- The paper demonstrates a proactive framework that uses iterative discovery and reusable thought templates to identify unarticulated problems across contexts.
- It details an iterative process that conditions new predictions on previous findings, substantially improving coverage and precision over baseline methods.
- Empirical results show significant gains in problem retrieval, identification, and resolution in both workplace and software repository settings.
Proactive Multi-Problem Discovery via Template-Guided Iteration: An Expert Analysis of TIDE
Motivation and Problem Definition
The deployment of LLM agents as digital assistants across domains such as workspace management and software engineering has largely conformed to a reactive paradigm, where systems await explicit user queries before engaging in problem solving. This architecture fundamentally limits agents to only the subset of issues perceived and articulated by end users, leaving unattended a suite of coexisting, unarticulated bottlenecks. The paper "TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration" (2606.04743) escalates the discussion to a more sophisticated operational regime: proactive, context-wide, multi-problem discovery. The objective is the systematic identification, evidential grounding, and actionable resolution of multiple latent problems within arbitrary contextual corpora, without prior enumeration or explicit solicitation by the user.
TIDE Framework
TIDE (Template-guided Iterative Discovery and rEsolution) introduces two key mechanisms to address the deficits of single-pass or naive multi-agent approaches:
- Thought Templates: Reusable, abstract schemas representing problem patterns, abstracted from past solved cases, which guide the agent's attention to salient evidence configurations across diverse scenarios.
- Iterative Discovery: A multi-round process where, at each iteration, a small batch of predictions is generated conditional on all previously surfaced issues, effectively expanding coverage to less salient, easily overshadowed problems.
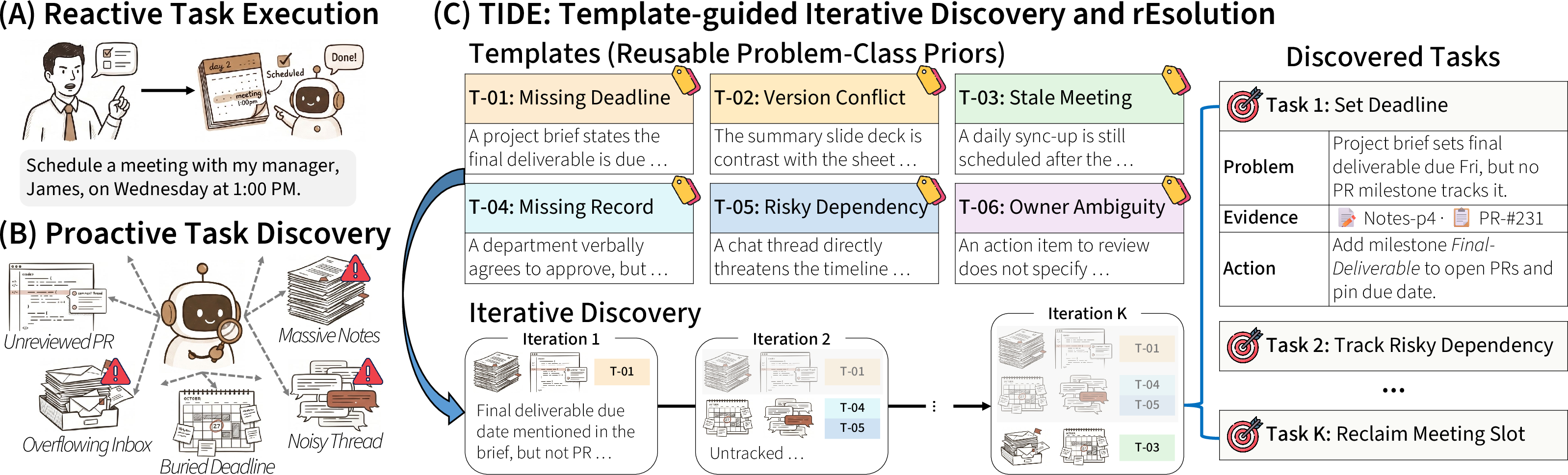
Figure 1: TIDE conceptualizes proactive assistance as iterative template-guided search over hidden problems, with contextual expansion at every round.
TIDE’s inference isolates the prediction process to tuples containing a natural-language description, a subset of evidence artifacts, and a concrete action, such that each surfaced problem is fully specified and actionable.
Given a collection of contextual artifacts D, TIDE aims to approximate the unknown set of hidden problems P⋆ by producing P^={p^1,…,p^m}, where each p^i=(b,D^,a) comprises a description, supporting evidence, and an action. This setting imposes two orthogonal requirements: maximized coverage over P⋆ and high per-instance fidelity with precise matchings in both identification and proposed resolution.
Iterative Discovery
Motivated by the observation that single-pass LMs anchor on the most salient problems and saturate early, TIDE’s iterative process updates the discovered set P^(t) after every round t, with subsequent rounds conditioning their exploration on the cumulative set of prior discoveries—explicitly defusing the classical recency/saliency bottleneck.
Thought Templates
Thought templates T encapsulate latent structural regularities. Each template ti is tripartite: a pattern label (problem class), a heuristic pattern description, and a prescribed evidential flow (sequence of contextual cues and their logical dependencies). Templates are constructed via LLM abstraction over gold examples in the training corpus, followed by deployment as reusable reasoning guides at inference.
Experimental Setup
Evaluation occurs in two complex, realistic settings:
- Personal Workspace: Each instance is an aggregate of an individual’s emails, documents, and events, with numerous coexisting unsurfaced issues (4-6 per workspace, up to 113 candidate artifacts per instance).
- Software Repositories: Each instance is an unpatched snapshot with multiple coexisting GitHub issues, each associated with one or more buggy functions (up to 41 problems and 646 candidate functions per repo).
The model pool comprises GPT-5 mini, Claude Sonnet 4.5, Gemini 3.5 Flash, and Qwen 3.6 Flash.
Evaluation relies on retrieval (evidence grounding), identification (correctness of problem description), and resolution (action efficacy), with metrics macro-averaged as Coverage and F1.
Results and Analysis
Multi-Problem Coverage
TIDE demonstrates substantial improvement over both single-pass and parallel multi-agent baselines, achieving:
- In the Workspace setting with GPT (F1): retrieval 70.46, identification 68.76, resolution 77.32
- In the Repository setting with GPT (F1): retrieval 18.61, identification 19.73, resolution 17.39
These are consistently higher than the corresponding single-pass and multi-agent results, with gains in both pure coverage and precision-oriented F1.
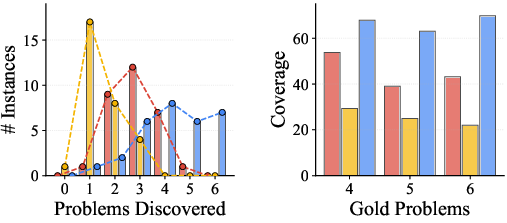
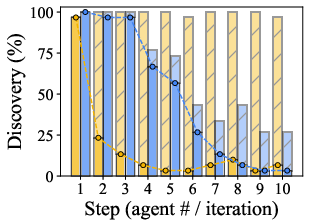
Figure 2: TIDE (left) recovers more coexisting problems per instance and maintains higher coverage even as instance gold problem count increases; (right) TIDE continues generating novel discoveries across rounds, whereas multi-agent baselines repeatedly surface the same salient problems.
Scalability and Iterative Conditioning
Analysis of discovery dynamics (Figure 2, right panel) reveals that parallel multi-agents plateau rapidly, offering diminishing returns with additional agents, while TIDE continues to accumulate new discoveries at each iteration due to explicit conditioning on prior states.
Increasing the per-instance LLM-call budget k (Figure 3) further highlights that TIDE’s gains are not a function of brute-force agent scaling but rather of superior search dynamics induced by iterative conditioning.
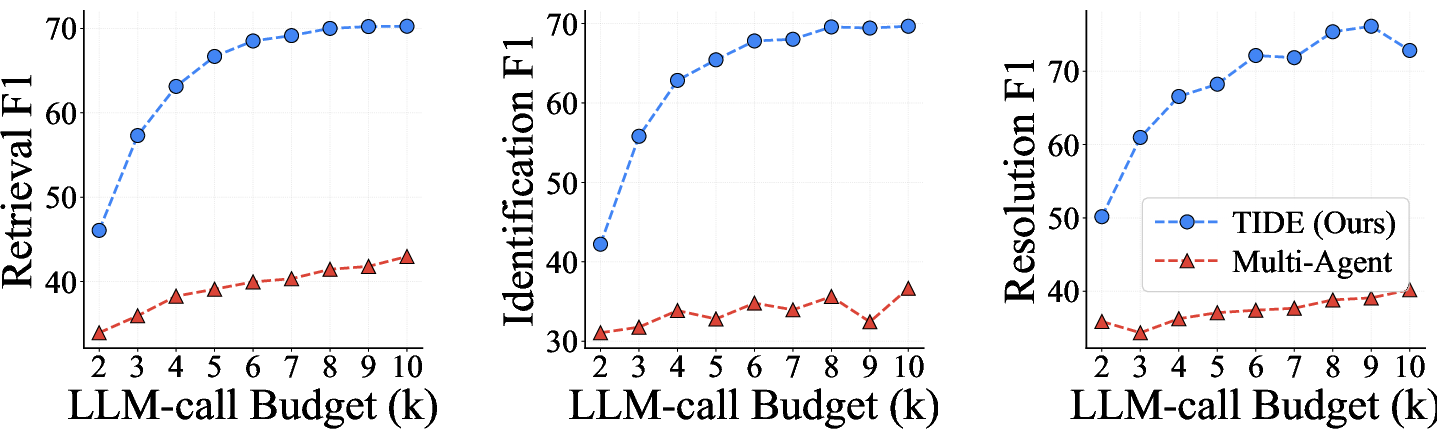
Figure 3: F1 as a function of LLM-call budget P⋆0; TIDE scales discovery performance with P⋆1, outperforming parallel multi-agents at every budget point.
Role of Thought Templates
Ablation demonstrates that pure iteration without templates improves coverage, but templates yield large, persistent precision gains (Figure 4). Templates enable the agent to deliver actionable, low-noise discoveries beyond what is obtained by operationalizing past examples as few-shot demonstrations (which underperform, per the reported results).
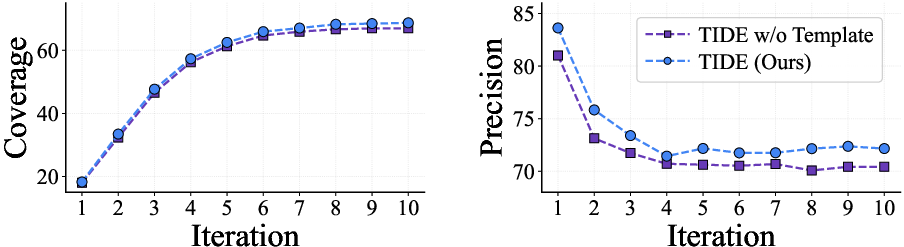
Figure 4: Iteration boosts recall, whereas templates confer significant precision improvements in retrieval per iteration.
Template pool analysis with Claude (Figure 5) confirms that template diversity and pool size further correlate with increasing F1, underscoring transferability and extensibility.
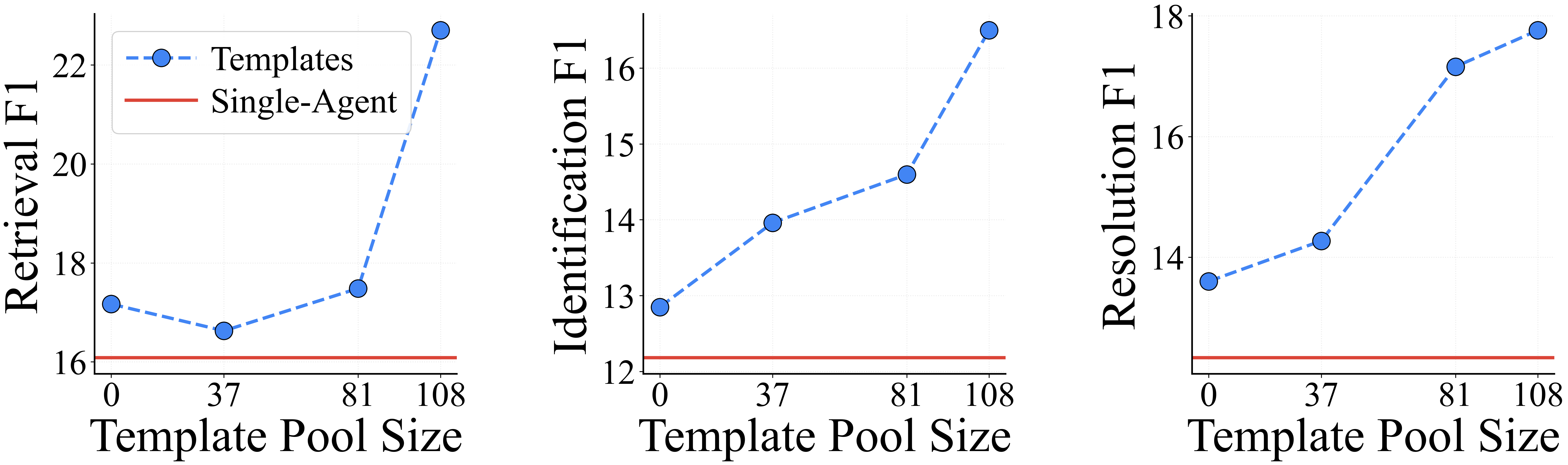
Figure 5: F1 increases monotonically with template pool size, highlighting the compositional benefit of scalable template libraries.
Cross-LLM Transferability and Template Diversity
Templates distilled by different backbones display distinct usage frequency patterns (Figure 6, left), but transfer tests (Figure 6, right) show that templates abstracted by one LLM are reusable, with comparable performance when applied by another LLM—a strong claim for backbone-agnosticity in reasoning schema design.
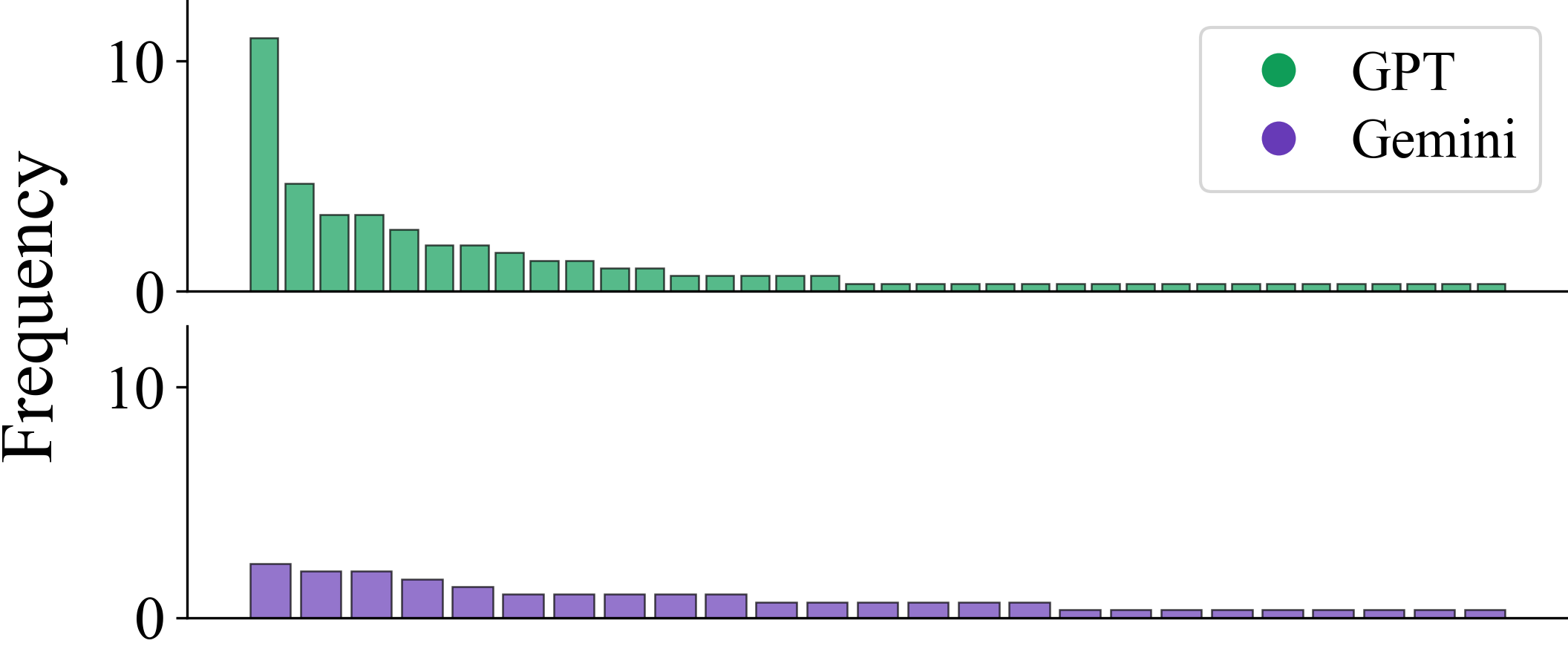
Figure 6: Left—Template usage frequency varies by LLM; Right—Templates are transferable between LLMs with only minor performance differentials.
Qualitative Outcomes
Case studies in both workspace and code settings evidence TIDE’s utility in surfacing subtle, multi-artifact problems and proposing tightly grounded, coherent actions where single-pass agents either miss the core bottleneck or issue fragmented, unintegrated recommendations.
Implications and Future Work
TIDE’s explicit shift from reactive, user-driven query handling to proactive, iterative context mining has significant ramifications for autonomous agent design. The template-guided iterative paradigm supports generalization across domains, robustifies problem discovery against saliency-driven omissions, and enables structured reasoning translatable across model backbones. Practically, this suggests designs for next-generation assistants that can semi-autonomously maintain workflow health, codebase integrity, or operational reliability without waiting for explicit user complaints.
Theoretically, the demonstrated complementarity of iterative conditioning and structural knowledge transfer (via templates) signals an important direction for integrating externalized memory and schema evolution mechanisms with LLM reasoning. Immediate extensions include online or self-adaptive template augmentation, deeper integration with retrieval-augmented architectures, and broader study of cross-domain template pools.
Conclusion
TIDE instantiates a highly effective framework for proactive, multi-problem discovery in LLM agents via the dual axes of iterative, cumulative discovery and structurally abstracted thought templates. Empirical results robustly support significant gains in both coverage and precision as compared to reactive or naive multi-agent techniques, with templates demonstrating transferability and compositional benefits. These findings advocate for reframing proactive digital assistance as a process of guided, iterative context exploration under reusable structural priors, with substantial relevance for the design of future autonomous systems.

