SFT-then-RL Outperforms Mixed-Policy Methods for LLM Reasoning
Abstract: Recent mixed-policy optimization methods for LLM reasoning that interleave or blend supervised and reinforcement learning signals report improvements over the standard SFT-then-RL pipeline. We show that numerous recently published research papers rely on a faulty baseline caused by two distinct bugs: a CPU-offloaded optimizer bug in DeepSpeed that silently drops intermediate micro-batches during gradient accumulation (affecting multiple downstream frameworks including TRL, OpenRLHF and Llama-Factory), and a loss aggregation bug in OpenRLHF that incorrectly weights per-mini-batch losses. Together they suppress SFT performance, with the optimizer bug accounting for most of the gap and the loss aggregation bug contributing a smaller additional effect. Once corrected, the standard SFT-then-RL pipeline surpasses every published mixed-policy method we evaluate by +3.8 points on math benchmarks with Qwen2.5-Math-7B and by +22.2 points with Llama-3.1-8B. Even a truncated variant with just 50 RL steps outperforms mixed-policy methods on math benchmarks while using fewer FLOPs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper looks at how to train LLMs to solve hard math problems. There are two common ways to train:
- Supervised Fine-Tuning (SFT): the model learns by studying expert examples, like a student learning from worked solutions.
- Reinforcement Learning (RL): the model practices and gets a reward when it gets answers right, and adjusts to do better next time.
Many papers claimed that “mixing” SFT and RL together in one stage works better than doing SFT first and then RL (SFT→RL). This paper shows that those claims were based on a broken starting point: common training tools had hidden bugs that made SFT much worse than it should be. When the bugs are fixed, the simple two-step plan—SFT first, then RL—actually beats all the fancy mixed methods.
The main questions the paper asks
- Are mixed SFT+RL training methods really better than doing SFT first and RL second?
- Could hidden software bugs be making the basic SFT baseline look worse than it is?
- If we fix those bugs, how well does the standard SFT→RL pipeline perform compared to mixed methods?
- Can we get the same or better results with less compute?
How they investigated (everyday explanations)
To test this fairly, the authors:
- Trained the same base models on the same math training data and tested on the same math exams.
- Compared the usual two-step pipeline (SFT→RL) with several “mixed-policy” methods that blend SFT and RL together.
- Carefully checked the training software for bugs and measured how each bug affected results.
Two key bugs they found:
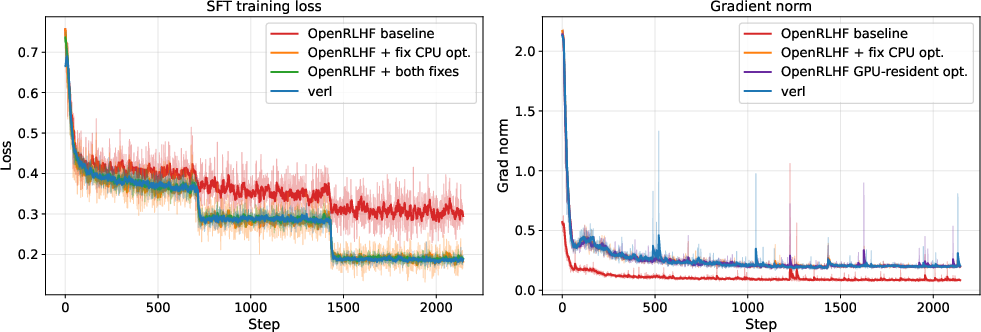
- CPU-offloaded optimizer bug (big impact)
- Analogy: Imagine you’re summing scores from 8 mini-quizzes to get your total grade, but a glitch only includes the first mini-quiz and silently ignores the rest. Your “grade” looks lower than it should.
- In training terms: when adding up small chunks of training (micro-batches), only the first chunk’s learning signal was being sent to the optimizer. Most of the learning simply didn’t count.
- Loss aggregation bug (smaller but real impact)
- Analogy: You average class test scores by averaging each class’s average equally—even if one class took 100 questions and another took 10. That’s unfair.
- In training terms: the code averaged losses per mini-batch and then averaged those averages, instead of correctly averaging over all tokens. Batches with fewer useful tokens were weighted the same as batches with many tokens, skewing learning.
They re-trained models with these bugs fixed and compared:
- Qwen2.5-Math-7B (a 7B-parameter math-focused model)
- Llama-3.1-8B (a general model with less math focus)
They used standard math benchmarks (think official problem sets like AIME, AMC, MATH, etc.), checked both “in-distribution” math tests and “out-of-distribution” general knowledge/science tests, and measured compute cost in FLOPs (a way to count how much computing work is done).
What they found and why it matters
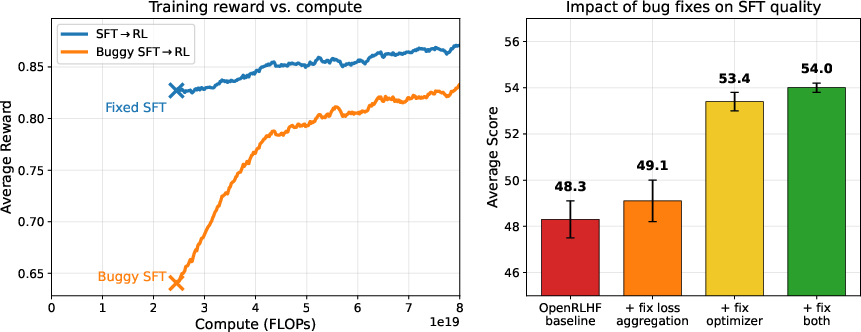
After fixing the bugs:
- SFT gets much stronger:
- Most of the lost performance was due to the optimizer bug; the loss-averaging bug added extra instability and a smaller performance drop.
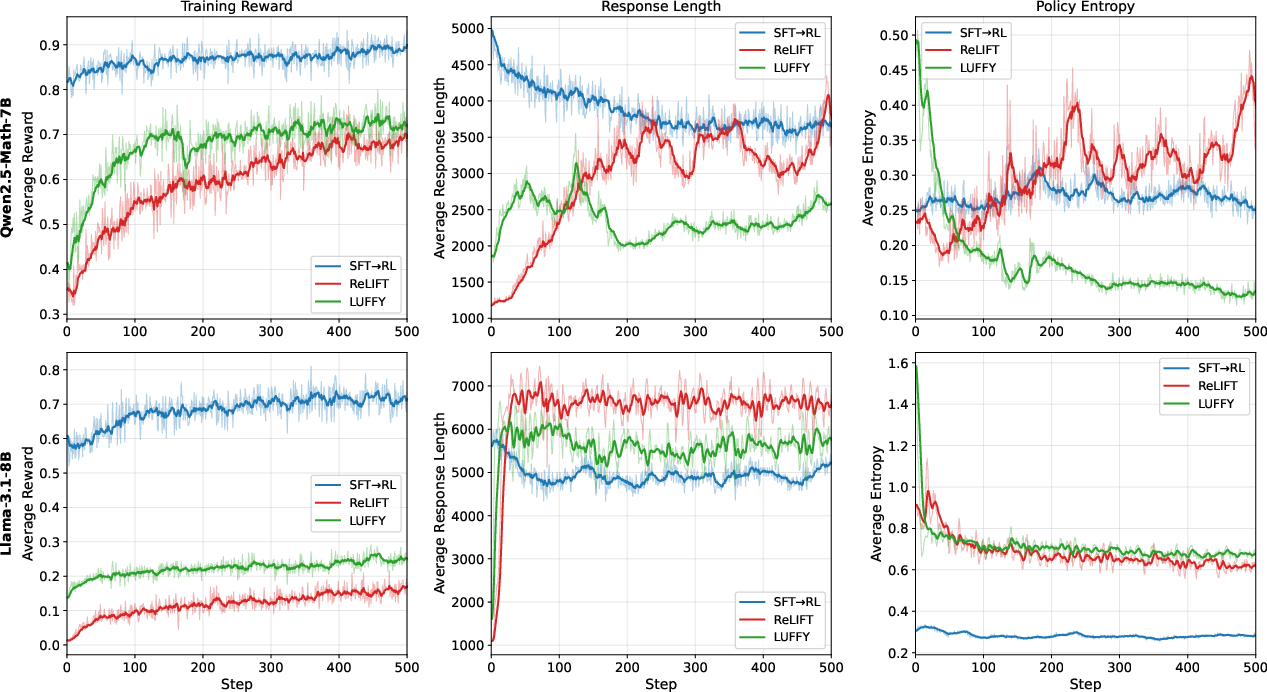
- SFT→RL beats all mixed-policy methods they evaluated:
- On Qwen2.5-Math-7B, SFT→RL scored about +3.8 points higher (on average across math benchmarks) than the best mixed-policy method.
- On Llama-3.1-8B, the gap was huge: SFT→RL beat the best mixed-policy method by about +22 points.
- Even a short RL phase works:
- Just 50 RL steps (instead of 500) after SFT still outperformed all mixed-policy methods on math tasks, and used fewer FLOPs (less compute).
- Training is more stable and efficient with SFT→RL:
- After a good SFT stage, RL starts with lots of correct answers (“dense rewards”), which makes RL efficient and stable.
- Mixed methods have to learn and refine at the same time, but early on they get very few correct answers (“sparse rewards”), so learning is slower and less efficient.
Why this matters:
- Many recent “improvements” reported by mixed methods were likely comparing against a weakened SFT baseline caused by these bugs.
- With fair, bug-free comparisons, the classic SFT→RL pipeline is not only competitive—it’s better and cheaper in compute.
What this means going forward
- SFT→RL is a strong, efficient way to train reasoning models: first “teach by example,” then “practice with feedback.”
- Research needs careful, cross-tool validation: hidden bugs in widely used training frameworks can quietly deflate baselines and mislead conclusions.
- Mixed methods aren’t useless—they might add value on top of a strong SFT checkpoint—but the published comparisons (as single-stage alternatives) don’t hold up once SFT is fixed.
- Limitations: The study focuses on math reasoning and two model families. Results could differ in other domains (like coding) or with larger models, but the main lesson—trustworthy baselines and bug-free training—still applies.
Quick glossary
- Supervised Fine-Tuning (SFT): Learning from expert examples, like studying solved problems.
- Reinforcement Learning (RL): Learning by trial and error with rewards, like practicing and getting points for correct answers.
- Micro-batches: Slices of a big training batch processed one after another to fit in memory.
- Loss: A number measuring how wrong the model is; lower is better.
- FLOPs: A measure of how much computation was used; lower usually means cheaper training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions the paper leaves unresolved, intended to guide future research.
- Domain generality: Does the SFT→RL superiority hold beyond mathematical reasoning (e.g., code generation/verification, symbolic logic, planning, multimodal reasoning, open-ended QA)?
- Scale generality: Do the findings persist at larger model scales (e.g., 32B–70B–>100B) and across more diverse model families (e.g., Qwen non-math variants, Mistral, Gemma, Phi, Qwen2.5 general)?
- RL algorithm dependence: Are conclusions invariant to different RLVR methods (e.g., PPO/RLHF with other reward models, DPO/IPO/KTO/RLAIF variants, process rewards, stepwise credit assignment, MCTS-augmented RL)?
- Verifier sensitivity: How robust are results to the choice and error profile of the verifier (e.g., Math-Verify alternatives, different false-positive/negative regimes, spurious reward mitigation)?
- Fairness under equal-compute budgets: With strict compute equalization and matched rollout budgets, do mixed-policy methods still underperform SFT→RL, or do they close the gap when hyperparameters are retuned?
- Mixed-policy on top of strong SFT: If mixed-policy training is applied after a correctly trained SFT checkpoint (rather than as a single-stage alternative), does it yield additional gains over SFT→RL?
- Hyperparameter robustness: How sensitive are the SFT→RL advantages to SFT and RL hyperparameters (LR schedules, batch sizes, KL/entropy regularization, rollout counts, curriculum strategies) across seeds and hardware?
- Data dependence: How do results vary with SFT data size/quality (e.g., fewer demonstrations, longer traces, different correctness filters, alternative datasets), and does the SFT→RL edge persist with scarcer SFT data?
- OOD breadth and retention: Beyond ARC-c, GPQA, and MMLU-Pro, does SFT→RL maintain or improve performance on broader non-math tasks (e.g., knowledge-grounded QA, reasoning-heavy reading comprehension, coding), and does RL introduce catastrophic forgetting?
- Why SRFT leads on some OOD metrics: What mechanisms enable SRFT’s stronger OOD performance relative to SFT→RL on certain benchmarks, and can those mechanisms be integrated into SFT→RL?
- Llama-specific failure modes for mixed-policy: Why do mixed-policy methods fail so severely on Llama-3.1-8B, and can curriculum design, off-policy ratios, or importance-sampling strategies fix early sparse-reward regimes?
- Training dynamics diagnostics: Beyond reward, length, and entropy, how do reasoning behaviors (e.g., self-verification, backtracking, planning steps) evolve under SFT→RL vs mixed-policy? Are quality gains consistent with process-level metrics?
- Chat template and prompt-format confounds: To what extent is the claimed improvement due to corrected SFT vs. the choice of prompt/template (especially for Llama)? Controlled ablations isolating template effects are missing.
- Evaluation sensitivity: Are the rankings stable under different sampling temperatures, decoding strategies (nucleus/beam), max lengths, and pass@k settings?
- Distribution and hardware robustness: Do the bug fixes and performance conclusions hold under varied distributed configurations (multi-node, ZeRO stages 1/2/3, FSDP, CPU/GPU offload, micro-batch counts), precision modes, and gradient checkpointing?
- Extent of ecosystem impact: Which published works and framework versions (DeepSpeed, TRL, Llama-Factory, OpenRLHF, others) were affected by the optimizer and loss-aggregation bugs? A systematic audit and version-by-version impact analysis is absent.
- Additional hidden failures: Are there other silent issues in widely used SFT/RL codepaths (e.g., token masking, padding, label shift, gradient scaling) that could bias baselines? A standardized auditing suite is not provided.
- Comprehensive reimplementations: Only LUFFY and ReLIFT were reproduced in the same codebase; other mixed-policy methods (SRFT, Prefix-RFT, HPT, etc.) were not fully reimplemented under corrected baselines. Do fair, same-framework reproductions change their relative standings?
- Multi-seed comparisons for competitors: Mixed-policy reproductions were single-seed due to compute; do multi-seed runs narrow or widen the reported gaps?
- Compute-optimal scheduling: What is the compute-optimal split between SFT and RL steps for fixed FLOPs, and how does it vary across model scales and domains?
- Reward density quantification: The paper argues SFT yields dense reward for subsequent RL but does not quantify reward density curves across methods and datasets; measuring this explicitly could clarify efficiency claims.
- RoPE/context modifications: The impact of increased context length and RoPE theta on SFT and RL outcomes is not isolated; do these modifications contribute materially to the observed gains?
- Long-horizon stability: Do training stability and the bug fixes hold over much longer RL runs, larger distributed jobs, and mixed-precision variants without regressions?
- Releasing full configs/logs: The field lacks a standardized, version-locked recipe with configs, seeds, and logs enabling end-to-end reproducibility across frameworks to prevent future baseline deflation.
Practical Applications
Immediate Applications
Below are concrete ways practitioners can apply the paper’s findings today across industry, academia, policy, and daily use.
- Fix and harden SFT training stacks that use DeepSpeed, TRL, OpenRLHF, or Llama-Factory
- Sectors: software/ML tooling, cloud/AI platforms, MLOps
- What to do: upgrade to the DeepSpeed patch that fixes the CPU-offloaded optimizer micro-batch drop; implement true per-token loss aggregation (sum/count across ranks and micro-batches) in OpenRLHF/Llama-Factory/TRL; add unit tests to catch mean-of-means loss bugs
- Tools/workflows: CI tests that compare token-weighted vs batch-mean losses; gradient-accumulation micro-batch parity tests; loss/gradient-norm monitoring dashboards
- Assumptions/dependencies: access to patched DeepSpeed version and ability to modify framework code; distributed training setup where bugs can arise
- Make cross-framework baseline validation a default step in LLM training
- Sectors: industry R&D, academia
- What to do: train short pilots in two independent stacks (e.g., PyTorch FSDP vs DeepSpeed) and compare loss scales, gradient norms, and early evals; require convergence parity before full-scale runs
- Tools/workflows: “A/B trainer” harness that runs N steps in two frameworks and auto-flags deviations beyond thresholds
- Assumptions/dependencies: availability of two viable stacks; small compute budget for validation runs
- Adopt SFT-then-RL as the default reasoning pipeline; use the 50-step RL variant to cut compute
- Sectors: AI product teams, startups, open-source model builders
- What to do: perform SFT on high-quality CoT demonstrations; then run RLVR (e.g., GRPO) with verifiers; for strong SFT starts, use ~50 RL steps with a slightly higher LR to save FLOPs while retaining gains
- Tools/products: turnkey “SFT→RL” training recipes; parameter presets for Qwen/Llama; reward-verifier integration (e.g., Math-Verify-style checkers)
- Assumptions/dependencies: availability of verifiable rewards; access to expert SFT data; the task admits automatic checkers
- Strengthen SFT baselines via recommended hyperparameters and chat templating
- Sectors: AI labs, applied research groups
- What to do: avoid overly low learning rates and mismatched batch sizes that weaken SFT; validate that models follow the intended chat template after a correct SFT stage (paper shows Llama-3.1-8B can follow the full Qwen template when SFT is correct)
- Tools/workflows: SFT hparam sweeps with early stopping; chat-template sanity tests baked into eval
- Assumptions/dependencies: comparable data quality to OpenR1-Math variants; capacity to run small hparam grids
- Re-benchmark mixed-policy claims internally and in reports
- Sectors: model vendors, evaluation platforms, enterprise buyers
- What to do: re-run SFT baselines with patched stacks; re-evaluate mixed-policy gains; update leaderboards and procurement comparisons to reflect corrected baselines
- Tools/workflows: reproducible eval harness with randomized MC option order; standardized temperatures and max tokens; pass@K tracking
- Assumptions/dependencies: access to training configs and seeds; consistent evaluation protocols
- Lower training costs with compute-aware planning
- Sectors: cloud providers, MLOps/FinOps
- What to do: prioritize SFT tokens over early-stage RL rollouts; schedule short RL phases when SFT has reached dense-reward regimes; forecast FLOPs using paper’s accounting to plan budgets
- Tools/workflows: cost dashboards projecting SFT vs RL token mix; autoscaling policies tied to reward density
- Assumptions/dependencies: reliable reward metrics; observational hooks to detect when RL signal is dense
- Domain teams with verifiable signals can replicate the recipe now
- Sectors: software engineering (unit tests), data pipelines (schema/constraint checks), education (auto-grading), operations research (solver verification)
- What to do: collect expert demonstrations; build/verbatim adopt verifiers; run SFT→RL; evaluate in- and out-of-domain targets
- Tools/products: “Verifier kits” (unit-test harnesses, graders); curated SFT datasets; domain-specific reasoners
- Assumptions/dependencies: availability and correctness of verifiers; coverage of demonstrations for SFT
- Establish internal QA for training metrics and stability
- Sectors: MLOps, platform teams
- What to do: monitor loss-level shifts, variance spikes, and gradient-norm suppression (as seen with the DeepSpeed bug); gate training continuation on passing stability checks
- Tools/workflows: automated metric anomaly detection; regression tests across seeds; logging of token counts per mini-batch/rank
- Assumptions/dependencies: consistent metric logging; standardized seed/eval protocols
- Update lab and classroom curricula with reproducibility labs
- Sectors: academia, training programs
- What to do: student labs that reproduce the bug effect and fixes; assignments on token-weighted loss; cross-framework parity checks
- Tools/workflows: minimal reproducible examples of accumulation bugs; teaching modules on RLVR vs mixed-policy dynamics
- Assumptions/dependencies: modest compute; open-stack access
- Encourage artifact and review policy changes in venues and orgs
- Sectors: journals, conferences, enterprise governance
- What to do: require publishing exact SFT configs; cross-framework validation evidence; report FLOPs and per-stage schedules; disclose verifiers
- Tools/workflows: artifact checklists; reproducibility badges that include “SFT baseline verification”
- Assumptions/dependencies: venue buy-in; feasible burden for authors
Long-Term Applications
These applications require further research, development, or scaling before broad deployment.
- Extend SFT→RL with verifiable rewards beyond math to code, data engineering, scientific workflows, and theorem proving
- Sectors: software, data platforms, science, education
- Potential products: “Code-R1” with unit-test RLVR; “Data-R1” with schema/expectations verifiers; “Proof-R1” with formal checkers
- Dependencies: robust, low-noise verifiers; scalable demo collection; domain alignment to avoid spurious rewards
- Create standardized certification for SFT baselines and training pipelines
- Sectors: model marketplaces, enterprise procurement, regulators
- Potential products: “SFT Baseline Certified” labels; third-party audits validating token-weighted loss, accumulation correctness, cross-framework parity
- Dependencies: consensus on test suites and thresholds; independent auditors
- Build automated static/dynamic analyzers for training correctness
- Sectors: ML tooling, IDEs, CI/CD
- Potential products: linters that detect mean-of-means patterns; analyzers that trace gradient offloading paths; runtime probes that validate micro-batch accumulation
- Dependencies: instrumentation hooks in frameworks; cross-version compatibility
- Revisit mixed-policy methods atop strong SFT to find additive value
- Sectors: research labs, applied ML groups
- Potential workflows: hybrid schedules that trigger mixed updates only after dense-reward SFT regimes; dynamic gates informed by rollout accuracy and entropy
- Dependencies: clean baselines; careful ablations to isolate real gains
- RLVR-as-a-Service platforms with turn-key SFT and verifier libraries
- Sectors: cloud/AI platforms, enterprises
- Potential products: managed SFT→RL pipelines; catalog of domain verifiers; autoscaling with cost and reward-density optimization
- Dependencies: secure data connectors; domain-specific IP for demonstrations; SLAs and compliance
- Safety and robustness research that leverages dense-reward regimes
- Sectors: safety, compliance, regulated industries
- Potential products: reward-hacking detectors; counterfactual verifiers; entropy/length shaping policies to avoid degeneracies
- Dependencies: robust safety verifiers; coverage against spurious shortcuts; red-teaming frameworks
- Hardware and scheduler co-design for multi-stage training
- Sectors: cloud providers, HPC centers
- Potential products: schedulers that allocate GPUs differently for SFT vs RL (token-heavy vs rollout-heavy); memory/offload policies tuned to avoid known pitfalls
- Dependencies: hardware–software co-optimization; telemetry to detect reward density transitions
- Sector-specific reasoning assistants built with curated demonstrations and verifiers
- Sectors: healthcare (coding/billing checks), finance (valuation/accounting checks), legal (citation/structure checks), education (stepwise grading)
- Potential products: domain reasoners with enforced format and verification; audit logs suitable for compliance
- Dependencies: high-quality, legally compliant datasets; verifiers aligned with regulation; domain expert oversight
- Leaderboard and benchmark governance upgrades
- Sectors: evaluation ecosystems
- Potential products: benchmarks that demand cross-framework training attestations; standardized reward-verifier disclosures; seed-averaged reporting
- Dependencies: community adoption; infrastructure to store training attestations
- Training attestations and supply-chain transparency for regulated deployments
- Sectors: government, finance, healthcare
- Potential products: machine-readable training cards documenting stacks, patches, verifiers, FLOPs, and validation evidence; audit trails for model updates
- Dependencies: policy frameworks; interoperability standards; organizational processes
Notes on Assumptions and Dependencies (cross-cutting)
- Verifier availability is pivotal: RLVR depends on reliable, low-noise, automatically checkable rewards. Domains without such verifiers will benefit less immediately.
- Findings are strongest for math reasoning and the studied model families (Qwen2.5-Math-7B, Llama-3.1-8B); generalization to other domains/scales is promising but not guaranteed.
- Correctness hinges on using patched frameworks and token-weighted loss implementations; unpatched stacks can silently deflate baselines.
- Hyperparameter choices and chat templates materially affect SFT quality; reproductions should match the paper’s settings or justify deviations.
- Compute constraints and data quality will determine how quickly RL reaches dense-reward regimes; truncated RL schedules assume a strong SFT start.
Glossary
- AIME24: A 2024 subset of the American Invitational Mathematics Examination used as a math reasoning benchmark. "AIME24"
- AIME25: A 2025 subset of the American Invitational Mathematics Examination used as a math reasoning benchmark. "AIME25"
- AMC: The American Mathematics Competition, used here as a math benchmark. "AMC"
- ARC-c: The ARC-Challenge (ARC-c) benchmark of difficult science questions. "ARC-Challenge (ARC-c)"
- avg@32: An evaluation protocol averaging accuracy over 32 sampled generations per item. "avg@32"
- Chat template: The structured system/user/assistant formatting used to wrap prompts for chat models. "Chat template."
- context length: The maximum number of tokens a model can attend to in a single sequence. "max context length from 4096 to 16,384"
- CPU-offloaded optimizer: An optimization setup where optimizer states and/or gradients are moved to CPU to save GPU memory. "a CPU-offloaded optimizer bug in DeepSpeed"
- data packing: A pretraining trick that concatenates sequences so batches have equal active tokens, affecting loss averaging behavior. "data packing ensures equal active token counts"
- DeepSpeed: A deep learning system for distributed and memory-efficient training. "DeepSpeed"
- DeepSpeed ZeRO Stage 2: A ZeRO optimization stage in DeepSpeed that shards optimizer states/gradients to reduce memory use. "ZeRO Stage~2"
- distributed data-parallel ranks: Independent worker processes/GPUs that each compute local gradients in data-parallel training. "distributed data-parallel ranks"
- evaluation temperature: The softmax sampling temperature used during generation for evaluation. "The evaluation temperature is 0.6"
- FLOPs: Floating-point operations used to measure training or inference compute cost. "using fewer FLOPs"
- FSDP: Fully Sharded Data Parallel, a PyTorch strategy that shards model states across devices. "PyTorch FSDP~\cite{FSDP}"
- GRPO: A policy-gradient reinforcement learning algorithm (Group Relative Policy Optimization) used for post-training. "runs GRPO for 500 steps"
- GPU-resident optimizer: An optimizer configuration that keeps optimizer states and gradient updates on the GPU. "the GPU-resident DeepSpeed optimizer"
- gradient accumulation: The process of summing gradients across multiple micro-batches before an optimizer step. "during gradient accumulation"
- gradient norms: The magnitudes of the gradient vectors, monitored to assess training dynamics. "gradient norms"
- importance sampling: A technique that reweights samples from a different distribution to correct for distribution mismatch. "importance sampling"
- in-distribution (ID): Evaluation on benchmarks drawn from the same distribution as the training data. "in-distribution (ID) benchmarks"
- imitation collapse: A failure mode where a policy overfits to demonstrations and loses exploration diversity. "avoid imitation collapse"
- KL-based switching signal: A mechanism that uses Kullback–Leibler divergence to decide when to switch between SFT and RL. "a KL-based switching signal"
- loss aggregation bug: An error where per-mini-batch mean losses are averaged, misweighting batches with differing active token counts. "a loss aggregation bug in OpenRLHF"
- Math-Verify: An automatic verifier for mathematical answers used to filter training data and compute rewards. "Math-Verify"
- Math-Verify: An automatic verifier for mathematical answers used to filter training data and compute rewards. "Math-Verify"
- mean of per-mini-batch means: An incorrect loss averaging scheme that averages batch means instead of a true token-level mean. "computes a mean of per-mini-batch means"
- micro-batch: A partition of a larger batch used to fit memory constraints during gradient accumulation. "micro-batches"
- mini-batch: A subset of training samples processed together to compute a single loss/gradient. "per-mini-batch"
- MCTS: Monte Carlo Tree Search, used here to derive templates for exploration in RL. "MCTS-derived templates"
- off-policy: Using data collected under a different policy than the current one (e.g., expert demonstrations). "off-policy expert demonstrations"
- on-policy: Using data (rollouts) generated by the current policy during training. "on-policy rollouts"
- OpenR1-Math-46k-8192: A filtered math dataset of 46k prompts (≤8192 tokens) with expert traces for SFT and RL. "OpenR1-Math-46k-8192"
- OpenRLHF: An open-source framework for RLHF and SFT used by several referenced works. "OpenRLHF"
- out-of-distribution (OOD): Evaluation on benchmarks differing from the training distribution to test generalization. "out-of-distribution (OOD) benchmarks"
- pass rate: The fraction of problems solved correctly, used to identify unsolved items in iterative training. "pass rate"
- pass@1: The probability that the first sampled generation solves the problem correctly. "pass@1"
- policy entropy: The entropy of the model’s action distribution, reflecting exploration vs. determinism. "policy entropy."
- policy gradient objective: The optimization objective in RL that maximizes expected reward via gradients of the policy. "policy gradient objective"
- regularized importance sampling: Importance sampling augmented with regularization to stabilize learning under distribution mismatch. "regularized importance sampling"
- reinforcement learning from verifiable rewards (RLVR): RL where rewards are computed by automatic/verifiable checks rather than human feedback. "reinforcement learning from verifiable rewards (RLVR)"
- rollouts: Sequences generated by a policy during RL training to estimate rewards and gradients. "8 rollouts per prompt"
- RoPE theta: The scaling parameter for Rotary Position Embeddings that controls positional encoding range. "RoPE theta"
- shaped policy: A transformed policy used to control update behavior or distribution mismatch during RL. "with a shaped policy "
- system prompt: The initial instruction template that sets behavior and formatting for chat models. "the full Qwen system prompt"
- TRL: The Hugging Face library for reinforcement learning with LLMs. "TRL~\cite{vonwerra2020trl}"
- verifier: A mechanism that automatically checks solution correctness to provide rewards. "as the verifier during training"
- verl: An open RL training framework used for independent baselines and reproductions. "verl"
- ZeRO Stage 1: A ZeRO optimization stage that partitions optimizer states to reduce memory, alternative to Stage 2. "ZeRO Stage~1 or~2"
Collections
Sign up for free to add this paper to one or more collections.

