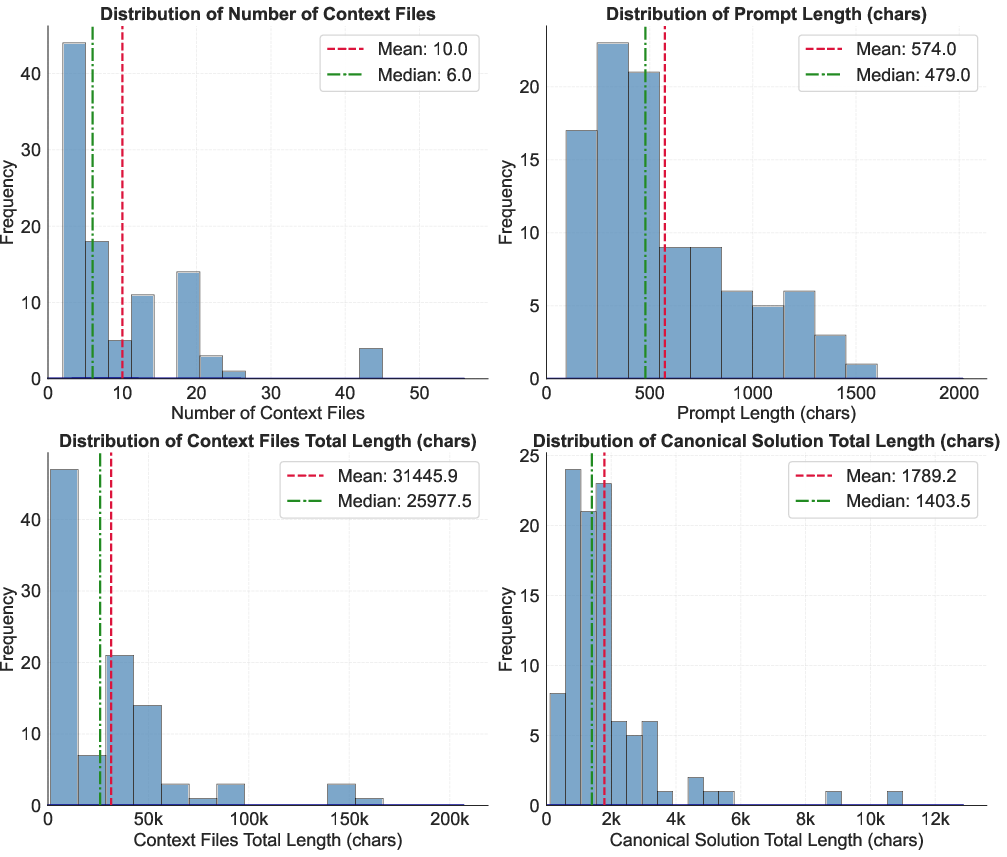
Figure 4: SWE-InfraBench Statistics on Context Size and Solution Length.
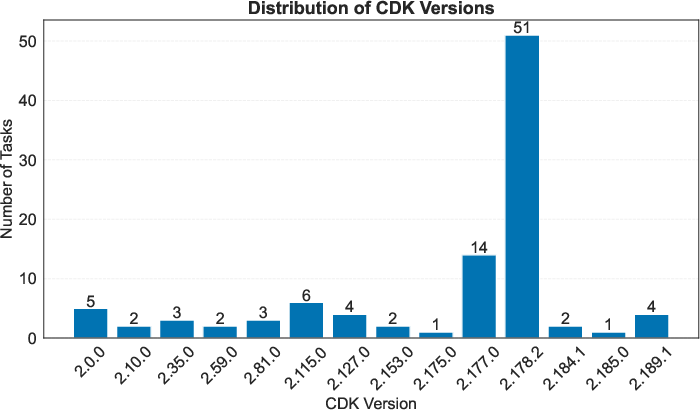
Figure 5: Distribution of AWS CDK Versions Across SWE-InfraBench Tasks.
Consistency and Multiturn Agent Analysis
Subsequent multi-trial experimentation establishes that the best-in-class models (e.g., Claude 3.7 Sonnet, Gemini 2.5 Pro) achieve higher pass@5 (e.g., up to 47% for Gemini 2.5 Pro) compared to single-shot, but remain inconsistent, with high variance in trial-to-trial outcomes. Claude 3.7 demonstrates both the highest average correctness and superior trial consistency.
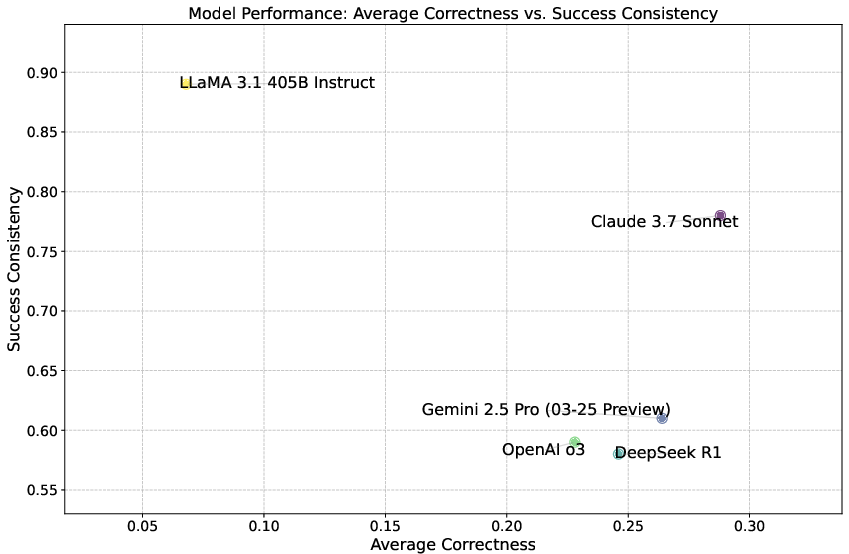
Figure 6: Average Correctness vs Consistency. Models positioned higher on average correctness, notably Claude 3.7 Sonnet, tend to demonstrate greater consistency, providing similar outcomes across repeated attempts. In contrast, models such as Gemini 2.5 Pro, DeepSeek R1, and OpenAI o3, despite achieving significant improvements when allowed multiple attempts, exhibit less consistency, indicating more variability in their success across trials.
Agentic Multiturn Refinement and RAG
Building agent-like two-turn solvers—where the LLM is given error feedback after its first failure, optionally augmented via retrieval-augmented generation (RAG) with relevant AWS documentation—yields substantial gains. For instance, Claude 3.7 Sonnet reaches 64% correctness in the high-verbosity feedback regime, a 30-point improvement over its single-attempt baseline. The gains are closely tied to verbosity: high-fidelity traceback information facilitates more robust error correction, especially in larger models.
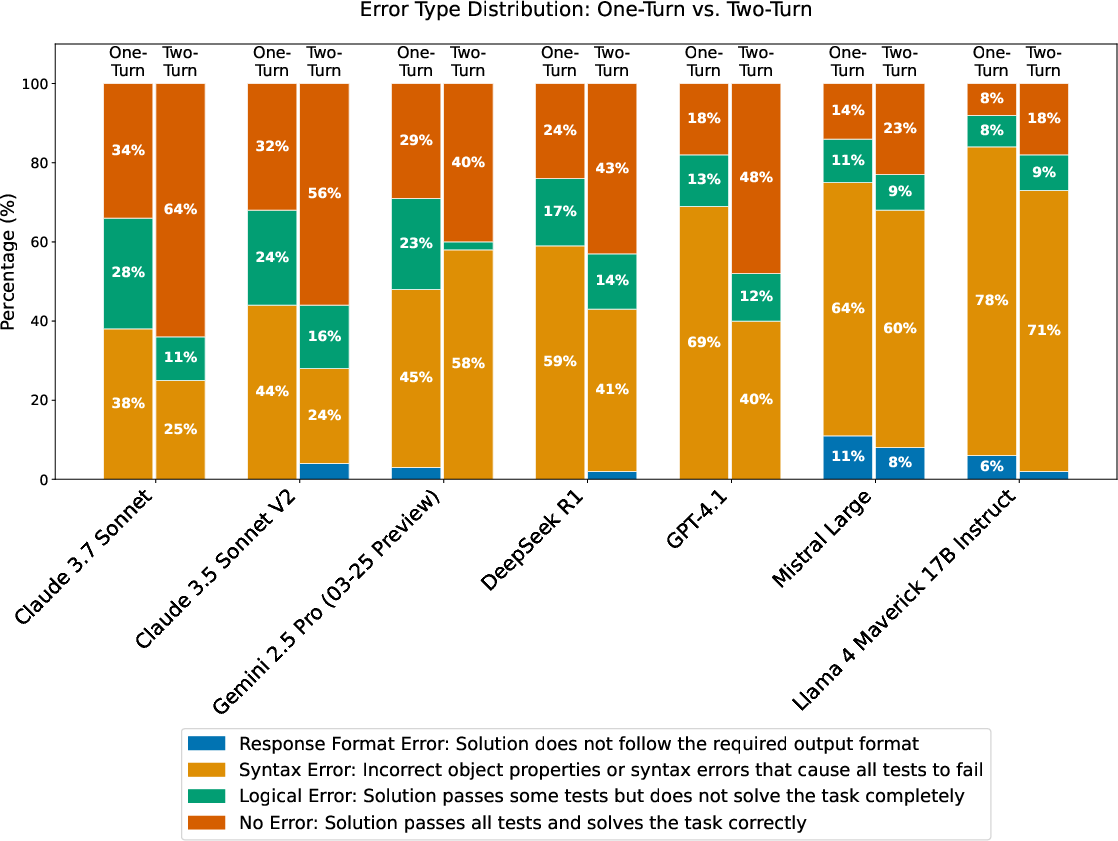
Figure 7: Error type distribution comparison between one-turn and two-turn (without RAG, high verbosity) approaches. All models show improved performance in the two-turn approach. The Claude family models demonstrate balanced improvement by reducing both syntax and logical errors. Gemini model primarily addresses logical errors in its second attempt, while GPT-4.1 and DeepSeek R1 shows substantial reduction in syntax errors. While most examples benefit from the two-turn approach, a small percentage show regression due to the inherent randomness in the generation process.
RAG benefits are non-uniform across architectures, with some models (e.g., Claude 3.5 Sonnet V2) reaching 65% correctness, whereas others (e.g., GPT-4.1) stagnate or regress compared to purely error-feedback-based iterative refinement.
Implications for LLM Research and AI in DevOps
The study presents several consequential findings:
- Present-day LLMs, even SOTA, are not yet fit for complex, context-rich IaC modification tasks encountered in production cloud environments.
- Syntax adherence remains a dominant failure mode, implicating the need for domain-adaptive syntactic regularization and more sophisticated, up-to-date knowledge integration.
- Multi-turn, agentic error-driven approaches and high-fidelity diagnostic feedback can substantially raise LLM efficacy—this finding underscores the non-negotiable importance of feedback loops and hybrid agent frameworks in future AI for code automation.
- RAG's performance is highly model-dependent, warranting further research into adaptive retrieval and context compression for memory-scarce settings.
- Automatic test-passing is necessary but not sufficient; the gap to deployment-grade reliability, covering inefficiencies, misconfigurations, and security, suggests potential future directions in static analysis integration and LLM-as-a-Judge paradigms.
Future Directions
Expanding beyond Python/AWS CDK to encompass additional languages, frameworks, and operational tools (e.g., search, scripting, and live environment integration) will be essential for achieving broader coverage and more comprehensive AI assistant evaluation. Extending benchmarks to incorporate non-functional requirements (cost, security, compliance) and simulating production-like deployment environments is critical to bridging research and operationalization.
Conclusion
SWE-InfraBench is established as the de facto standard for evaluating LLM capabilities in real-world imperative IaC codebase modification. It exposes significant limitations in current LLM architectures—even those successful on general code benchmarks—with <35% single-pass task success and substantial error fragility. However, iterative, agentic enhancements nearly double effectiveness, attesting to the value of agent-HCI workflows and advanced error-informed feedback. The benchmark provides a rigorous measurement framework for future advances in AI-driven infrastructure engineering and exposes an acute research agenda for LLMs in complex, reliability-critical domains.
Reference: "SWE-InfraBench: Evaluating LLMs on Cloud Infrastructure Code" (2606.05249)