- The paper introduces Diamond Maps to achieve fast and accurate reward alignment via stochastic flow maps for generative modeling.
- It leverages posterior and weighted designs to enable efficient value function estimation and unbiased Monte Carlo sampling.
- Empirical results on benchmarks like CIFAR-10 and ImageNet demonstrate improved scalability, fidelity, and computational efficiency.
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
Motivation and Problem Statement
Reward alignment in generative modeling with diffusion and flow-based models remains a significant challenge, especially when adapting to arbitrary preferences or constraints post-training. Existing approaches fall into reward fine-tuning—costly and inflexible for new rewards—and inference-time guidance, which is computationally expensive and frequently yields biased results due to inaccurate value function estimation. This paper introduces Diamond Maps, a new class of stochastic flow map models designed to enable fast and accurate reward alignment through efficient value function estimation, thereby enabling scalable guidance, search, and sequential Monte Carlo (SMC) at inference time.
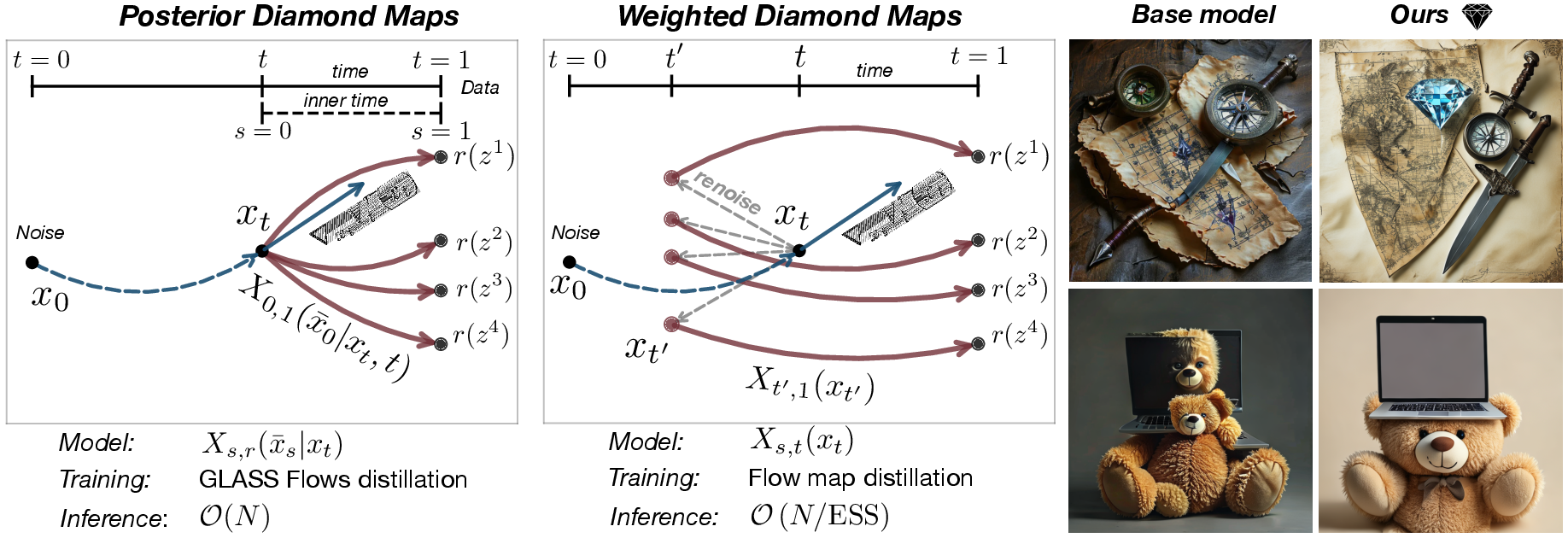
Figure 1: Diamond Maps overview illustrating stochastic flow maps for high-reward endpoints, with improved alignment and sampling efficiency across multiple tasks.
Stochastic Flow Maps and Value Function Estimation
Diamond Maps leverage recent advances in flow map distillation, specifically the ability to amortize the simulation of flow and diffusion models into a single-step neural network evaluation. The central insight is that stochasticity—absent in conventional (deterministic) flow maps—is essential for consistent value function estimation, which underpins reward-aligned sampling. Two designs are presented:
Posterior Diamond Maps and Efficient Guidance
Posterior Diamond Maps enable one-step "look-ahead" sampling for value function estimation. The model is trained via distillation from GLASS Flows; stochastic transitions allow exploration (critical for SMC and search), and exact guidance can be performed using consistent Monte Carlo estimators for the value function and its gradient.
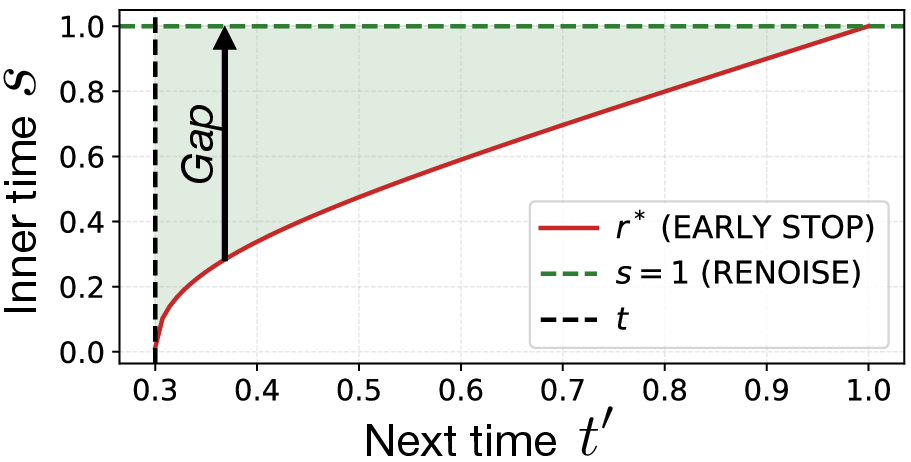
Additionally, Posterior Diamond Maps are demonstrated to encapsulate DDPM time-reversal transitions, allowing efficient iterative sampling that avoids error accumulation seen with conventional iterative denoising and noising. The method is validated quantitatively against standard and distilled flow maps, showing superior performance in Faithful ImageNet, CIFAR-10, and CelebA-64 benchmarks.

Figure 3: Guidance effect on blueness reward—Weighted Diamond Maps incorporate regularization, preventing drift from the data manifold.
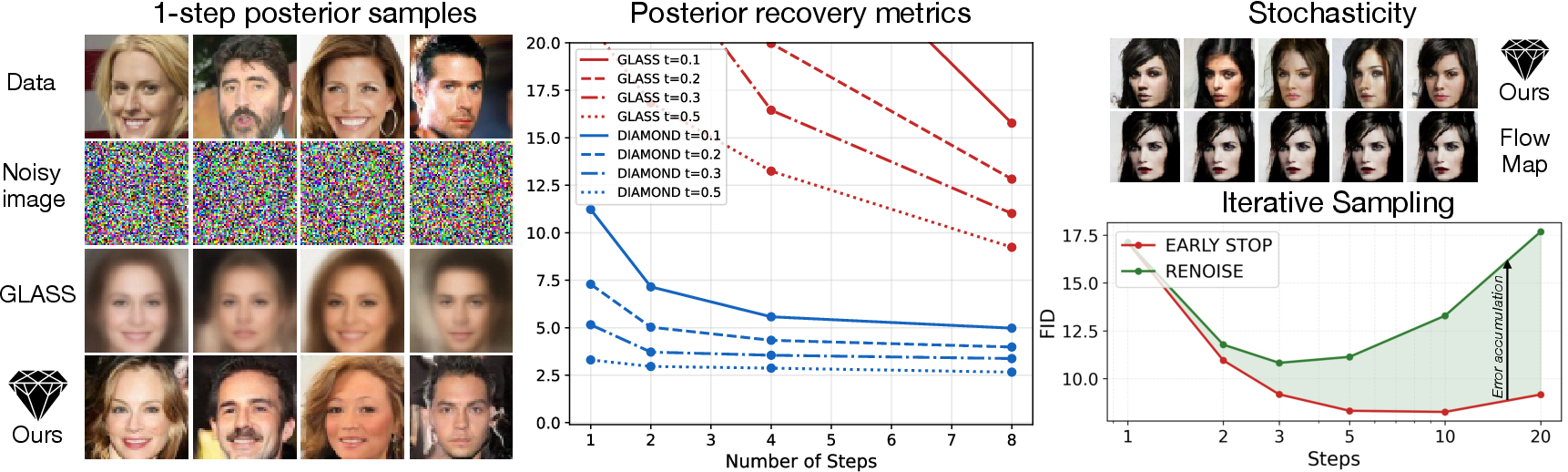
Figure 4: Posterior Diamond Map sampling: High-quality, stochastic samples from posterior; error accumulation avoided.
Weighted Diamond Maps and Plug-and-Play Scalability
Weighted Diamond Maps enable reward-aligned sampling using off-the-shelf distilled flow maps (e.g., SANA-Sprint) without retraining. Stochasticity is injected via a renoising map, and unbiased estimation is achieved by incorporating recovery rewards and score-based corrections. Monte Carlo estimators are presented for both value function and its gradient, with effective sample size (ESS) considerations influencing inference-time compute. This approach is tested at scale in high-resolution text-to-image (T2I) settings.
Weighted Diamond Maps outperform Best-of-N, prompt optimization, and Reward-based Noise Optimization methods in efficiency and reward alignment (GenEval and ImageReward metrics), demonstrating tight Pareto frontiers for guidance steps versus compute. Trajectories show improved adherence to prompts and reduced artifacts.

Figure 5: Illustration of guidance trajectories with Weighted Diamond Maps, highlighting prompt fidelity and artifact reduction after iterative steps.
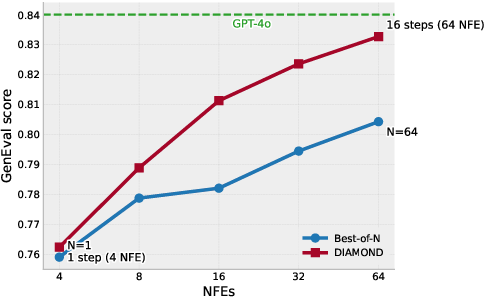
Figure 6: Pareto frontier for guidance—Weighted Diamond Maps achieve superior scaling and reward alignment compared to Best-of-N selection.
Experiments and Empirical Results
Experiments cover posterior distillation, reward-guided inference in linear inverse problems, text-to-image alignment with human preference rewards, and SMC with CLIP reward adaptation. Posterior Diamond Maps are distilled from flow-matching models on CIFAR-10/CelebA-64 and evaluated, demonstrating competitive FID and robustness to high reward scales due to stochasticity. Weighted Diamond Maps are applied to SANA-Sprint in 1024×1024 T2I, outperforming baselines and achieving state-of-the-art metrics in GenEval benchmarks for alignment and efficiency.
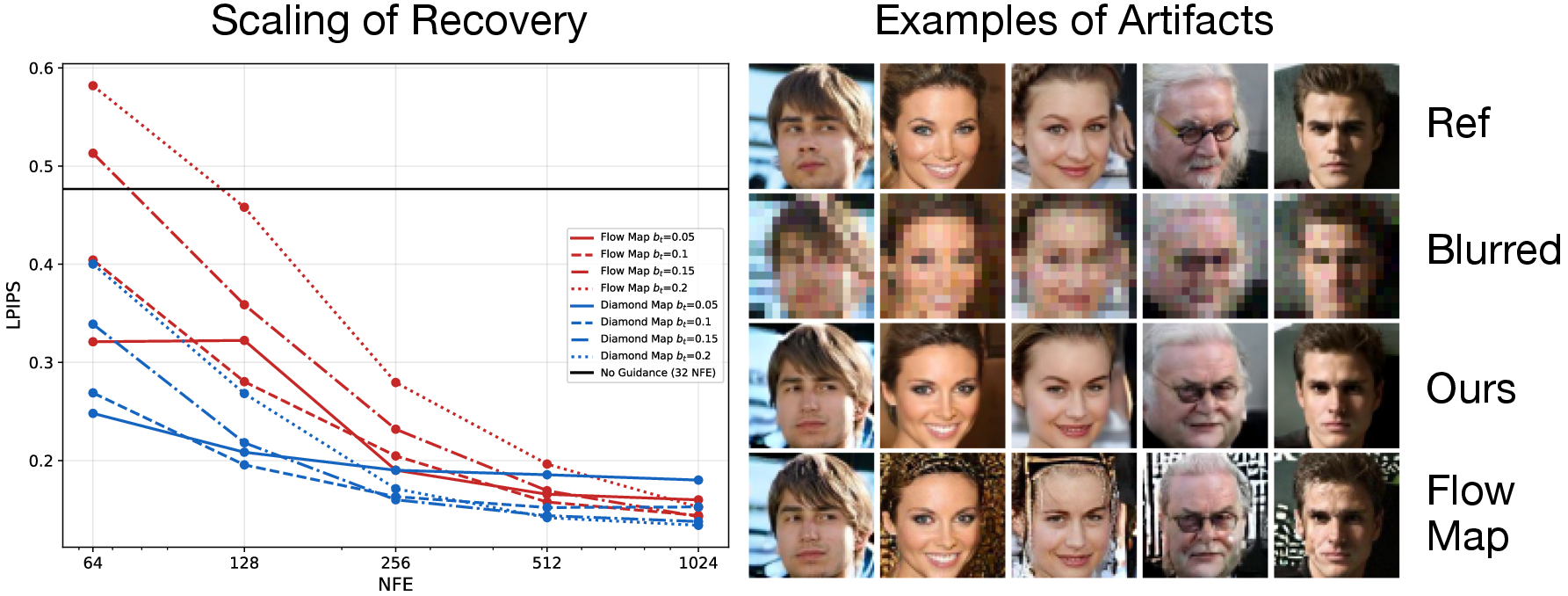
Figure 7: Pareto frontier for Gaussian deblurring—Posterior Diamond Maps are more robust to high reward scales, outperforming naive flow map guidance.

Figure 8: CLIP-reward SMC with Posterior Diamond Maps—successful adaptation to text prompts using stochastic search.
Practical and Theoretical Implications
Diamond Maps provide a practical inference-time approach for reward alignment in generative modeling, bridging the gap between sample efficiency, flexibility, and accuracy. The stochastic flow map paradigm supports rapid adaptation to arbitrary reward functions and constraints without retraining, enabling scalable search and guidance. The theoretical framing clarifies the role of stochasticity for value function estimation and positions Diamond Maps as a core architectural advance for plug-and-play reward alignment.
The results open pathways for RLHF-driven RL-guided sampling, efficient conditional generative modeling, and search-based inference over high-dimensional probabilistic manifolds. Extensions may include multi-modal reward composition, exploration-driven search trees, and integration with large-scale generators or alignment frameworks.
Conclusion
Diamond Maps represent a technically rigorous and empirically validated solution to the reward alignment problem in diffusion and flow-based generative models, enabling efficient value function estimation and scalable guidance at inference time. The stochastic flow map architecture unlocks practical and versatile adaptation to arbitrary preferences and constraints, and is poised for extensive application in scalable, reward-driven generative modeling paradigms.