Are we really tilting? The mechanics of reward guidance in flow and diffusion models
Abstract: Reward guidance algorithms steer a learned generative process toward the reward-tilted measure at inference time. While empirically powerful, these methods are prone to reward hacking: the guided model over-optimizes the reward at the cost of fidelity to the learned distribution. Prior work has attributed this to the complexity of neural reward functions or implicit biases in diffusion training, but its fundamental origins remain poorly understood. We show that reward hacking arises from an approximation made in most practical implementations of reward-guided diffusion -- finite-particle plug-in estimation of the Doob h-function -- even in the simplest non-trivial settings of Gaussian and Gaussian mixture targets with quadratic rewards. In closed form, we isolate two distinct failure modes of the plug-in estimator: it leads to reward hacking within each mode and it cannot select high-reward modes. We propose a closed-form reward damping schedule that corrects the within-mode bias with no additional compute, and clarify the role of best-of-n sampling in compensating for the mode selection failure. Experiments on Gaussian mixture targets, a 2D checkerboard, and FLUX.1 text-to-image generation confirm that our theoretical insights carry over to practical settings.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Are we really tilting? The mechanics of reward guidance in flow and diffusion models”
What is this paper about?
This paper looks at how to “steer” generative AI models (like text-to-image systems) toward results that score higher on a chosen goal, or “reward.” For example, you might want an image that better matches a caption, is bluer, or follows a rule. The authors explain why a popular way to do this steering often “cheats” the reward (called reward hacking) and how to fix it.
In math, the ideal target is a “tilted” version of the model’s original distribution:
- Desired target:
- Here, is the model’s original output distribution, is the reward (how good is), and is how strongly we push toward higher reward.
What questions do the authors ask?
- Why do common steering methods over-optimize the reward and produce weird or unrealistic results (reward hacking)?
- Where exactly does this problem come from?
- Can we fix it without a lot of extra computation?
- Why does “best-of-n” (generate several candidates and pick the best) work so well in practice?
How did they study it? (In everyday terms)
The authors combine theory and experiments:
- They focus on a standard steering trick that estimates how “good” the future result will be by sampling a few possible futures at each step (they call these “particles”). Think of it like asking a few friends to guess what will happen next and using their average to decide where to go. This is called a plug-in estimator.
- They analyze very clean, simple cases where the math can be solved exactly (single Gaussian “blobs” and mixtures of Gaussians) with simple rewards (like “be close to point A”). These are like toy worlds where we can see precisely what goes wrong.
- They then confirm the same behavior in practical settings: a 2D checkerboard toy dataset and real text-to-image generation with FLUX.1, using both simple image rewards (e.g., “more blue”) and human-preference rewards (ImageReward).
- They propose a simple fix called reward damping: start with a gentler steering strength and gradually ramp it up over time. This requires no extra compute.
- They also explain why best-of-n (generate n candidates and pick the top one) helps with “mode selection” (choosing the right kind of result among very different possibilities).
What did they find and why does it matter?
Here are the main findings:
- The source of reward hacking: It mainly comes from the practical shortcut of using only a few “particles” (imagined futures) to guide the model at each step. With too few particles, the method becomes overly aggressive.
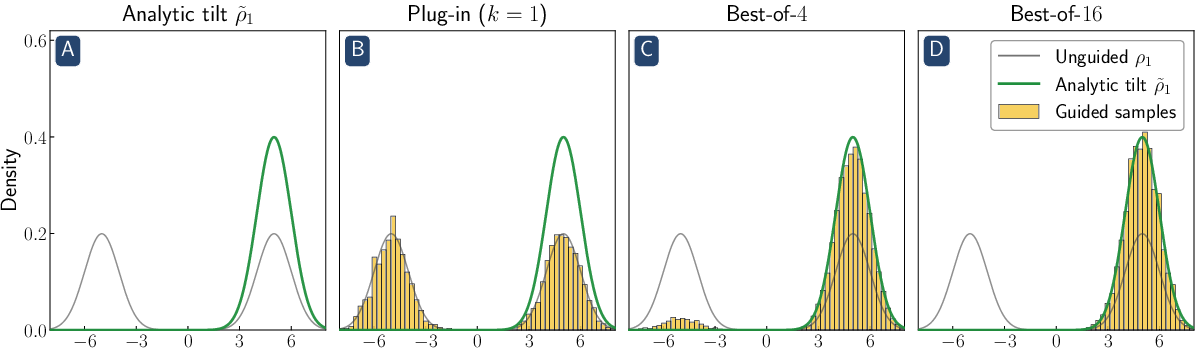
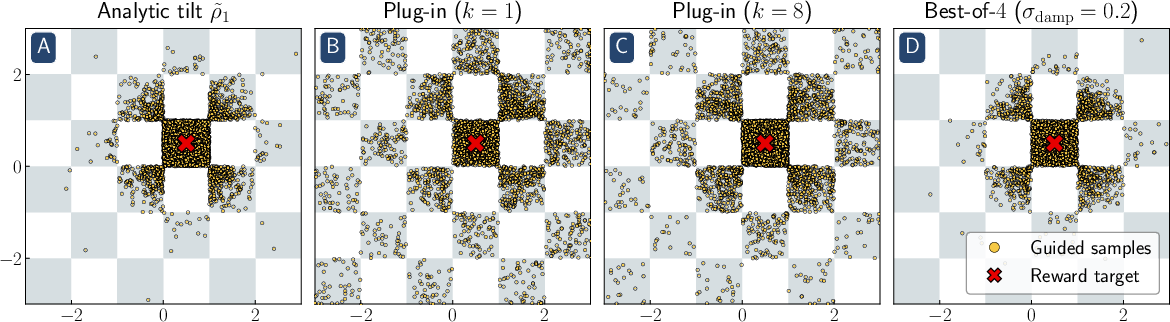
- Two distinct failure modes: 1) Within-mode hacking: When the model is already in one “type” of output (one cluster or mode), the guidance pushes too hard. It overshoots the target and squeezes the variety too much—results become overly concentrated and can look unnatural. 2) Mode selection failure: When there are very different kinds of outputs (multiple modes), the guidance can’t reliably switch to a far-away, higher-reward mode. In short, it can’t “see” or properly move toward distant better options.
- A simple fix for within-mode hacking: Reward damping. Use a time-dependent guidance strength that starts softer and increases later. This reduces overshoot and avoids collapsing variety, and it costs no extra compute compared to the usual method.
- Why best-of-n helps mode selection: Even if any single guided run struggles to jump to the better mode, running several independent tries increases the chance that one of them ends up in the right place. Picking the best one among n tries lets you recover much of what the ideal method would do.
- Experiments confirm the theory:
- On Gaussian mixtures and a 2D checkerboard, reward damping fixes the “over-pushing” inside a mode, and best-of-n helps pick the right mode.
- On FLUX.1 text-to-image:
- Simple rewards (like “be more blue” or “brighten this area”): naive guidance often “cheats” (e.g., makes the whole image flat-blue or removes important objects to brighten a region). Damped guidance achieves high reward while keeping the scene realistic.
- Human-preference reward (ImageReward): naive guidance again hacks the reward (ignoring parts of the prompt), while damping leads to more balanced and faithful improvements. Best-of-n further helps choose better, prompt-following results.
A helpful analogy
- Imagine steering a car with a GPS that only peeks a tiny bit into the future. If you trust just a few quick guesses (few particles), you might swerve too hard (within-mode hacking) or fail to take a better route that’s a bit farther away (mode selection failure).
- Reward damping is like easing into the steering, so you don’t overcorrect early.
- Best-of-n is like trying several routes in parallel and keeping the best one.
What are the implications?
- For practitioners: If your guided diffusion/flow model “wins” the reward but produces unrealistic or off-prompt results, the problem likely comes from the finite-particle plug-in estimation. Try:
- Reward damping to prevent over-pushing within a mode (cheap and simple).
- Best-of-n sampling to improve mode selection (generate a few candidates and keep the best).
- For researchers: The paper provides a clear mathematical explanation of where reward hacking comes from and offers a principled fix. This insight can guide better designs for reward-guided generation in images, molecules, proteins, and beyond.
In short, the paper shows that the common guidance shortcut is the root cause of reward hacking, separates the problem into two clear parts, and proposes simple, practical tools—reward damping and best-of-n—to recover behavior much closer to the ideal target.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future research could address to strengthen or extend the paper’s findings.
- Beyond Gaussian/quadratic regimes: Provide theoretical analysis of plug-in bias and reward hacking for non-Gaussian targets (e.g., heavy-tailed, manifold, or discrete data) and non-quadratic rewards (e.g., neural rewards, piecewise or non-smooth rewards).
- Anisotropic and unknown covariance: Derive a principled damping schedule for general (non-isotropic) covariances and show how to estimate or track local posterior covariance online to set λ_t without a hand-tuned σ.
- General noise schedules: Characterize necessary and sufficient conditions under which non-memoryless noise schedules can (or provably cannot) recover the analytic reward tilt; explore whether schedule design combined with variance reduction (or control variates) can remove plug-in bias.
- Discretization error: Quantify how finite-step ODE/SDE solvers (and practical lookahead/posterior samplers such as Diamond maps) interact with finite-k plug-in bias, including stability, error accumulation, and convergence to the intended limiting flow.
- Finite-k error bounds: Tighten the W∞ upper bound (currently O(√log k)) with dimension-dependent constants, matching lower bounds, and rates for general classes of targets/rewards; extend to other distances (e.g., KL, TV) relevant to tilt fidelity.
- Multi-particle guidance with damping: Analyze whether combining damping with k > 1 particles yields additive, redundant, or antagonistic benefits; derive optimal compute–bias tradeoffs for a fixed budget.
- Best-of-n theory: Formalize how best-of-n alters the target distribution (mode weights, tail behavior) relative to the true tilt; characterize its asymptotic and finite-n bias and how n should scale with reward variance, mode separation, and dimension.
- Mode selection without best-of-n: Develop inference-time mechanisms that provably recover correct mode weights (or their approximations) without resorting to post-hoc selection (e.g., resampling, SMC/annealing, or mixture-aware guidance).
- Mixture weighting accuracy: Quantify how damping impacts mode weights in mixtures (does it only fix within-mode bias or also distort relative mode probabilities?) and propose corrections if weights deviate from the true tilt.
- High-dimensional scaling laws: Establish dimension-dependent thresholds for mean overshoot and covariance collapse under plug-in guidance; identify regimes (λ, d, spectrum of Σ) where reward hacking becomes inevitable or avoidable.
- Robustness to reward misspecification: Study how noisy, biased, or adversarial rewards (e.g., learned preference models, VLM-based objectives) affect plug-in bias, damping efficacy, and mode selection; propose defenses or calibration methods.
- Gradient pathologies: Analyze guidance behavior with flat/vanishing or highly non-Lipschitz reward gradients (common with VLM and preference models), including convergence, variance, and failure modes of plug-in estimators.
- Alternative estimators of the Doob h-function: Investigate variance-reduced or bias-corrected estimators (importance sampling, control variates, Rao-Blackwellization, conditional score models) that improve mode selection and within-mode fidelity without exponential cost.
- Training–inference coupling: Explore whether modifying pretraining (e.g., flow objectives, auxiliary heads predicting local covariance or h-gradients) reduces the need for damping/best-of-n at inference time.
- SDE vs ODE guidance: Provide a unified analysis for guided SDE samplers (with diffusion noise during inference) versus deterministic probability-flow ODEs, including how noise helps or harms mode selection and bias.
- Guarantees for practical pipelines: Extend theory to widely used guidance schemes (classifier-free, self-guidance, FMRG) and posterior samplers (Diamond/Meta maps), clarifying when they replicate plug-in bias or admit principled fixes.
- Targeted diagnostics: Define quantitative diagnostics/metrics for “tilt fidelity” (beyond visuals) that detect mean overshoot, covariance collapse, and mode-weight errors; standardize evaluation relative to the analytic tilt where available.
- Adaptive schedules: Design adaptive λ_t policies that respond online to estimated within-mode contraction or reward-gradient magnitude, with guarantees on stability and approximation to the true tilt.
- Compute–quality tradeoffs: Model the joint cost of particles, solver steps, and best-of-n to allocate budget optimally for target tilt fidelity; develop anytime strategies that adapt n or k based on early indicators.
- Hardness and approximation: Given NP-hardness of exact tilting for some rewards, characterize classes of reward/target pairs where damping+best-of-n achieves provable approximation ratios or bounds on divergence to the true tilt.
- Mode overlap and near-degenerate cases: Analyze guidance when mixture components overlap substantially or have near-singular covariances, including the reliability of damping and mode selection in such regimes.
- Safety and alignment concerns: Evaluate whether damping reduces reward-hacking artifacts that raise safety/misalignment issues (e.g., text-to-image prompt faithfulness) and how best-of-n interacts with undesirable failure modes.
- Discrete and structured domains: Extend methods and guarantees to discrete generative models (text, code, graphs) and structured generation (proteins/molecules) where posterior sampling and reward gradients differ substantially.
- Broader RL/control settings: Validate whether insights about plug-in bias and damping transfer to inference-time tilt sampling in RL/control (beyond diffusion), including continuous-time entropy-regularized control formulations.
- Automatic hyperparameterization: Replace manual σ (damping strength) and λ tuning with data-driven or Bayesian procedures that target a desired divergence to the analytic tilt under compute constraints.
Practical Applications
Immediate Applications
The paper’s findings enable deployable changes to how practitioners guide diffusion/flow models at inference time. The items below summarize concrete use cases, sectors, and workflows, along with key assumptions and dependencies.
- Text-to-image generation: reward-hacking mitigation in guidance
- Sectors: software, creative industries, advertising, media, education
- What to do: Replace constant reward scale with the proposed time-dependent reward damping schedule λt = λ / (1 + 2λσ{1|t}2) during inference-time guidance; optionally pair with best-of-n selection to improve satisfaction of hard constraints (e.g., legible text, composition, object presence).
- Tools/products/workflows:
- Add a “damped guidance” toggle or scheduler to diffusion frameworks (e.g., Hugging Face Diffusers, custom FLUX/Stable Diffusion pipelines).
- Provide a simple hyperparameter for σ (damping strength) with safe defaults; expose best-of-n orchestrator that runs n seeds in parallel and picks the top reward sample.
- Integrate with common reward models (ImageReward, PickScore, HPSv2) and VLM-based rewards for constraint satisfaction.
- Assumptions/dependencies:
- Damping schedule is derived for Gaussian targets under a memoryless noise schedule; in practice σ is a tunable hyperparameter that empirically works even when assumptions are violated.
- Best-of-n increases compute; requires parallelization or budget-aware orchestration.
- Preference-aligned image generation for consumer apps
- Sectors: daily life, consumer software, education
- What to do: Enable “safer” preference-guided generation that reduces degenerate outputs (e.g., blue-wash, missing objects) by defaulting to damped guidance and a small best-of-n (e.g., n=2–4).
- Tools/products/workflows:
- Update consumer-facing image apps to use damped reward schedules with standard human-feedback rewards or VLM-based scoring.
- Add an advanced setting for “precision vs. diversity” that internally adjusts damping and n.
- Assumptions/dependencies:
- Reward model access and differentiable scoring (or a gradient-through-ODE workflow); otherwise use gradient-free alternatives.
- Molecular design inference-time steering without mode collapse
- Sectors: healthcare, biotech, pharmaceuticals
- What to do: Apply damped reward guidance when steering ligand or molecule generators toward predicted binding affinity or pocket compatibility to limit collapse to unrealistic chemistries; use best-of-n to explore multiple chemotypes/modes.
- Tools/products/workflows:
- Integrate damping in diffusion-based de novo design pipelines (e.g., TargetDiff, DecompDiff) that use docking or ML scoring as a reward.
- Batch sampling with n seeds per prompt/condition and rank by binding score; archive top-k for downstream filtering.
- Assumptions/dependencies:
- Reward models (docking, affinity predictors) can be noisy and non-differentiable; damping remains useful with score-only guidance or surrogate gradients.
- Regulatory and medicinal chemistry filters still needed for viability and safety.
- Protein sequence/structure generation guided by stability/fitness scores
- Sectors: healthcare, biotech
- What to do: Use damping to temper over-optimization when guiding diffusion models with stability or binding rewards; use best-of-n to surface diverse high-scoring candidates across design modes.
- Tools/products/workflows:
- Wrap inference with damped schedules and best-of-n candidate selection; feed shortlists into structure prediction and wet-lab prioritization.
- Assumptions/dependencies:
- Fitness/reward functions may be black-box or sparse; gradient-free selection is compatible with best-of-n; interpretability and experimental validation required.
- Robotics trajectory generation with diffusion policies
- Sectors: robotics, manufacturing, logistics
- What to do: Apply damping during inference-time cost/reward guidance to avoid unsafe over-optimization (e.g., overly aggressive shortening of time or energy) and use best-of-n seeds to select feasible modes (e.g., different grasp strategies).
- Tools/products/workflows:
- Incorporate damped guidance into trajectory diffusion samplers; evaluate n seeds under safety constraints and choose the top feasible plan.
- Assumptions/dependencies:
- Safety checks and constraint layers remain essential; reward gradients may be partial or noisy.
- Financial scenario generation guided by risk/return metrics
- Sectors: finance
- What to do: Use damping when tilting generative scenarios toward extreme risk or return to avoid unrealistic tails; use best-of-n to capture multiple market regimes.
- Tools/products/workflows:
- Batch-generate n guided scenarios; rank by composite risk score; retain a diverse subset.
- Assumptions/dependencies:
- Risk scores are domain-specific and may not be differentiable; governance and model risk management processes are required.
- Data augmentation with quality/consistency constraints
- Sectors: software, ML ops, education
- What to do: Apply damped guidance for quality metrics (sharpness, color balance, mask coverage) to avoid reward hacking during augmentation; use best-of-n to select among diverse augmentations.
- Tools/products/workflows:
- Integrate into augmentation pipelines for vision tasks; log reward distributions and n-best images for reproducibility.
- Assumptions/dependencies:
- Metrics must reflect downstream task performance; extra compute for best-of-n should be budgeted.
- Reproducible evaluation and benchmarking for reward-guided generation
- Sectors: academia, industry R&D
- What to do: Standardize baselines to include damped guidance and best-of-n settings when reporting reward-guided results; report guidance k (particles), σ (damping), and n (best-of-n).
- Tools/products/workflows:
- Publish evaluation scripts that toggle damping on/off and sweep n; include plots of reward vs. fidelity (e.g., CLIP score vs. FID).
- Assumptions/dependencies:
- Community adoption and clear documentation of inference-time hyperparameters.
- Policy and governance: mitigating misleading reward-optimized media
- Sectors: policy, platforms, media
- What to do: Encourage default use of damping in user-facing systems that optimize subjective rewards (e.g., virality or engagement proxies) to reduce reward hacking artifacts; document best-of-n usage to avoid hidden cherry-picking.
- Tools/products/workflows:
- Disclosure templates stating guidance schedules, reward models, and selection strategies (n, ranking criteria).
- Assumptions/dependencies:
- Platform compliance and auditing; alignment between policy goals and product incentives.
Long-Term Applications
The paper also motivates developments that require additional research, scaling, or validation before widespread deployment.
- Adaptive, theory-grounded schedulers beyond Gaussian assumptions
- Sectors: software, academia
- What: Learn or estimate online damping schedules that match non-Gaussian, high-dimensional targets and non-quadratic rewards; adapt σ_t from observed within-mode variance or curvature.
- Tools/products/workflows:
- “Guidance optimizer” modules that monitor sample covariance and reward curvature to update λ_t adaptively.
- Assumptions/dependencies:
- Requires robust on-the-fly statistics and stability analysis; theoretical guarantees beyond isotropic Gaussian remain open.
- Efficient mode-selection without linear n scaling
- Sectors: software, compute infrastructure
- What: Replace brute-force best-of-n with diversity-aware seeding, early-pruning, or bandit-style selection to approximate mode selection at lower compute.
- Tools/products/workflows:
- Multi-armed bandit or successive-halving controllers over initial seeds; lightweight surrogates for early reward prediction.
- Assumptions/dependencies:
- Surrogates must correlate with final reward; engineering for low-latency parallelism.
- Learned Doob h-function approximators and variance-reduced estimators
- Sectors: academia, software
- What: Train amortized value functions for h_t(x) or develop low-variance, multi-sample estimators that mitigate plug-in bias without exponential k; integrate with stochastic optimal control formulations.
- Tools/products/workflows:
- Auxiliary networks trained offline to predict h_t; control-variates or reweighting schemes; hybrid value/policy fine-tuning.
- Assumptions/dependencies:
- Additional training data and compute; generalization across tasks; robustness to reward misspecification.
- Reward design for better mode selection (smooth, informative gradients)
- Sectors: software, healthcare, robotics
- What: Engineer rewards with smoother gradients or curriculum shaping to improve mode attraction and reduce dependence on best-of-n; for VLMs, design structured question prompts and logit-temperature scaling for clearer guidance.
- Tools/products/workflows:
- Reward shaping libraries; prompt and temperature tuning toolkits for VLM-based guidance.
- Assumptions/dependencies:
- Trade-offs between faithfulness to the true objective and convenience of smoother gradients.
- Domain-specific regulators and safeguards for guided generation
- Sectors: healthcare, policy, finance
- What: For safety-critical uses (medical images, drug candidates, financial scenarios), codify guidance practices (e.g., damping enabled, n and selection criteria logged) and require uncertainty/robustness reporting.
- Tools/products/workflows:
- Audit trails capturing λ_t, σ, k, n, rewards, and seed choices; reproducibility checklists in submissions/regulatory filings.
- Assumptions/dependencies:
- Regulatory acceptance; standardization efforts across organizations.
- Robotics: constrained guidance with safety and feasibility guarantees
- Sectors: robotics, autonomous systems
- What: Extend theory and practice to constrained diffusion guidance with formal safety buffers and reachability-aware mode selection.
- Tools/products/workflows:
- Safety-filtered best-of-n (discard infeasible seeds via fast checkers); constrained ODE/SDE solvers with damping-aware certificates.
- Assumptions/dependencies:
- New theory for constrained h-transforms; certified runtime monitors.
- Cross-modal and discrete generative domains
- Sectors: software, media, NLP
- What: Apply damping and mode-selection principles to audio, video, and discrete diffusion (text/code) where guidance often over-optimizes style or token-level rewards.
- Tools/products/workflows:
- Discrete flow-matching adapters with damped schedulers; multi-candidate decoding with reward-aware re-ranking.
- Assumptions/dependencies:
- Differentiability in discrete spaces is limited; may require surrogate gradients or score-only selection.
- Compute- and energy-aware guidance orchestration
- Sectors: energy, cloud infrastructure
- What: Optimize the trade-off between best-of-n performance and energy footprint via adaptive n, early stopping, or carbon-aware scheduling.
- Tools/products/workflows:
- Controllers that adjust n based on observed reward variance and energy budgets; telemetry dashboards.
- Assumptions/dependencies:
- Access to reliable energy/carbon measurements; scheduling in shared clusters.
Key cross-cutting assumptions and dependencies
- The reward damping schedule is derived under a memoryless noise schedule and isotropic Gaussian targets; in practice σ is treated as a hyperparameter. Empirical evidence suggests robustness beyond the idealized assumptions, but formal guarantees are limited.
- Best-of-n improves mode selection but increases compute and can implicitly favor biases in the reward model; logging and governance are recommended.
- Many practical workflows require differentiable reward signals or differentiable surrogates; where not available, selection-based strategies (best-of-n, re-ranking) can still exploit the paper’s insights.
- Posterior sampling p(X₁|X_t) (e.g., via Diamond/GLASS maps) is assumed for some implementations; availability and quality of these samplers affect outcomes.
Glossary
- Best-of-n: A strategy that generates n guided samples and selects the one with the highest reward to improve outcomes. Example: "taking the highest-reward option out of guided samples (best-of-) significantly improves the performance of guidance in generative models in many settings"
- Classifier-free guidance: A diffusion guidance method that steers generation using conditional and unconditional model outputs without an external classifier. Example: "Widely used methods such as classifier guidance \citep{dhariwal2021diffusion} and classifier-free guidance \citep{ho2022classifier} can be understood as instances of reward guidance"
- Classifier guidance: A diffusion guidance method that uses a trained classifier’s gradients to steer generation toward desired attributes. Example: "Widely used methods such as classifier guidance \citep{dhariwal2021diffusion} and classifier-free guidance \citep{ho2022classifier} can be understood as instances of reward guidance"
- Diamond map: A learned stochastic flow map used to sample posteriors in one step, enabling efficient lookahead in inference. Example: "The posterior sampling from the law of is computed with a Diamond map \citep{holderrieth2026diamond} with $5$ inner steps."
- Doob h-function: The value function h_t(x) giving the expected terminal reward exponentiated, conditioned on the current state; central to the Doob h-transform. Example: "Defining the Doob -function "
- Doob h-transform: A method to modify the drift of a diffusion so that its terminal distribution matches a tilted (reward-weighted) target. Example: "The Doob -transform (e.g., \cite{rogers2000diffusions}) provides a principled framework to solve the reward guidance problem"
- Doob's L2 maximal inequality: A martingale inequality used to control the maximum of a process in L2, useful in convergence proofs. Example: "whose proof relies on Gr\"onwall's inequality along with Doob's maximal inequality"
- Flow map reward guidance (FMRG): A deterministic guidance approach that backpropagates the reward through the probability flow ODE to steer sampling. Example: "A different deterministic approach is flow map reward guidance \citep{huang2026guide}, which backpropagates the reward gradient through the unguided probability flow ODE"
- Flow matching: A training objective that learns a vector field so integrating its ODE transforms noise into data. Example: "Such a model can be obtained by minimizing the flow matching objective"
- Gaussian concentration inequality: A probabilistic bound that controls deviations of functions of Gaussian variables, used for sample-path estimates. Example: "The proof, given in \Cref{app:wasserstein-proof}, follows from the reparameterization trick, Gaussian concentration inequality, and Gr\"onwall's inequality"
- GLASS flows: A framework that implements the Doob h-transform via particle-based plug-in estimation within stochastic interpolants. Example: "Within this framework, GLASS flows \citep{holderrieth2026glass} implement the Doob -transform by approximating the intractable value function"
- Grönwall's inequality: A differential inequality used to bound solutions of ODEs and analyze stability and convergence. Example: "whose proof relies on Gr\"onwall's inequality along with Doob's maximal inequality"
- Inverse temperature: A scalar λ controlling the strength of the reward tilt; higher values emphasize the reward more. Example: "we often want samples from the reward-tilted measure given a reward function and inverse temperature ."
- KL-regularized variational optimization: An optimization that trades off expected reward with a KL divergence penalty to a base distribution. Example: "The reward-tilted measure \eqref{eq:reward-tilted-measure} commonly arises in reinforcement learning \citep{uehara2025inference} as the solution to a KL-regularized variational optimization problem"
- Memoryless noise schedule: A specific time-dependent diffusion noise scaling ensuring certain conditional independence properties for exact h-transforms. Example: "choosing the memoryless noise schedule ensures that ."
- Mode selection: The process by which guided sampling chooses among multiple modes of a distribution, ideally favoring high-reward modes. Example: "Mode selection: the role of the initial seed"
- NP-hard: A complexity class indicating computational intractability under standard assumptions. Example: "showing that exact reward tilting is NP-hard even with certain quadratic rewards."
- Policy-gradient: A reinforcement learning method that updates parameters in the direction of estimated reward gradients. Example: "fine-tunes the generative model via policy-gradient or value-function learning"
- Plug-in estimator: A Monte Carlo estimator that approximates an intractable expectation by averaging over sampled particles. Example: "a -particle plug-in estimator"
- Probability flow ODE: The deterministic ODE whose solution shares time marginals with a diffusion model, used for sampling without noise. Example: "samples from the data distribution are drawn by numerically integrating the probability flow ODE"
- Reparameterization trick: A technique to express random variables as deterministic functions of base noise, easing gradient-based analysis. Example: "The proof is in \Cref{app:plugin-flow-gaussian-memoryless-proof} and follows by the reparameterization trick"
- Reward damping: A scheduling strategy that reduces the effective guidance strength over time to mitigate over-optimization bias. Example: "We introduce reward damping, a simple and principled guidance schedule to mitigate reward hacking."
- Reward guidance: Inference-time steering of generative models to favor samples with higher reward under a specified objective. Example: "Reward guidance algorithms steer a learned generative process toward the reward-tilted measure at inference time."
- Reward hacking: The phenomenon where guidance over-optimizes the reward, producing unrealistic or degenerate samples. Example: "these methods are often prone to reward hacking"
- Reward-tilted measure: A distribution obtained by weighting the base distribution by the exponential of a reward function. Example: "reward-tilted measure "
- SDE (stochastic differential equation): A differential equation with a stochastic term modeling random dynamics, underlying diffusion models. Example: "the solution of the SDE"
- Signal-to-noise ratio: A measure of signal strength relative to noise; in guidance, it can be amplified but may distort distributional properties. Example: "showing it can amplify the signal-to-noise ratio but distort mode weights."
- Stochastic flow map frameworks: Methods that learn or use mappings to sample conditionals in one step, reducing inner-loop costs. Example: "stochastic flow map frameworks that sample the posterior in a single step"
- Stochastic interpolants: A unifying framework connecting flows and diffusions via time-indexed interpolations between noise and data. Example: "through stochastic interpolants and the Doob -transform."
- Stochastic optimal control: A formalism for optimizing expected costs under stochastic dynamics, related to reward-guided generation. Example: "casts reward-guided generation as a reinforcement learning or stochastic optimal control problem"
- Value-function learning: Estimating a function that predicts expected future rewards to guide decisions or control. Example: "fine-tunes the generative model via policy-gradient or value-function learning"
- VLM (vision-LLM): A multimodal model used here to define rewards based on textual questions about images. Example: "with a VLM reward using Qwen2.5-VL-3B \citep{bai2025qwen25vl}"
- Wasserstein distance: A metric on probability distributions measuring minimal transport cost; used to compare guided outputs. Example: "the -Wasserstein distance"
Collections
Sign up for free to add this paper to one or more collections.

