- The paper introduces a novel sleep-language model that aligns multimodal PSG signals with hierarchical text supervision for interactive sleep analysis.
- It employs a multimodal pretraining framework, ReCoCa, combining contrastive, reconstruction, and autoregressive objectives to achieve superior zero-shot performance.
- Experimental results demonstrate enhanced sleep staging, event localization, and cross-modal retrieval with robust generalization on unseen sleep events.
SleepLM: Natural-Language Foundation Models for Human Sleep
Motivation and Context
Sleep physiology is inherently multimodal, continuous, and dense, with critical interactions spanning neural, cardiac, respiratory, and somatic systems. The prevailing computational paradigm for sleep analysis relies on discriminative models trained within closed label spaces, incapable of supporting open-ended reasoning, language-based description, or generalization to novel sleep phenomena. LLMs and Vision-LLMs (VLMs), despite their generative versatility, are insufficiently equipped to handle raw physiological data and exhibit suboptimal zero-shot performance on sleep-relevant tasks. "SleepLM: Natural-Language Intelligence for Human Sleep" (2602.23605) addresses these limitations by introducing sleep-language foundation models that align polysomnography (PSG) signals with natural language, enabling interpretable, interactive, and generalizable sleep intelligence.
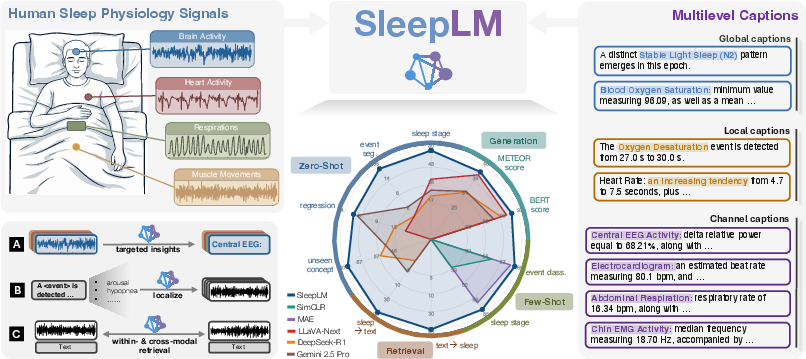
Figure 1: SleepLM is trained on >100K hours of multimodal PSG from >10,000 individuals, using a multi-level captioning pipeline and supports targeted insight generation, language-guided event localization, and zero-shot retrieval.
Multilevel Sleep Captioning Pipeline and Sleep-Text Dataset
A foundational innovation in SleepLM is the hierarchical caption generation pipeline, which produces three complementary levels of labels per PSG epoch: channel-specific statistics, local event localization, and global semantic summaries. Channel captions reflect directly measurable features per modality (e.g., EEG band power, respiratory periodicity), local captions capture transient morphological changes and event onset/offset timestamps, while global captions describe high-level physiological states (e.g., sleep stage, cardiac/respiratory summaries). This pipeline enables the assembly of the first large-scale paired sleep-text dataset, encompassing >100,000 hours from >10,000 individuals, and provides dense supervision well beyond the information bottleneck of traditional sleep datasets.
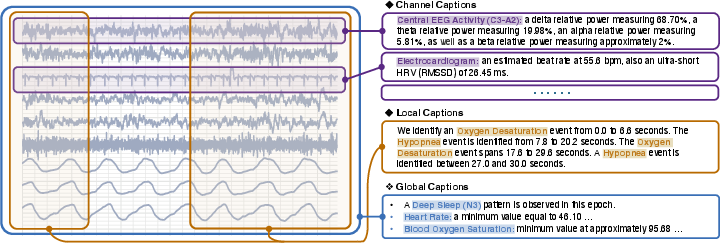
Figure 2: Multilevel sleep captioning pipeline produces channel, local, and global text supervision from each PSG window.
ReCoCa: Multimodal Sleep-Language Pretraining Architecture
SleepLM employs a generic multimodal pretraining formulation, ReCoCa (Reconstructive Contrastive Captioner), unifying signal reconstruction, contrastive alignment, and caption generation. PSG signals are embedded via channel-independent patch encoding, followed by interleaved temporal- and channel-attention mechanisms (RoPE/time, RoPE/channel). This structure supports montage-level topology and stable inter-modal relationships. The text decoder is conditioned with modality-specific tokens, enabling targeted and controllable generative outputs.
The composite objective consists of symmetric InfoNCE contrastive loss, mean-squared error reconstruction loss, and autoregressive caption generation. Ablating any component (e.g., pure CLIP-style dual-encoder, captioning-only, or CoCa-style contrastive+captioning) yields specialized variants, but full ReCoCa achieves superior performance across all task categories.
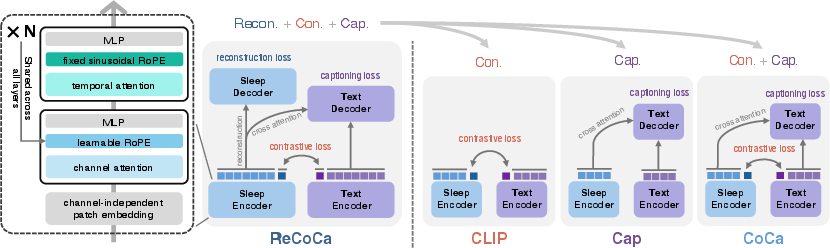
Figure 3: SleepLM architecture and pretraining objectives; ReCoCa enables joint alignment, signal fidelity, and generative supervision.
Experimental Results and Model Capabilities
SleepLM is benchmarked against fine-tuned open-source VLMs (Qwen3-VL-8B-Instruct, LLaVA-Next), proprietary LLMs (Gemini 2.5 Pro, DeepSeek-R1), and SOTA self-supervised baselines (MAE, SimCLR), across diverse task classes:
- Zero-shot sleep staging (5-class) and event localization: SleepLM achieves AUC=85.4, balanced accuracy=76.9, and event IoU=30.4, outperforming both VLMs and LLMs by significant margins. LLMs are near-random on staging and event detection, though competitive on explicit numeric regression (HR/SpO2).
- Cross-modal retrieval: SleepLM attains Recall@1 of 78.7 (external) and 96.1 (internal), demonstrating precise alignment between physiological embedding and text descriptions, far exceeding LLMs whose retrieval is only slightly above random.
- Generalization to unseen concepts: On held-out events (Mixed Apnea, Obstructive Apnea, excluded during training), SleepLM achieves F1=~80, balanced accuracy=~80, while LLMs are at chance level.
- Few-shot linear probe: In data-scarce regimes (up to 50 samples/class), SleepLM reaches ~0.90 AUC for sleep staging with just 50 samples, confirming transferability and strong data efficiency.
- Full-night clinical reporting: SleepLM produces accurate longitudinal PSG metrics, demonstrating concordance with manual scoring across thousands of epochs, outperforming fine-tuned VLMs.

Figure 4: SleepLM generates accurate, targeted, and localized sleep captions; LLM baselines lack morphological and temporal awareness.
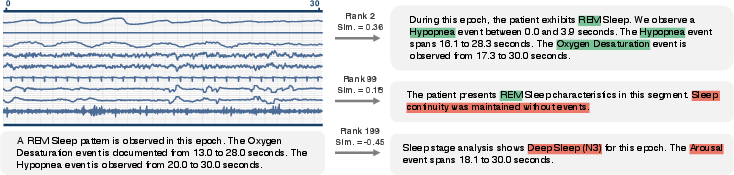
Figure 5: Semantic retrieval continuity—embedding distance of SleepLM reflects physiological similarity, supporting gradient-based exploration.
Architectural and Captioning Ablations
The superiority of SleepLM is robust to ablation:
- Removing the signal reconstruction objective degrades performance on classification and regression tasks, reinforcing the importance of physiologically grounded representation.
- Omitting channel/local captioning reduces accuracy even on high-level tasks, validating the need for hierarchical supervision.
- Scaling both model size and dataset diversity yields monotonic improvements, with no evidence of performance saturation at maximal capacity.
Practical and Theoretical Implications
SleepLM formalizes a generative, open-ended approach to sleep intelligence, transitioning from static classification to interactive description and reasoning. The multilevel captioning yields transferable representations and practical interpretability in clinical and consumer settings. The embedding space continuity enables semantic retrieval, controlled insight generation, and zero-shot generalization, creating new possibilities for sleep medicine, precision health monitoring, and the development of personalized physician assistants.
Theoretically, SleepLM demonstrates that compound multimodal objectives and hierarchical linguistic supervision can unlock rich abstraction and transfer in dense temporal physiological domains, currently inaccessible to generic LLMs or VLMs. By bridging language and signal, SleepLM advances the frontier of foundation model utility for time-series health signals.
Targeted Generation Ability
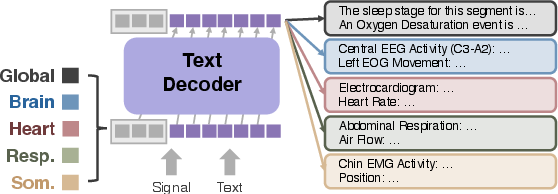
Figure 6: SleepLM supports targeted generation by modality, allowing precise, controllable insight synthesis conditioned on designated channels.
Conclusion
SleepLM establishes a scalable and generalizable framework for natural-language sleep intelligence by aligning raw PSG with multilevel text supervision, using unified multimodal objectives and architecture. The model achieves dominant performance across classification, regression, retrieval, and generative tasks, with strong numerical evidence for data efficiency, semantic alignment, and unseen-concept generalization. Its capabilities lay the foundation for practical, interactive, and interpretable sleep analytics, and signal broader advances in foundation models for physiological time series.